 無殘差連接或歸一化層,也能成功訓練深度Transformer
無殘差連接或歸一化層,也能成功訓練深度Transformer

盡管取得了很多顯著的成就,但訓練深度神經網絡(DNN)的實踐進展在很大程度上獨立于理論依據。大多數成功的現代 DNN 依賴殘差連接和歸一化層的特定排列,但如何在新架構中使用這些組件的一般原則仍然未知,并且它們在現有架構中的作用也依然未能完全搞清楚。
殘差架構是最流行和成功的,最初是在卷積神經網絡(CNN)的背景下開發的,后來自注意力網絡中產生了無處不在的 transformer 架構。殘差架構之所以取得成功,一種原因是與普通 DNN 相比具有更好的信號傳播能力,其中信號傳播指的是幾何信息通過 DNN 層的傳輸,并由內核函數表示。
最近,使用信號傳播原則來訓練更深度的 DNN 并且殘差架構中沒有殘差連接和 / 或歸一化層的參與,成為了社區感興趣的領域。原因有兩個:首先驗證了殘差架構有效性的信號傳播假設,從而闡明對 DNN 可解釋性的理解;其次這可能會實現超越殘差范式的 DNN 可訓練性的一般原則和方法。
對于 CNN,Xiao et al. (2018)的工作表明,通過更好初始化提升的信號傳播能夠高效地訓練普通深度網絡,盡管與殘差網絡比速度顯著降低。Martens et al. (2021) 的工作提出了 Deep Kernel Shaping (DKS),使用激活函數轉換來控制信號傳播,使用 K-FAC 等強二階優化器在 ImageNet 上實現了普通網絡和殘差網絡的訓練速度相等。Zhang et al. (2022) 的工作將 DKS 擴展到了更大類的激活函數,在泛化方面也實現了接近相等。
信號傳播中需要分析的關鍵量是 DNN 的初始化時間內核,或者更準確地說,是無限寬度限制下的近似內核。對于多層感知機(MLP)以及使用 Delta 初始化的 CNN,該內核可以編寫為僅包含 2D 函數的簡單層遞歸,以便于進行直接分析。跨層 transformer 的內核演化更加復雜,因此 DKS 等現有方法不適用 transformer 或實際上任何包含自注意力層的架構。
