") Meta開源ImageBind新模型,超越GPT-4,對齊文本、音頻等6種模態(tài)!
Meta開源ImageBind新模型,超越GPT-4,對齊文本、音頻等6種模態(tài)!

據(jù)外媒報(bào)道,上周四,Google、微軟、OpenAI 幾家公司的 CEO 受邀去白宮,共論關(guān)于人工智能發(fā)展的一些重要問題。然而,讓人有些想不通的是,深耕 AI 多年的 Meta 公司(前身為 Facebook)卻沒有在受邀之列。
沒多久,更讓 Meta CEO 扎克伯格扎心的是,一位官員對此解釋稱,本次會議“側(cè)重的是目前在 AI 領(lǐng)域,尤其是面向消費(fèi)者的產(chǎn)品方面,處于領(lǐng)先地位的公司。”
顯然對于這樣的解釋,并不能讓人信服,畢竟這一次受邀名單中還有一家由 OpenAI 的前成員創(chuàng)立的美國人工智能初創(chuàng)和公益公司 Anthropic。
似乎是為了出一口“氣”,也為證明自家的實(shí)力,相比 OpenAI、Google 推出閉源的 GPT-4、Bard 模型,Meta 在開源大模型的路上一騎絕塵,繼兩個(gè)月前開源 LLaMA大模型之后,再次于5 月 9 日開源了一個(gè)新的 AI 模型——ImageBind(https://github.com/facebookresearch/ImageBind),短短一天時(shí)間,收獲了 1.6k 個(gè) Star。
這個(gè)模型與眾不同之處便是可以將多個(gè)數(shù)據(jù)流連接在一起,包括文本、圖像/視頻和音頻、視覺、IMU、熱數(shù)據(jù)和深度(Depth)數(shù)據(jù)。這也是業(yè)界第一個(gè)能夠整合六種類型數(shù)據(jù)的模型。
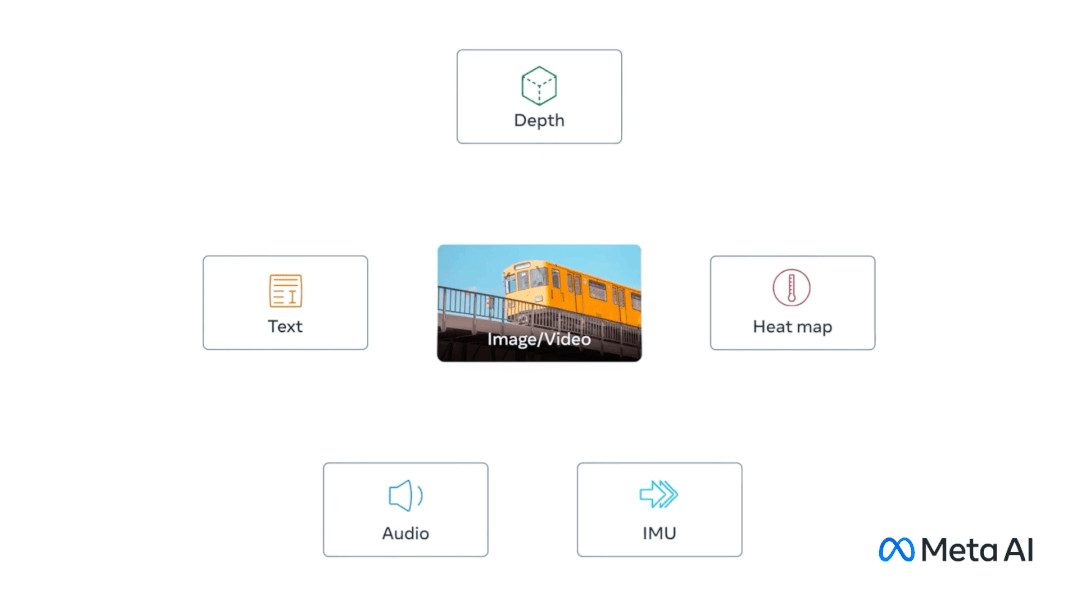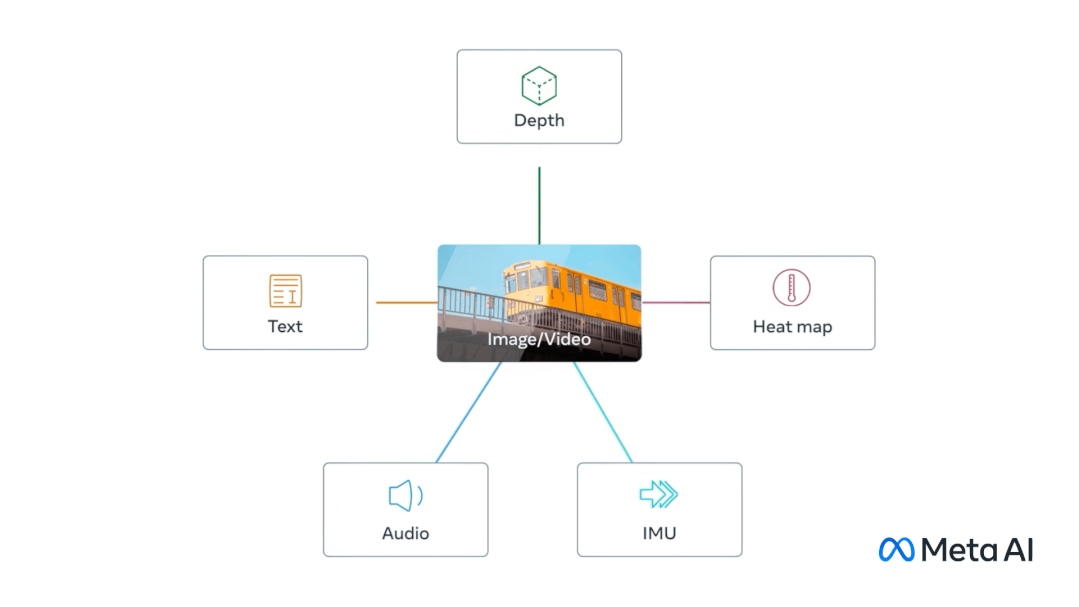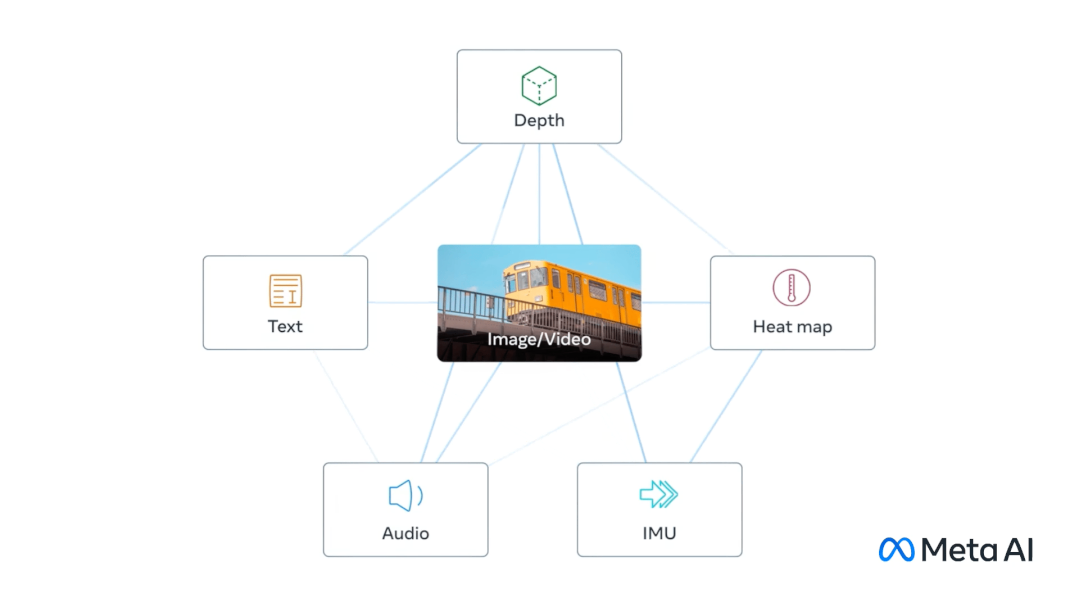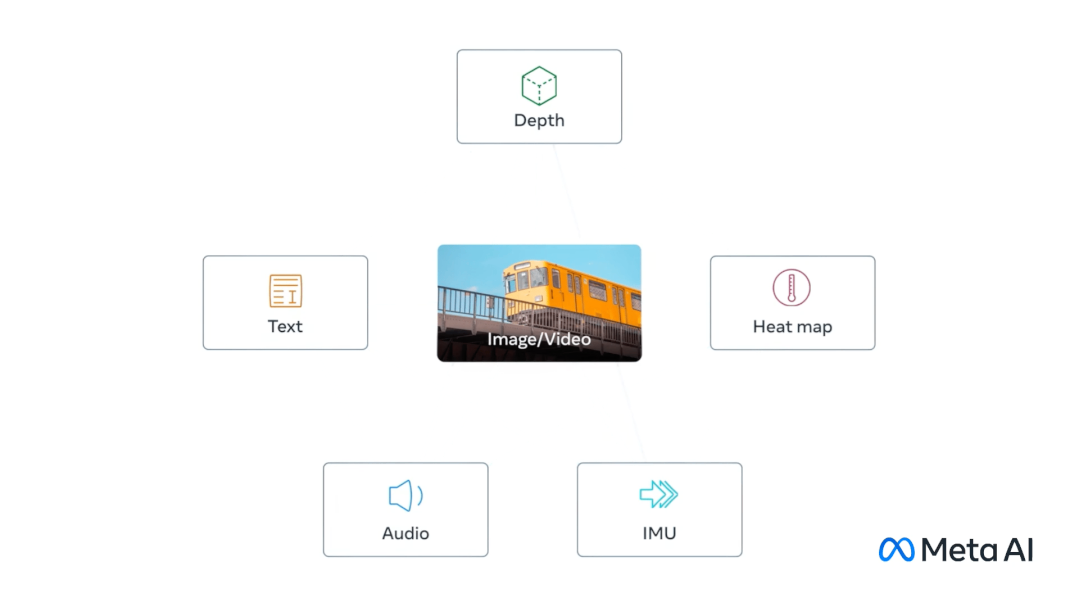

