 存算一體+Chiplet能否應對AI大算力和高能耗的挑戰?
存算一體+Chiplet能否應對AI大算力和高能耗的挑戰?

01. AI大算力芯片的“出奇”想法
在最近由AspenCore主辦的2023中國IC領袖峰會上,中國半導體行業協會IC設計分會理事長魏少軍教授在《集成電路發展中的“正”與“奇”》的主題演講中提到,中國半導體產業的發展要在“守正”的市場發展道路上穩步前行,同時也需要在新的賽道“出奇”。比如在高性能計算領域,在先進工藝、技術和芯片產品受到外界限制的情況下,我們如何利用國產工藝技術實現創新而跟全球高性能計算和AI發展保持同步甚至超越?更具體一點,就目前炒作火熱的AIGC大模型所需要的大算力AI芯片來說,能否利用我們現在可用的工藝和技術來開發在性能上可以跟英偉達GPGPU對標的AI芯片呢?一些“守正且出奇”的技術包括:軟件定義芯片、chiplet、3D堆疊和先進封裝、存算一體等。
自從OpenAI的ChatGPT于2022年11月推出以來,AIGC迅速在全球掀起一股熱潮。與OpenAI有深度合作的微軟在BING搜索方面有了明顯的收益,谷歌和百度等搜索引擎和互聯網巨頭紛紛發布各自的大語言模型(LLM)。在這些熱潮的背后是GPU芯片的瘋狂購買囤貨,因為訓練LLM需要龐大的算力支持。要支撐這類AI大模型的訓練和基于這些模型的AIGC應用,需要投入數十億美元的資金,同時還需要巨大的電力供應,因為算力強大的GPGPU耗電量也十分驚人。
據統計預測,全球算力需求呈現高速發展態勢。2021年,全球計算設備算力總規模達到615EFLOPS(每秒一百京次(=10^18)浮點運算);到2025年,全球算力規模將達6.8 ZFLOPS( 每秒十萬京(=10^21)次的浮點運算 ),與2020年相比提升30倍;到2030年,有望增至56ZFLOPS。算力翻倍時間在明顯縮短,大模型出現后,帶來了新的算力增長趨勢,平均算力翻倍時間約為9.9個月。
伴隨著算力的提升,數據中心和AI服務器的耗電量也大幅提升。2022年Intel第四代服務器處理器單CPU功耗已突破350瓦,英偉達單GPU芯片功耗突破700瓦,AI集群算力密度普遍達到50kW/柜。根據ChatGPT在使用訪問階段所需算力和耗電費用估計,使用英偉達DGX A100服務器的標準機柜需要542臺(每臺機柜的功率為45.5kw),折算為每日電費大約4.7萬美元。
對國內AI應用企業來說,即便資金不是問題,能否購買到最先進的GPU芯片也是個大問題。即便部署了足夠的GPU和服務器機柜,日常運營的耗電成本也不容小覷。盡管最近兩年有不少國產GPU初創公司發布性能不錯的GPU芯片,但到目前為止還難以跟英偉達的GPU相提并論。面對算力和能耗這兩大挑戰,國產AI芯片公司能否想出“出奇”之道?