在 MLP 中,信號傳播是通過查看(一維)內核的行為來判斷的,而 transformer 中的信號傳播可以通過查看(高維)內核矩陣在網絡層中的演化來判斷。
該研究必須避免一種情況:對角線元素隨深度增加快速增長或收縮,這與不受控制的激活范數有關,可能導致飽和損失或數值問題。避免秩崩潰(rank collapse)對于深度 transformer 的可訓練性是必要的,而是否可以訓練深度無殘差 transformer 仍是一個懸而未決的問題。
ICLR 2023 盲審階段的這篇論文解決了這個問題,首次證明了無需殘差連接或歸一化層時也可能成功訓練深度 transformer。為此,他們研究了深度無殘差 transformer 中的信號傳播和秩崩潰問題,并推導出三種方法來阻止它們。
具體而言,方法中使用了以下組合:參數初始化、偏置矩陣和位置相關的重縮放,并強調了 transformer 中信號傳播特有的幾種復雜性,包括與位置編碼和因果掩蔽的交互。研究者實證證明了他們的方法可以生成可訓練的深度無殘差 transformer。
在實驗部分,在 WikiText-103 和 C4 數據集上,研究者展示了使用他們主要的方法——指數信號保持注意力(Exponential Signal Preserving Attention, E-SPA),可以通過延長大約五倍的訓練時間使得標準 transformer 與文中無殘差 transformer 的訓練損失相當。此外通過將這一方法與殘差連接結合,研究者還表明無歸一化層的 transformer 能夠實現與標準 transformer 相當的訓練速度。

論文鏈接:
https://openreview.net/pdf?id=NPrsUQgMjKK
對于這篇論文,Google AI 首席工程師 Rohan Anil 認為是 Transformer 架構向前邁出的一大步,還是一個基礎性的改進。

構造無捷徑可訓練的深層Transformer
