 從Elasticsearch到Apache Doris,10倍性價比的新一代日志存儲分析平臺
從Elasticsearch到Apache Doris,10倍性價比的新一代日志存儲分析平臺

本文導讀
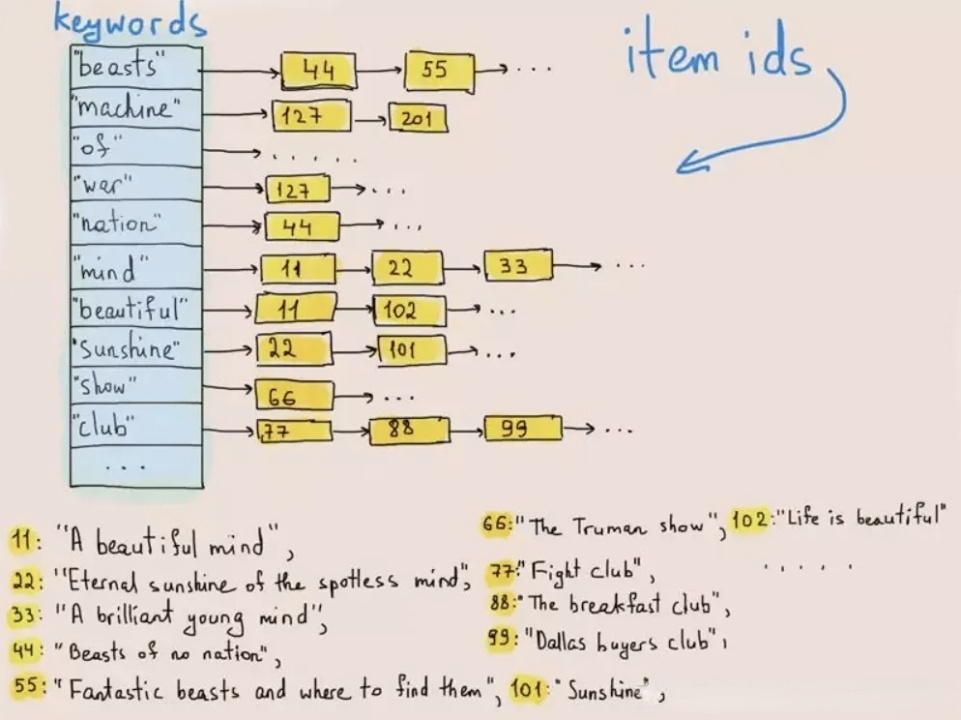
 ES 在日志場景的優勢在于全文檢索能力,能快速從海量日志中檢索出匹配關鍵字的日志,其底層核心技術是倒排索引(Inverted Index)。倒排索引是一種用于快速查找文檔中包含特定單詞或短語的數據結構,最早應用于信息檢索領域。如下圖所示,在數據寫入時,倒排索引可以將每一行文本進行分詞,變成一個個詞(Term),然后構建詞(Term) -> 行號列表(Posting List) 的映射關系,將映射關系按照詞進行排序存儲。當需要查詢某個詞在哪些行出現的時候,先在 詞 -> 行號列表 的有序映射關系中查找詞對應的行號列表,然后用行號列表中的行號去取出對應行的內容。這樣的查詢方式,可以避免遍歷對每一行數據進行掃描和匹配,只需要訪問包含查找詞的行,在海量數據下性能有數量級的提升。
ES 在日志場景的優勢在于全文檢索能力,能快速從海量日志中檢索出匹配關鍵字的日志,其底層核心技術是倒排索引(Inverted Index)。倒排索引是一種用于快速查找文檔中包含特定單詞或短語的數據結構,最早應用于信息檢索領域。如下圖所示,在數據寫入時,倒排索引可以將每一行文本進行分詞,變成一個個詞(Term),然后構建詞(Term) -> 行號列表(Posting List) 的映射關系,將映射關系按照詞進行排序存儲。當需要查詢某個詞在哪些行出現的時候,先在 詞 -> 行號列表 的有序映射關系中查找詞對應的行號列表,然后用行號列表中的行號去取出對應行的內容。這樣的查詢方式,可以避免遍歷對每一行數據進行掃描和匹配,只需要訪問包含查找詞的行,在海量數據下性能有數量級的提升。 業界各類系統為了支持全文檢索和任意列索引,往往有兩種實現方式:一是通過外接索引系統來實現,原始數據存儲在原系統中、索引存儲在獨立的索引系統中,兩個系統通過數據的 ID 進行關聯。數據寫入時會同步寫入到原系統和索引系統,索引系統構建索引后不存儲完整數據只保留索引。查詢時先從索引系統查出滿足過濾條件的數據 ID 集合,然后用 ID 集合去原系統查原始數據。這種架構的優勢是實現簡單,借力外部索引系統,對原有系統改動小。但是問題也很明顯:
業界各類系統為了支持全文檢索和任意列索引,往往有兩種實現方式:一是通過外接索引系統來實現,原始數據存儲在原系統中、索引存儲在獨立的索引系統中,兩個系統通過數據的 ID 進行關聯。數據寫入時會同步寫入到原系統和索引系統,索引系統構建索引后不存儲完整數據只保留索引。查詢時先從索引系統查出滿足過濾條件的數據 ID 集合,然后用 ID 集合去原系統查原始數據。這種架構的優勢是實現簡單,借力外部索引系統,對原有系統改動小。但是問題也很明顯: 高性能是 Apache Doris 倒排索引設計和實現的首要出發點,我們通過公開的測試數據集分別與 ES 以及 Clickhouse 進行性能測試,測試效果如下:
