 Instruct-UIE:信息抽取統一大模型
Instruct-UIE:信息抽取統一大模型

復旦大學自然語言處理實驗室桂韜、張奇課題組發布信息抽取統一大模型 Instruct-UIE,在領域大模型上取得突破性進展。Instruct-UIE 在信息抽取精度上全面大幅度超越ChatGPT以及基于預訓練微調的單一小模型。
自2022年11月 ChatGPT 橫空出世以來,其在對話、閱讀理解、對話、代碼生成等方面優異性能,受到了極大的關注。大模型所展現出來的長文本建模能力以及多任務統一學習能力使得自然語言處理范式正在發生快速變革。
在對 GPT 系列工作進行了詳細分析[1][2]后,我們發現雖然 ChatGPT 在很多任務上都展現出了良好的性能,但是在包括命名實體識別、關系抽取、事件抽取等在工業界有廣泛應用的信息抽取任務上效果卻亟待提升。ChatGPT 在某些命名實體識別數據集合上的的精度甚至只有不到20%。但是大模型所展示出來的多任務統一學習能力,驅使我們針對信息抽取領域的統一大模開展了深入研究。

實 驗 結 果
針對信息抽取任務,我們收集了包括 ACE 2005、ConLL 2003 等在內的41種評測集合,針對Flan-T5、Bloomz、LLama 等大模型進行了系統研究,構建了信息抽取統一大模型Instruct-UIE。該模型在絕大部分信息抽取任務中(85%以上)都超越了單個小模型的預訓練微調結果。
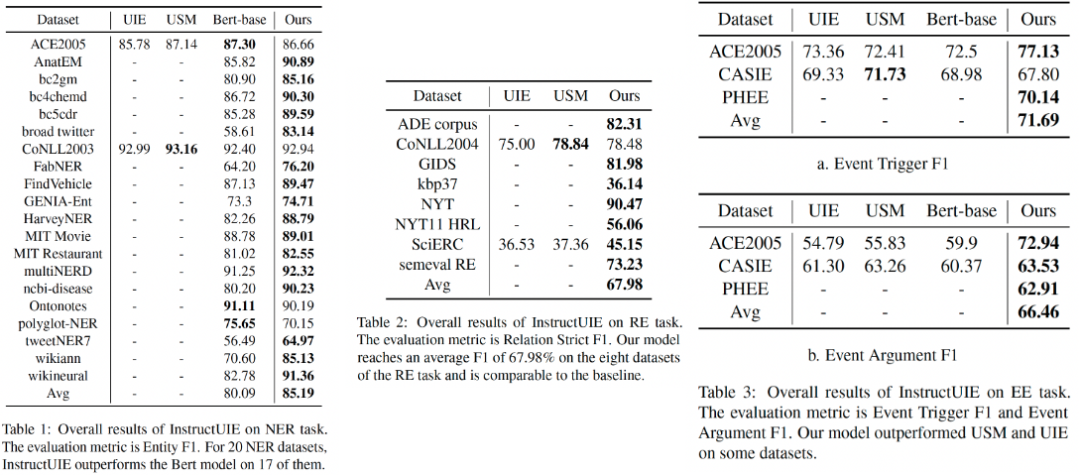
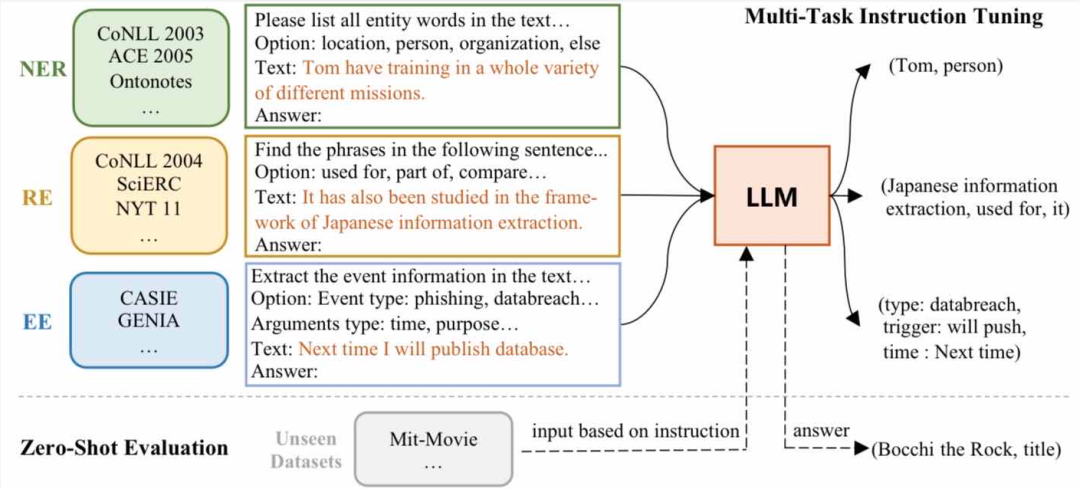
Instruct-UIE 統一了信息抽取任務訓練方法,可以融合不同類型任務以及不同的標注規范,統一進行訓練。針對新的任務需求,僅需要少量的數據進行增量式學習,即可完成模型的升級。
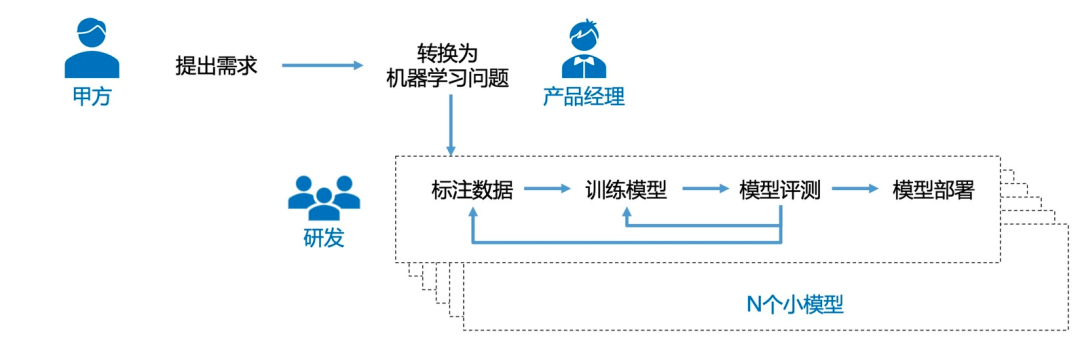