ImageBind 用圖像對齊六模態(tài),旨在實(shí)現(xiàn)感官大一統(tǒng)
簡單來看,相比 Midjourney、Stable Diffusion 和 DALL-E 2 這樣將文字與圖像配對的圖像生成器,ImageBind 更像是廣撒網(wǎng),可以連接文本、圖像/視頻、音頻、3D 測量(深度)、溫度數(shù)據(jù)(熱)和運(yùn)動數(shù)據(jù)(來自 IMU),而且它無需先針對每一種可能性進(jìn)行訓(xùn)練,直接預(yù)測數(shù)據(jù)之間的聯(lián)系,類似于人類感知或者想象環(huán)境的方式。

對此,Meta 在其官方博客中也說道,“ImageBind 可以勝過之前為一種特定模式單獨(dú)訓(xùn)練的技術(shù)模型。但最重要的是,它能使機(jī)器更好地一起分析許多不同形式的信息,從而有助于推進(jìn)人工智能。”
打個(gè)比喻,人類可以聽或者閱讀一些關(guān)于描述某個(gè)動物的文本,然后在現(xiàn)實(shí)生活中看到就能認(rèn)識。
你站在繁忙的城市街道等有刺激性環(huán)境中,你的大腦會(很大程度上應(yīng)該是無意識地)吸收景象、聲音和其他感官體驗(yàn),以此推斷有關(guān)來往的汽車、行人、高樓、天氣等信息。
在很多場景中,一個(gè)單一的聯(lián)合嵌入空間包含許多不同種類的數(shù)據(jù),如聲音、圖像、視頻等等。
如今,基于 ImageBind 這樣的模型可以讓機(jī)器學(xué)習(xí)更接近人類學(xué)習(xí)。
在官方博客中,Meta 分享 ImageBind 是通過圖像的綁定屬性,只要將每個(gè)模態(tài)的嵌入與圖像嵌入對齊,即圖像與各種模式共存,可以作為連接這些模式的橋梁,例如利用網(wǎng)絡(luò)數(shù)據(jù)將文本與圖像連接起來,或者利用從帶有 IMU 傳感器的可穿戴相機(jī)中捕獲的視頻數(shù)據(jù)將運(yùn)動與視頻連接起來。

ImageBind 整體概覽
從大規(guī)模網(wǎng)絡(luò)數(shù)據(jù)中學(xué)到的視覺表征可以作為目標(biāo)來學(xué)習(xí)不同模態(tài)的特征。這使得 ImageBind 能夠?qū)R與圖像共同出現(xiàn)的任何模式,自然地將這些模式相互對齊。與圖像有強(qiáng)烈關(guān)聯(lián)的模態(tài),如熱學(xué)和深度,更容易對齊。非視覺的模態(tài),如音頻和 IMU,具有較弱的關(guān)聯(lián)性。
ImageBind 顯示,圖像配對數(shù)據(jù)足以將這六種模式綁定在一起。該模型可以更全面地解釋內(nèi)容,使不同的模式可以相互 "對話",并在不觀察它們的情況下找到聯(lián)系。
例如,ImageBind 可以在沒有看到它們在一起的情況下將音頻和文本聯(lián)系起來。這使得其他模型能夠 "理解 "新的模式,而不需要任何資源密集型的訓(xùn)練。

不過,該模型目前只是一個(gè)研究項(xiàng)目,沒有直接的消費(fèi)者和實(shí)際應(yīng)用,但是它展現(xiàn)了生成式 AI 在未來能夠生成沉浸式、多感官內(nèi)容的方式,也表明了 Meta 正在以與 OpenAI、Google 等競爭對手不同的方式,趟出一條屬于開源大模型的路。

ImageBind 強(qiáng)大的背后
與此同時(shí),作為一種多模態(tài)的模型,ImageBind 還加入了 Meta近期開源的一系列 AI 工具,包括DINOv2計(jì)算機(jī)視覺模型,這是一種不需要微調(diào)訓(xùn)練高性能計(jì)算機(jī)視覺模型的新方法;以及 Segment Anything(SAM),這是一種通用分割模型,可以根據(jù)任何用戶的提示,對任何圖像中的任何物體進(jìn)行分割。
ImageBind 是對這些模型的補(bǔ)充,因?yàn)樗鼘W⒂诙嗄B(tài)表示學(xué)習(xí)。它試圖為多種模式學(xué)習(xí)提供一個(gè)統(tǒng)一的特征空間,包括但不限于圖像和視頻。在未來, ImageBind 可以利用 DINOv2 的強(qiáng)大視覺特征來進(jìn)一步提高其能力。

ImageBind 的性能
針對 ImageBind 性能,Meta 研究科學(xué)家還發(fā)布了一篇《IMAGEBIND: One Embedding Space To Bind Them All》(https://dl.fbaipublicfiles.com/imagebind/imagebind_final.pdf)論文,分享了技術(shù)細(xì)則。