高性能是 Apache Doris 倒排索引設計和實現的首要出發點,我們通過公開的測試數據集分別與 ES 以及 Clickhouse 進行性能測試,測試效果如下:
日志數據的處理與分析是最典型的大數據分析場景之一,過去業內以 Elasticsearch 和 Grafana Loki 為代表的兩類架構難以同時兼顧高吞吐實時寫入、低成本海量存儲、實時文本檢索的需求。Apache Doris 借鑒了信息檢索的核心技術,在存儲引擎上實現了面向 AP 場景優化的高性能倒排索引,對于字符串類型的全文檢索和普通數值、日期等類型的等值、范圍檢索具有更高效的支持,相較于 Elasticsearch 實現性價比 10 余倍的提升,以此為日志存儲與分析場景提供了更優的選擇。

日志數據在企業大數據中非常普遍,其體量往往在企業大數據體系中占據非常高的比重,包括服務器、數據庫、網絡設備、IoT 物聯網設備產生的系統運維日志,與此同時還包含了用戶行為埋點等業務日志。
日志數據對于保障系統穩定運行和業務發展至關重要:基于日志的監控告警可以發現系統運行風險,及時預警;在故障排查過程中,實時日志檢索能幫助工程師快速定位到問題,盡快恢復服務;日志報表能通過長歷史統計發現潛在趨勢。而用戶埋點日志數據則是用戶行為分析以及智能推薦業務所依賴的決策基礎,有助于用戶需求洞察與體驗優化以及后續的業務流程改進。由于其在業務中能發揮的重要意義,因此構建統一的日志分析平臺,提供對日志數據的存儲、高效檢索以及快速分析能力,成為企業挖掘日志數據價值的關鍵一環。而日志數據和應用場景往往呈現如下的特點:- 數據增長快:每一次用戶操作、系統事件都會觸發新的日志產生,很多企業每天新增日志達到幾十甚至幾百億條,對日志平臺的寫入吞吐要求很高;
- 數據總量大:由于自身業務和監管等需要,日志數據經常要存儲較長的周期,因此累積的數據量經常達到幾百 TB 甚至 PB 級,而較老的歷史數據訪問頻率又比較低,面臨沉重的存儲成本壓力;
- 時效性要求高:在故障排查等場景需要能快速查詢到最新的日志,分鐘級的數據延遲往往無法滿足業務極高的時效性要求,因此需要實現日志數據的實時寫入與實時查詢。
- 高吞吐實時寫入:即需要保證日志流量的大規模寫入,又要支持低延遲可見;
- 低成本大規模存儲:系統自身可以存儲海量數據,且通過數據壓縮、冷熱分離等多種機制降低存儲成本;
- 高性能交互式分析且支持文本檢索:日志檢索的隨機性很強、很難提前預測模式,因此要求支持靈活的文本檢索,通過實時交互式查詢滿足分析需求。

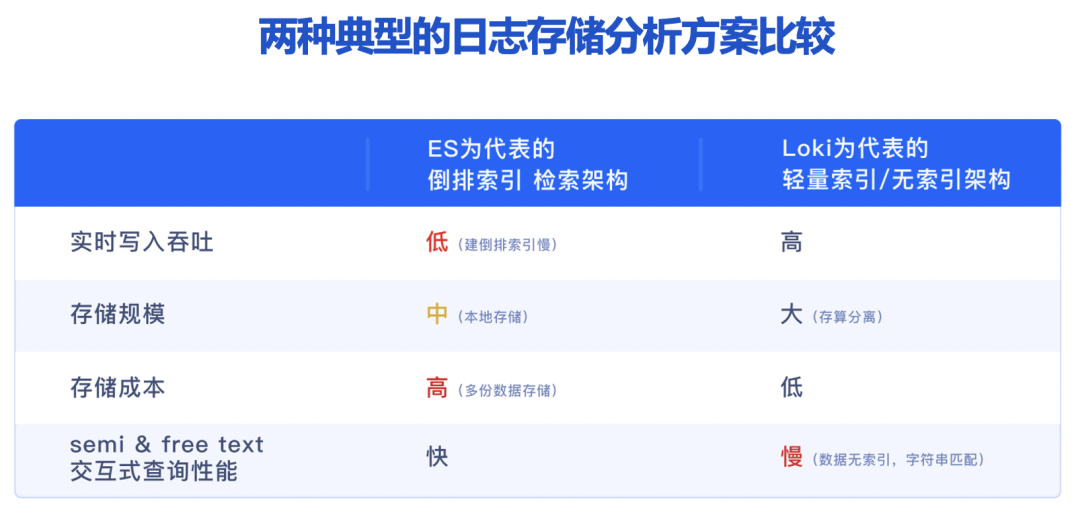
- 以 ES 為代表的倒排索引檢索架構,支持全文檢索、查詢性能好,因此在日志場景中被業內大規模應用,但其仍存在一些不足,包括實時寫入吞吐低、消耗大量資源構建索引,且需要消耗巨大存儲成本;
- 以 Loki 為代表的輕量索引或無索引架構,實時寫入吞吐高、存儲成本較低,但是檢索性能慢、關鍵時候查詢響應跟不上,性能成為制約業務分析的最大掣肘。
