 Cache與性能優化精彩問答38條
Cache與性能優化精彩問答38條

編者按:1月8日晚上,《深入理解cache訓練營》講師甄建勇和閱碼場資深用戶wisen圍繞Cache和性能優化展開了一場線上圓桌討論。本文是對圓桌內問題的解答整理,不一而詳,供大家參考。感謝閱碼場用戶王建峰對于問題的整理。
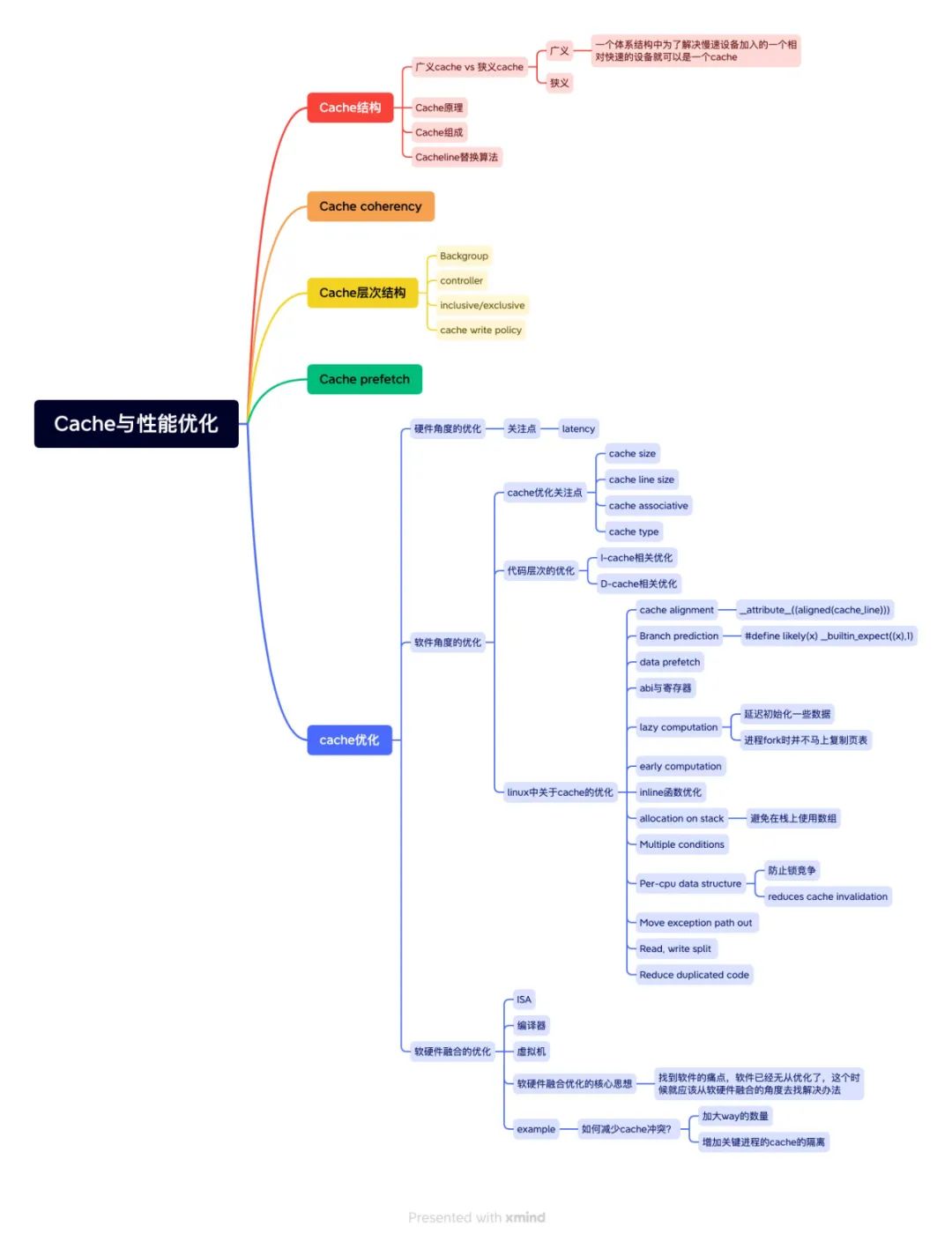
圖:wisen整理的Cache和性能優化的思維導圖
1、能不能舉個日常生活的例子來理解什么是Cache?
例如,我在商場購物時,把要買的東西先把它放到小推車中,最后統一結賬。此時,把 自己想象成芯片中的 CPU,購物車是芯片中 Cache,柜臺是芯片的輸出口。再例如,我在圖書館看書,隨手將喜歡看的書放到柜子里,這里某一些書我會反復看,不想看時把書放回書架上。此時,我是 CPU,書柜是 Cache,書架是下一級存儲器。
2、關于 Cache和硬件設計的問題:在具體的 SOC和 CPU實現的時候,Cache占用面積給 Cache設計的限制有多大?