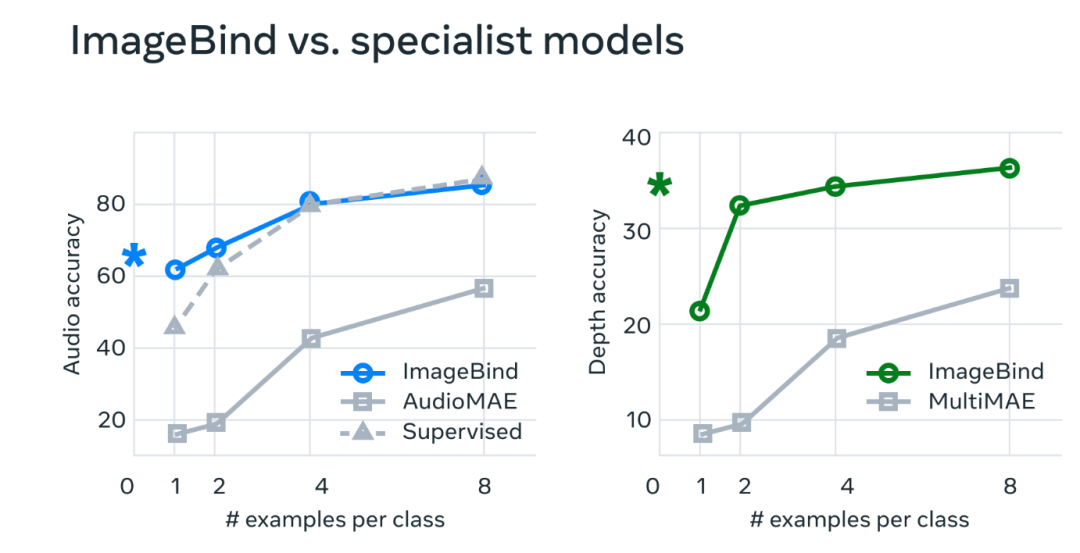
通過分析表明,ImageBind 模型的性能實(shí)際上可以通過使用很少的訓(xùn)練實(shí)例來提高。這個(gè)模型有新的出現(xiàn)的能力,或者說是擴(kuò)展行為--也就是說,在較小的模型中不存在的能力,但在較大的版本中出現(xiàn)。這可能包括識別哪種音頻適合某張圖片或從照片中預(yù)測場景的深度。
而 ImageBind 的縮放行為隨著圖像編碼器的強(qiáng)度而提高。
換句話說,ImageBind 對準(zhǔn)各種模式的能力隨著視覺模型的強(qiáng)度和大小而增加。這表明,較大的視覺模型有利于非視覺任務(wù),如音頻分類,而且訓(xùn)練這種模型的好處超出了計(jì)算機(jī)視覺任務(wù)。
在實(shí)驗(yàn)中,研究人員使用了 ImageBind 的音頻和深度編碼器,并將其與之前在 zero-shot 檢索以及音頻和深度分類任務(wù)中的工作進(jìn)行了比較。
結(jié)果顯示,ImageBind 可以用于少量樣本的音頻和深度分類任務(wù),并且優(yōu)于之前定制的方法。
最終,Meta 認(rèn)為ImageBind 這項(xiàng)技術(shù)最終會超越目前的六種“感官”,其在博客上說道,“雖然我們在當(dāng)前的研究中探索了六種模式,但我們相信引入連接盡可能多的感官的新模式——如觸覺、語音、嗅覺和大腦 fMRI 信號——將使更豐富的以人為中心的人工智能模型成為可能。”