迄今為止,糾正 Transformer 秩崩潰(rank collapse)的唯一策略依賴于殘差連接,該方式跳過了自注意力層固有的可訓練性問題。與此相反,該研究直接解決這個問題。首先通過注意力層更好地理解信號傳播,然后根據見解(insights)進行修改,以在深度 transformer 中實現對忠實信號的傳輸,無論是否使用殘差連接,都可以對信號進行訓練。
具體而言,首先,該研究對僅存在注意力的深度 vanilla transformer 進行了一下簡單設置,之后他們假設該 transformer 具有單一頭(h = 1)設置或具有多頭設置,其中注意力矩陣 A 在不同頭之間不會變化。如果塊 l≤L 初始化時有注意力矩陣 A_l,則最終塊的表示形式為 X_L:

對于上式而言,如果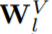 和
和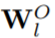 采用正交初始化,那么
采用正交初始化,那么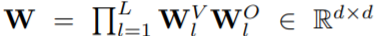 就可以在初始化時正交。
就可以在初始化時正交。
在上述假設下,如果采用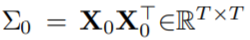 表示跨位置輸入核矩陣,經過一些簡化處理后,可以得到如下公式:
表示跨位置輸入核矩陣,經過一些簡化處理后,可以得到如下公式:

從這個簡化公式(深度僅注意力 transformer 中的核矩陣)中,可以確定對 (A_l)_l 的三個要求:
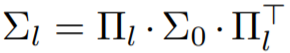
必須在每個塊中表現良好,避免退化情況,如秩崩潰和爆炸 / 消失的對角線值;
A_l 必須是元素非負 ?l;
A_l 應該是下三角?l,以便與因果掩碼注意力兼容。
