 華為自研分布式時序數據庫集群:初始GaussDB(for Influx)
華為自研分布式時序數據庫集群:初始GaussDB(for Influx)

前言
隨著云計算規模越來越大,以及物聯網應用逐漸普及,在物聯網(AIoT)以及運維監控(AIOps)領域,存在海量的時序數據需要存儲管理。以華為云監控服務(Cloud Eye Service,CES)為例,單個Region需要監控7000多萬監控指標,每秒需要處理90萬個上報的監控指標項,假設每個指標50個字節,一年的數據將達到PB級。另以地震監測系統為例,數萬監測站點24小時不間斷采集數據,平均每天要處理的指標數據達到TB級,一年的數據同樣達到PB級,并且數據需要永久存儲。傳統的關系型數據庫很難支撐這么大的數據量和寫入壓力,Hadoop等大數據解決方案以及現有的開源時序數據庫也面臨非常大的挑戰。對時序數據實時交互、存儲和分析的需求,將推動時序數據庫在架構、性能和數據壓縮等方面不斷進行創新和優化。
GaussDB(for Influx)時序數據庫依靠華為在數據存儲領域多年的實踐經驗,整合華為云的計算、存儲、服務保障和安全等方面的能力,大膽在架構、性能和數據壓縮等方面進行了技術創新,達到了較好的效果,對內支撐了華為云基礎設施服務,對外以服務的形式開放,幫助上云企業解決相關業務問題。
云原生存儲與計算分離架構