ImageBind 可以用來干什么?
如果說 ChatGPT 可以充當(dāng)搜索引擎、問答社區(qū),Midjourney 可以被用來當(dāng)畫畫工具,那么用 ImageBind 可以做什么?
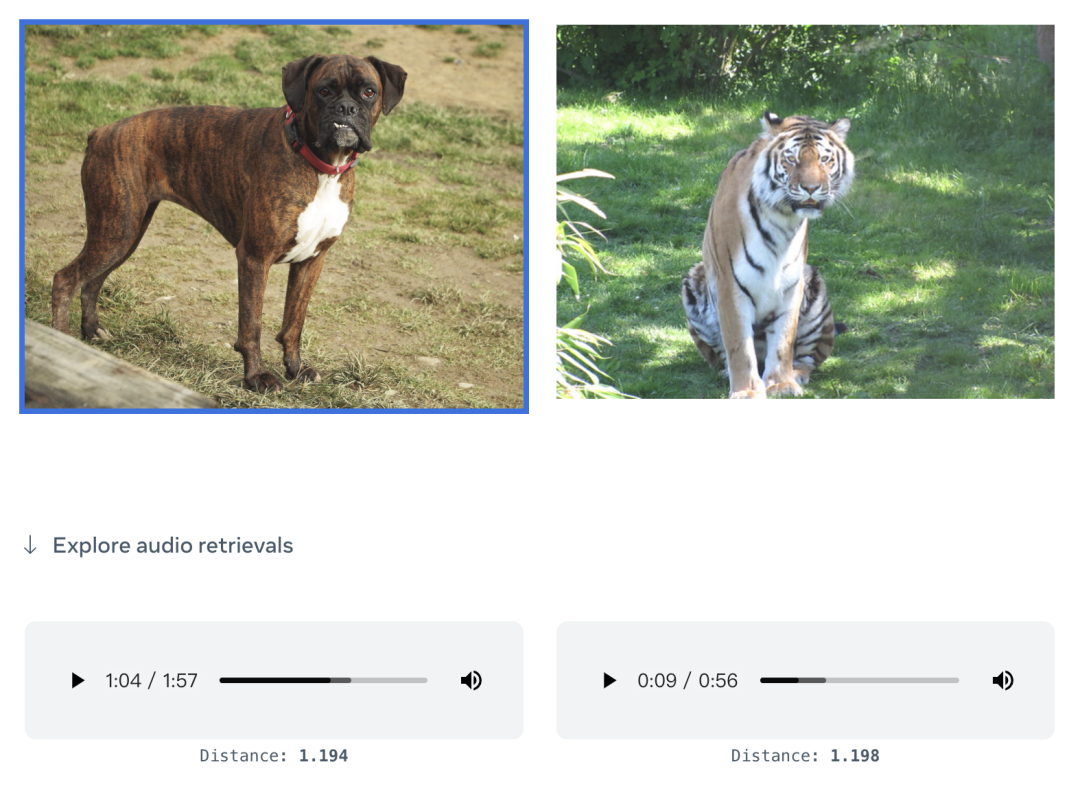
根據(jù)官方發(fā)布的 Demo 顯示,它可以直接用圖片生成音頻:
也可以音頻生成圖片:
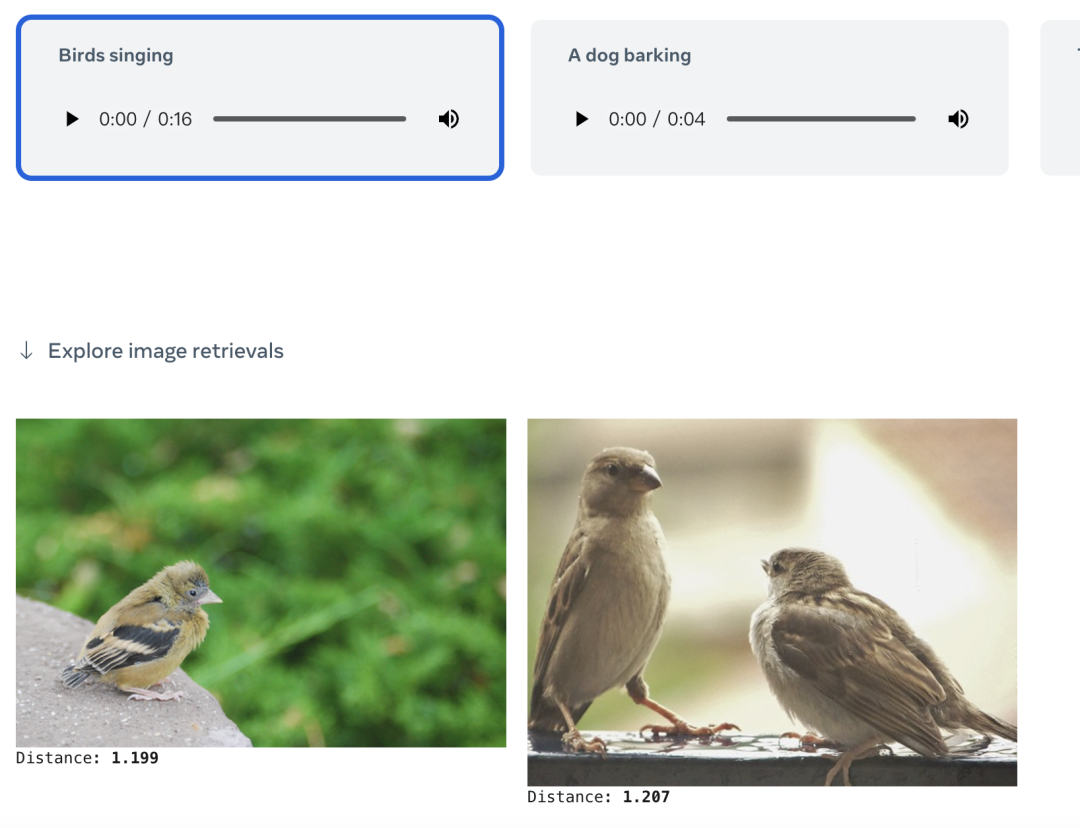
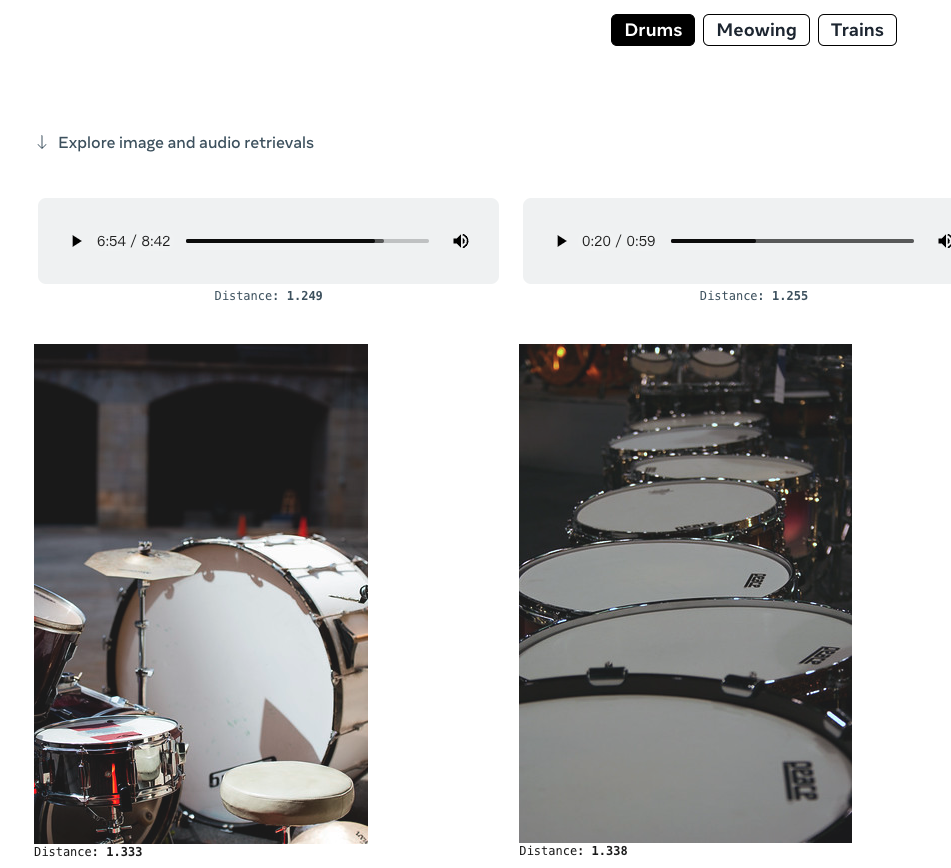
亦或者直接給一個(gè)文本,就可以檢索相關(guān)的圖片或者音頻內(nèi)容:
當(dāng)然,基于 ImageBind 也可以給出一個(gè)音頻+一張圖,如“狗叫聲”+海景圖:
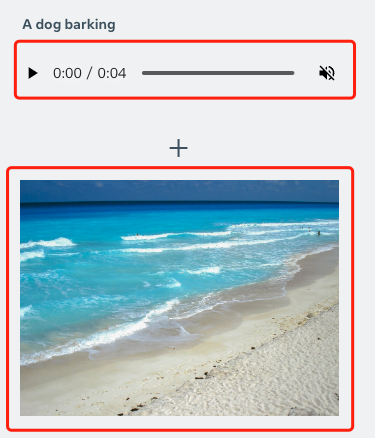
可以直接得到一張“狗在看海”的圖:

