 淺析時序數據庫的流計算支持
淺析時序數據庫的流計算支持

01
時序數據及其特點
時序數據(Time Series Data)是基于相對穩定頻率持續產生的一系列指標監測數據,比如一年內的道瓊斯指數、一天內不同時間點的測量氣溫等。時序數據有以下幾個特點:
●歷史數據的不變性
● 數據的有效性
● 數據的時效性
● 結構化的數據
● 數據的大量性
02
時序數據庫基本架構
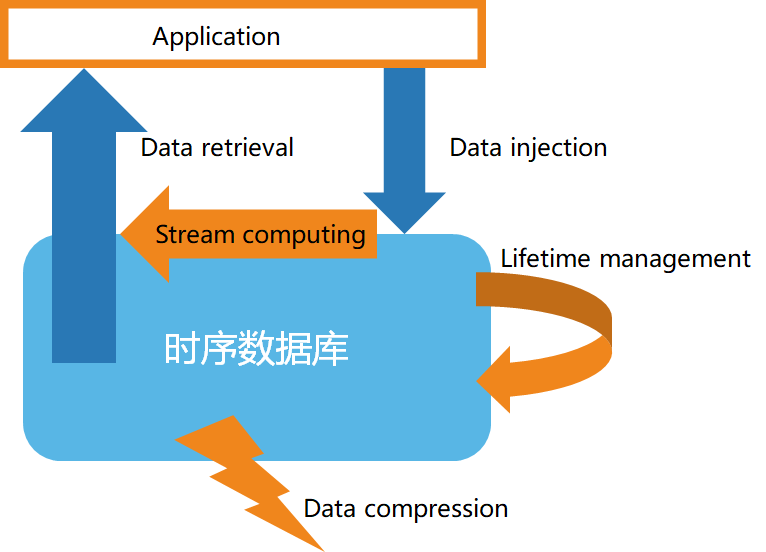
針對時序數據的特點,時序數據庫一般具有以下特性:
● 高速的數據入庫
● 數據的生命周期管理
● 數據的流處理
● 高效的數據查詢
● 定制的數據壓縮
03
流計算介紹
流計算主要是指針對實時獲取來自不同數據源的海量數據,經過實時分析處理,從而獲得有價值的信息。常見的業務場景包括實時事件的快速反應,市場變化的實時告警,實時數據的交互分析等。流計算一般包括如下幾方面的功能:
1)過濾和轉換 (filter & map)
2)聚合以及窗口函數 (reduce,aggregation/window)
3)多數據流合并以及模式匹配 (joining & pattern detection)
4)從流到塊處理
04
時序數據庫對流計算的支持
案例一:使用定制化的流計算 API,如下面例子所示:
?
from(bucket: "mydb")
|> range(start: -1h)
|> filter(fn: (r) => r["_measurement"] == "mymeasurement")
|> map(fn: (r) => ({ r with value: r.value * 2 }))
|> filter(fn: (r) => r.value > 100)
|> aggregateWindow(every: 1m, fn: sum, createEmpty: false)
|> group(columns: ["location"])
|>join(tables:{stream1:{bucket:"mydb",measurement:"stream1",start:-1h},stream2:{bucket:"mydb",measurement:"stream2",start:-1h}},on:["location"])
|>alert(name:"value_above_threshold",message:"Valueisabovethreshold",crit:(r)=>r.value>100)
|>to(bucket:"mydb",measurement:"output",tagColumns:["location"])
案例二:使用類 SQL 指令,創建流計算以及定義流計算規則,如下:
CREATE STREAM current_stream TRIGGER AT_ONCE INTO current_stream_output_stb AS SELECT _wstartasstart, _wendasend, max(current)asmax_current FROMmeters WHERE voltage <= 220 ?INTEVAL (5S) SLIDING (1s);
審核編輯:劉清
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
SQL
+關注
關注
1文章
789瀏覽量
46700 -
數據庫
+關注
關注
7文章
4020瀏覽量
68349 -
API接口
+關注
關注
1文章
114瀏覽量
11248
原文標題:時序數據庫的流計算支持
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
熱點推薦
時間序列數據的存儲和計算 - 開源時序數據庫解析
摘要: Prometheus 開源時序數據庫解析的系列文章在之前已經完成了幾篇,對比分析了Hbase系的OpenTSDB、Cassandra系的KairosDB、BlueFlood及Heroic
發表于 01-25 14:53
關于時序數據庫的內容
簡介: 這是一篇無法一口氣讀完的、文字過萬[正文字數14390]的長文,這是一個無法中途不上廁所就看完的、關于時序數據庫的視頻[時長111分鐘]分享的文字整理..大家好,很開心能夠和大家一起交流時序數據庫
發表于 07-12 08:00
TableStore時序數據存儲 - 架構篇
Schema設計以及索引設計方案。最后還會有計算篇,會提供幾個時序數據流計算和時序分析的方案設計。?什么是時序數據
發表于 08-08 16:17
?892次閱讀
工業互聯網時代,我們為什么需要一個時序數據庫?
、管理、查詢、處理上述二元函數數據的數據庫,則可以稱之為時序數據庫。時序數據庫主要以解決下面幾個問題:時序數據的寫入:如何
工業互聯網時代,我們為什么需要時序數據庫之二:適合的就是最好的
。至此,我們得出的結論就一個:選擇到底用什么數據庫來支持時序數據,還是需要對時序數據的需求進行透徹的分析,然后根據時序數據的特點,來選擇適合
時序數據庫的前世今生
? 時序數據庫忽然火了起來。Facebook開源了beringei時序數據庫,基于PostgreSQL打造的時序數據庫TimeScaleDB也開源了。時序數據庫作為物聯網方向一個非常重
工業互聯網時代:我們為什么需要時序數據庫之二
作為資深“杠精”,當然需要先知道要“杠”的到底是什么?就時序數據庫而言,就是要“杠”兩個東西:1、“杠”數據;2、“杠”數據庫。
華為時序數據庫為智慧健康養老行業貢獻應用之道
隨著 IoT 技術的快速發展,物聯網設備產生的數據呈爆炸式增長。這些數據通常隨時間產生,稱之為時序數據。這樣的一種專門用于管理時序數據的數據庫
華為PB級時序數據庫Gauss DB,助力海量數據處理
,時序數據作為大數據、機器學習、實時預測的基礎數據,作用更加顯著。因此,對時序數據的研究與應用應當更為深入。 ??近 5 年來,時序數據庫發
華為自研分布式時序數據庫集群:初始GaussDB(for Influx)
要處理的指標數據達到TB級,一年的數據同樣達到PB級,并且數據需要永久存儲。傳統的關系型數據庫很難支撐這么大的數據量和寫入壓力,Hadoop

CeresDB 1.0正式發布,Rust高性能云原生時序數據庫
在經典的時序數據庫中,Tag 列(InfluxDB 稱之為 Tag,Prometheus 稱之為 Label)通常會對其生成倒排索引,但在實際使用中,Tag 的基數在不同的場景中是不一樣的 ———— 在某些場景下
涂鴉推出NekoDB時序數據庫,助力全球客戶實現低成本部署
隨著IoT技術逐漸成熟,眾多設備產出的數據呈現指數級增長。企業亟需用行之有效的方式管理海量時序數據。由此,各類時序數據庫開始成為市場寵兒。與市場需求相悖的是,時序數據庫水平參差不齊。縱
時序數據庫是什么?時序數據庫的特點
時序數據庫是一種在處理時間序列數據方面具有高效和專門化能力的數據庫。它主要用于存儲和處理時間序列數據,比如傳感器數據、監控



 工商網監
工商網監
評論