GaussDB(for Influx)接口完全兼容InfluxDB,寫入接口兼容OpenTSDB、Prometheus和Graphite。從架構上看,一個時序數據庫集群可以分為三大組件。它們分別是:
Shard節點:節點采用無狀態設計,主要負責數據的寫入和查詢。在節點內,除了分片和時間線管理之外,還支持數據預聚合、數據降采樣和TAG分組查詢等專為時序場景而優化的功能。
Config集群:存儲和管理集群元數據,采用三節點的復制集模式,保證元數據的高可靠性。
分布式存儲系統:集中存儲持久化的數據和日志,數據采用三副本方式存放,對上層應用透明。存儲系統為華為自研,經過多年產品實踐檢驗,系統的高可用和高可靠性都得到了驗證。
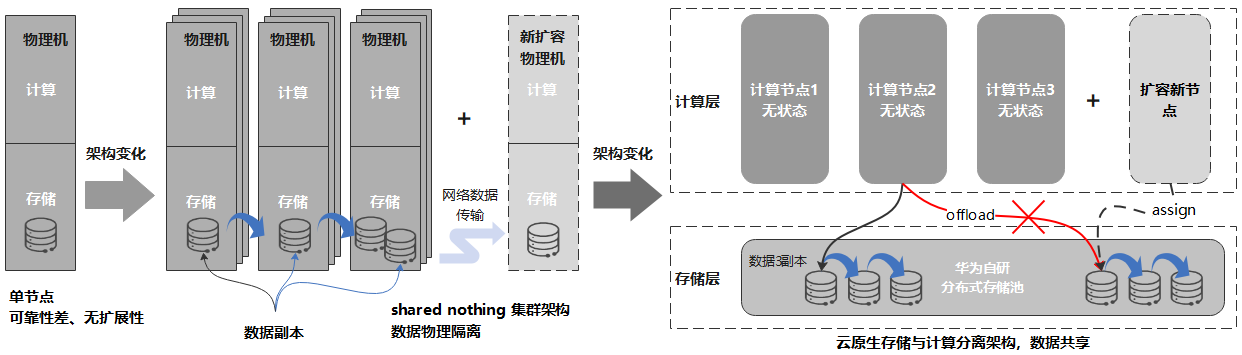
相比InfluxDB等開源時序數據庫,采用存儲與計算分離的云原生數據庫設計具備以下優勢:
容忍N-1節點故障,更高可用。存儲與計算分離,可以復用成熟的分布式存儲系統,提供系統的極致可靠性。時序數據通常會持續高性能寫入,同時還有大量的查詢業務,任何系統故障導致業務中斷甚至數據丟失都會造成嚴重的業務影響,而利用經過驗證的成熟的分布式存儲系統,能夠顯著的提升系統可靠性,降低數據丟失風險。
分鐘級計算節點擴容,秒級存儲擴容。解除在傳統Shared Nothing架構下,數據和節點物理綁定的約束,數據只是邏輯上歸宿于某個節點,使的計算節點無狀態化。這樣在擴容計算節點時,可以避免在計算節點間遷移大量數據,只需要邏輯上將部分數據從一個節點移交給另一個節點即可,可以將集群擴容的耗時從以天為單位縮短為分鐘級別。
消除多副本冗余,降低存儲成本。通過將多副本復制從計算節點卸載到分布式存儲節點,可以避免用戶以Cloud Hosting形態在云上自建數據庫時,分布式數據庫和分布式存儲分別做3副本復制導致總共9副本的冗余問題,能夠顯著降低存儲成本。
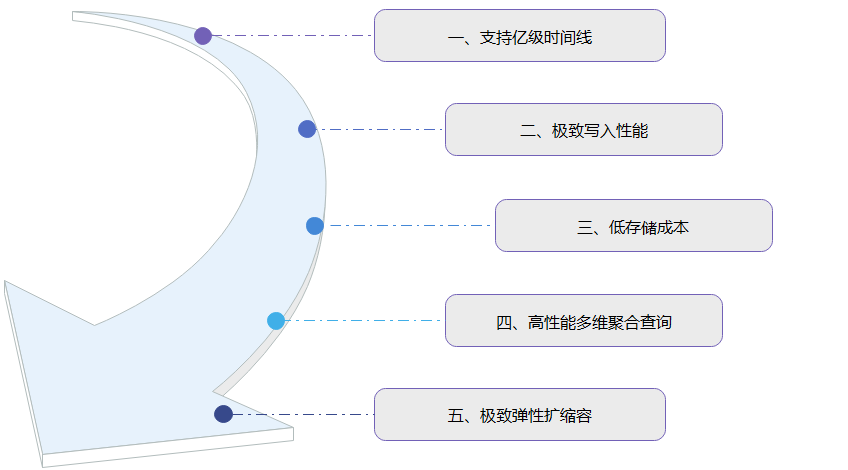
GaussDB(for Influx)采用云原生存儲與計算分離架構,具有支持億級時間線、極致寫入性能、低存儲成本、高性能多維聚合查詢和極致彈性擴縮容等5大特性。
支持億級時間線
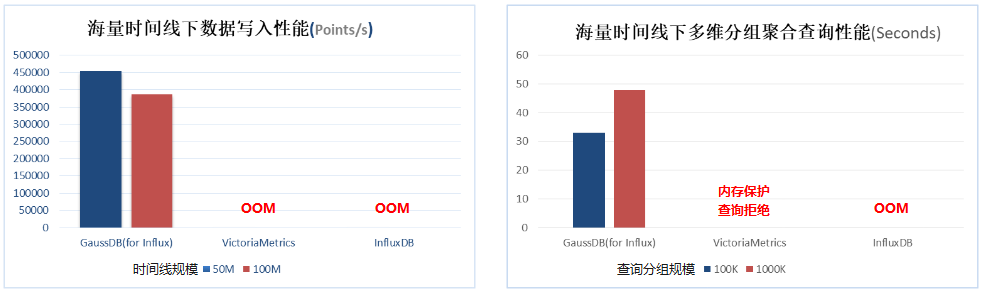
在時序數據庫系統中,存在大量并發查詢和寫入操作,合理控制內存的使用量顯得十分重要。開源時序數據庫VictoriaMetrics和InfluxDB在寫入數據的時間線增加到千萬級別時,進程會因內存耗盡而OOM退出。為了避免寫入海量時間線數據導致內存資源被耗盡,GaussDB(for Influx)做了如下優化:
●在內存分配上,大量使用內存池復用技術,減少臨時對象內存申請,降低內存碎片;
●在內存回收上,實現算法根據內存負載,動態調整GC頻率,加快內存空間回收;
●在單查詢上,實行Quota控制,避免單查詢耗盡內存;
●在緩存使用上,針對不同節點規格提供不同的最優配置。
經過改進,在海量時間線下,系統寫入性能保持穩定,大幅超出InfluxDB開源實現。對于涉及海量時間線的聚合查詢,如高散列聚合查詢,查詢性能提升更為顯著。
極致寫入性能:支持每天萬億條數據寫入

