 ConvNeXt模型更新了!
ConvNeXt模型更新了!

ConvNeXt 模型更新了!
經過幾十年的基礎研究,視覺識別領域已經迎來了大規模視覺表征學習的新時代。預訓練的大規模視覺模型已經成為特征學習(feature learning)和視覺應用的基本工具。視覺表征學習系統的性能在很大程度上受到三個主要因素的影響:模型的神經網絡架構、訓練網絡的方法以及訓練數據。每個因素的改進都有助于模型整體性能的提高。
神經網絡架構設計的創新在表征學習領域一直發揮著重要作用。卷積神經網絡架構(ConvNet)對計算機視覺研究產生了重大影響,使得各種視覺識別任務中能夠使用通用的特征學習方法,無需依賴人工實現的特征工程。近年來,最初為自然語言處理而開發的 transformer 架構因其適用于不同規模的模型和數據集,在其他深度學習領域中也開始被廣泛使用。
ConvNeXt 架構的出現使傳統的 ConvNet 更加現代化,證明了純卷積模型也可以適應模型和數據集的規模變化。然而,要想對神經網絡架構的設計空間進行探索,最常見方法仍然是在 ImageNet 上進行監督學習的性能基準測試。
另一種思路是將視覺表征學習的重點從有標簽的監督學習轉向自監督預訓練。自監督算法將掩碼語言建模引入視覺領域,并迅速成為視覺表征學習的一種流行方法。然而,自監督學習通常會使用為監督學習設計的架構,并假定該架構是固定的。例如,掩碼自編碼器(MAE)使用了視覺 transformer 架構。
有一種方法是將這些架構和自監督學習框架結合起來,但會面臨一些具體問題。例如,將 ConvNeXt 與 MAE 結合起來時就會出現如下問題:MAE 有一個特定的編碼 - 解碼器設計,該設計針對 transformer 的序列處理能力進行了優化,這使得計算量大的編碼器專注于那些可見的 patch,從而降低了預訓練成本。