在接下來的 3.1 和 3.2 節中,該研究專注于尋找滿足上述需求的注意力矩陣,他們提出了 3 種方法 E-SPA、U-SPA 和 Value-Skipinit,每種方法都用來控制 transformer 的注意力矩陣,即使在很深的深度也能實現忠實的信號傳播。此外,3.3 節演示了如何修改 softmax 注意力以實現這些注意力矩陣。
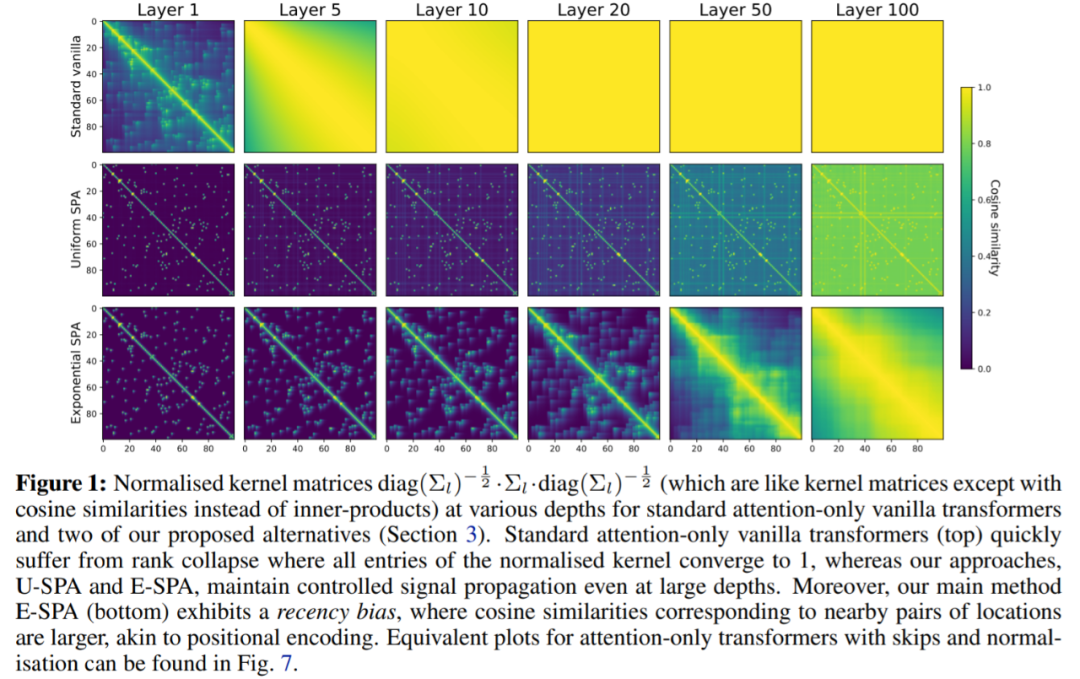
下圖中,該研究對提出的兩個 SPA 方案進行了驗證,U-SPA 和 E-SPA,結果顯示即使在網絡較深時也能成功地避免僅注意力 vanilla transformers 中的秩崩潰現象。
實驗
WikiText-103 基線:首先,該研究驗證了沒有殘差連接的標準深度 transformer 是不可訓練的,即使它們有歸一化層 (LN) 和 transformed 激活,但本文的方法可以解決這個問題。如圖 2 所示,可以清楚地看到,從標準 transformer 中移除殘差連接使其不可訓練,訓練損失穩定在 7.5 左右。正如圖 1 所示,標準 transformer 遭受了秩崩潰。
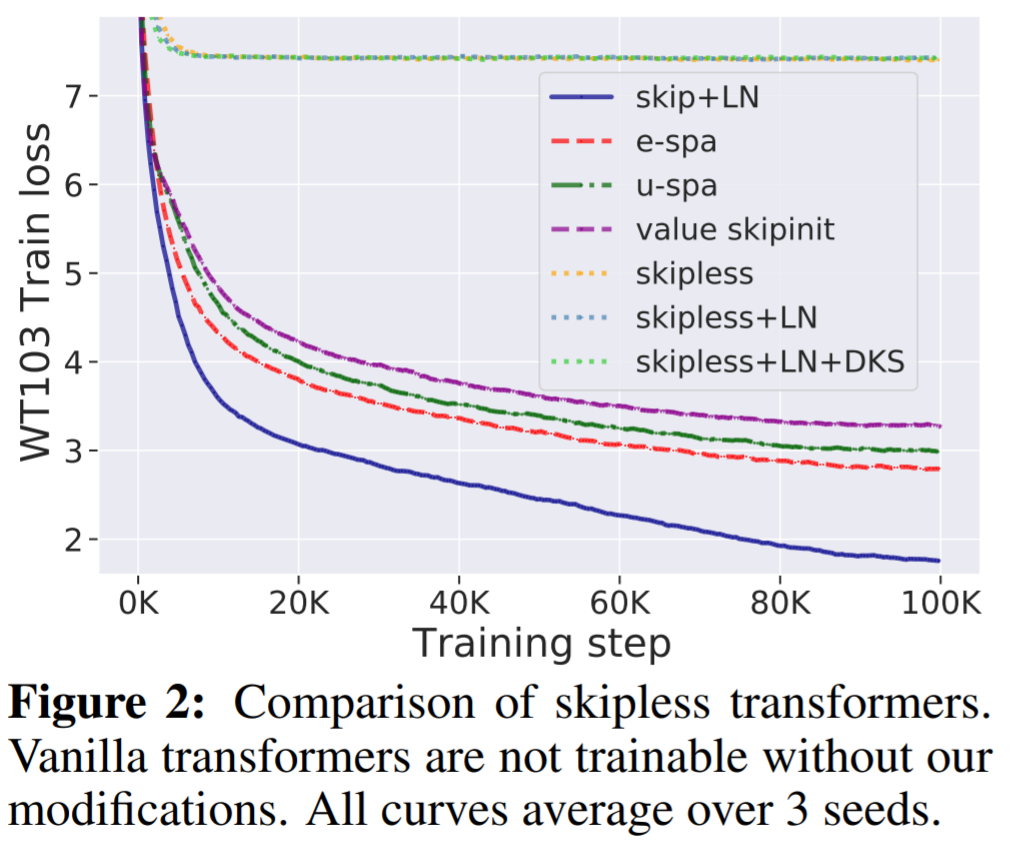
另一方面,該研究提出的 E-SPA 方法優于 U-SPA 和 Value-Skipinit。然而,與本文無殘差方法相比,帶有殘差和 LN 的默認 transformer 仍然保持訓練速度優勢。
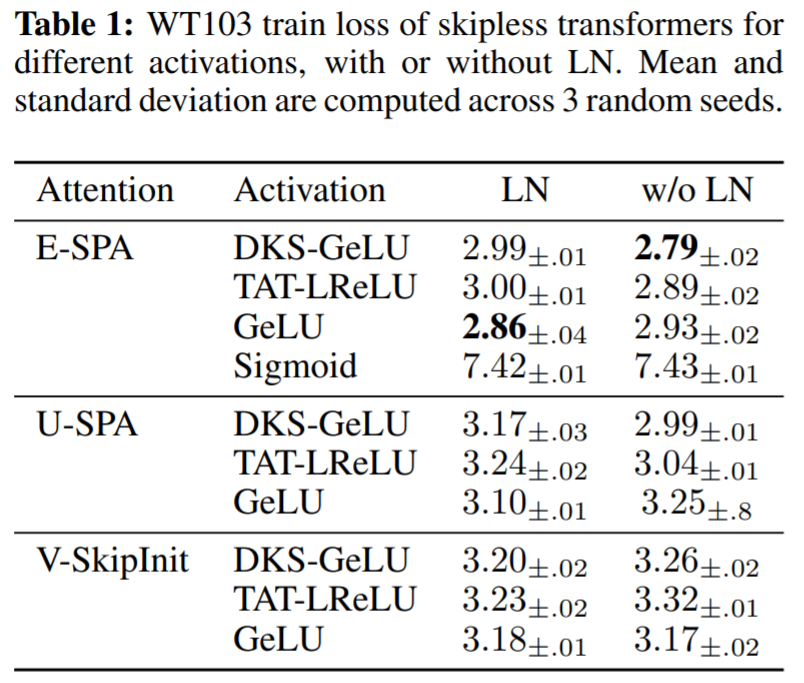
在表 1 中,該研究使用提出的方法評估了 MLP 塊中不同激活函數的影響,以及 LN 在無殘差 transformer 的使用。可以看到在深度為 36 處,本文方法針對一系列激活實現了良好的訓練性能:DKS-transformed GeLU、TAT-transformed Leaky ReLU 以及 untransformed GeLU ,但不是 untransformed Sigmoid。
通過實驗還看到,層歸一化對于訓練速度而言相對不重要,甚至在使用 SPA 時對 transformed activation 的激活有害,因為 SPA 已經具有控制激活規范的內置機制。
