 YOLOv6在LabVIEW中的推理部署(含源碼)
YOLOv6在LabVIEW中的推理部署(含源碼)

??
前言
前面我們給大家介紹了使用OpenCV以及ONNX工具包實現yolov5在LabVIEW中的部署,有英偉達顯卡的朋友們可能已經感受過使用cuda加速時yolov5的速度,今天主要和大家分享在LabVIEW中使用純TensoRT工具包快速部署并實現yolov5的物體識別, 本博客中使用的智能工具包可到主頁置頂博客[https://blog.csdn.net/virobotics/article/details/129304465]
中安裝 。若配置運行過程中遇到困難,歡迎大家評論區留言,博主將盡力解決。
以下是YOLOv5的相關筆記總結,希望對大家有所幫助。
| 【YOLOv5】LabVIEW+OpenVINO讓你的YOLOv5在CPU上飛起來 | https://blog.csdn.net/virobotics/article/details/124951862 |
|---|---|
| 【YOLOv5】LabVIEW OpenCV dnn快速實現實時物體識別(Object Detection) | https://blog.csdn.net/virobotics/article/details/124929483 |
| 【YOLOv5】手把手教你使用LabVIEW ONNX Runtime部署 TensorRT加速,實現YOLOv5實時物體識別(含源碼) | https://blog.csdn.net/virobotics/article/details/124981658 |
一、關于YOLOv5
YOLOv5是在 COCO 數據集上預訓練的一系列對象檢測架構和模型。表現要優于谷歌開源的目標檢測框架 EfficientDet,在檢測精度和速度上相比yolov4都有較大的提高。本博客,我們以YOLOv5 6.1版本來介紹相關的部署開發。
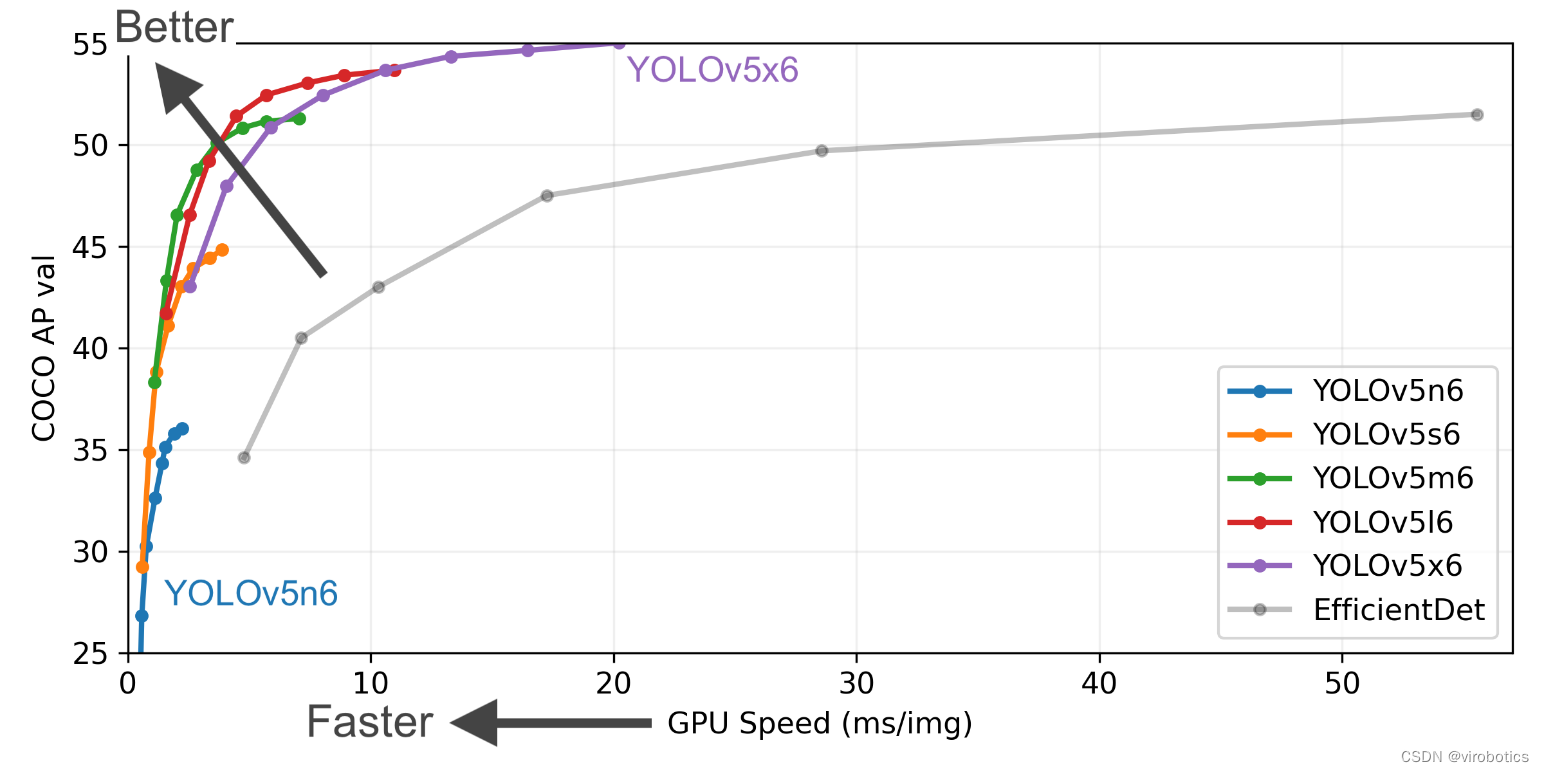
YOLOv5相比于前面yolo模型的主要特點是:
1、小目標的檢測精度上有明顯的提高;
2、能自適應錨框計算
3、具有數據增強功能,隨機縮放,裁剪,拼接等功能
4、靈活性極高、速度超快,模型超小、在模型的快速部署上具有極強優勢
關于YOLOv5的網絡結構解釋網上有很多,這里就不再贅述了,大家可以看其他大神對于YOLOv5網絡結構的解析。
二、YOLOv5模型的獲取
為方便使用, 博主已經將yolov5模型轉化為onnx格式 ,可在百度網盤下載
鏈接:[https://pan.baidu.com/s/15dwoBM4W-5_nlRj4G9EhRg?pwd=yiku]
