 HLS for循環優化
HLS for循環優化

FOR循環優化
基本概念
從下面的例子中來解釋for循環中的基本概念:
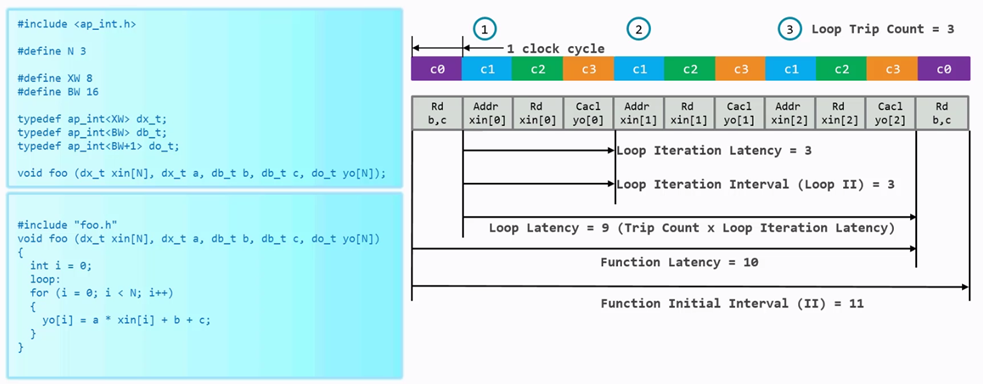
圖 4.1 for循環基本概念
由于N等于3,因此每次循環可以分成4個步驟來完成:
c0:讀取數據b和c;
c1:獲取數據xin 0處地址;
c2:讀取對應地址上的數據;
c3:計算yo[0]的值。
后面的計算都是三個時鐘周期計算出一個值,因此對一次循環來說,Loop Iteration Latency為3,Loop Iteration Interval也是3,Loop Latency是9,再加上前面讀b和c的值的一個周期,整個函數的Latency是10,函數間的Initial Interval是11.
Pipeline
對for循環常用的優化是pipeline,pipeline的原理如下圖4.2所示。
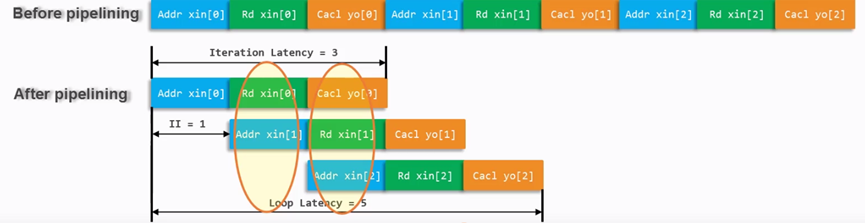
圖 4.2 pipeline優化原理
在優化結束后,Loop Iteration Latency為3,Loop Iteration Interval變成1,Loop Latency為5.
如果對函數做pipeline,那么會自動把函數下面的for循環都做unrolling處理;如果對外層的for循環做pipeline,那么會自動對內層的for循環做unrolling處理。
Unrolling
默認情況下for循環是折疊的,就是電路被時分復用。當展開后,資源增加。如下圖所示將for循環展開成3倍的情況,資源也擴大了3倍。

圖 4.3 展開成3倍
也可以部分展開,循環次數為6,但展開成3倍,程序如下所示:
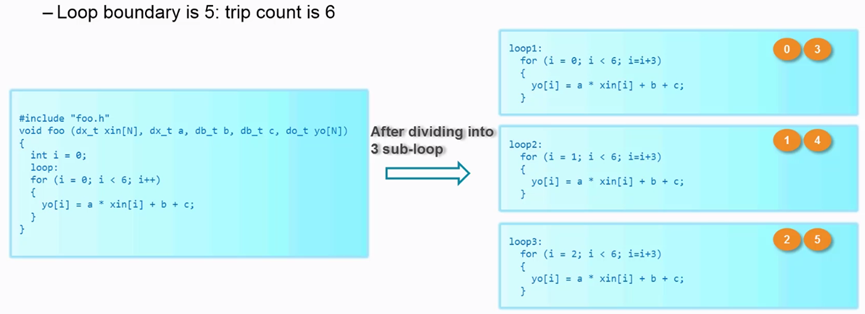
展開后,程序被分成3部分,資源也復制了3份。
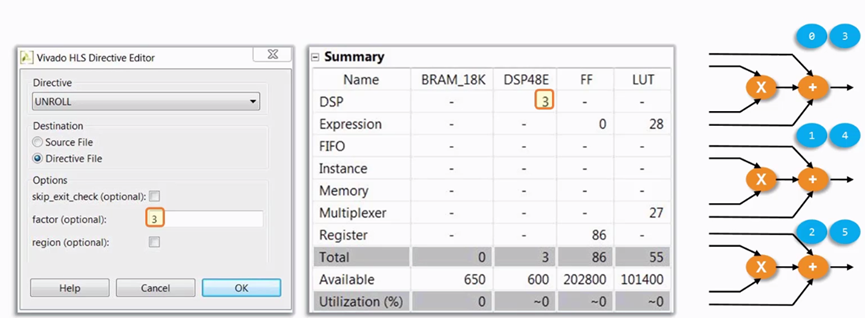
圖 4.4 Unroll的設置
Merge
當幾個for循環執行的內容很相似時,如下面的程序所示:

