") 一種新的混合SoC處理器—GPNPU!
一種新的混合SoC處理器—GPNPU!

Performance, Power, Area(PPA)是半導體行業(yè)中常用的衡量標準。這三個指標對開發(fā)的所有電子產品都產生了巨大的影響。影響的程度當然取決于具體的電子產品以及目標終端市場和應用。因此,PPA權衡決策由產品公司在為各自的終端產品選擇各種芯片(以及ASIC的IP)時做出。
另一個重要的考慮因素是在不需要重新設計的情況下確保產品的壽命。換句話說,就是讓自己的產品適應不斷變化的市場和產品需求。雖然產品公司在重新設計之前會采用輔助方法來延長產品的使用壽命,但直接提供future proofing的解決方案是首選的方法。例如,在需求快速變化的市場積極增長時期,FPGA在面向未來的通信基礎設施產品中發(fā)揮了關鍵作用。當然,替代路徑可能比FPGA路徑提供更好的PPA收益。但是FPGA路徑通過避免重新設計幫助產品公司節(jié)省了大量的時間和金錢,并確保他們能夠保持或增長他們的市場份額。
還有一個考慮因素是,開發(fā)產品的路徑可以提供方便和速度。這直接轉化為上市時間,進而轉化為市場份額和盈利能力。最后,客戶可以輕松地在產品上開發(fā)應用軟件。
市場情況
人工智能(AI)驅動的、支持機器學習(ML)的產品和應用正在快速增長,并帶來巨大的市場增長機會。新的ML模型正在快速引入,現有的模型也在增強。市場機會范圍從數據中心到邊緣人工智能產品和應用。許多針對這些市場的產品無法在PPA和產品/應用程序開發(fā)的易用性之間進行權衡。
如果有一種方法可以提供PPA優(yōu)化、future proofing、便于產品和應用程序開發(fā),所有這些都集中到一個產品中會怎么樣呢?它是一個統(tǒng)一的體系結構,簡化SoC硬件設計和編程的混合處理器IP。可以解決ML推理、預處理和后處理的一體化問題。
新型混合SoC處理器
最近,Quadric宣布了第一個通用神經處理器(GPNPU)系列,這是一種半導體知識產權(IP)產品,融合了神經處理加速器和數字信號處理器(DSP)。IP使用一個統(tǒng)一的體系結構,解決ML性能特征和DSP功能,具有完全的C++可編程性。本文將從一個典型的支持ML的SoC架構的組件、其局限性、Quadric產品、優(yōu)點和可用性等方面展開介紹。
典型的支持ML的SoC架構的組件
支持ML架構的關鍵組件包括神經處理單元(NPU)、數字信號處理(DSP)單元和實時中央處理單元(CPU)。NPU用于運行當今最流行的ML網絡的圖形層,并且在已知的推理工作負載上表現非常好。DSP用于有效地執(zhí)行語音和圖像處理,并涉及復雜的數學運算。實時CPU用于協(xié)調NPU、DSP和存儲ML模型權重的內存之間的ML工作負載。通常,只有CPU可直接供軟件開發(fā)人員用于代碼開發(fā)。NPU和DSP只能通過預定義的應用程序編程接口(API)訪問。