相比單機模式,集群模式可以將寫入負載分散到集群中各個計算節點上,從而支持更大規模的數據寫入。GaussDB(for Influx)支持每天萬億條數據寫入,在工程實現上進行了以下優化:
首先,時序數據按照時間線做Hash Partition,利用所有節點并行寫入,充分發揮集群優勢。
其次,Shard節點采用針對寫場景優化的LSM-Tree布局,寫WAL后確保日志持久化,再寫入內存Buffer即可返回。
最后,數據庫多副本復制卸載到分布式存儲,降低計算節點到存儲節點的網絡流量。
在大規模寫入場景下,GaussDB(for influx)的寫入性能線性擴展度大于80%。
低存儲成本:只需1/20的存儲成本
在時序數據庫面對的AIOps運維監控和AIoT物聯網兩個典型應用場景中,每天會產生數GB甚至數TB的時序數據。如果無法對這些時序數據進行很好的管理和壓縮,那將會給企業帶來非常高的成本壓力。
GaussDB(for Influx)對數據采用列式存儲,相同類型的數據被集中存儲,更有利于數據壓縮。采用自研的時序數據自適應壓縮算法,在壓縮前對數據進行抽樣分析,根據數據量、數據分布以及數據類型選擇最合適的數據壓縮算法。在壓縮算法上,相比原生的InfluxDB,重點針對Float、String、Timestamp這三種數據類型進行了優化和改進。
Float數據類型:對Gorilla壓縮算法進行了優化,將可以無損轉換的數值轉為整數,再根據數據特點,選擇最合適的數據壓縮算法。
String數據類型:采用了壓縮效率更好的ZSTD壓縮算法,并根據待壓縮數據的Length使用不同Level的編碼方法。
Timestamp數據類型:采用差量壓縮方法,最后還針對數據文件內的Timestamp進行相似性壓縮,進一步降低時序數據存儲成本。
下圖是分別采用實際業務場景的事件日志數據(數據集1)和云服務器監控指標數據 (數據集2)與InfluxDB進行了數據壓縮效率的性能對比。