但是這種設計可能與標準的 ConvNet 不兼容,因為后者使用了密集的滑動窗口。此外,如果不考慮架構和訓練目標之間的關系,那么也就不清楚是否能達到最佳性能。事實上,已有研究表明用基于掩碼的自監督學習來訓練 ConvNet 是很困難的,而且實驗證據表明,transformer 和 ConvNet 可能在特征學習方面存在分歧,會影響到最終表征的質量。
為此,來自 KAIST、Meta、紐約大學的研究者(包括ConvNeXt一作劉壯、ResNeXt 一作謝賽寧)提出在同一框架下共同設計網絡架構和掩碼自編碼器,這樣做的目的是使基于掩碼的自監督學習能夠適用于 ConvNeXt 模型,并獲得可與 transformer 媲美的結果。

論文地址:https://arxiv.org/pdf/2301.00808v1.pdf
在設計掩碼自編碼器時,該研究將帶有掩碼的輸入視為一組稀疏 patch,并使用稀疏卷積處理可見的部分。這個想法的靈感來自于在處理大規模 3D 點云時使用稀疏卷積。具體來說,該研究提出用稀疏卷積實現 ConvNeXt,然后在微調時,權重不需要特殊處理就能被轉換回標準的密集網絡層。為了進一步提高預訓練效率,該研究用單個 ConvNeXt 替換 transformer 解碼器,使整個設計完全卷積網絡化。研究者觀察到加入這些變化后:學習到的特征是有用的并且改進了基線結果,但微調后的性能仍然不如基于 transformer 的模型。
然后,該研究對不同訓練配置的 ConvNeXt 的特征空間進行了分析。當直接在掩碼輸入上訓練 ConvNeXt 時,研究者發現 MLP 層存在潛在的特征崩潰(feature collapse)問題。為了解決這個問題,該研究提出添加一個全局響應歸一化層(Global Response Normalization layer)來增強通道間的特征競爭。當使用掩碼自編碼器對模型進行預訓練時,這種改進最為有效,這表明監督學習中重復使用監督學習中的固定架構設計可能不是最佳方法。
