 什么是機器學習?ML 基礎知識簡介
什么是機器學習?ML 基礎知識簡介

本文旨在為硬件和嵌入式工程師提供機器學習 (ML)、它是什么、它是如何工作的、為什么它很重要以及 TinyML 如何適應。
機器學習是一個一直存在且經常被誤解的技術概念。幾十年來,這種實踐是一門使用復雜處理和數學技術使計算機能夠找到大量輸入和輸出數據之間相關性的科學,這在我們的集體技術意識中已經存在了幾十年。近年來,科學已經爆炸式增長,這得益于以下方面的改進:
計算能力
圖形處理單元 (GPU) 架構支持的并行處理
適用于大規模工作負載的云計算
事實上,該領域一直專注于桌面和基于云的使用,以至于許多嵌入式工程師并沒有過多考慮ML如何影響他們。在大多數情況下,它沒有。
然而,隨著提尼毫升或微型機器學習(在微控制器和單板計算機等受限設備上的機器學習),ML已與所有類型的工程師相關,包括那些從事嵌入式應用程序的工程師。除此之外,即使您熟悉TinyML,對機器學習有一個具體的了解也很重要。
在本文中,我將概述機器學習、其工作原理以及為什么它對嵌入式工程師很重要。
什么是機器學習?
作為人工智能 (AI)領域的一個子集,機器學習是一門專注于使用數學技術和大規模數據處理來構建可以找到輸入和輸出數據之間關系的程序的學科。作為一個總稱,人工智能涵蓋了計算機科學的一個廣泛領域,專注于使機器能夠在沒有人為干預的情況下“思考”和行動。它涵蓋了從“通用智能”或機器以與人類相同的方式思考和行動的能力,到專門的、面向任務的智能,這是ML所屬的地方。
我過去聽到的最強大的ML定義方式之一是與經典計算機編程中使用的傳統算法方法進行比較。在經典計算中,工程師向計算機提供輸入數據(例如,數字 2 和4)以及將它們轉換為所需輸出的算法(例如,將 x 和 y 相乘得到 z)。當程序運行時,提供輸入,并應用算法來生成輸出。如圖 1 所示。

圖1. 在經典方法中,我們為計算機提供輸入數據和算法,并要求答案。
另一方面,ML是向計算機提供一組輸入和輸出并要求計算機識別“算法”(或模型,使用ML術語)的過程,每次都將這些輸入轉換為輸出。通常,這需要大量輸入,以確保模型每次都能正確識別正確的輸出。
例如,在圖 2 中,如果我向 ML 系統提供數字 2 和 2,以及預期的輸出 4,它可能會決定算法始終將這兩個數字相加。但是,如果我隨后提供數字 2和 4 以及預期的輸出 8,則模型將從兩個示例中了解到,正確的方法是將提供的兩個數字相乘。
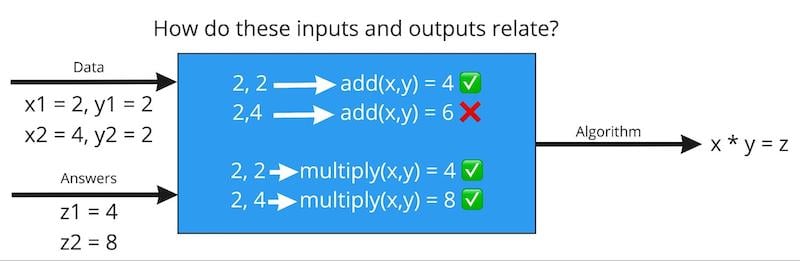
圖2. 使用ML,我們擁有數據(輸入)和答案(輸出),并且需要計算機通過確定輸入和輸出如何以適用于整個數據集的方式關聯來得出各種算法。
鑒于我使用一個簡單的例子來定義一個復雜的字段,你可能會問:為什么人們會費心使簡單的復雜化?為什么不堅持我們的經典算法計算方法呢?
答案是,傾向于機器學習的問題類別通常不能通過純粹的算法方法來表達。沒有簡單的算法可以給計算機一張圖片,并要求它確定它是否包含貓或人臉。相反,我們利用ML并給它數千張圖片(作為像素集合),其中有貓,也有人臉,兩者都沒有,并且通過學習如何將這些像素和像素組與預期輸出相關聯來開發模型。當機器看到新數據時,它會根據之前看到的所有示例推斷輸出。這個過程的這一部分,通常稱為預測或推理,是ML的魔力。
這聽起來很復雜,因為它確實如此。在嵌入式和物聯網 (IoT) 系統領域,ML越來越多地被用于幫助機器視覺、異常檢測和預測性維護等領域。在這些領域中,我們收集大量數據(圖像和視頻、加速度計讀數、聲音、熱量和溫度),用于監控設施、環境或機器。然而,我們經常難以將數據轉化為我們可以采取行動的洞察力。條形圖很好,但是當我們真正想要的是能夠在機器中斷和離線之前預測機器需要服務時,簡單的算法方法就行不通了。
機器學習開發循環
進入機器學習。在有能力的數據科學家和ML工程師的指導下,這個過程從數據開始。也就是說,我們的嵌入式系統創建的大量數據。ML開發過程的第一步是在將數據輸入模型之前收集數據并對其進行標記。標記是一個關鍵的分類步驟,也是我們將一組輸入與預期輸出相關聯的方式。
ML 中的標記和數據收集
例如,一組加速度計 x、y 和 z 值可能對應于計算機處于空閑狀態,另一組可能表示計算機運行良好,第三組可能對應于問題。圖 3中可以看到高級描述。
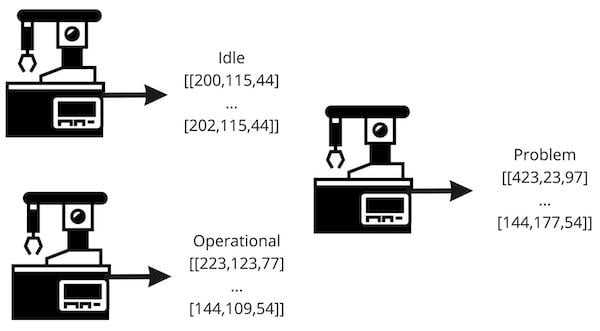
圖3. ML 工程師在數據收集過程中使用標簽對數據集進行分類。
數據收集和標記是一個耗時的過程,但對于正確處理至關重要。雖然 ML領域有一些創新,利用預先訓練的模型來抵消一些工作和新興工具來簡化來自真實系統的數據收集,但這是一個不容錯過的步驟。世界上沒有ML模型可以可靠地告訴您您的機器或設備是否運行良好或即將崩潰,而無需看到該機器或其他類似機器的實際數據。
機器學習模型開發、訓練、測試、優化
數據收集后,接下來的步驟是模型開發、訓練、測試和優化。在此階段,數據科學家或工程師創建一個程序,該程序引入收集的大量輸入數據,并使用一種或多種方法將其轉換為預期的輸出。解釋這些方法可以填滿體積,但足以說明大多數模型對其輸入執行一組轉換(例如,向量和矩陣乘法)。此外,它們將相互調整每個輸入的權重,以找到一組與預期輸出可靠相關的權重和函數。
該過程的這一階段通常是迭代的。工程師將調整模型、使用的工具和方法,以及在模型訓練期間運行的迭代次數和其他參數,以構建能夠可靠地將輸入數據與正確的輸出(也稱為標簽)相關聯的東西。一旦工程師對這種相關性感到滿意,他們就會使用訓練中未使用的輸入來測試模型,以查看模型在未知數據上的表現。如果模型在此新數據上表現不佳,工程師將重復該循環(如圖4 所示),并進一步優化模型。