提取碼:yiku
1.下載源碼
將Ultralytics開源的YOLOv5代碼Clone或下載到本地,可以直接點擊Download ZIP進行下載,
下載地址:[https://github.com/ultralytics/yolov5]
2.安裝模塊
解壓剛剛下載的zip文件,然后安裝yolov5需要的模塊,記住cmd的工作路徑要在yolov5文件夾下:
打開cmd切換路徑到yolov5文件夾下,并輸入如下指令,安裝yolov5需要的模塊
pip install -r requirements.txt
3.下載預訓練模型
打開cmd,進入python環境,使用如下指令下載預訓練模型:
import torch
# Model
model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # or yolov5n - yolov5x6, custom
成功下載后如下圖所示: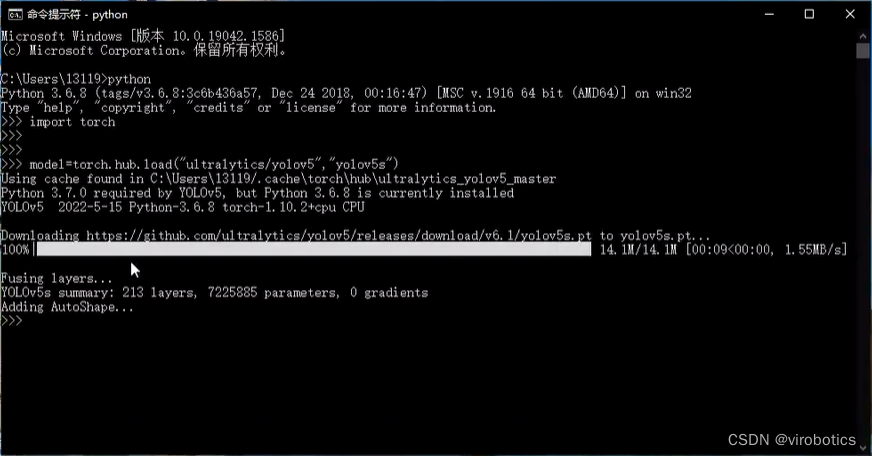
4.轉換為onnx模型
將.pt文件轉化為.onnx文件,在cmd中輸入轉onnx的命令(記得將export.py和pt模型放在同一路徑下):
python export.py --weights yolov5s.pt --include onnx