占用非常大的面積,大概在一半以上,而且一個好的 Cache 的設計復雜度非常高,可能比較 CPU 的 Pipeline 還要復雜。這里要考慮成本,設計復雜度,或者其他方面的考慮。你知道 L1 Cache 為什么一般是 32K 嗎?如果畫出曲線的話它會有一個拐點。另外一個角度是根據業務的場景,來設計 Cache Size,包括 Cache 的規格的定義。
3、像現在有很多的服務器的芯片,一上來就有 128個核,做這種 SOC設計的時候有需要特別考慮的點嗎?
像這種設計的內存模型一般是 NUMA 和 UMA 的混合,考慮平衡性和靈活性。
刷 Cache時沒有一致性協議保證。比如有兩個 Core,其中一個 Core刷 Cache,(要保證一致性)另外個 Core也要刷。這個時候時一個 Core發中斷,另一個 Core收到中斷以后在去執行。有遇到過這種場景嗎?
情況比較復雜,如果是一個主核和一個從核刷的話,需要這種方式來刷。如果運行虛擬機的話,只能刷自己的。
4、為什么需要 Cache Line Size對齊?
提高對 cache 的利用率,避免浪費。我們假設一個 Cache Line 的 Size 是 64 Byte,例如
?如果有 32 Byte 的數據要存入 Cache ,在 Cache Line 內部沒有對齊的話(比如存放到中間的某一個區域),這時在想要向這個 Cache Line 繼續存儲 32 Byte 的數據時,剩余 32 Byte 的空間卻無法存儲這一部分數據,那么就會造成資源浪費。
?如果有 64 Byte 的數據要存入 Cache ,在 Cache Line 起始地址沒有對齊的話(地址沒有按照 size 的倍數對齊),實際上占用2個 Cache Line Size ,可能就會多造成一個 Cache Line 的浪費。
5、Cache指令預取和 BTB預取有什么區別嗎?
BTB 根據硬件自己的算法做預測的,和 Cache 指令預取(likely 函數)相互補充,使得整體效益最大。
6、L1/L2/L3/SYSTEM/Cache相互是之間的聯系是怎么樣的?
它們是一個金字塔類型,一般情況越往下的 capacity 越大,速度越慢。它們之間關系的話有兩種:inclusive 和 exclusive。inclusive 表示是一個包含關系; exclusive 相反的關系,例如 L1 里有的 在 L2 一定沒有。
7、我們主要針對 L2/L3/Cache做的代碼優化吧?
不僅僅是這些。課程在詳細展開討論。
8、System Cache一般是 DDR前面的是吧?
結論正確。這個提問方式不是特別的好,可以問 System Cache 干嘛用的呢? 一般來說 L1/L2/L3 是給 CPU 來用的,而 System 中的一些 IP ,比如 GPU 也需要緩存的話,可以使用 System Cache 。
9、單 Cache的優化方向。除 Cache Line的按場景分配,對齊,之外,在內存本身上還有什么樣的優化方向?
其中一個是結合程序本身的行為進行優化,不同場景的分配算法;其中另一個方向 Cache Line 的壓縮。
10、各級Cache大小如何選擇,有哪些選擇標準?不同大小組合對不同性能影響怎樣?
例如 PPA 、PPAC 、PPACY。
11、以 VIPT為例,Cache訪問時候 Index到底是怎么從虛擬地址里取出來的,Tag又是取了物理地址的那部分?
地址到達 Cache 之前,假設是 VIPT ,Index 查找直接跨過 MMU 到達 L1 Cache ,Index 直接從虛擬地址取出對應的位就可以了。Tag 的話看 Cache 的組織,幾路組相連,知道 Cache Size 就能知道 Tag 大小。實際上這個地方,在實際的 Cache 中還要考慮 MMU,考慮虛擬機,考慮不同的進程。
12、如何提升 Cache命中率,有哪些方式方法?
如圖片歸納的方法。如果用一句話總結的話,局部性越好一般(Cache命中率)越高的。局部性是指時間的局部性和空間的局部性,就是說 CPU 越是頻繁的訪問相同的物理地址,Cache 的命中率是越高的。
13、請問下做 Cache性能優化的常用手段有哪些啊。Perf采集?
如圖片歸納的方法。Perf 采集時其中的一部分。我們的邏輯時這樣,我們做 Cache 性能優化,(前提是)要先了解它,當我們了解之后,甚至是非常熟悉和通透之后,很多優化的算法思路就會涌現出來。
14、exclusive有什么好處與代價?
如果從上層看它的等價的 Cache Size 是變大的,因為是互斥的嘛。例如你有兩個桶,雨水從屋子上留下來,這兩個桶是重疊呢還是不重疊呢? 此時桶就是 Cache,雨水就是流入的數據,exclusive 不重疊會讓局部變大一些。
15、請問 ARM64架構下,如何理解 Cache refill和 Cache allocate的異同?謝謝
Cache allocate 策略是什么樣子的,怎么去走 refill 策略。這里做法有很多,比如是直接去拿,還是等一等,如果等的話要等多久。課程在詳細展開討論。
這個壓縮是平臺硬件設計的行為還是軟件算法?
軟硬件結合設計。
17、VIPT也有 Cache的重名問題。這個一般要怎么解決啊?
ASID
18、Cache設計時遇到什么嚴重問題?