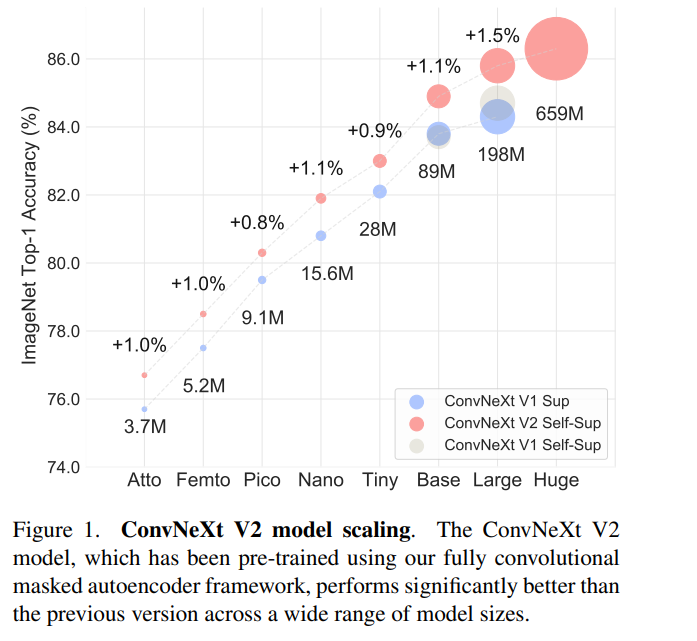
基于以上改進,該研究提出了 ConvNeXt V2,該模型在與掩碼自編碼器結合使用時表現出了更好的性能。同時研究者發現 ConvNeXt V2 在各種下游任務上比純 ConvNet 有明顯的性能提升,包括在 ImageNet 上的分類任務、COCO 上的目標檢測和 ADE20K 上的語義分割。
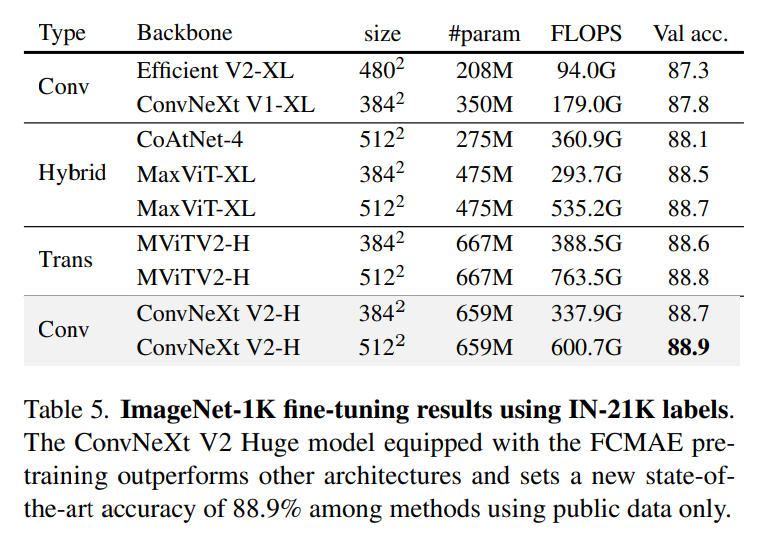
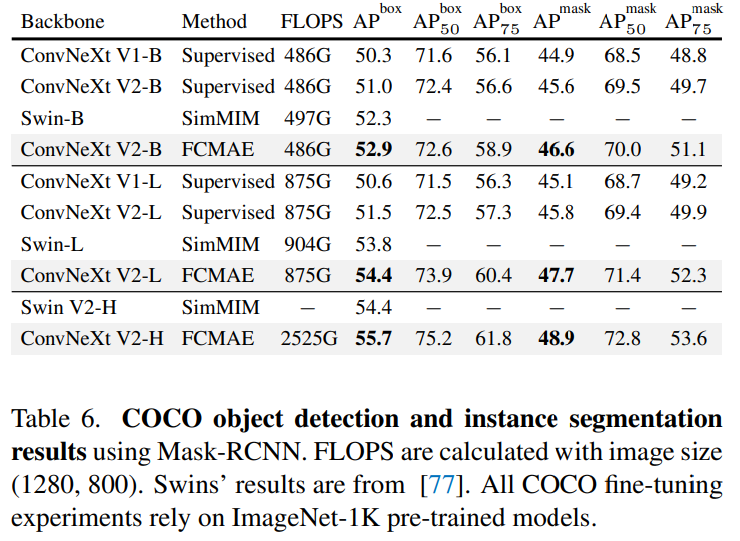
方法介紹
全卷積掩碼自編碼器
該研究提出的方法在概念上很簡單,是以完全卷積的方式運行的。學習信號通過對原始的視覺輸入隨機掩碼來生成,同時掩碼的比率需要較高,然后再讓模型根據剩余的 context 預測缺失的部分。整體框架如下圖所示。
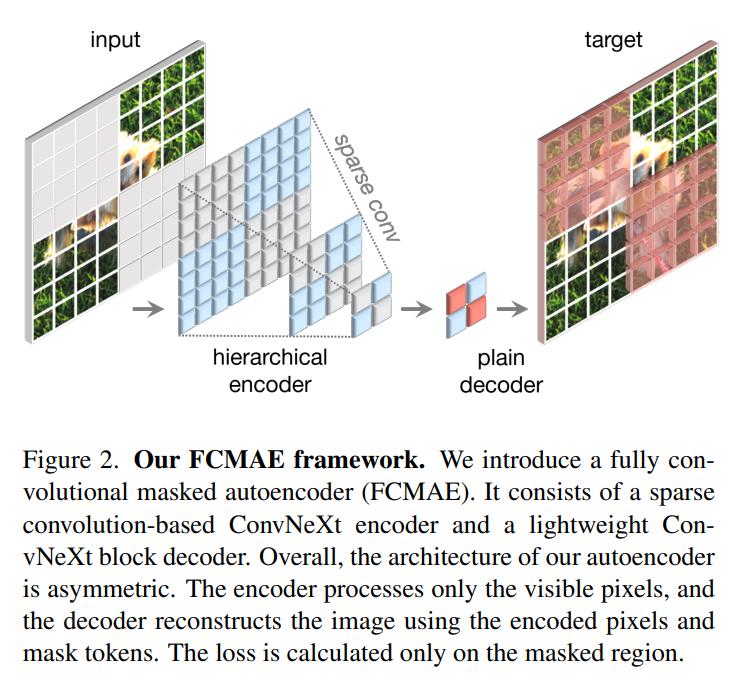
框架由一個基于稀疏卷積的 ConvNeXt 編碼器和一個輕量級的 ConvNeXt 解碼器組成,其中自編碼器的結構是不對稱的。編碼器只處理可見的像素,而解碼器則使用已編碼的像素和掩碼 token 來重建圖像。同時只在被掩碼的區域計算損失。
全局響應歸一化