如下圖所示為轉化成功界面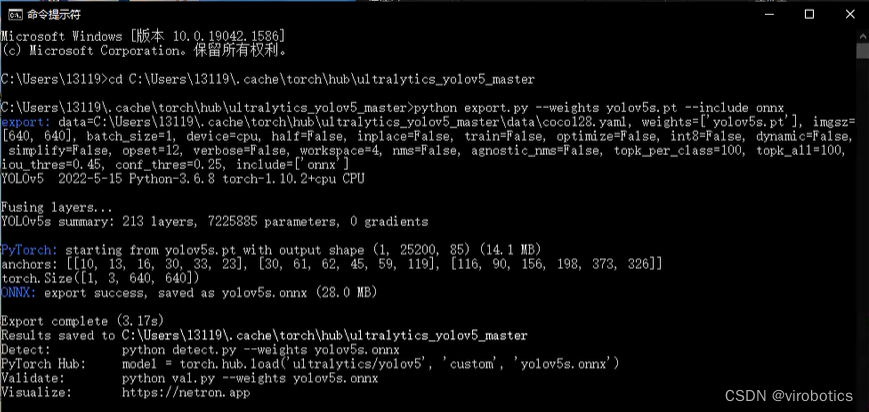
其中yolov5s可替換為yolov5myolov5myolov5lyolov5x
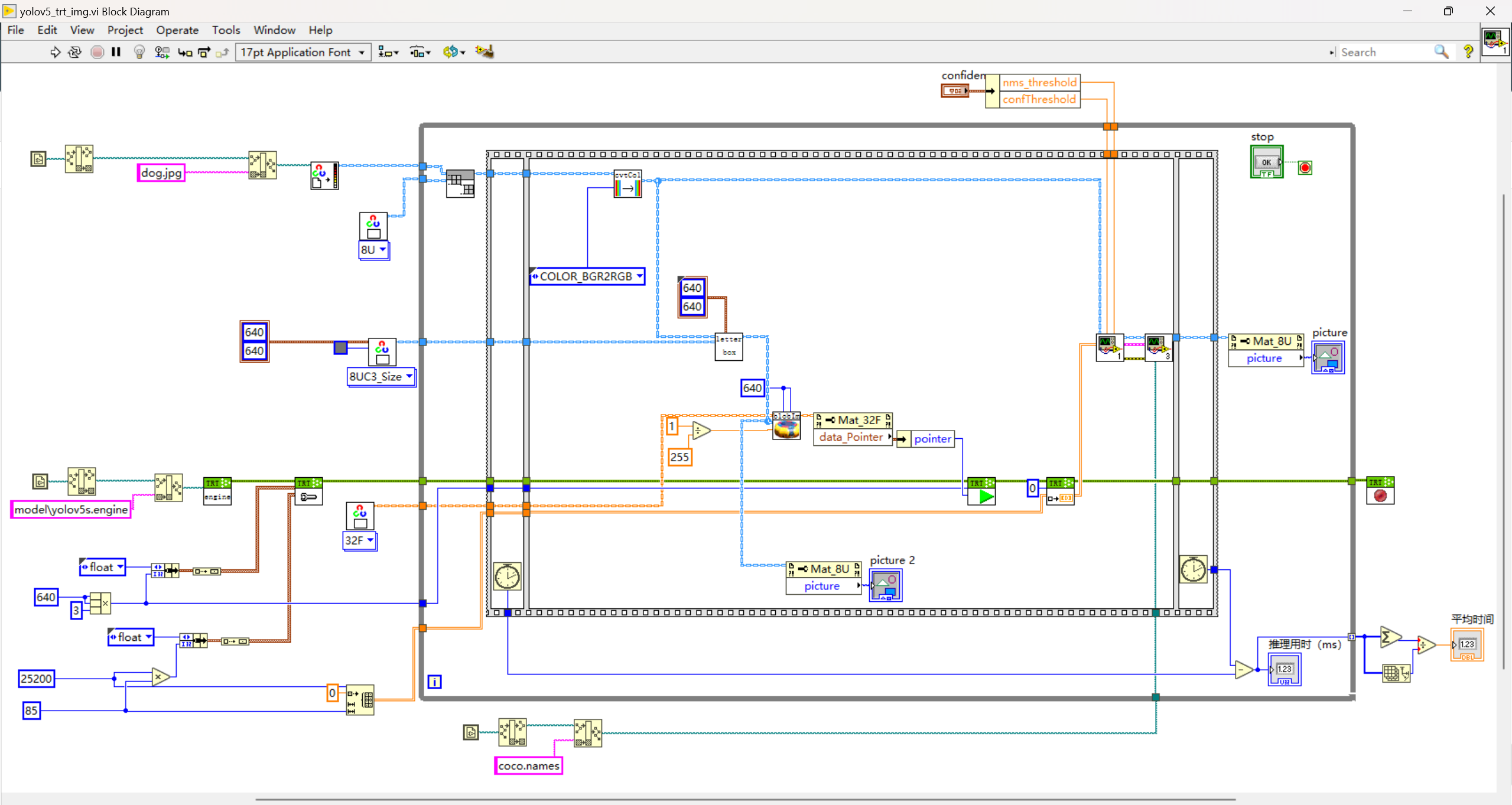
三、LabVIEW+TensorRT的yolov5部署實戰(yolov5_trt_img.vi)
如需要查看TensorRT工具包相關vi含義,可查看:[https://blog.csdn.net/virobotics/article/details/129492651]
1.onnx轉化為engine(onnx to engine.vi)
使用onnx_to_engine.vi,將該vi拖拽至前面板空白區域,創建并輸入onnx的路徑以及engine的路徑,type即精度,可選擇FP32或FP16,肉眼觀看精度無大差別。(一般FP16模型比FP32速度快一倍)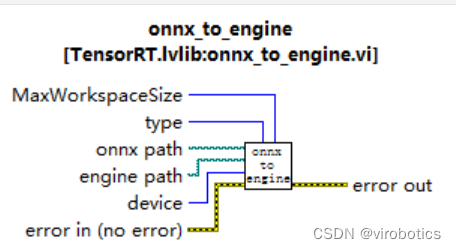
轉換的完整程序如下: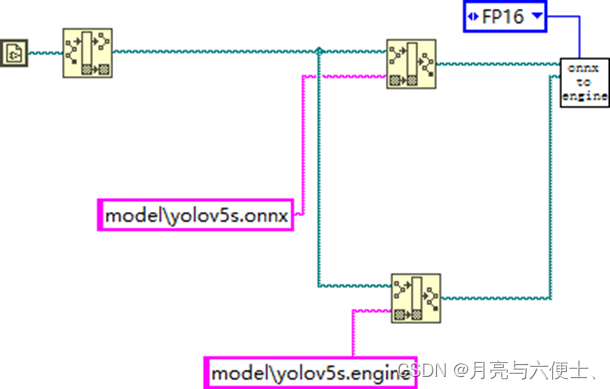
點擊運行,等待1~3分鐘,模型轉換成功,可在剛剛設定的路徑中找到我們轉化好的mobilenet.engine.