ES 在日志場景的優勢在于全文檢索能力,能快速從海量日志中檢索出匹配關鍵字的日志,其底層核心技術是倒排索引(Inverted Index)。倒排索引是一種用于快速查找文檔中包含特定單詞或短語的數據結構,最早應用于信息檢索領域。如下圖所示,在數據寫入時,倒排索引可以將每一行文本進行分詞,變成一個個詞(Term),然后構建詞(Term) -> 行號列表(Posting List) 的映射關系,將映射關系按照詞進行排序存儲。當需要查詢某個詞在哪些行出現的時候,先在 詞 -> 行號列表 的有序映射關系中查找詞對應的行號列表,然后用行號列表中的行號去取出對應行的內容。這樣的查詢方式,可以避免遍歷對每一行數據進行掃描和匹配,只需要訪問包含查找詞的行,在海量數據下性能有數量級的提升。

- ES 基于 Apache Lucene 構建倒排索引,Apache Lucene 自 2000 年開源至今已有超過 20 年的歷史,設計之初主要面向信息檢索領域、功能豐富且復雜,而日志和大多數 OLAP 場景只需要其核心功能,包括分詞、倒排表等,而相關度排序等并非強需求,因此存在進一步功能簡化和性能提升的空間;
- ES 和 Apache Lucene 均采用 Java 實現,而 Apache Doris 存儲引擎和執行引擎采用 C++ 開發并且實現了全面向量化,相對于 Java 實現具有更好的性能;
- 倒排索引并不能決定性能表現的全部,作為一個高性能、實時的 OLAP 數據庫,Apache Doris 的列式存儲引擎、MPP 分布式查詢框架、向量化執行引擎以及智能 CBO 查詢優化器,相較于 ES 更為高效。
業界各類系統為了支持全文檢索和任意列索引,往往有兩種實現方式:一是通過外接索引系統來實現,原始數據存儲在原系統中、索引存儲在獨立的索引系統中,兩個系統通過數據的 ID 進行關聯。數據寫入時會同步寫入到原系統和索引系統,索引系統構建索引后不存儲完整數據只保留索引。查詢時先從索引系統查出滿足過濾條件的數據 ID 集合,然后用 ID 集合去原系統查原始數據。這種架構的優勢是實現簡單,借力外部索引系統,對原有系統改動小。但是問題也很明顯:- 數據寫入兩個系統,異常有數據不一致的問題,也存在一定冗余存儲;
- 查詢需在兩個系統進行網絡交互有額外開銷,數據量大時用 ID 集合去原系統查性能比較低;
- 維護兩套系統的復雜度高,將系統的復雜性從開發測轉移到運維測;
數據庫內置倒排索引
在選擇了在數據庫內核中內置倒排索引后,我們需要進一步對 Apache Doris 索引結構進行分析,判斷能否通過在已有索引基礎上進行拓展來實現。Apache Doris 現有的索引存儲在 Segment 文件的 Index Region 中,按照適用場景可以分為跳數索引和點查索引兩類:1. 跳數索引:包括 ZoneMap 索引和 Bloom Filter 索引。
- ZoneMap 索引對每一個數據塊和文件保存 Min/Max/isnull 等匯總信息,可以用于等值、范圍查詢的粗粒度過濾,只能排除不滿足查詢條件的數據塊和文件,不能定位到行,也不支持文本分詞。