也可以給出音頻,生成相應(yīng)的圖像:
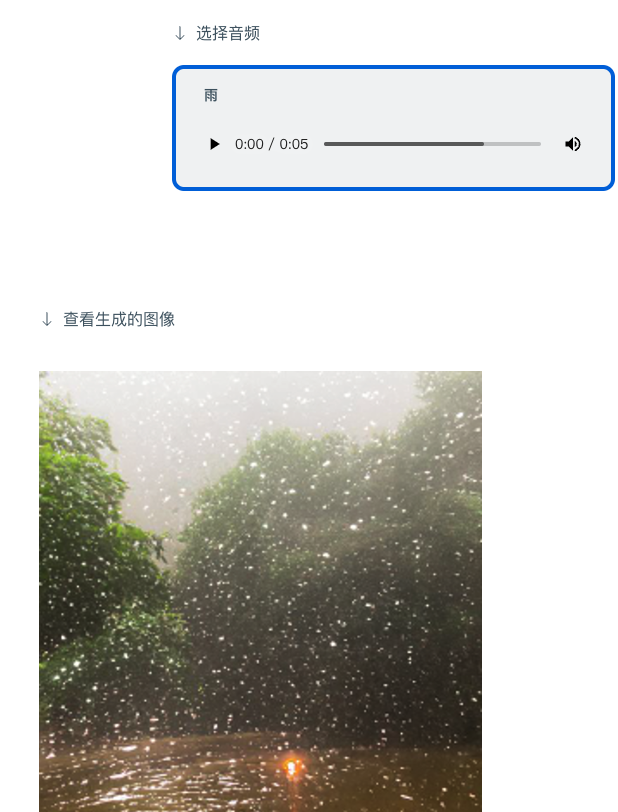
正如上文所述, ImageBind 給出了未來生成式 AI 系統(tǒng)可以以多模態(tài)呈現(xiàn)的方式,同時(shí),結(jié)合 Meta 內(nèi)部的虛擬現(xiàn)實(shí)、混合現(xiàn)實(shí)和元宇宙等技術(shù)和場景結(jié)合。
可以想象一下未來的頭顯設(shè)備,它不僅可以生成音頻和視頻輸入,也可以生成物理舞臺上的環(huán)境和運(yùn)動,即可以動態(tài)構(gòu)建 3D 場景(包括聲音、運(yùn)動等)。
亦或者,虛擬游戲開發(fā)人員也許最終可以使用它來減少設(shè)計(jì)過程中的大量跑腿工作。
同樣,內(nèi)容創(chuàng)作者可以僅基于文本、圖像或音頻輸入制作具有逼真的音頻和動作的沉浸式視頻。
也很容易想象,用 ImageBind 這樣的工具會在無障礙空間打開新的大門,譬如,生成實(shí)時(shí)多媒體描述來幫助有視力或聽力障礙的人更好地感知他們的直接環(huán)境。
“在典型的人工智能系統(tǒng)中,每個(gè)模態(tài)都有特定的嵌入(即可以表示數(shù)據(jù)及其在機(jī)器學(xué)習(xí)中的關(guān)系的數(shù)字向量),”Meta 說。“ImageBind 表明可以跨多種模態(tài)創(chuàng)建聯(lián)合嵌入空間,而無需使用每種不同模態(tài)組合對數(shù)據(jù)進(jìn)行訓(xùn)練。這很重要,因?yàn)檠芯咳藛T無法創(chuàng)建包含例如來自繁忙城市街道的音頻數(shù)據(jù)和熱數(shù)據(jù),或深度數(shù)據(jù)和海邊文本描述的樣本的數(shù)據(jù)集。”
當(dāng)前,外界可以通過大約 30 行 Python 代碼就能使用這個(gè)多模式嵌入 API:


