 提高AI算力,異構優化也是關鍵
提高AI算力,異構優化也是關鍵

近期,勁爆亮相的ChatGPT著實讓人們眼前一亮,讓普羅大眾也“親密”體驗了人工智能(AI)的神奇魔力,窺見了智能未來的璀璨前景之一斑。
然而,就在這離生活愈來愈近的AI讓人們對未來充滿無限憧憬、滿懷激動的同時,也有冷靜的分析指出,諸如ChatGPT等AI規模應用也是一個“吞金獸”,其帶來的不僅僅是讓人急呼“AI算力告急”的算力消耗(有研究顯示,中國智能算力需求規模,到2026年就將進入每秒十萬億億次浮點計算(ZFLOPS)級別,達到1,271.4EFLOPS,從2021到2026年,年復合增長率將達52.3%1);更有從云端、邊緣到終端廣泛AI應用場景,使得IT運營環境日益復雜和多樣,讓各種AI方案在異構平臺獲得便捷、易用且有效優化成為急迫的需求。
異構計算,主要指不同類型的指令集和體系架構的計算單元組成的系統的計算方式,在云數據中心、邊緣計算場景等有著廣泛應用。
異構計算的興起與工作負載密切相關,在能有效發揮異構計算優勢的應用場景中,人工智能場景可謂是典型的代表場景之一,不管是深度學習訓練,還是深度學習推理,都會進行大量矩陣運算,需要異構計算提供更有力支撐;而隨著AI應用快速走向邊緣,由此引致的云邊端協同,對異構計算提出了更高要求。計算平臺在提升自身算力水平的同時,也需要通過提供優化策略,幫助用戶更好地提升AI方案的性能,助力AI應用降本增效。
騰訊云創新打造TACO Kit套件,為AI應用提供異構加速
為幫助廣大用戶應對日益復雜的異構環境給AI應用帶來的挑戰,騰訊云創新推出計算加速套件TACO Kit (TencentCloud Accelerated Computing Optimization Kit),通過在異構硬件平臺上提供全棧式的軟硬件解決方案的模式,為AI方案設計者、AI開發人員以及AI使用者構建全新的異構計算加速軟件服務,助其借助多元化異構、高性能加速框架、離線虛擬化技術以及靈活的商業模式,輕松駕馭多元算力,助力AI應用全方位、全場景降本增效。
而作為異構加速服務的入口,TACO Kit內置AI推理加速引擎TACO Infer,能針對AI應用中不同的訓練和服務框架、個性的優化實踐和使用習慣、各異的軟件版本和硬件偏好,以計算加速、無感接入和魯棒易用的特性和優勢,幫助用戶一站式解決AI模型在生產環境中部署與應用的痛點。