- BloomFilter 索引也是數據塊和文件級別的索引,通過 Bloom Filter 判斷某個值是否在數據塊和文件中,同樣不能定位到行、不支持文本分詞;
- ShortKey 在排序的基礎上,根據給定的前綴列實現快速查詢數據的索引方式,能夠對前綴索引的列進行等值、范圍查詢,但不支持文本分詞,另外由于數據要按前綴索引排序、因此一個表只允許一組前綴索引。
- Bitmap 索引記錄數據值 -> 行號 Bitmap 的有序映射,是一種很基礎的倒排索引,但是索引結構比較簡單、查詢效率不高、不支持文本分詞。
- 數據寫入和 Compaction 階段:在寫 Segment 文件的同時,同步寫入一個 Inverted Index 文件,文件路徑由 Segment ID + Index ID 決定。寫入 Segment 的 Row 和 Index 中的 Doc 一一對應,由于同步順序寫入,Segment 中的 Rowid 和 Index 中的 Docid 完全對應。
- 查詢階段:如果查詢 Where 條件中有建了倒排索引的列,會自動去 Index 文件中查詢,返回滿足條件的 Docid List,將 Docid List 一一對應的轉成 Rowid Bitmap,然后走 Doris 通用的 Rowid 過濾機制只讀取滿足條件的行,達到查詢加速的效果。
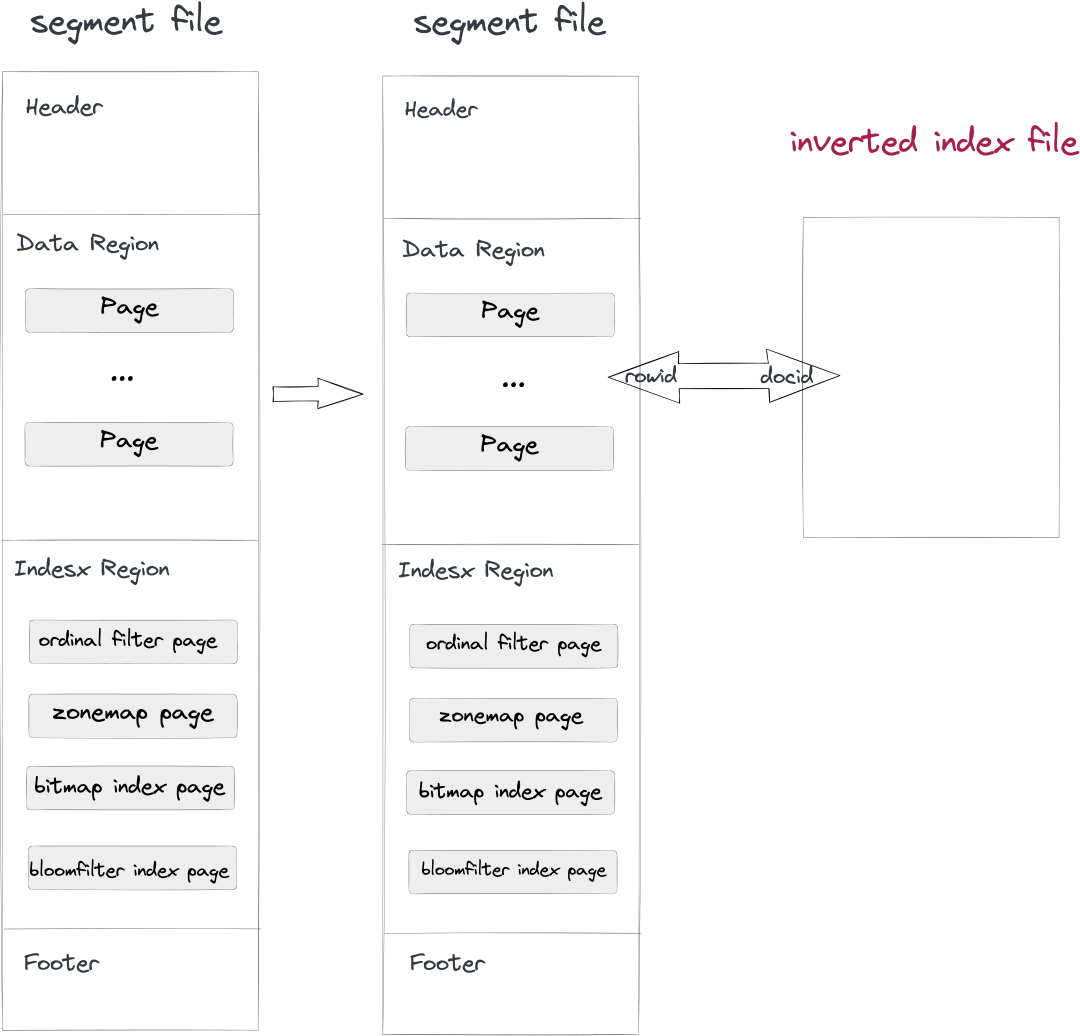
Doris倒排索引架構圖
這個設計的好處是已有的數據文件無需修改,可以做到兼容升級,而且增減索引不影響數據文件和其他索引,用戶增建索引沒有負擔。
通用倒排索引優化
C++和向量化實現Apache Doris 使用 CLucene(https://clucene.sourceforge.net/) 作為底層的倒排索引庫,CLucene 是一個用 C++ 實現的高性能、穩定的 Lucene 倒排索引庫,它的功能比較完整,支持分詞和自定義分詞算法,支持全文檢索查詢和等值、范圍查詢。Apache Doris 的存儲模塊和 CLucene 都用 C++ 實現,避免了Java Lucene 的 JVM GC 等開銷,同樣的計算 C++ 實現相對于 Java 性能優勢明顯,而且更利于做向量化加速。Doris 倒排索引進行了向量化優化,包括分詞、倒排表構建、查詢等,性能得到進一步提升。整體來看 Doris 的倒排索引寫入速度可以超過單核 20MB/s,而 ES 的單核寫入速度不到 5MB/s,有 4 倍的性能優勢。列式存儲和壓縮Lucene 本身是文檔存儲模型,主數據采用行存,而 Doris 中不同列的倒排索引是相互獨立的,因此倒排索引文件也采用列式存儲,有利于向量化構建索引和提高壓縮率。采用壓縮比高且速度快的 ZSTD,通常可以達到 5 ~10倍的壓縮比,與常用的GZIP壓縮相比有50%以上的空間節省且速度更快。BKD 索引與數值、日期類型列優化針對數值、日期類型的列,我們還實現了 BKD 索引,可以對范圍查詢提高性能,存儲空間也相對于轉成定長字符串更加高效,具有以下主要特性和優勢:- 高效范圍查詢:BKD 索引采用多維數據結構,為范圍查詢帶來高效率。它能迅速定位數值或日期類型列中所需的數據范圍,降低查詢時間復雜度。