開源大模型是好事還是壞事?
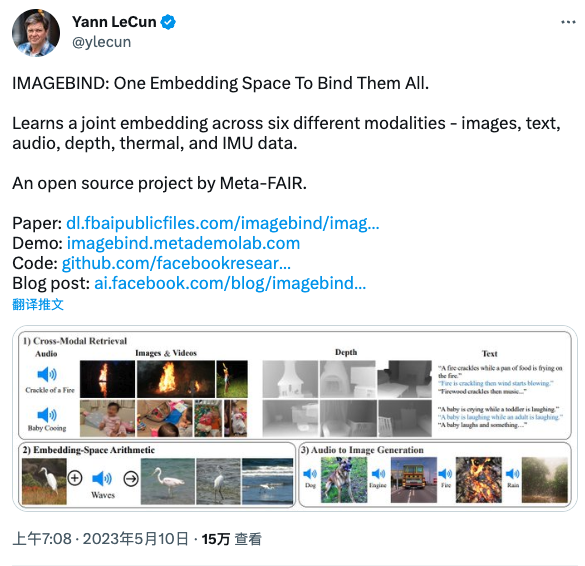
ImageBind 一經(jīng)官宣,也吸引了很多 AI 專家的關(guān)注。如卷積網(wǎng)絡(luò)之父 Yann LeCun 也在第一時(shí)間分享了關(guān)于 ImageBind 的資料:
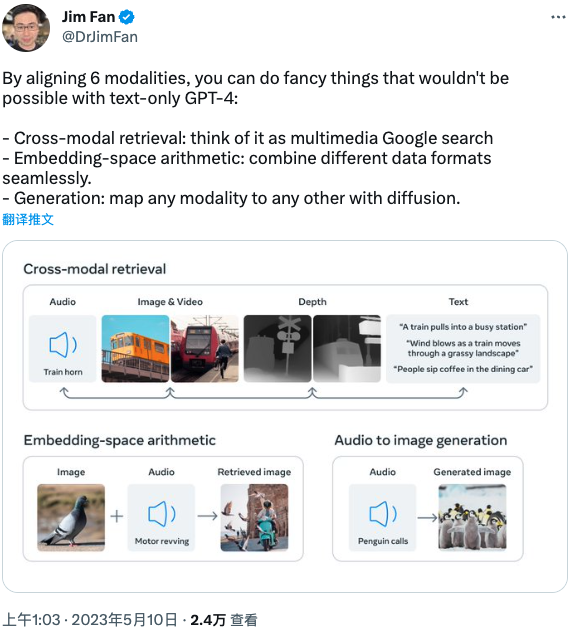
NVIDIA AI 科學(xué)家 Jim Fan 在 Twitter 上表示:
自從 LLaMA 以來,Meta 就在開源領(lǐng)域大放異彩。
ImageBind:Meta 最新的多模態(tài)嵌入,不僅涵蓋了常規(guī)數(shù)據(jù)類型(文本、圖像、音頻),還包括深度、熱量(紅外)和 IMU 信號!
OpenAI Embedding 是 AI 驅(qū)動搜索和長期記憶的基礎(chǔ)。ImageBind 是 Meta 的 Embedding API,用于豐富的多媒體搜索、虛擬現(xiàn)實(shí)甚至機(jī)器人技術(shù)。元宇宙將建立在向量的基礎(chǔ)上。
通過對齊 6 種模態(tài),你可以實(shí)現(xiàn)一些僅靠文本的 GPT-4 無法實(shí)現(xiàn)的花式功能:
跨模態(tài)檢索:將其視為多媒體谷歌搜索
嵌入空間算術(shù):無縫地組合不同的數(shù)據(jù)格式。
生成:通過擴(kuò)散將任何模態(tài)映射到其他任何模態(tài)。
當(dāng)然,這種通用的多模態(tài)嵌入在性能上優(yōu)于領(lǐng)域特定的特征。
ImageBind:將它們?nèi)拷壎ǖ揭粋€(gè)嵌入空間。
也有網(wǎng)友評價(jià)道,「這項(xiàng)創(chuàng)新為增強(qiáng)搜索、沉浸式 VR 體驗(yàn)和高級機(jī)器人技術(shù)鋪平了道路。對于 AI 愛好者和專業(yè)人士來說,激動人心的時(shí)刻即將到來!」。