圖4. 模型開發是一個包含許多步驟的迭代過程,但它始于數據收集。
模型準備就緒后,將部署該模型并可用于針對新數據的實時預測。在傳統 ML中,模型部署到云服務,以便正在運行的應用程序可以調用它,該應用程序提供所需的輸入并從模型接收輸出。應用程序可能會提供一張圖片并詢問是否有人在場,或者一組加速度計讀數,并詢問模型這組讀數是否與空閑、正在運行或損壞的計算機相對應。
正是在這個過程的這一部分,TinyML是如此重要和具有開創性。
那么TinyML適合在哪里呢?
如果還不清楚,機器學習是一個數據密集型過程。當您嘗試通過關聯派生模型時,您需要大量數據來提供該模型。數百張圖像或數千個傳感器讀數。事實上,模型訓練的過程是如此密集,如此專業化,以至于幾乎對任何人來說都是資源消耗者。
中央處理器 (CPU),無論多么強大。相反,ML 中常見的矢量和矩陣數學運算與圖形處理應用程序沒有什么不同,這就是為什么 GPU
已成為模型開發如此受歡迎的選擇。
鑒于對強大計算的需求,云已成為減輕訓練模型工作并托管它們以進行實時預測的事實上的地方。雖然模型訓練現在是,并且仍然是云的領域,特別是對于嵌入式和物聯網應用程序,但我們越接近將實時預測的能力轉移到捕獲數據的地方,我們的系統就會越好。在微控制器上運行模型時,我們受益于內置安全性和低延遲,以及在本地環境中做出決策和采取行動的能力,而無需依賴互聯網連接。
這是TinyML的領域,平臺公司喜歡 邊緣脈沖 正在構建基于云的傳感器數據收集和 ML 架構工具,以輸出專為 微控制器單元
(MCU)。其中越來越多的硅供應商,從 意法半導體 自 阿里夫半導體 正在構建具有類似 GPU 的計算功能的芯片,使其非常適合在收集數據的位置與傳感器一起運行
ML 工作負載。
對于嵌入式和物聯網工程師來說,現在是探索機器學習世界的最佳時機,從云到最小的設備。我們的系統只會比以往任何時候都更加復雜,處理的數據也越來越多。將ML帶到邊緣意味著我們可以處理這些數據并更快地做出決策。
-
人工智能
+關注
關注
1819文章
50185瀏覽量
266283 -
數據收集
+關注
關注
0文章
73瀏覽量
11756 -
模型
+關注
關注
1文章
3778瀏覽量
52195 -
ML
+關注
關注
0文章
154瀏覽量
35504 -
機器學習
+關注
關注
66文章
8558瀏覽量
137112
發布評論請先 登錄
PCB基礎知識簡介
PLC基礎知識簡介


什么是單片機怎樣學習?單片機基礎知識及Proteus應用簡介資料概述
液壓基礎知識的學習課件免費下載





 工商網監
工商網監
評論