- 存儲空間優化:與其他索引方法相比,BKD 索引在存儲空間使用上更高效。通過聚合并壓縮相鄰數據塊,減少索引所需存儲空間,降低存儲成本。
- 多維數據支持:BKD 索引具備良好擴展性,支持多維數據類型,如地理坐標(GEO point)和范圍(Range),使其在處理復雜數據類型時具有高適應性。
- 優化低基數場景:針對數值分布集中、單個數值倒排列表較多的低基數場景,我們調整了針對性的壓縮算法,降低大量倒排表解壓縮和反序列化所帶來的CPU性能消耗。
- 預查詢技術:針對查詢結果命中數較高的場景,我們采用預查詢技術進行命中數預估。若命中數顯著超過閾值,可跳過索引查詢,直接利用Doris在大數據量查詢下的技術優勢進行數據過濾。
面向 OLAP 的倒排索引優化
日志存儲和分析場景對檢索的需求很簡單,不需要特別復雜的功能(比如相關性排序),更需要降低存儲成本和快速按照條件查出數據。因此,在面對海量數據的寫入和查詢時,Apache Doris 還針對 OLAP 數據庫的特點優化了倒排索引的結構,使其更加簡潔高效。例如:- 在寫入流程保證不會多個線程寫入一個索引,從而避免寫入時多線程鎖競爭的開銷;
- 在存儲結構上去掉了不必要的正排、norm 等文件,減少寫入 IO 開銷和存儲空間占用;
- 查詢過程中簡化相關性打分和排序邏輯,降低不必要的開銷,提升查詢性能。
- 指定分區構建倒排索引,比如新增一個索引的時候指定最近7天的日志構建索引,歷史數據不建索引
- 指定分區刪除倒排索引,比如刪除超過1個月的日志的索引,釋放訪問頻度低的索引存儲空間
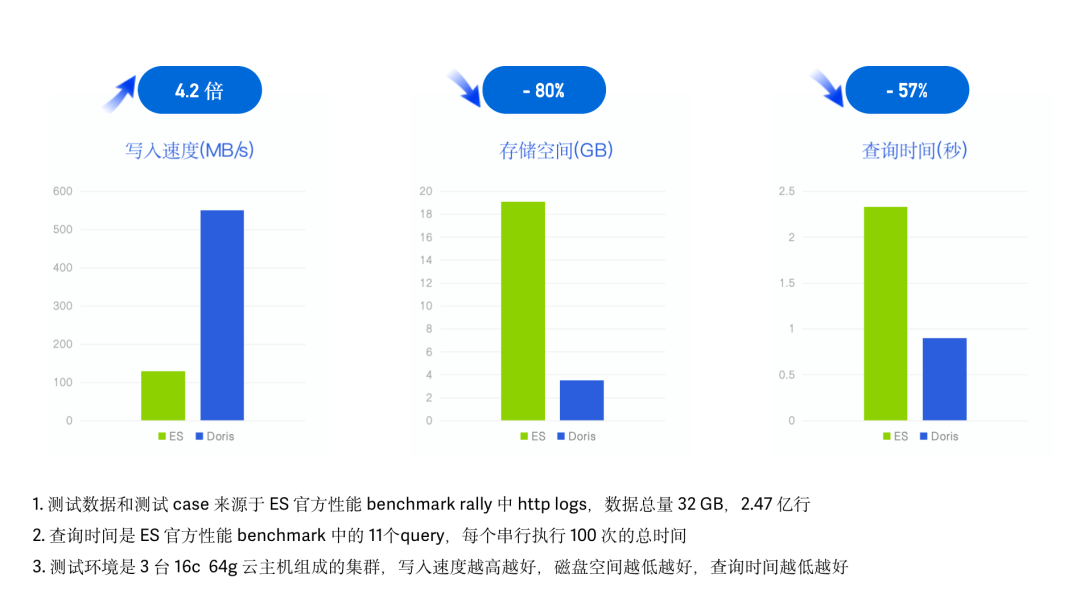
高性能是 Apache Doris 倒排索引設計和實現的首要出發點,我們通過公開的測試數據集分別與 ES 以及 Clickhouse 進行性能測試,測試效果如下:vs Elasticsearch
我們采用了 ES 官方的性能測試 Benchmark esrally 并使用其中的 HTTP Logs 日志,在同樣的硬件資源、數據、測試Case 以及測試工具下,記錄并對比各自的數據寫入時間、吞吐以及查詢延遲。- 測試數據:esrally HTTP Logs track 中自帶測試數據集,1998 年 World Cup HTTP Server Logs,未壓縮前 32G、共 2.47 億行、單行平均長度 134 字節;
- 測試查詢:esrally HTTP Logs 測試關鍵詞檢索、范圍查詢、聚合、排序等 11 個 Query,所有查詢跑 100 次串行執行;
- 測試環境:3 臺 16C 64G 云主機組成的集群。
vs Clickhouse
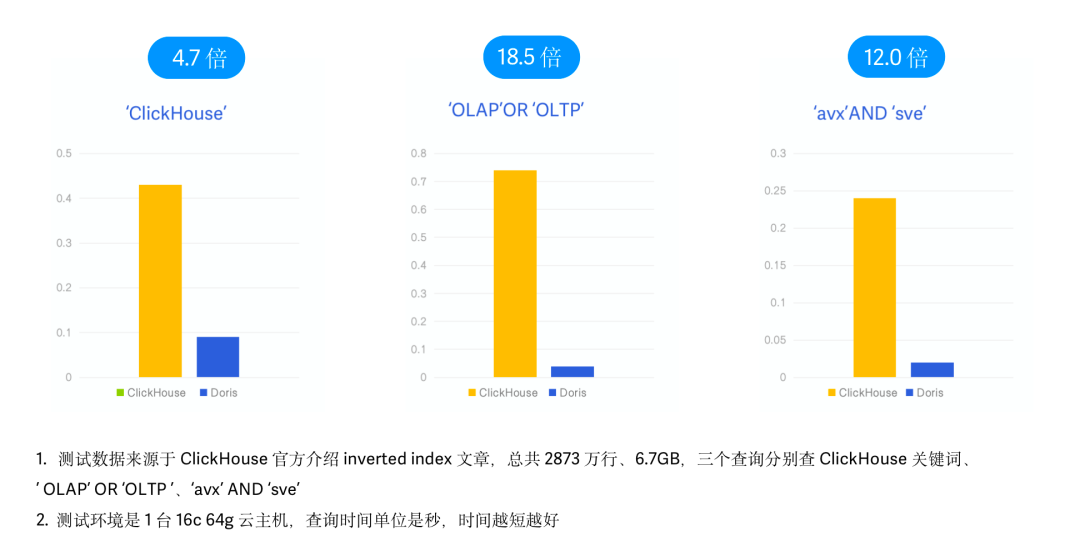