在圖 3 中,我們看到一種不需要更多迭代就能匹配默認 transformer 訓練損失的方法是使用歸一化殘差連接。
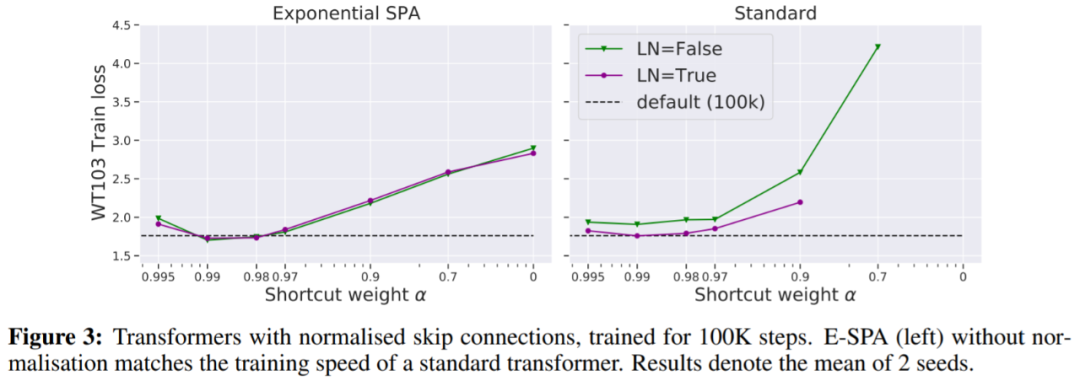
表 2 顯示帶有歸一化殘差和 LN 的 E-SPA 優于默認的 PreLN transformer。
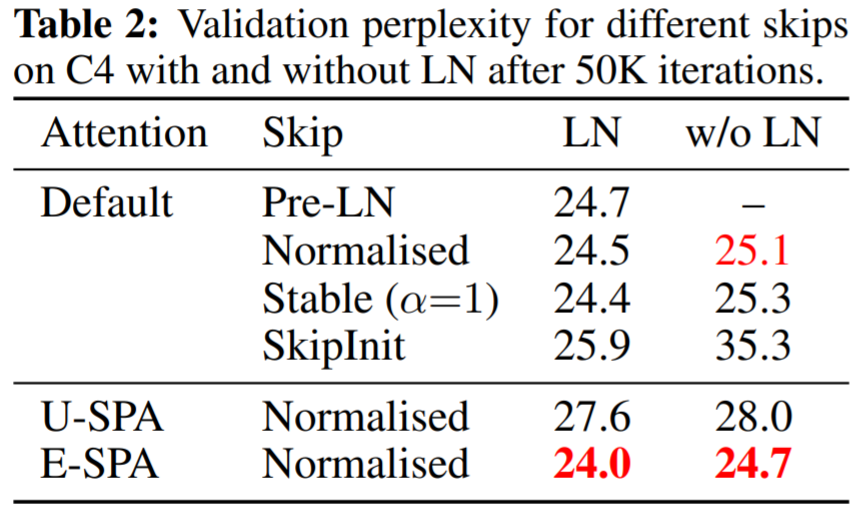
下圖 4(a)表明 E-SPA 再次優于其他方法;4(b)表明訓練損失差距可以通過簡單地增加訓練時間來消除。
審核編輯 :李倩
-
神經網絡
+關注
關注
42文章
4838瀏覽量
107756 -
Transformer
+關注
關注
0文章
156瀏覽量
6937 -
dnn
+關注
關注
0文章
61瀏覽量
9499
原文標題:首次!無殘差連接或歸一化層,也能成功訓練深度Transformer
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
Transformer 入門:從零理解 AI 大模型的核心原理
【團購】獨家全套珍藏!龍哥LabVIEW視覺深度學習實戰課(11大系列課程,共5000+分鐘)
【團購】獨家全套珍藏!龍哥LabVIEW視覺深度學習實戰課程(11大系列課程,共5000+分鐘)
構建CNN網絡模型并優化的一般化建議
在Ubuntu20.04系統中訓練神經網絡模型的一些經驗
【「AI芯片:科技探索與AGI愿景」閱讀體驗】+第二章 實現深度學習AI芯片的創新方法與架構
基于瑞芯微RK3576的resnet50訓練部署教程

TFT液晶顯示屏為什么會顯示殘影、如何解決
自動駕駛中Transformer大模型會取代深度學習嗎?

【「DeepSeek 核心技術揭秘」閱讀體驗】第三章:探索 DeepSeek - V3 技術架構的奧秘
NVMe高速傳輸之擺脫XDMA設計之七:系統初始化
Transformer架構中解碼器的工作流程



 工商網監
工商網監
評論