兩個for循環分別對兩個數據做加法和減法,在HLS綜合后,會先進行第一個for循環的計算,完成后再進行第二個for循環的計算。這樣綜合出的Latency為18,Interval為19。
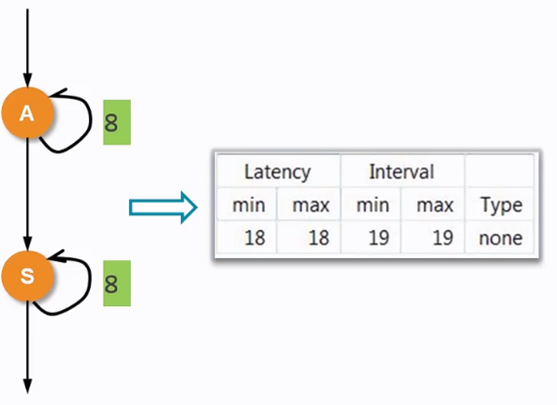
圖 4.5 綜合后延遲
在HLS中提供了Merge的選項,合并的是for所作用的region,合并后綜合后的延遲如下圖4.6所示。
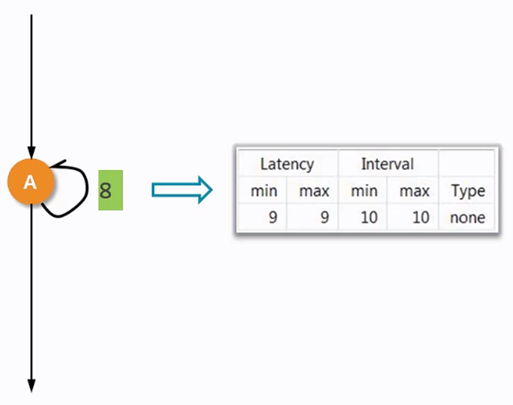
圖 4.6 Merge后的延遲
上面的例子中兩個循環的邊界相同,如果兩個循環的邊界不同,則以最大的作為合并后的邊界;如果一個邊界是變量,另一個是常量,則不能合并;如果兩個循環邊界都是變量,依然不能合并。
還可以將for循環封裝成一個函數,并在上一層中例化兩次,并對函數采用Allocation來使函數并行執行,在allocation中有limit選項,可以指定實例化的次數,該數據與程序中實際的數值應該是一樣的。
數據流
在下面的例子中,Task B依賴于Task A,Task C依賴于Task B,如圖4.7所示。