大腦中有許多促進神經元多樣性的機制。例如,側向抑制可以幫助增強激活神經元的反應,增加單個神經元對刺激的對比度和選擇性,同時還可以增加整個神經元群的反應多樣性。在深度學習中,這種形式的側向抑制可以通過響應歸一化(response normalization)來實現。該研究引入了一個新的響應歸一化層,稱為全局響應歸一化 (GRN),旨在增加通道間的對比度和選擇性。GRN 單元包括三個步驟:1) 全局特征聚合,2) 特征歸一化,3) 特征校準。如下圖所示,可以將 GRN 層合并到原始 ConvNeXt 塊中。
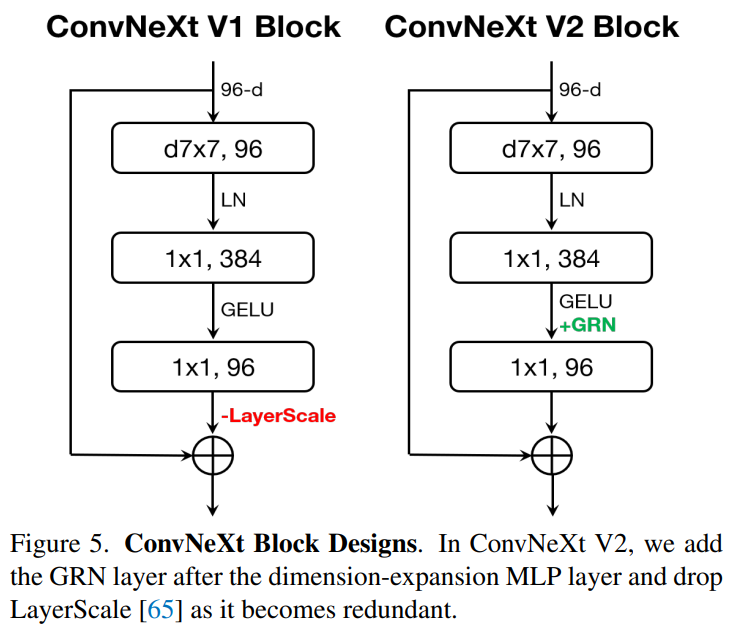
研究者根據實驗發現,當應用 GRN 時,LayerScale 不是必要的并且可以被刪除。利用這種新的塊設計,該研究創建了具有不同效率和容量的多種模型,并將其稱為 ConvNeXt V2 模型族,模型范圍從輕量級(Atto)到計算密集型(Huge)。
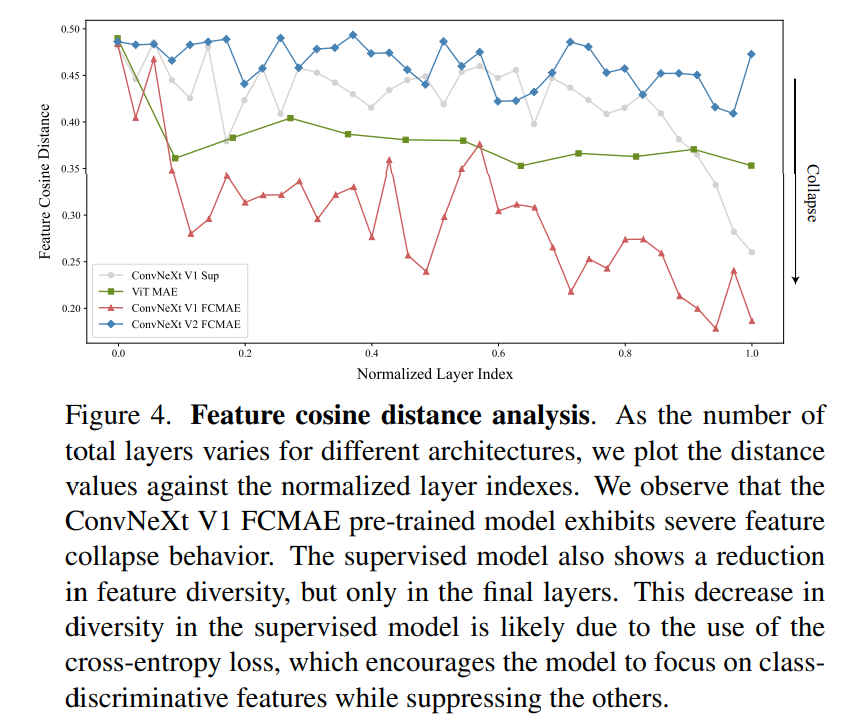
為了評估 GRN 的作用,該研究使用 FCMAE 框架對 ConvNeXt V2 進行預訓練。從下圖 3 中的可視化展示和圖 4 中的余弦距離分析,可以觀察到 ConvNeXt V2 有效地緩解了特征崩潰問題。余弦距離值一直很高,表明在網絡層傳遞的過程中可以保持特征的多樣性。這類似于使用 MAE 預訓練的 ViT 模型。這表明在類似的掩碼圖像預訓練框架下,ConvNeXt V2 的學習行為類似于 ViT。

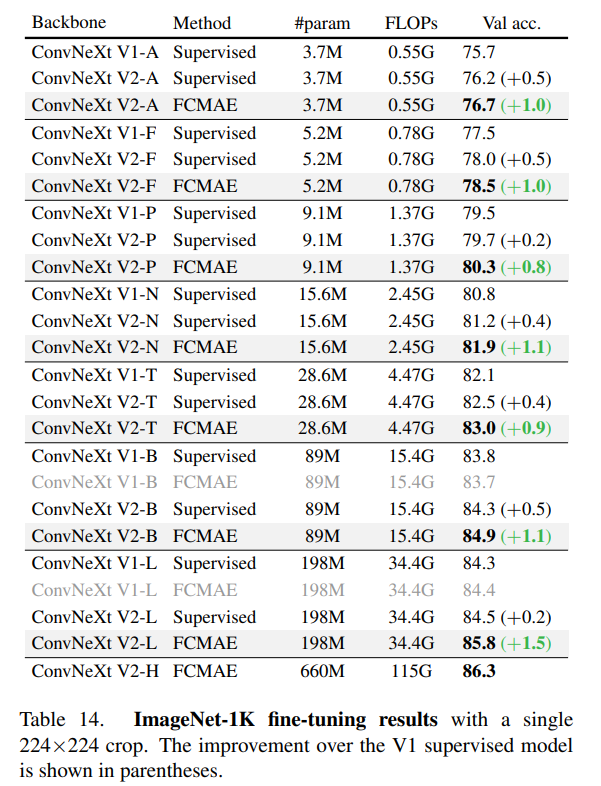
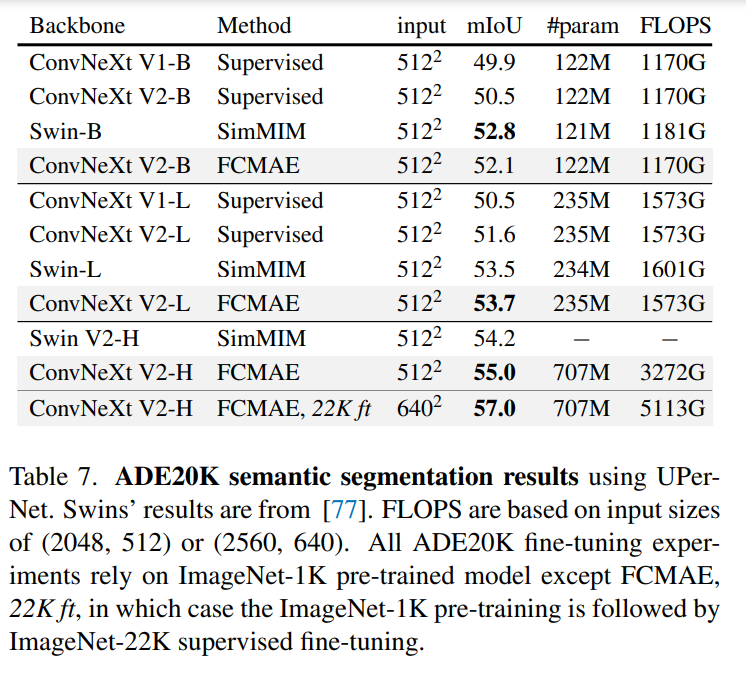
該研究進一步評估了微調性能,結果如下表所示。
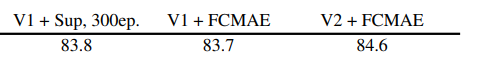