圖一 AI推理加速引擎TACO Infer
TACO Infer引擎具備的功能特性包括:
■無感集成:可跨平臺透明適配CPU、GPU、NPU等異構芯片;尊重用戶使用習慣,無需改變模型源格式;無需進行IR(Intermediate Representation,中間表示)轉換,對無顯式算子結構模型友好;
■基于原生框架Runtime:可基于多種流行原生框架,包括TensorFlow、PyTorch、ONNXRuntime 等運行;可基于框架原Runtime構建,并可充分利用框架自定義的擴展機制;
■無縫對接服務框架:包括TF Serving、Triton以及TorchServe等。
基于以上特性,無論在何種場景中,用戶在硬件平臺上部署AI應用,都只需要進行簡單地前端交互,就能讓TACO Kit在后臺以最佳模式啟動工作負載,并獲得更優的推理性能。
而這一優異推理性能的獲得,離不開英特爾和騰訊云面向TACO Kit開展的深度協作加持。具體講,就是將英特爾 Neural Compressor集成到TACO Kit之中,來大幅提升AI推理性能,加速各類AI應用便捷高效落地。
英特爾 Neural Compressor提供優化支持,助力TACO Kit加速推理
英特爾 Neural Compressor是英特爾開源的神經網絡模型壓縮庫,不僅面向如量化、修剪以及知識提取等主流模型壓縮技術,提供了跨多個深度學習框架的統一接口,還具有以下模型性能調優特性:
■具備由精度驅動的自動化調整策略,幫助用戶快速獲得最佳量化模型;
■可使用預定義的稀疏性目標生成修剪模型,實現不同的權重修剪算法;
■能夠從更大的網絡(“教師”)中提取知識用于訓練更小的網絡(“學生”),實現更小的精度損失。
英特爾和騰訊云協作,通過插件的方式將英特爾 Neural Compressor集成到TACO Kit,讓TACO Kit充分利用英特爾 Neural Compressor的優勢特性。如圖二所示,利用量化壓縮技術來為不同的深度深度框架(如TensorFlow、PyTorch、ONNXRuntime等)提供統一的模型優化 API,便捷實現模型推理優化(由FP32數據類型量化為INT8數據類型)。同時,也可以利用壓縮庫內置的精度調優策略,根據不同的模型內部結構生成精度更佳的量化模型,幫助用戶大幅降低模型量化的技術門檻,并有效提升AI模型的推理效率。
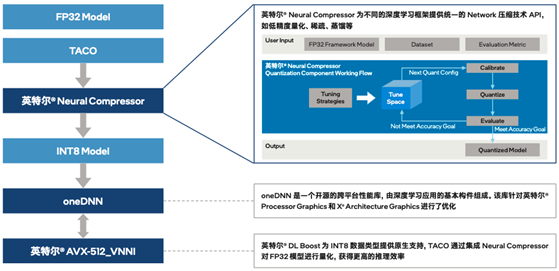
圖二 集成英特爾 Neural Compressor后的TACO Kit工作流程
在云端部署時,量化后的模型可通過英特爾 至強 可擴展平臺內置的英特爾 DL Boost,來獲得有效的硬件加速和更高的推理效率。以指令集中的vpdpbusd指令為例,以往需要3條指令(vpmaddubsw、vpmaddwd、vpaddd)完成的64次乘加過程,現在僅需1條指令(vpdpbusd)即可,并能夠消除運行過程中的處理器飽和問題,再輔之以乘加過程中的中間數值直接從內存播送,可使得處理性能達初始FP32模型的4倍2。這無疑為TACO Kit加速推理,進而幫助用戶在異構環境更高效地構建和部署AI提供了關鍵助力。
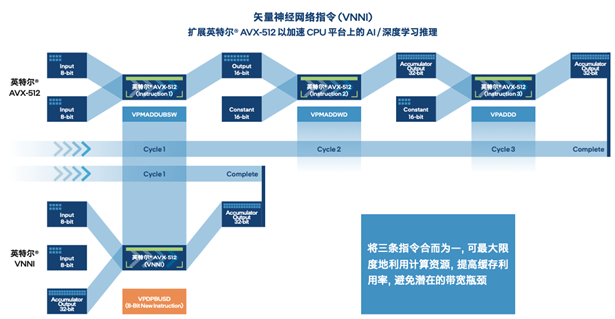
圖三 英特爾 DL Boost(AVX-512_VNNI)技術
方案驗證顯真實性能,展異構AI加速優勢
那么,集成英特爾 Neural Compressor后的TACO Kit的性能究竟有何等驚艷提升呢?實踐最有發言權,數據最有說服力。套件打造完成后,英特爾與騰訊云一起選取了多種被廣泛應用的自然語言處理深度學習模型,對TACO Kit性能加速進行了驗證測試。
測試中,各個深度學習模型在通過TACO Kit進行優化后,使用英特爾 Neural Compressor進行INT8量化及性能調優,推理性能加速結果令人滿意。如圖四所示3,在保持精度水平基本不變的情況下,各深度學習模型的推理性能均獲得顯著提升,提升幅度從55%到139%不等,在其中的bert-base-uncased-mrpc場景中,推理性能更是達到了基準值的2.39倍。

圖四 集成英特爾 Neural Compressor的TACO Kit所帶來的推理性能加速4
對TACO Kit引入英特爾 Neural Compressor獲得的大幅性能加速,騰訊云異構計算專家級工程師葉帆直言,這一合作成果能幫助不同角色的用戶在異構硬件平臺上獲得便捷、易用且經過有效優化的 AI 加速能力,助力AI 應用實現全方位、全場景的降本增效。而英特爾 Neural Compressor 是 TACO Kit 中 AI 推理負載獲得充分性能加速的有效技術保證。
基于這一成果,英特爾和騰訊云也將面向未來繼續深化合作,通過融合硬件廠商優化算子、自研AI編譯技術升級等措施,驅動TACO Infer在軟硬件兼容性和性能上不斷迭代優化。同時,雙方還計劃進一步將第四代英特爾 至強 可擴展平臺及其內置的深度學習加速技術與騰訊計算加速套件TACO Kit相融合,借助新平臺更為澎湃的算力輸出與深度學習加速新技術,為用戶提供更加高效可用的異構AI加速能力,進而在推動AI走向更廣泛應用的同時,助力應對多模態大模型等對算力提出的更嚴峻挑戰,驅動智能應用向縱深化演進,為經濟社會的高質量發展提供強勁數字生產力。
審核編輯 :李倩
-
英特爾
+關注
關注
61文章
10301瀏覽量
180451 -
AI
+關注
關注
91文章
39793瀏覽量
301404 -
人工智能
+關注
關注
1817文章
50098瀏覽量
265372
原文標題:提高AI算力,異構優化也是關鍵
文章出處:【微信號:英特爾中國,微信公眾號:英特爾中國】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄

解鎖邊緣智能新境界,天數智算AI邊緣算力模組賦能端側AI應用新篇章?

解鎖邊緣智能新境界,天數智算AI邊緣算力模組賦能端側AI應用新篇章?


從CPU、GPU到NPU,美格智能持續優化異構算力計算效能

硅芯科技:AI算力突破,新型堆疊EDA工具持續進化
國產AI芯片真能扛住“算力內卷”?海思昇騰的這波操作藏了多少細節?
什么是AI算力模組?

什么是AI算力模組?


RAKsmart智能算力架構:異構計算+低時延網絡驅動企業AI訓練范式升級
弘信電子旗下燧弘華創與聯想發布多元異構算力調度平臺
DeepSeek推動AI算力需求:800G光模塊的關鍵作用
存力接棒算力,慧榮科技以主控技術突破AI存儲極限




 工商網監
工商網監
評論