02. “存算一體”沖破能耗墻
“存算一體”技術可以解決傳統馮諾伊曼架構處理器所面臨的三堵墻:存儲墻、能耗墻、編譯墻。存算一體架構沒有深度多層級存儲的概念,所有的計算都放在存儲器內實現,這就從根本上消除了因為存算異構帶來的存儲墻及相應的額外開銷;存儲墻的消除可大量減少數據搬運,不但提升了數據傳輸和處理速度,而且能效比得以數倍提升,這意味著支持與傳統架構處理器同等算力所需的功耗可以大大降低;存儲和計算單元之間的調用和數據搬運需要復雜的編程模型,而存算一體的數據狀態都是編譯器可以感知的,因此編譯效率很高,可以繞開傳統架構的編譯墻(生態墻)。
在存算一體這一賽道上,最早是美國的Mythic公司在2010年左右推出了存算一體芯片,國內在2017年左右出現了存算一體技術路徑的創業團隊,到現在為止已有數家,比如知存科技、千芯科技、蘋芯科技、九天睿芯、后摩智能和億鑄科技等。但這些初創公司在存儲器的選擇上出現了三種主要方向,最早從傳統存儲器開始,如Flash,SRAM再到新型憶阻器ReRAM。算力也從微小算力(《1T)、500T到1P的大算力。存算一體最大的優勢在于高能效比,但微小算力場景與大算力場景最大的應用區別是對計算精度要求的滿足及成本。這也決定著這些存算一體初創公司通向了不同的應用場景,比如九天睿芯的芯片產品主要面向小算力的邊緣和端側應用。而ChatGPT等大模型的出現勢必對AI大算力芯片提出新的要求。
基于“存算一體”架構開發的AI芯片在克服能耗挑戰方面有很大的潛力,但如何實現高性能和大算力呢?
存算一體+chiplet也許是一種可行的“出奇”之道。
03. ReRAM:材料、工藝和AI應用潛力
在傳統馮諾依曼計算架構中,占據主要地位的DRAM和Flash等傳統存儲技術面臨技術瓶頸,面對低功耗和高性能的需求,無法實現根本性的改善,而新型存儲技術成為業界重點布局與探索的方向。經過10多年的努力,MRAM(磁性存儲器)、PCRAM(相變存儲器)、FRAM(鐵電存儲器)和ReRAM(阻變存儲器)等新型存儲技術也逐步走出實驗室,進入試用甚至商用階段。
ReRAM(阻變存儲器,或憶阻器)是以非導性材料的電阻在外加電場作用下,在高阻態和低阻態之間實現可逆轉換為基礎的非易失性存儲器。ReRAM包括許多不同的技術類別,比如氧空穴存儲器(OxRAM)、導通橋聯存儲器(CBRAM)等。ReRAM的單元面積極小,可做到4F2,讀寫速度是NAND Flash的1000倍,同時功耗可降低10倍以上。
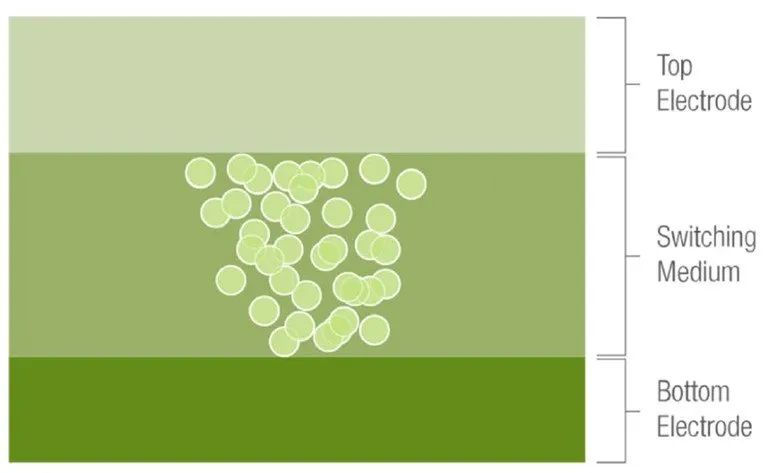
導通橋聯CBRAM基本結構。(來源:Crossbar)
由于電阻切換機制基于金屬導絲,Crossbar ReRAM(CBRAM)單元非常穩定,能夠承受從-40°C到125°C的溫度波動,寫周期為1M+,在85°C的溫度下可保存10年。從密度、能效比、成本、工藝制程和良率各方面綜合衡量,ReRAM存儲器在目前已有的新型存儲器中具備明顯優勢。