兩個比較嚴重的問題,其中一個時物理地址和虛擬地址發生錯亂,一個物理地址對應到兩個虛擬地址,或者一個虛擬地址對應到兩個物理地址;另外一個時同一塊數據存放到兩個不同的 Cache Line 里面。課程在詳細展開討論。
19、請問關于 Cache壓縮之類的配置是看 Cache的 datasheet還是 armarchtrm?
armarchtrm
20、為什么要避免在棧上用數組?
有兩個原因,第一個是在棧里面分配數組,數組分配的初始化,對 Cache 是一個操作。然后再多進程切換時,棧的數組(在Cache中)還會被刷掉。所以對于比較大的數組,用全局變量分配比較好。如果在棧上分配的話,在初始化的時候(Cache)被沖刷。
21、老師課程會講 innersharebale/outershareable/pou/poc嗎?
會。課程中深入討論。
22、課程會講 CPU/GPU/NPU架構方面的內容嗎?
會。講師個人經歷過多年的 CPU/GPU/NPU 的架構設計。課程中深入討論。
23、請問同一個 SoC/L1/L2/L3/Cache的組織方式相同么?會不會 L1用 vipt,L2用 pipt?
其中 PIVT 很少見之外,其他三種都會用。有很多 L2 用 PIPT。課程中深入討論。
L1主要負責速度, L2主要負責廣度
正確。
24、inclusive與 exclusive在 Cache一致性維護上有什么區別?
inclusive 與 exclusive 在設計的時候,它們的要求是不一樣的,硬件行為是不一樣的。
25、L1中的數據在 L2中的位置是固定的么?
不固定。
26、CPU訪問 Cache和訪問 DDR在 Power上的消耗比例?
1000倍量級。
27、有啥工具可以分析不同 NUMA節點核的 Cache invalidate的延遲嗎?
芯片規格說明書里一般會提供。
28、編譯器優化會做自動的 Cacheline對齊嗎?
向編譯器里加一些編譯選項。
29、有哪些專門測試 Cache性能測試的 benchmark嗎?
非常多。
30、Snoop啥時候工作呢?
是一個 Standby 的機制,一直在工作。
31、Cache怎么仿真?
僅在 Cache 的設計階段。
32、什么情況下會將 Cache invalid之后,然后 flush到 DDR中?
Cache Line 一般放置處理的數據,flush 為了將 Cache 騰空
33、什么情況下會將 Cache invalid之后,然后 flush到 DDR中?例如數據從外設(用DMA)搬進來,這時候數據在 DDR中,此時 CPU想要不過 Cache直接讀 DDR中的數據。
直接設置 non-cached 的地址去讀寫就可以了。這種情況是申請的時候是帶 cache 的地址空間,然后直接就用的話,訪問數據是帶 cache 的。
34、busrtmemaccess導致同一個 Cacheline多次連續 miss,一般 pmu會重復計算嗎?
看 pmu 的 spec。
35、監聽式和目錄式一致性維護有什么區別?
完全兩套不同的機制。監聽式是一個廣播的機制,適合核比較小的情況。目錄式完全相反。
36、CPU內存和外設共享,外設寫到 DDR中,然后 CPU讀。之前遇到個這樣的問題,有兩個Cache,在一個 Cache中可能因為預取一些數據。那么在另外一個 Cache中做無效,那么在原來 Cache已經預取的那一部分數據沒有辦法做處理,這樣 CPU就讀不到外設搬到 DDR上新的數據。因為 Cache預取的緣故,在另外 Cache中做無效是沒有用的這種情況,怎么處理呢?
原來 Cache 讀的時候,將預取功能 disable 掉。但是預取不能一直關掉,只有代碼在危險區的時候,才關掉。
37、什么場景要用到 RSB?
動態指令修改。
38、DSB的原理是什么?
原理很簡單,實際上在硬件上結構里面,它是有先后順序的。只不過在為了某種性能的考慮,允許它亂序。但是有些特殊的指令,比如你提到 Barrier 指令,出現這類指令的時候,決定這條指令的完成。CPU 內部 Pipeline 里面,核里面,是有一定的順序的。所有的指令都有一個提交態,我們會知道單條指令的取指、譯碼、執行,寫回是誰給他的呢? 實際上是 Cache 給它的。Cache 是誰給他的呢? 實際上是下面的 DDR 給它的。所以實際上這里是一個非常大的環,看起來這個指令在 CPU Core 里面,一級一級來,最終這個指令才能提交。硬件上要保證它的順序,通過它的 FIFO。FIFO 里面你怎么 POP 出來,POP 出來之后,怎么釋放,要等它的下一級。
審核編輯 :李倩
-
芯片
+關注
關注
463文章
54007瀏覽量
465903 -
cpu
+關注
關注
68文章
11277瀏覽量
224938 -
Cache
+關注
關注
0文章
130瀏覽量
29707
原文標題:Cache與性能優化精彩問答38條
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
探索MAX25588:38通道局部調光LED驅動器的卓越性能
探索MAX25580:38通道局部調光LED驅動器的卓越性能
DAC38RF83技術手冊

DAC38RF93技術手冊




 工商網監
工商網監
評論