節約存儲成本并非只有數據壓縮一種辦法。針對時序數據越舊的數據被訪問的概率越低的特點,GaussDB(for Influx)提供了時序數據的分級存儲,支持用戶自定義冷熱數據,實現數據的冷熱分離。熱數據相對數據量小,訪問頻繁,被存儲在性能更好、成本較高的存儲介質上;冷數據相對數據量大,訪問概率低,保存時間較久,被存儲在成本較低的存儲介質上,進而達到節約存儲成本的目的。根據實際業務數據測算,相同數據量下存儲成本僅有關系型數據庫的1/20。
高性能多維聚合查詢
多維聚合是時序數據庫中較為常見,且會定期重復執行的一種查詢,例如AIOps運維監控場景中查詢CPU、內存在指定時間范圍內的平均值。
|
SELECTmean(usage_cpu), mean(usage_mem) FROMcpu_info WHEREtime >= '2020-11-01T06:05:27Z' and time < '2020-11-01T18:05:27Z'? GROUPBYtime(1h), hostname |
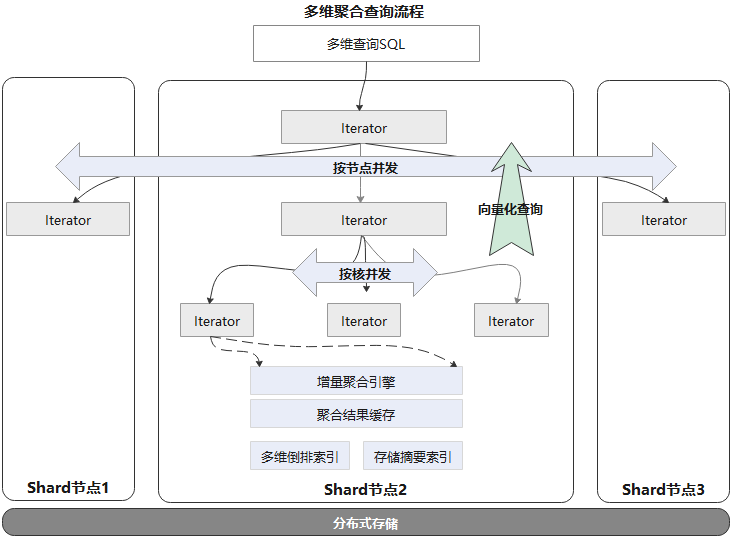
在提升聚合查詢整體性能方面,GaussDB(for Influx) 做了如下優化:
●采用MPP架構:一條查詢語句可以在多節點及多核并發執行。
●向量化查詢引擎:在查詢結果數據量很大時,傳統的火山模型每次迭代返回一條數據,存在過多的開銷導致性能瓶頸。GaussDB(for Influx)內部實現了向量化查詢引擎,每次迭代批量返回數據,大大減少了額外開銷。
●增量聚合引擎:基于滑動窗口的聚合查詢,大部分從聚合結果緩存中直接命中,僅需要聚合增量數據部分即可。
●多維倒排索引:支持多維多條件組合查詢,避免大量Scan數據。
●存儲摘要索引,加快數據查詢中過濾無關數據。
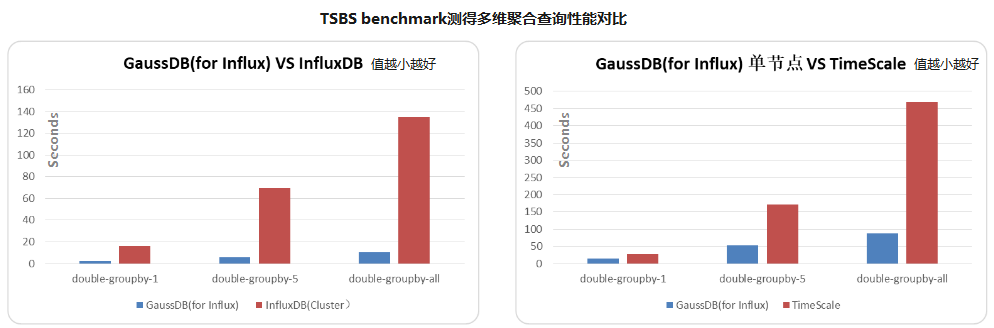
相同節點規格,GaussDB(for Influx)的聚合查詢性能是InfluxDB Enterprise的10倍,是Timescale的2到5倍。
分鐘級彈性擴縮容
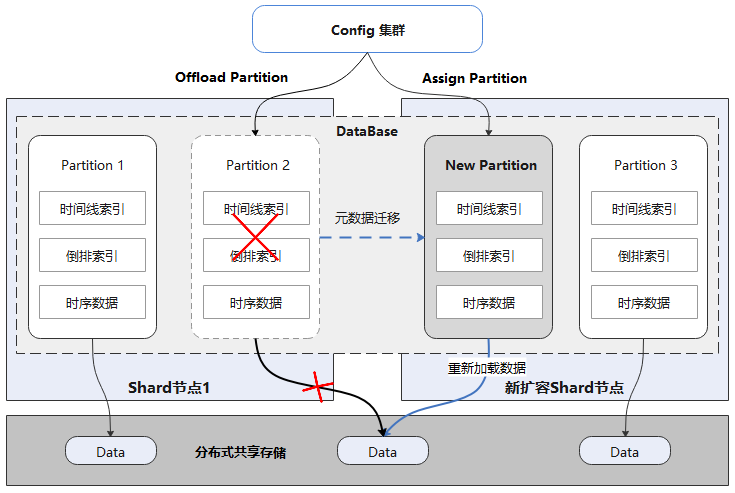
在時序數據庫的運行過程中,隨著業務量的增加,常常需要對數據庫進行在線擴容,以滿足業務的要求。傳統數據庫中的數據存儲在本地,擴容后往往需要遷移數據。當數據量達到一定規模時,數據遷移所耗費的時間往往按天計算,給運維帶來了很大的困難。
如上圖所示,每個Database邏輯上由多個Partition組成,每個Partition獨立存儲,且都可自描述。所有Partition數據都存儲在分布式共享存儲上,數據庫Shard節點和數據沒有物理綁定關系。擴容時首先offload源節點Partition,再在目標節點assign即可。
總結
時序數據應該存儲在專門為時序數據進行優化的時序數據庫系統中。華為云某業務從Cassandra切換到GaussDB(for Influx)后,計算節點從總共39個(熱集群18個,冷集群9個,大數據分析集群 12個)降低到了9個節點,縮減4倍計算節點。存儲空間消耗從每天1TB降低到100GB以內,縮減10倍存儲空間消耗。
GaussDB(for Influx)提供了獨特的數據存儲管理解決方案,云原生的存儲與計算架構,可根據業務變化快速擴容縮容;高效的數據壓縮能力和數據冷熱分離設計,可大幅降低數據存儲成本;高吞吐的集群,可滿足大規模運維監控和物聯網場景海量數據寫入和查詢性能要求。
審核編輯:湯梓紅
-
華為
+關注
關注
218文章
36005瀏覽量
262093 -
云計算
+關注
關注
39文章
8021瀏覽量
144392 -
數據庫
+關注
關注
7文章
4020瀏覽量
68342
發布評論請先 登錄
TiDB分布式數據庫運維實踐
分布式數據恢復—Ceph+TiDB數據恢復報告