典型架構的局限性
如上所述,典型的加速器NPU不是完全可編程的處理器。雖然它們非常高效地運行已知的圖形層,但它們不能隨著ML模型的發(fā)展而運行新的層。如果需要通過API不可用的ML操作符,則需要將其添加到CPU上,因為知道它的性能會很差。該架構不適合新ML模型和ML操作符的future proofing。充其量,可以通過在實時CPU上實現新的ML操作符來呈現性能較低的解決方案。
另一個限制是,程序員必須在NPU、DSP和實時CPU上劃分代碼,然后調整交互以滿足期望的性能目標。典型的架構還可能導致在NPU核和CPU核之間拆分矩陣操作。由于需要在內核之間交換大數據塊,因此此操作會導致推斷延遲和功耗問題。
來自不同IP供應商的多個IP核迫使開發(fā)者依賴于多個設計和生產力工具鏈。必須使用多個工具鏈通常會延長開發(fā)時間,并使調試具有挑戰(zhàn)性。
Quadric方法的好處
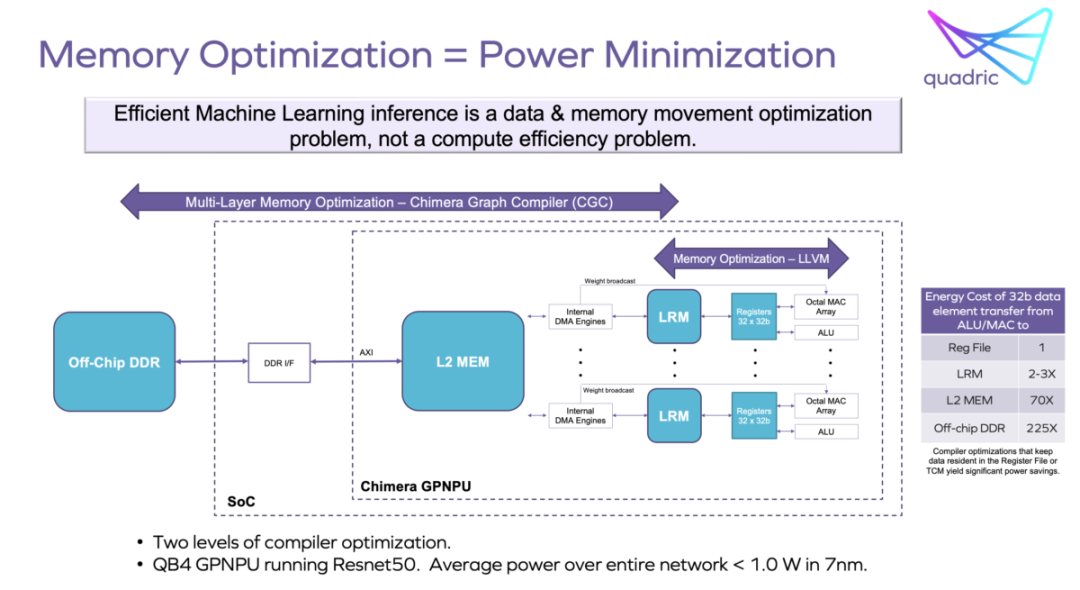
Quadric的Chimera GPNPU家族為ML推理和相關的傳統(tǒng)C++圖像、視頻、雷達和其他信號處理創(chuàng)建了統(tǒng)一的單核體系結構。這允許將神經網絡和C++代碼合并到單個軟件代碼流中。內存帶寬通過單一的統(tǒng)一編譯堆棧進行優(yōu)化,并使功耗顯著減小。編程單核系統(tǒng)也比處理異構多核系統(tǒng)容易得多。標量、向量和矩陣計算只需要一個工具鏈。
統(tǒng)一的Chimera GPNPU架構的其他好處包括,由于不必在NPU、DSP和CPU之間移動激活數據,從而節(jié)省了面積和功耗。統(tǒng)一的核心架構大大簡化了硬件集成,使性能優(yōu)化任務更加容易。
分析內存使用情況以確定最佳片外帶寬的系統(tǒng)設計任務也得到了簡化。這也直接導致了功率最小化。
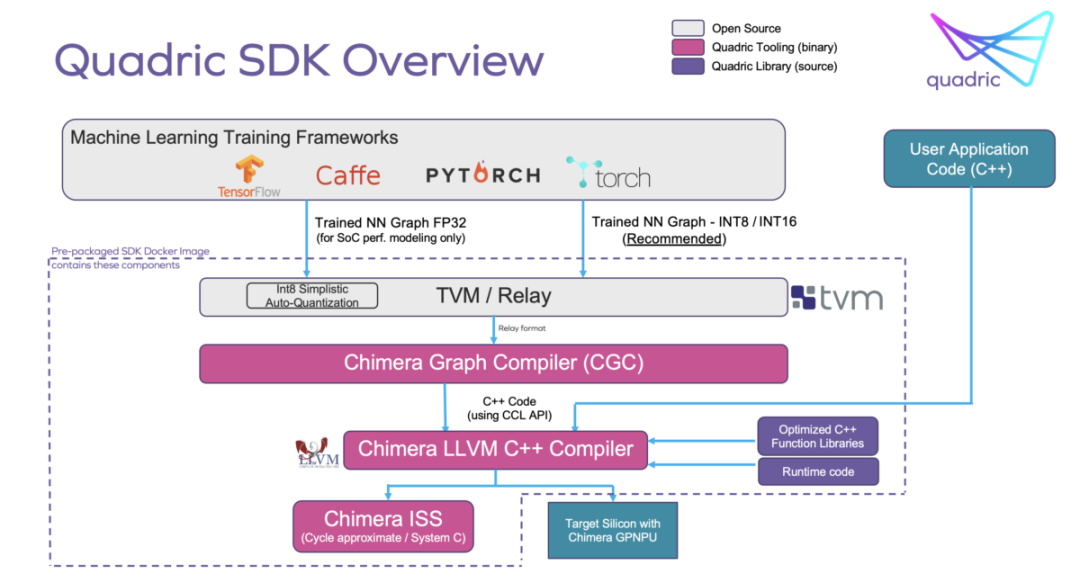
應用程序開發(fā)
Chimera軟件開發(fā)工具包(SDK)允許通過兩步編譯過程將來自通用ML訓練工具集的圖代碼與客戶的C++代碼合并。這導致可以在統(tǒng)一的Chimera單處理器核心上運行的單一代碼流。目前廣泛使用的ML訓練工具集有TensorFlow、PyTorch、ONNX和Caffe。實現的SoC的用戶將擁有對Chimera所有核心資源的完全訪問權,以實現應用程序編程的最大靈活性。整個系統(tǒng)也可以從單個調試控制臺進行調試。
在不損失性能的情況下實現future proofing
