") 機器學習讓存儲器設(shè)計提速N個數(shù)量級
機器學習讓存儲器設(shè)計提速N個數(shù)量級

買電腦時誰不想要個大內(nèi)存呢,其他電子產(chǎn)品的存儲器需求也是如此。大存儲器對于像自動駕駛和智能設(shè)備這類被AI和ML技術(shù)加持的高性能計算應(yīng)用則更加重要,因為它們通常需要實時計算結(jié)果,這個數(shù)據(jù)量可想而知。隨著這類數(shù)據(jù)密集型應(yīng)用日益普及,芯片開發(fā)者需要快速生成衍生設(shè)計和不同版本,才能更好地滿足終端用戶需求。
因此,存儲器件變得容量越來越大,設(shè)計越來越復(fù)雜。在開發(fā)存儲器件時,怎樣做才能既滿足嚴苛的性能、功耗、面積(PPA)目標,又能確保產(chǎn)品按時上市呢?
先進的存儲器設(shè)計需要不一樣的開發(fā)流程
當今的存儲器會更多地采用2.5D/3D結(jié)構(gòu)的multi-die設(shè)計,這類架構(gòu)十分具有挑戰(zhàn)性。
以完整的存儲器陣列為例,在設(shè)計先進的高帶寬(HBM)DRAM或3D NAND閃存芯片時必須要考慮晶粒之間的互連以及電源分配網(wǎng)絡(luò)(PDN),以便針對PPA和硅可靠性進行優(yōu)化。
傳統(tǒng)的存儲器設(shè)計和驗證技術(shù)已經(jīng)無法支持先進的存儲器件設(shè)計了。仿真大型陣列非常耗時,并且由于周轉(zhuǎn)時間過長,會導(dǎo)致產(chǎn)品上市延遲。另外,在流程后期發(fā)現(xiàn)設(shè)計問題時,解決問題需要使用手動迭代循環(huán),還會進一步導(dǎo)致延遲。
存儲器設(shè)計和驗證過程的“前移”是應(yīng)對上述挑戰(zhàn)的唯一方法。存儲器設(shè)計前移讓開發(fā)者們可以更早地執(zhí)行更好的分析,避免流程后期出現(xiàn)意外,并最大限度地減少迭代。
通過前移還可以避免存儲器開發(fā)中影響整體周轉(zhuǎn)時間和上市時間的四個關(guān)鍵瓶頸:宏單元特征提取、模塊設(shè)計優(yōu)化、版圖前到版圖后的仿真差距,以及定制版圖設(shè)計。首先來逐一探討下這四個瓶頸。
AI+ML,打破存儲器設(shè)計瓶頸
瓶頸1:宏單元特征提取
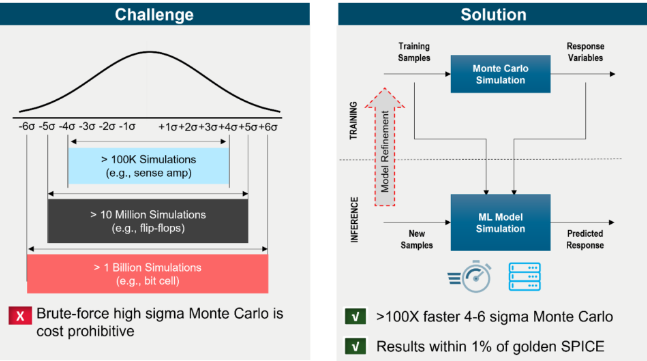
存儲器宏單元特征提取需要蒙特卡洛仿真,但在設(shè)計先進的存儲器時,執(zhí)行詳盡蒙特卡洛仿真所需的時間和資源會大大增加,這使得其成為一個難以實現(xiàn)的解決方案。為了實現(xiàn)高西格瑪特征提取并確保設(shè)計的穩(wěn)健性,需要運行數(shù)十億次的仿真。
機器學習技術(shù)恰好可以在這方面發(fā)揮作用。高精度的設(shè)計替代模型經(jīng)過訓練,能夠預(yù)測高西格瑪電路行為。通過采用該模型,可以顯著減少仿真運行次數(shù)。
根據(jù)公開的案例分析,與傳統(tǒng)方法相比,這種方法可以實現(xiàn)100-1000倍的加速,同時能夠提供精度在1%以內(nèi)的黃金SPICE結(jié)果。
瓶頸2:模塊設(shè)計優(yōu)化
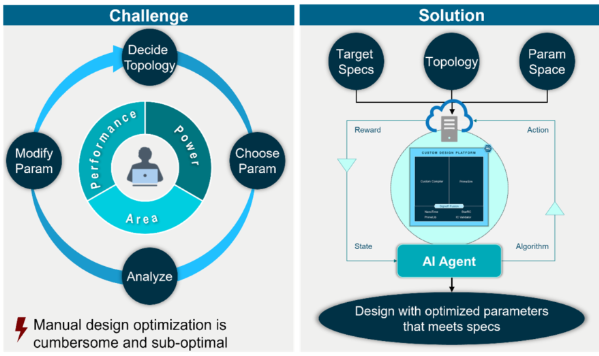
在存儲器設(shè)計項目中,導(dǎo)致周轉(zhuǎn)時間和上市時間延長的主要因素是需要根據(jù)分析結(jié)果來迭代更改設(shè)計。傳統(tǒng)的流程是,先決定拓撲結(jié)構(gòu),再選擇晶體管尺寸和R/C值等設(shè)計參數(shù),接著對設(shè)計進行仿真,然后是檢查輸出。如果結(jié)果不符合項目的PPA目標,則必須調(diào)整參數(shù),重新進行仿真并重新評估結(jié)果。這種手動迭代循環(huán)會占用寶貴的開發(fā)資源并導(dǎo)致進度延誤。
針對這一挑戰(zhàn),如果機器和算法能自動優(yōu)化設(shè)計,情況會怎么樣呢?