七大大模型賦能的無人集群分布式協同調度與任務分配系統
大模型ai賦能的無人集群分布式協同調度與任務分配系統
深入理解分布式共識算法 Raft

怎樣確定分布式光伏集群通信網絡的負載均衡策略?

一鍵部署無損網絡:EasyRoCE助力分布式存儲效能革命

數據庫數據恢復—服務器異常斷電導致Oracle數據庫故障的數據恢復案例
數據庫數據恢復—MongoDB數據庫文件丟失的數據恢復案例
數據庫數據恢復—SQL Server數據庫被加密如何恢復數據?

分布式存儲數據恢復—虛擬機上hbase和hive數據庫數據恢復案例
數據庫數據恢復——MongoDB數據庫文件拷貝后服務無法啟動的數據恢復
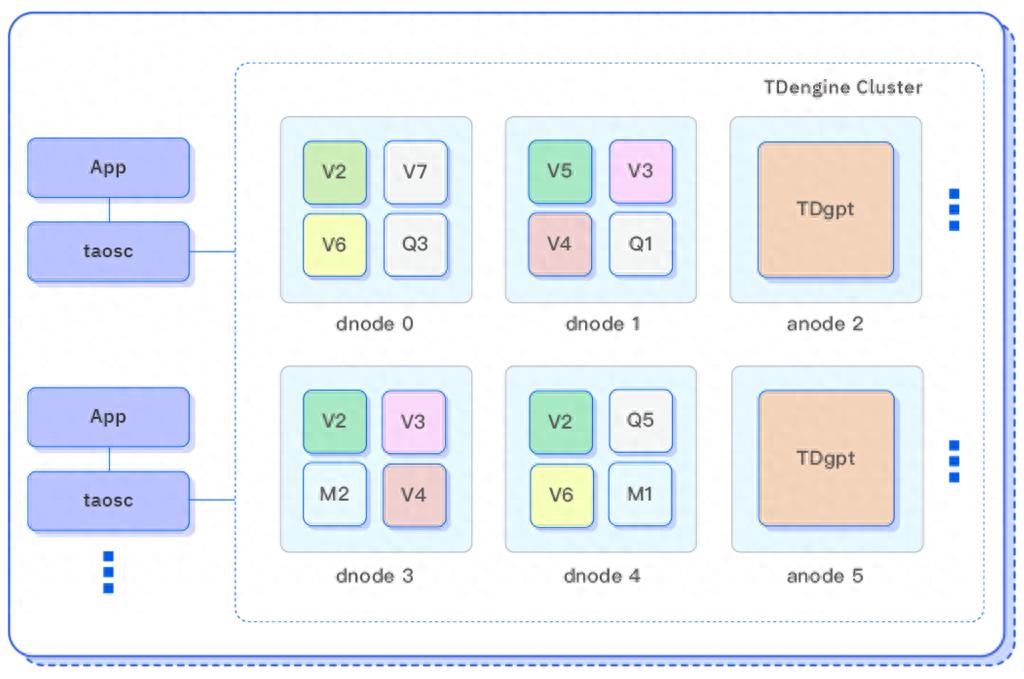
TDengine 發布時序數據分析 AI 智能體 TDgpt,核心代碼開源
如何在基于Arm Neoverse平臺的CPU上構建分布式Kubernetes集群



 工商網監
工商網監
評論