Clickhouse 近期的 v23.1 版本也引入了類似 Feature,將倒排索引作為實驗性功能發布,因此我們同樣進行了跟 Clickhouse 倒排索引的性能對比。在本次測試中,我們采用了 Clickhouse 官方 Inverted Index 介紹博客中使用的 Hacker News 樣例數據以及查詢 SQL ,同樣保持相同的物理資源、數據、測試 Case 以及測試工具。(參考文章:https://clickhouse.com/blog/clickhouse-search-with-inverted-indices)- 測試數據:Hacker News 2873 萬條數據,6.7G,Parquet 格式;
- 測試查詢:3 個查詢,分別查詢 'clickhouse'、'olap' OR 'oltp'、'avx' AND 'sve' 等關鍵字出現的次數;
- 測試機器:1 臺 16C 64G 云主機

-
INDEX idx_comment (`comment`)指定對 comment 列建一個名為idx_comment的索引 -
USING INVERTED指定索引類型為倒排索引 -
PROPERTIES("parser" = "english")指定分詞類型為英文分詞
CREATETABLEhackernews_1m ( `id`BIGINT, `deleted`TINYINT, `type`String, `author`String, `timestamp`DateTimeV2, `comment`String, `dead`TINYINT, `parent`BIGINT, `poll`BIGINT, `children`Array<BIGINT>, `url`String, `score`INT, `title`String, `parts`Array<INT>, `descendants`INT, INDEXidx_comment(`comment`)USINGINVERTEDPROPERTIES("parser"="english")COMMENT'invertedindexforcomment' ) DUPLICATEKEY(`id`) DISTRIBUTEDBYHASH(`id`)BUCKETS10 PROPERTIES("replication_num"="1");注:對于已經存在的表,也可以通過ADD INDEX idx_comment ON hackernews_1m(`comment`) USING INVERTED PROPERTIES("parser" = "english")來增加索引。值得一提的是,和 Doris 原先存儲在 Segment 數據文件中的智能索引和二級索引相比,增加倒排索引的過程只會讀 comment 列構建新的倒排索引文件,不會讀寫原有的其他數據,效率有明顯提升。2. 導入數據后查詢,使用