近年來,我們已經(jīng)看到設(shè)計空間優(yōu)化作為一個完整的人工智能驅(qū)動工作流程出現(xiàn)在數(shù)字設(shè)計中。人工智能代理能夠自動選擇器件參數(shù),運行仿真,從結(jié)果中學習并進行微調(diào),從而以迭代方式收斂到正確的器件參數(shù)集。
依靠AI驅(qū)動的設(shè)計優(yōu)化,可以顯著減少手動工作,更快地實現(xiàn)設(shè)計目標,速度提升好幾個數(shù)量級。
瓶頸3:版圖前到版圖后的仿真差距
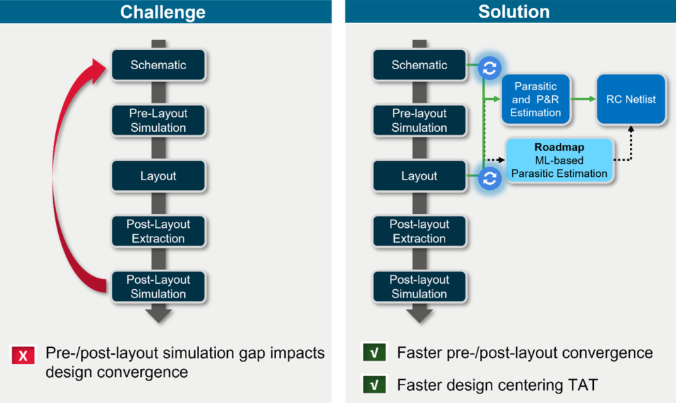
導(dǎo)致周轉(zhuǎn)時間和上市時間延長的另一個主要迭代來源是版圖前到版圖后的仿真差距。開發(fā)者希望在版圖之前盡可能準確地預(yù)先提取寄生參數(shù)對時序、功耗、噪聲和穩(wěn)定性等設(shè)計規(guī)格的影響,從而避免在從版圖中提取寄生參數(shù)時出現(xiàn)意外。不幸的是,在傳統(tǒng)流程中,這些類型的意外很常見,從而導(dǎo)致需要重復(fù)版圖和仿真。
對此,解決辦法是什么呢?