小模型時代任務,模型開發需要經過標注數據,訓練模型,模型評測和模型部署等多個步驟。其顯著缺點是成本高、時間周期長;相同任務的微小需求變化,需要30%-70%的重新開發成本;模型開發和維護成本高等問題都極大地制約了自然語言處理產品化。
而在大模型時代,我們可以將大量各類型任務,統一為生成式自然語言理解框架,并構造訓練語料進行微調。由于大模型所展現出來的通用任務理解能力和未知任務泛化能力,使得未來自然語言處理的研究范式進一步發生變化。這樣的研究范式使得小模型時代所面臨的問題可以在一定程度上可以得到解決。針對新任務和需求,基于大模型的方法可以快速訓練,并且不需要部署新的模型,從而實現自然語言處理的低成本產品化。
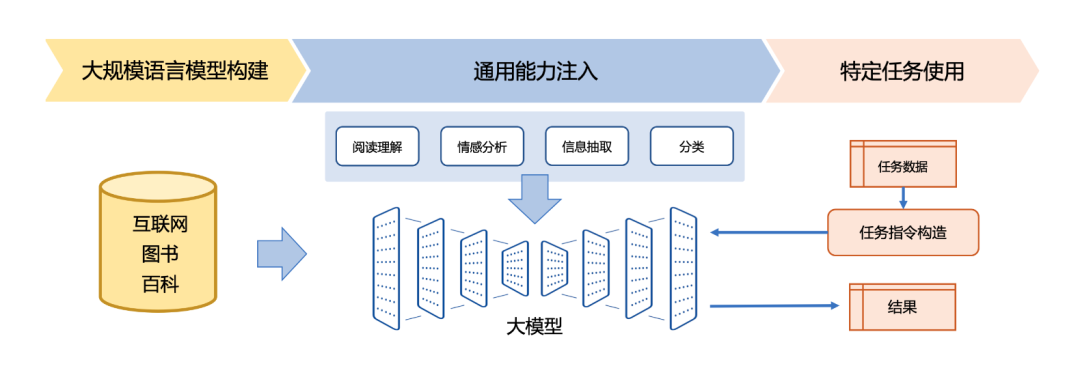
InstructUIE 工作驗證了領域大模型的可行性,針對B端場景,百億級領域模型具有高效、成本低、可私有化部署等優勢,在行業應用中具有廣闊前景。我們將近期開源相關代碼和模型。
審核編輯 :李倩
-
模型
+關注
關注
1文章
3802瀏覽量
52224 -
自然語言處理
+關注
關注
1文章
630瀏覽量
14704 -
ChatGPT
+關注
關注
31文章
1598瀏覽量
10365
發布評論請先 登錄
基于XML的WEB信息抽取模型設計
使用神經網絡進行微博情緒識別與誘因抽取聯合模型的說明
模型NLP事件抽取方法總結

了解信息抽取必須要知道關系抽取

基于篇章信息和Bi-GRU的事件抽取綜述
統一的文本到結構生成框架——UIE
基于統一語義匹配的通用信息抽取框架USM
介紹一種信息抽取的大一統方法USM
基于統一語義匹配的通用信息抽取框架-USM
最佳開源模型刷新多項SOTA,首次超越Mixtral Instruct!「開源版GPT-4」家族迎來大爆發




 工商網監
工商網監
評論