基于導通橋聯的ReRAM具有高達1000倍的低/高阻態差異,使其不易受外界運行環境的干擾影響,具有很強的穩定性。同時,以ReRAM組成的存算陣列單元因為阻態區分度大,所實現的存內計算可以更好地滿足大算力應用場景對算力、精度、能效比和可靠性的嚴格要求。
ReRAM以其密度增長空間大、生產工藝與CMOS兼容等優勢,吸引了國內外眾多IP技術企業、大型晶圓代工廠、傳統存儲企業和半導體初創企業投入到其商業化進程中。目前,臺積電、聯電、Crossbar、昕原半導體、松下、東芝、索尼、美光、海力士和富士通等廠商都在積極開展ReRAM技術的研究和產業化推進。國內新型存儲器ReRAM的生產工藝及產線已經實現了規模化量產商用。
基于ReRAM工藝的芯片主要用于存儲和存算一體兩個方面,其中采用”存算一體“結構和技術的AI芯片將有可能實現AI大算力突破,成為可以應對AIGC大算力挑戰的GPGPU有力競爭者,有望在AIoT、智能汽車、數據中心和高性能計算等方面獲得廣泛的應用。存算一體AI芯片初創公司億鑄科技基于憶阻器這種新型存儲器件,創新性地采用全數字化的實現方式,將存算一體架構應用于AI大算力芯片,從而讓存算一體真正在高精度、大算力AI方向實現商用落地。
04. 存算一體+Chiplet助力AI算力第二增長曲線
由于AI模型規模不斷擴大,用于深度學習的存內計算 (IMC) 單芯片方案在芯片面積、良率和片上互連成本等方面面臨著巨大挑戰。存算一體AI芯片能否借助芯粒(chiplet)和2.5D/3D堆疊封裝技術實現異構集成,從而形成大型計算系統,提供超越單一架構IMC芯片的大型深度學習模型訓練和推理方案?
美國亞利桑那州立大學的學者于2021年發布了一種基于chiplet 的IMC架構基準測試仿真器SIAM,用于評估這種新型架構在AI大模型訓練上的潛力。SIAM集成了器件、電路、架構、片上網絡(NoC)、封裝網絡(NoP)和DRAM訪問模型,以實現一種端到端的高性能計算系統。SIAM 在支持深度神經網絡 (DNN) 方面具有可擴展性,可針對各種網絡結構和配置進行定制。其研究團隊通過使用 CIFAR-10、CIFAR-100 和 ImageNet 數據集對不同的先進DNN進行基準測試來展示SIAM的靈活性、可擴展性和仿真速度。據稱,相對于英偉達V100和T4 GPU,通過SIAM獲得的chiplet +IMC架構顯示ResNet-50在ImageNet數據集上的能效分別提高了130和72。
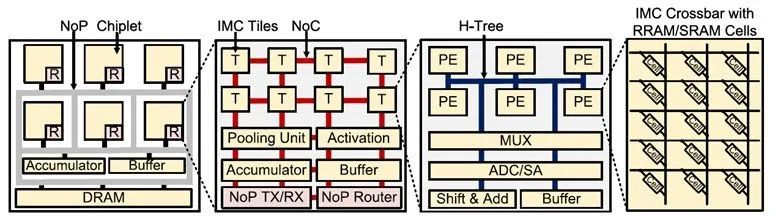
SIAM采用基于chiplet的 IMC 架構。(來源:SIAM/GOKUL KRISHNAN)