Chimera GPNPU架構擅長處理卷積層,這是卷積神經網絡(CNNs)的核心。Chimera GPNPU可以運行任何ML操作符。通過使用Chimera計算庫(CCL) API編寫C++內核并使用Chimera SDK編譯該內核,可以添加自定義ML操作符。自定義運算符的性能與本地運算符相同,因為它們利用了Chimera GPNPU的相關核心資源。
SoC開發(fā)人員可以在SoC被剝離后很長時間內實現新的神經網絡運算符和庫。這本身就大大增加了芯片的使用壽命。
軟件開發(fā)人員可以在產品的整個生命周期中繼續(xù)優(yōu)化他們的模型和算法的性能。他們可以添加新的特性和功能,為他們的產品在市場上獲得競爭優(yōu)勢。
Quadric的當前產品
Chimera架構已經在芯片領域得到了快速驗證。QB系列GPNPU的整個家族可以在主流的16nm和7nm工藝中使用傳統(tǒng)的標準電池流和常用的單端口SRAM實現1GHz的工作。Chimera核心可以針對任何芯片鑄造廠和任何工藝技術。
Chimera GPNPU系列的QB系列包括三個核心:
Chimera QB1 -每秒1萬億次機器學習運算(TOPS),每秒64千兆次DSP運算(GOPs);
Chimera QB4 - 4 TOPS機器學習,256 GOP DSP;
Chimera QB16–16 TOPS機器學習,1 TOPS DSP;
如果需要,可以將兩個或多個Chimera核心配對在一起,以滿足更高級別的性能要求。
審核編輯 :李倩
-
處理器
+關注
關注
68文章
20255瀏覽量
252340 -
soc
+關注
關注
40文章
4576瀏覽量
229156 -
人工智能
+關注
關注
1817文章
50098瀏覽量
265427
原文標題:一種新的混合SoC處理器—GPNPU!
文章出處:【微信號:SSDFans,微信公眾號:SSDFans】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
DPU數據處理器的核心功能和應用領域

MAXIM 納米功耗微處理器監(jiān)控電路:設計與應用指南
【「龍芯之光 自主可控處理器設計解析」閱讀體驗】--LoongArch的SOC邏輯設計
【「龍芯之光 自主可控處理器設計解析」閱讀體驗】--全書概覽與概述
瑞芯微SOC智能視覺AI處理器
算力積木+3D堆疊!GPNPU架構創(chuàng)新,應對AI推理需求
MD5信息摘要算法實現二(基于蜂鳥E203協(xié)處理器)
Cortex-M0+處理器的HardFault錯誤介紹
AUDIO SoC的解決方案
內置光學濾鏡用于紅外線過濾的一種光-數字轉換器-WH81120UF

德州儀器AM68x Jacinto 8處理器技術解析

nRF54系列新一代無線 SoC
光子 AI 處理器的核心原理及突破性進展
AI SoC # Apollo330 Plus 邊緣設備實時AI處理的創(chuàng)新解決方案




 工商網監(jiān)
工商網監(jiān)
評論