MATCH_ALL在comment這一列上匹配 OLAP 和 OLTP 兩個詞,和LIKE掃描硬匹配相比,查詢性能有十余倍的提升。(這僅是 100 萬條數據下的測試效果,而隨著數據量增大、性能提升越明顯)mysql>SELECTcount()FROMhackernews_1mWHEREcommentLIKE'%OLAP%'ANDcommentLIKE'%OLTP%'; +---------+ |count()| +---------+ |15| +---------+ 1rowinset(0.13sec) mysql>SELECTcount()FROMhackernews_1mWHEREcommentMATCH_ALL'OLAPOLTP'; +---------+ |count()| +---------+ |15| +---------+ 1rowinset(0.01sec)更多詳細功能介紹和測試步驟可以參考Apache Doris 倒排索引官方文檔:https://doris.apache.org/zh-CN/docs/dev/data-table/index/inverted-index/

審核編輯 :李倩
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
日志
+關注
關注
0文章
146瀏覽量
11063 -
數據類型
+關注
關注
0文章
237瀏覽量
14185 -
數組
+關注
關注
1文章
420瀏覽量
27351
原文標題:從 Elasticsearch 到 Apache Doris,10 倍性價比的新一代日志存儲分析平臺|新版本揭秘
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
熱點推薦
曦望發布新一代推理GPU芯片,單位Token推理成本降低90%
已突破萬片。 ? 啟望S3是專為大模型推理打造的定制化GPGPU芯片。在典型推理場景下,它的整體性價比較上一代提升超10倍。在算力與存儲設計
從0到1搭建實時日志監控系統:基于WebSocket + Elasticsearch的實戰方案
套低成本、實時性高的日志監控系統。
2. 技術選型
數據存儲 :Elasticsearch(高效檢索與聚合)
實時推送 :WebSocket(全雙工通信,避免HTTP輪詢)
后端服務 :Node.js
發表于 01-09 16:43
安森美低壓差穩壓器與電源穩壓器的技術解析 從經典到最新一代
安森美 (onsemi) 傾注數十年心血,持續打磨這一技術根基。從曾為收音機、電視機供電的傳統穩壓器,到如今為電動工具、醫療設備及自動駕駛汽車提供穩定運行保障的精密低壓差穩壓器 (LDO),技術迭代從未停歇。本文將深入探討傳統穩
翱捷科技ASR8662 SoC助力新一代智能車機量產上市
隨著智能座艙從“輔助駕駛”走向“沉浸交互”,用戶對于車載系統的流暢度、音質表現與互聯體驗提出了更高要求。近日,搭載翱捷科技高性價比八核智能SoC平臺——ASR8662 的新一代智能車機
使用littlefs存儲ulog日志,然后讀日志文件會出錯,為什么?