上圖顯示了SIAM使用的基于同構chiplet的IMC架構。整個架構由一系列chiplet組成,其中包括IMC計算單元、全局累加器、全局緩沖區和DRAM。Chiplet陣列利用封裝上網絡(NoP)實現互聯。SIAM支持基于SRAM或RRAM的IMC Crossbar存算單元,這些存算單元陣列組成處理元素(PE);PE陣列又構成IMC Tile陣列,然后構成IMC chiplet。
盡管SIAM仿真器僅針對同質架構或定制架構,但為異構集成實現的存算一體+Chiplet架構提供了很有價值的設計思路。就存算一體、Chiplet和2.5D/3D先進封裝技術的發展而言,國內廠商跟國外同行基本處于同一起跑線上。在兼容CMOS的國產ReRAM工藝上,通過Chiplet和先進封裝集成IMC單元、GPU和CPU等不同工藝節點的處理單元,來實現大算力AI芯片以應對算力和功耗的挑戰,看來是可行的。
有業界專家總結出AI算力增長的階段性曲線,自2018年至今的GPGPU和AI芯片算力增長屬于第一增長曲線階段。這一階段的參與者有英偉達和AMD等國際GPU巨頭,也有眾多國內廠商參與其中,包括百度昆侖芯、華為海思、天數智芯、寒武紀和壁仞科技等。這些公司所采用的晶圓工藝從14nm到5nm不等;算力從130T到485T;功耗從70W到150W。這一階段的AI芯片的共同點在于都是采用傳統的處理器架構,伴隨著算力的提升,功耗和成本也隨之上升。工藝節點到了5nm,一顆芯片的研發成本以億美元計算,不是每一家公司都能夠支撐得起的。即便有這個實力可以繼續支撐下去,但算力與功耗的矛盾也是難以解決的,因為處理器架構在本質上決定了其局限性。
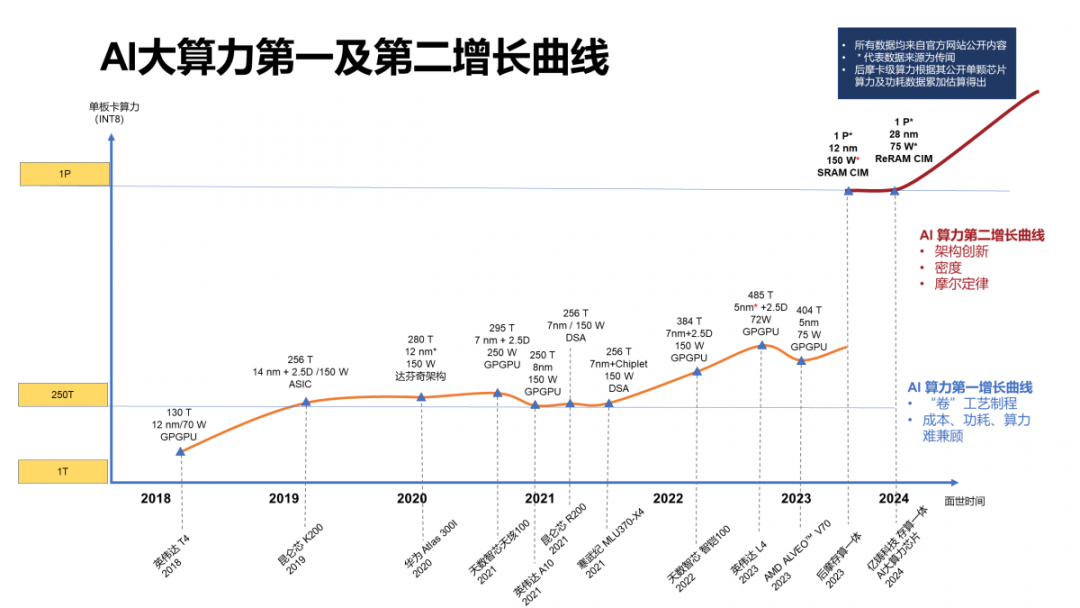
對于國內廠商來說,要在成熟工藝上以低成本實現500T以上的算力,就必須采用“出奇“的架構。存算一體+chiplet組合似乎是一種可行的實現方式,據稱億鑄科技正在這條路上探索,其第一代存算一體AI大算力商用芯片可實現單卡算力500T以上,功耗在75W以內。也許這將開啟AI算力第二增長曲線的序幕。
審核編輯 :李倩
-
芯片
+關注
關注
463文章
54256瀏覽量
468258 -
集成電路
+關注
關注
5461文章
12636瀏覽量
375395 -
AI
+關注
關注
91文章
40616瀏覽量
302286 -
chiplet
+關注
關注
6文章
499瀏覽量
13634
原文標題:存算一體+Chiplet能否應對AI大算力和高能耗的挑戰?
文章出處:【微信號:算力基建,微信公眾號:算力基建】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
ReRAM存算一體AI大算力芯片的獨特優勢









 工商網監
工商網監
評論