Q:為什么要轉換模型,不直接調用ONNX?> A:tensorRT內部加載ONNX后其實是做了一個轉換模型的工作,該過程時間長、占用內存巨大。因此不推薦每次初始化都加載ONNX模型,而是加載engine。
2.部署
模型初始化
- 加載yolov5s.engine文件
- 設置輸入輸出緩存
? 輸入大小為13640640
? 輸出大小為125200*85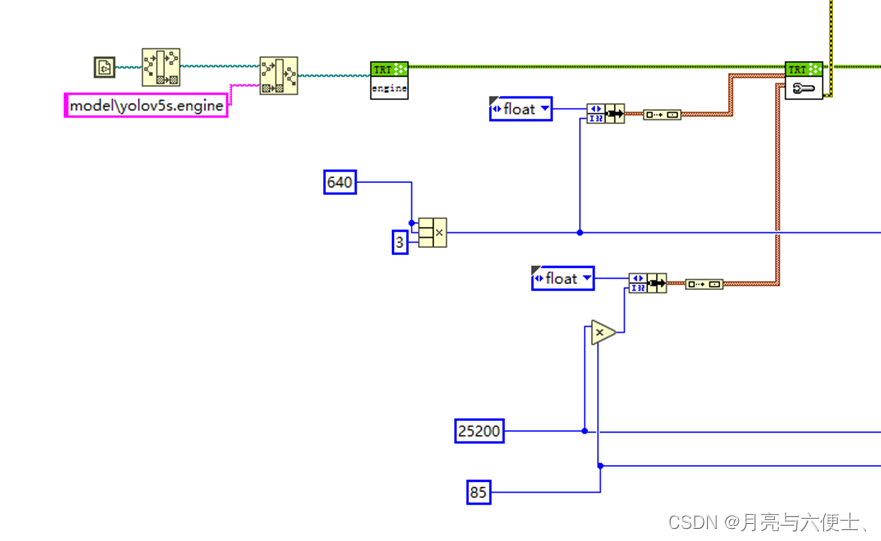
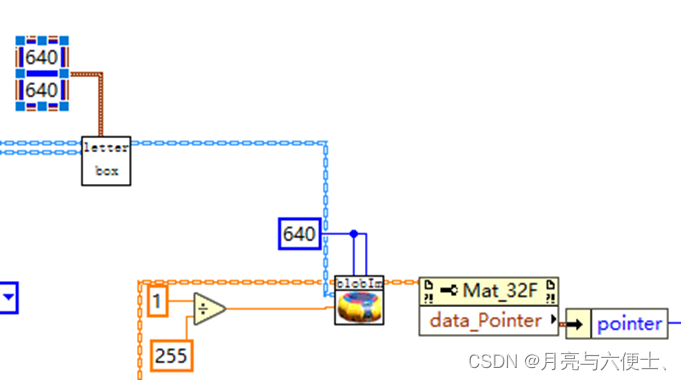
yolov5的預處理
- LetterBox
- blobFromImage,包含如下步驟:
1) img=img/255.0
2) img = img[None] #從(640,640,3)擴充維度至(1,640,640,3)
3) input=img.transpose(0,3,1,2) # BHWC to BCHW

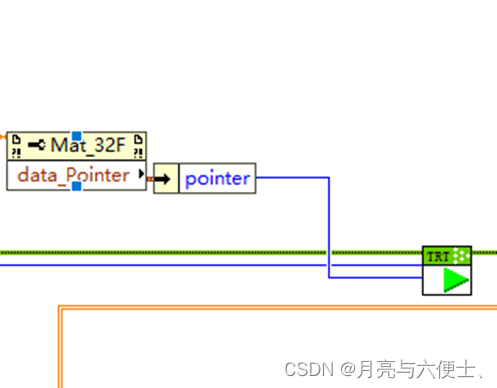
模型推理
- 推薦使用數據指針作為輸入給到run.vi
- 數據的大小為13640*640
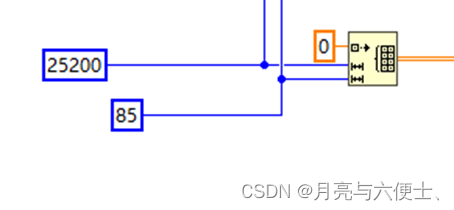
獲取推理結果
- 循環外初始化一個25200*85的二維數組
- 此數組作為Get_Result的輸入,另一個輸入為index=0
- 輸出為25200*85的二維數組結果
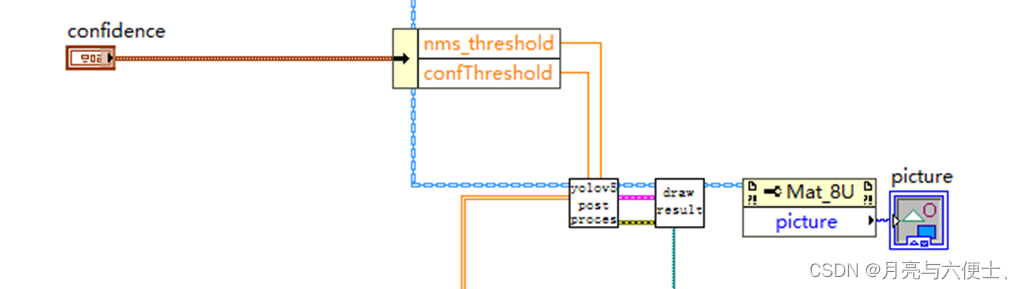
后處理
本范例中,后處理方式和使用onnx一樣
完整源碼