使用littlefs存儲ulog日志,然后通過命令讀取日志文件,或者通過API接口讀取或拷貝日志文件,都會導致線程卡死,嘗試了多種方法都不行,有沒有大佬有遇到或者處理過類似問題?
改成
發表于 09-29 06:14
華納云服務器Linux系統日志集中化管理平臺搭建
在云計算時代,企業運維團隊面臨服務器數量激增帶來的日志管理難題。本文詳細解析如何基于Linux系統構建高效的云服務器日志集中化管理平臺,涵蓋日志采集、傳輸、
從精準采集到智慧賦能:物聯網平臺打造新一代氣象監控體系
分析“團霧+車流密集”的風險。 物聯網平臺的核心突破,在于通過跨設備數據關聯技術,打破傳感器、終端設備的數據孤島,構建“多源數據融合-智能分析-場景落地”的全鏈路體系,讓氣象監控從“單
電商API日志分析的實用工具
? 在當今數字化電商時代,API(應用程序編程接口)已成為平臺與外部系統交互的核心通道。電商API日志記錄了每一次請求的詳細信息,包括用戶行為、交易狀態、錯誤響應等。分析這些

使用NVIDIA GPU加速Apache Spark中Parquet數據掃描
隨著各行各業的企業數據規模不斷增長,Apache Parquet 已經成為了一種主流數據存儲格式。Apache Parquet 是一種列式
新一代高效電機技術—PCB電機
純分享帖,點擊下方附件免費獲取完整資料~~~
*附件:新一代高效電機技術—PCB電機.pdf
內容有幫助可以關注、點贊、評論支持一下,謝謝!
【免責聲明】本文系網絡轉載,版權歸原作者所有。本文所用視頻、圖片、文字如涉及作品版權問題,請第
發表于 07-17 14:35
存儲示波器的存儲深度對信號分析有什么影響?
。以下從技術原理、實際影響及優化策略三方面展開分析。一、存儲深度對信號分析的核心影響1. 時域信號完整性
邊沿細節捕捉能力
高頻信號邊沿:
發表于 05-27 14:39
nRF54系列新一代無線 SoC
nRF54L 系列將廣受歡迎的 nRF52 系列提升到新的水平,專為下一代藍牙 LE 產品而設計。它集成了新型超低功耗 2.4 GHz 無線電和多用途 MCU 功能,采用 128 MHz Arm
發表于 05-26 14:48
如何在CentOS系統中部署ELK日志分析系統
日志分析已成為企業監控、故障排查和性能優化的重要組成部分。ELK(Elasticsearch、Logstash 和 Kibana)堆棧作為一種強大的開源解決方案,提供了高效的
新一代光纖涂覆機
新一代光纖涂覆機系列:國產!
2025年,濰坊華纖光電科技將推出五大類全光纖涂覆機,標志著國產光纖涂覆機技術邁入水平。以下是該系列產品的詳細介紹:
五大類光纖涂覆機
單套模組光纖涂覆機
特點:可替代
發表于 04-03 09:13
隆基新一代分布式組件Hi-MO X10登陸南歐市場
2月末,隆基新一代分布式組件Hi-MO X10強勢登陸法國、西班牙、意大利等南歐市場,以“技術+場景”雙核驅動,掀起一場跨越國界的光伏風暴。從古堡盛典



 工商網監
工商網監
評論