而且可以分析出,該結構不適合之前所講的pipeline和merge方式進行處理,在可以使用dataflow的方式。
從圖中可以看出,在使用DataFlow后,Loop B無需等待A執行完成后才開始執行,而且各個Loop之間也村在間隔。且延遲和資源都明顯減少。
DataFlow使用的限制:
1.一個輸出在多個Loop模塊中使用
2.被Bypass的模塊
3.帶反饋的模塊
4.帶條件的模塊
5.可變循環邊界的模塊
6.多個退出條件的模塊
下面分別對上面的限制條件進行說明。
1.din在Loop1中輸出的temp1同時賦給Loop2和Loop3使用,這時是不能使用dataflow的,如圖4.10所示。
通過對代碼進行適當的修改,將其結構進行變形,增加一個Loop_copy模塊,將其輸出一個送個Loop2,另一個輸出送給Loop3,但其實這兩個輸出的結果是相同的。就可以使用DataFlow來完成該函數。
且使用了DateFlow后,工程所占用的資源和延遲都相應減少。
- 被Bypass的模塊
如下圖4.12所示的例子中,temp1在Loop2中使用,但temp2沒有經過Loop2,直接在Loop3中使用,這種情況下也是不能使用DataFlow的。
同樣的,可以對代碼進行優化以達到可以使用DataFlow的目的,如下圖4.13所示。在Loop2中,增加一個輸出端口,使其輸出給Loop3,這樣就可以使用DataFlow了。
在DataFlow的循環之間的存儲模塊,對于scalar、pointer和reference或者函數的返回值,HLS會綜合為FIFO;對于數組,結果可能是乒乓RAM或者FIFO:如果HLS可以判斷數據是流模式,就會綜合為FIFO,且深度為1,若不能判斷,就會綜合為乒乓RAM。我們也可以指定為FIFO或者乒乓RAM,但在指定為FIFO時,如果指定的深度不合適,綜合時就會出現錯誤。
嵌套for循環
三種嵌套循環:
對于Perfect Loop,對外邊的Loop做流水比對內循環做流水更加節省時間。
對于Imperfect Loop,我們總希望可以轉換為Perfect Loop或者Semi-Perfect Loop。如下的Imperfect Loop,如果對內層Product做流水,綜合結果如右側的圖所示。
如果對第二層即col的Loop做流水,則會提示信息,col下的循環會被展開。
從圖中的warning可以看出,a被綜合為一個雙端口的RAM,但第14行和第20行對a的操作有一個重疊的區域,意味著吞吐率受限。
如果對最外部的循環做流水,會把下面所有的循環都展開,延遲會減少,但資源會增加。
如果對整個函數做流水,那么函數下面的所有循環都會展開,能獲得最好的Latency,但資源也是最多的。
我們可以對代碼就行優化,具體代碼具體優化。
Rewind
我們在使用了pipeline后,循環之間仍然會有間隔,但使用rewind功能,可以消除該間隔,如下圖所示。
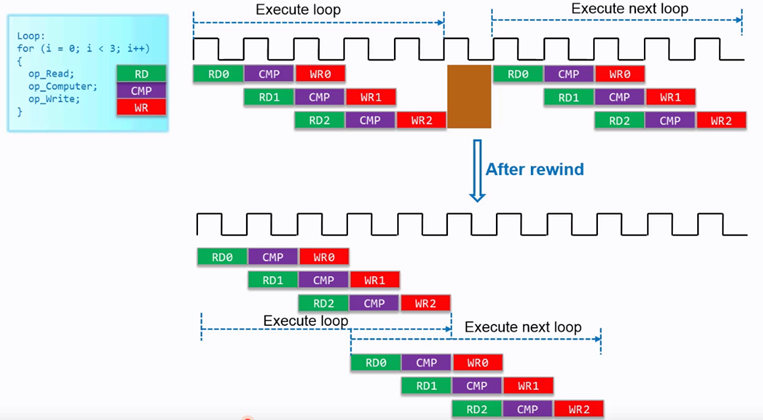
圖 4.16 rewind功能
但當函數中有多個循環時,rewind不能使用。
自動添加流水
在config_compile中,可以設置自動添加流水操作,如果循環次數小于我們設定的pipeline loops時,HLS就會自動為for循環添加流水。
在使用config_compile后,如果不想對某些for循環做流水,就可以在pipeline下面的選項中選中disable Loop pipeline。
變量邊界的解決方法
當循環邊界為變量時,通常可以采用下面的方式進行處理。
- 使用tripcount directive;
- 對于邊界變量的定義使用ap_int;
- 在C代碼中使用assert宏。
Tripcount directive不會對綜合有任何的影響,它只會對報告的顯示有影響。
使用ap_int和assert方法后,綜合后的資源會有明顯的減少。采用assert的方式的資源和延遲是最少的。
inline是針對函數,flatten是針對嵌套的循環。
-
函數
+關注
關注
3文章
4417瀏覽量
67521 -
HLS
+關注
關注
1文章
135瀏覽量
25841 -
for循環
+關注
關注
0文章
61瀏覽量
2885
發布評論請先 登錄
如何使用AMD Vitis HLS創建HLS IP

探索Vivado HLS設計流,Vivado HLS高層次綜合設計
HLS優化設計中pipeline以及unroll指令:細粒度并行優化的完美循環
如何優化HLS仿真腳本運行時間
AMD-Xilinx的Vitis-HLS編譯指示小結
優化 FPGA HLS 設計
怎么利用Synphony HLS為ASIC和FPGA架構生成最優化RTL代碼?
Vivado HLS設計流的相關資料分享
FPGA高層次綜合HLS之Vitis HLS知識庫簡析
使用Vitis HLS創建屬于自己的IP相關資料分享
HLS系列 – High Level Synthesis(HLS) 的一些基本概念1
HLS:lab3 采用了優化設計解決方案



 工商網監
工商網監
評論