當配備 GRN 時,FCMAE 預訓練模型可以顯著優于使用 300 個 epoch 訓練得到的監督模型。GRN 通過增強特征多樣性來提高表征質量,這對于基于掩碼的預訓練是至關重要的,并且在 ConvNeXt V1 模型中是不存在的。值得注意的是,這種改進是在不增加額外參數開銷,且不增加 FLOPS 的情況下實現的。
最后,該研究還檢查了 GRN 在預訓練和微調中的重要性。如下表 2 (f) 所示,無論是從微調中刪除 GRN,還是在微調時添加新初始化的 GRN,性能都會顯著下降,這表明在預訓練和微調中 GRN 很重要。

審核編輯 :李倩
-
解碼器
+關注
關注
9文章
1219瀏覽量
43426 -
編碼器
+關注
關注
45文章
3953瀏覽量
142650 -
Transformer
+關注
關注
0文章
156瀏覽量
6937
原文標題:ConvNeXt V2來了,僅用最簡單的卷積架構,性能不輸Transformer
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學堂】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
MES模型靜態測試工具更新信息 01/2026

利用NVIDIA Cosmos開放世界基礎模型加速物理AI開發
脈沖神經元模型的硬件實現
onnx模型轉換rknn模型出現問題
亞馬遜云科技Amazon Bedrock模型再更新,Anthropic最新版Claude4模型現已上線
螞蟻數科正式發布金融推理大模型
瑞芯微模型量化文件構建
FA模型訪問Stage模型DataShareExtensionAbility說明
如何將一個FA模型開發的聲明式范式應用切換到Stage模型
谷歌Gemini 2.5模型系列更新
ABAQUS內置了豐富的材料模型庫




 工商網監
工商網監
評論