那就是早期寄生效應(yīng)分析工作流程。通過該流程,可以準確地估算預(yù)版圖和部分版圖設(shè)計中的凈寄生參數(shù)。根據(jù)公開的案例分析,通過使用早期寄生效應(yīng)分析工作流程來預(yù)先提取寄生參數(shù),可將設(shè)計中版圖前后的時序差異從20-45%降低到0-20%。
有一項新興技術(shù)在這方面表現(xiàn)出了巨大前景,那就是利用機器學習通過預(yù)測互連寄生效應(yīng)來進一步增強早期寄生效應(yīng)分析工作流程。
瓶頸4:定制版圖
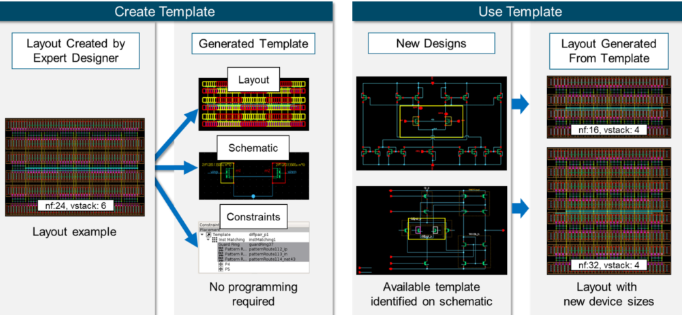
雖然加快存儲器設(shè)計的仿真和分析速度是實現(xiàn)設(shè)計流程前移的重要一環(huán),但是在定制版圖階段也同樣有機會來減少花費的時間和精力。在存儲器設(shè)計中,經(jīng)常會重復(fù)出現(xiàn)相同的子電路拓撲。這樣一來,便可以由專業(yè)開發(fā)者提取布局布線模式來創(chuàng)建成模板,然后其他開發(fā)者可以重復(fù)使用這些現(xiàn)成的模板。初級開發(fā)者可以利用這些模板,根據(jù)所需的任何設(shè)備尺寸創(chuàng)建新的版圖。這樣不僅可以節(jié)省時間,還可以讓初級開發(fā)者從原始版圖所體現(xiàn)的專業(yè)知識和經(jīng)驗中受益。
根據(jù)公開的案例分析,無論開發(fā)者的經(jīng)驗如何,通過創(chuàng)建和使用模板,存儲器中關(guān)鍵模擬電路的版圖周轉(zhuǎn)時間可以縮短50%以上,并且版圖質(zhì)量會更加一致。
機器學習技術(shù)代表著版圖設(shè)計的下一個前沿,能夠?qū)崿F(xiàn)模擬布局布線自動化,并推動版圖效率進一步提高。
實現(xiàn)存儲器開發(fā)前移的最佳方法
新思科技定制設(shè)計系列中提供了上述所有相關(guān)技術(shù),能夠幫助開發(fā)者克服這四個主要的存儲器設(shè)計和驗證瓶頸。
新思科技PrimeSim?連續(xù)電路仿真技術(shù)提供了機器學習驅(qū)動的高西格瑪蒙特卡洛仿真和一致的工作流程,消除了點工具流程中固有的麻煩和不一致。
與新思科技PrimeWave?設(shè)計環(huán)境相結(jié)合,PrimeSim解決方案還能提供早期寄生效應(yīng)分析。此外,新思科技Custom Compiler?設(shè)計和版圖解決方案全面支持基于模板的設(shè)計再利用。
結(jié)語
芯片的每一次更新?lián)Q代,都意味著存儲器設(shè)計和驗證會變得愈加具有挑戰(zhàn)性。新思科技擁有所有相關(guān)技術(shù),助力開發(fā)者們實現(xiàn)存儲器設(shè)計前移,縮短周轉(zhuǎn)和上市時間,并實現(xiàn)開發(fā)者們所期望的PPA。
審核編輯:郭婷
-
存儲器
+關(guān)注
關(guān)注
39文章
7739瀏覽量
171674 -
人工智能
+關(guān)注
關(guān)注
1817文章
50098瀏覽量
265372 -
ML
+關(guān)注
關(guān)注
0文章
154瀏覽量
35476
發(fā)布評論請先 登錄
抗輻射加固封裝國產(chǎn)存儲器的電子輻照試驗
使用Matlab捕獲N9010A跟蹤數(shù)據(jù)縮放了幾個數(shù)量級
請問AD9361跳頻穩(wěn)定時間是一個什么數(shù)量級?
開關(guān)電源的NTC阻值一般是什么數(shù)量級的?
MRAM如何實現(xiàn)對車載MCU中嵌入式存儲器
如何實現(xiàn)處理器的速度跟外圍硬件設(shè)備的速度在一個數(shù)量級上呢
傳感器檢測精度再度提高,檢測精度和分辨率提升了2個數(shù)量級
AI賦能下的當下與未來,人臉識別的準確度已經(jīng)提升了4個數(shù)量級
存儲創(chuàng)新技術(shù)正煥發(fā)著勃勃生機
中國電子系統(tǒng)2天時間建設(shè)蘇州市疫情管控平臺 可同時支持10萬數(shù)量級企業(yè)及1000萬數(shù)量級員工的活動軌跡分析
氣密封裝元器件可靠性要比非氣密封裝高一個數(shù)量級
英偉達已首次實現(xiàn)SDF實時渲染 速度提升2-3個數(shù)量級

兼顧PPA和上市時間,機器學習讓存儲器設(shè)計提速N個數(shù)量級
清華電化學電容新突破,比容量高出電解電容兩個數(shù)量級



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論