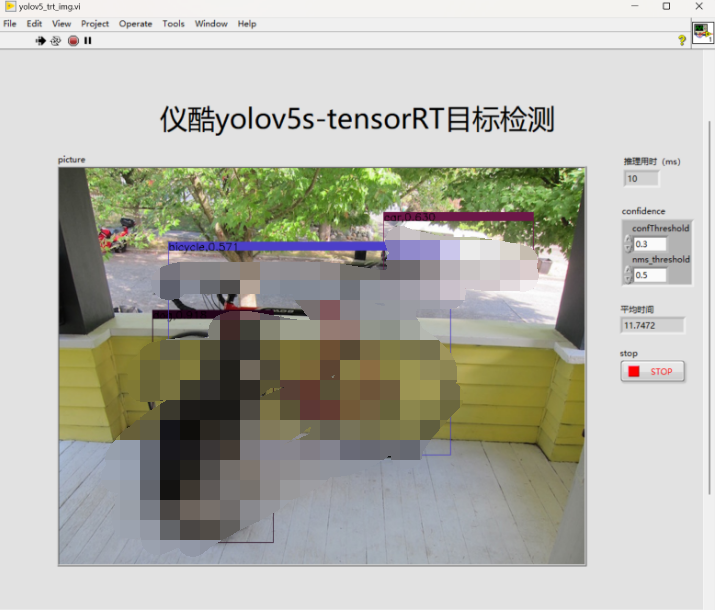
運行結果
項目源碼
源碼下載鏈接:https://pan.baidu.com/s/1y0scJ8tg5nzjJK4iPvNwNQ?pwd=yiku
附加說明
- 操作系統:Windows10
- python:3.6及以上
- LabVIEW:2018及以上 64位版本
- 視覺工具包:techforce_lib_opencv_cpu-1.0.0.98.vip
- LabVIEW TensorRT工具包:virobotics_lib_tensorrt-1.0.0.22.vip
- 運行結果所用顯卡:RTX3060
審核編輯 黃宇
-
LabVIEW
+關注
關注
2017文章
3688瀏覽量
347076 -
機器視覺
+關注
關注
165文章
4798瀏覽量
126045 -
目標檢測
+關注
關注
0文章
233瀏覽量
16492 -
深度學習
+關注
關注
73文章
5598瀏覽量
124396
發布評論請先 登錄
使用ROCm?優化并部署YOLOv8模型
基于瑞芯微RK3576的 yolov5訓練部署教程

在K230中,如何使用AI Demo中的object_detect_yolov8n,YOLOV8多目標檢測模型?
yolov5訓練部署全鏈路教程

在K230上部署yolov5時 出現the array is too big的原因?
labview調用yolov8/11目標檢測、分割、分類
RV1126 yolov8訓練部署教程
RK3576 yolov11-seg訓練部署教程



 工商網監
工商網監
評論