不過,對于 Meta 采取開源的做法,也有人提出了質(zhì)疑。
據(jù) The Verge 報(bào)道,那些反對開源的人,如 OpenAI,表示這種做法對創(chuàng)作者有害,因?yàn)楦偁帉κ挚梢詮?fù)制他們的作品,并且可能具有潛在的危險(xiǎn),允許惡意行為者利用最先進(jìn)的人工智能模型。
與之形成對比的是,支持開源的人則認(rèn)為,像 Meta 開源 ImageBind 的做法有利于生態(tài)的快速建立與發(fā)展,也能集結(jié)全球的力量,幫助 AI 模型快速迭代和捕捉 Bug。
早些時(shí)候,Meta開源的LLaMA 模型只能用于研究用途,但是期間LLaMA 模型在 4chan 上被泄露,有匿名用戶通過 BT 種子公開了 LLaMA-65B—— 有650 億個(gè)參數(shù)的 LLaMA,容量為 220GB。
隨著 LLaMA “被公開”,一大批基于這款大模型的衍生品,號稱是 ChatGPT 開源替代品的工具在短時(shí)間內(nèi)快速涌現(xiàn),如跟著LLaMA(美洲駝)名字走的“駝類”家族包含了:斯坦福大學(xué)發(fā)布的Alpaca(羊駝,https://github.com/tatsu-lab/stanford_alpaca),伯克利、卡內(nèi)基梅隆大學(xué)等高校研究人員開源的Vicuna(駱馬),還有基于 LLaMA 7B 的多語言指令跟隨語言模型 Guanaco(原駝,https://guanaco-model.github.io/)等等。
面對這股新興的力量,近日,在一位谷歌內(nèi)部的研究人員泄露的一份文件中顯示,在大模型時(shí)代,「Google 沒有護(hù)城河,OpenAI 也沒有」。其主要原因就是第三股——開源大模型的力量與生態(tài)正在崛起。
所以,OpenAI 和 Google 兩家在 AI 大模型上你追我趕的競爭中,誰能笑到最后,也未必就不會是 Meta,我們也將拭目以待。對此,你是否看好開源大模型的發(fā)展?
審核編輯 :李倩
-
開源
+關(guān)注
關(guān)注
3文章
4209瀏覽量
46169 -
模型
+關(guān)注
關(guān)注
1文章
3755瀏覽量
52121 -
Meta
+關(guān)注
關(guān)注
0文章
322瀏覽量
12461
原文標(biāo)題:Meta 開源 ImageBind 新模型,超越 GPT-4,對齊文本、音頻等 6 種模態(tài)!
文章出處:【微信號:AI科技大本營,微信公眾號:AI科技大本營】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
眾智FlagOS適配面壁智能開源全模態(tài)大模型MiniCPM-o 4.5

商湯科技正式開源多模態(tài)自主推理模型SenseNova-MARS

商湯開源SenseNova-MARS:突破多模態(tài)搜索推理天花板

商湯科技正式發(fā)布并開源全新多模態(tài)模型架構(gòu)NEO

格靈深瞳多模態(tài)大模型Glint-ME讓圖文互搜更精準(zhǔn)

亞馬遜云科技上線Amazon Nova多模態(tài)嵌入模型

商湯日日新V6.5多模態(tài)大模型登頂全球權(quán)威榜單
成都匯陽投資關(guān)于大模型白熱化,應(yīng)用加速分化
淺析多模態(tài)標(biāo)注對大模型應(yīng)用落地的重要性與標(biāo)注實(shí)例
基于米爾瑞芯微RK3576開發(fā)板的Qwen2-VL-3B模型NPU多模態(tài)部署評測
訊飛星辰MaaS平臺率先上線OpenAI最新開源模型
【「DeepSeek 核心技術(shù)揭秘」閱讀體驗(yàn)】書籍介紹+第一章讀后心得
今日看點(diǎn)丨臺積電、Intel合資運(yùn)營代工業(yè)務(wù);韓國計(jì)劃向當(dāng)?shù)仄囆袠I(yè)注入3萬億韓元援助
?VLM(視覺語言模型)?詳細(xì)解析




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論