") 為什么不同模態(tài)的embedding在表征空間中形成不同的簇
為什么不同模態(tài)的embedding在表征空間中形成不同的簇

本文介紹的是斯坦福大學在ICLR 2022發(fā)表的一篇多模態(tài)模型分析文章。這篇文章研究的是一個多模態(tài)對比學習模型中常見的問題:為什么不同模態(tài)的embedding在表征空間中形成不同的簇,以及這種gap對最終預訓練多模態(tài)模型在下游任務中效果的影響。文中分析的一些現(xiàn)象是我們在實驗中經(jīng)常遇到的,例如為什么深度學習模型輸出的embedding對的cosine往往是大于0的數(shù),并且做了很多有趣的實驗進行了分析和驗證。
文中將一些經(jīng)典的多模態(tài)對比學習模型中兩個模態(tài)的embedding,通過降維等方法映射到二維坐標系中。從下圖可以看出,不論是哪種模型,兩個模態(tài)的表征都會出現(xiàn)gap(形成獨立的簇)。并且無論是預訓練好的模型,還是隨機初始化的模型,都存在這個問題。
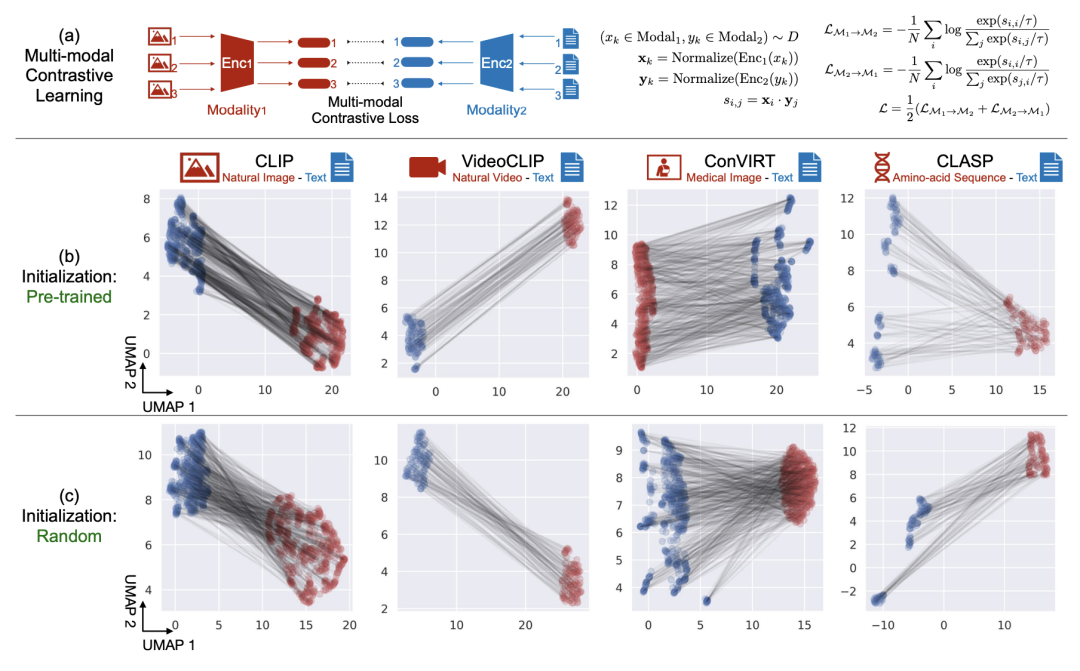
那么為什么會出現(xiàn)這種現(xiàn)象呢?文中從兩個角度進行了分析,一個是深度學習模型本身的cone effect會帶來gap,另一個是對比學習損失傾向于保持這種gap。
1 Core Effect的影響
Core effect在文中的定義可以理解為,使用深度學習模型得到的embedding,會分布在一個狹小的錐形空間里,不論模型的參數(shù)是訓練好的還是隨機的。同時,不同的隨機初始化最終產(chǎn)出的embedding會分布在不同的錐形區(qū)域。而多模態(tài)模型中,一般是兩個模態(tài)的模型分別隨機初始化,這就導致兩個模態(tài)會隨機生成兩個錐形區(qū)域,從而導致不同模態(tài)之間的表示空間存在gap。下面詳細介紹一下文中的分析過程。
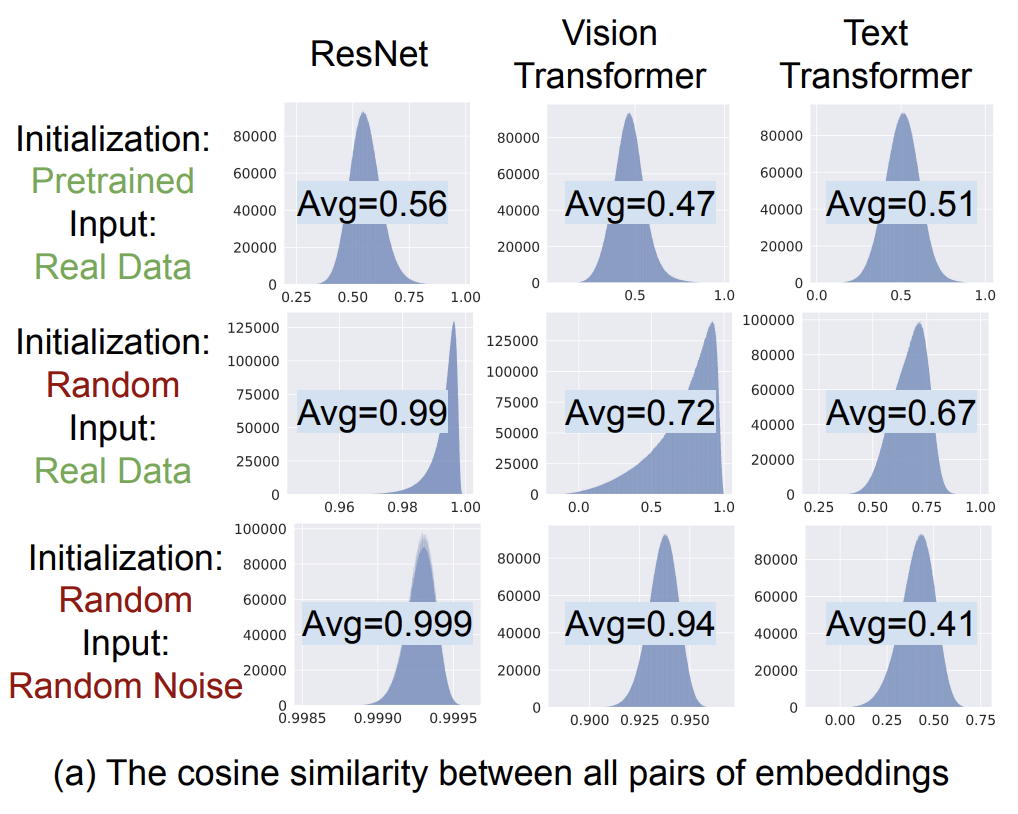
文中通過模型產(chǎn)出的任意兩個embedding的cosine相似度分布來驗證這個問題。從模型中獲取5000個embedding,然后計算兩兩embedding的cosine相似度,求出平均cosine和最小cosine。通過下圖可以發(fā)現(xiàn),各類模型的cosine值基本都是偏高的,并且很少有負數(shù)的cosine值。這表明,模型輸出的embedding并不是散落在整個空間中的,而是形成一個從坐標遠點向外擴展的狹小錐形中,才會出現(xiàn)cosine取值分布偏大的現(xiàn)象。
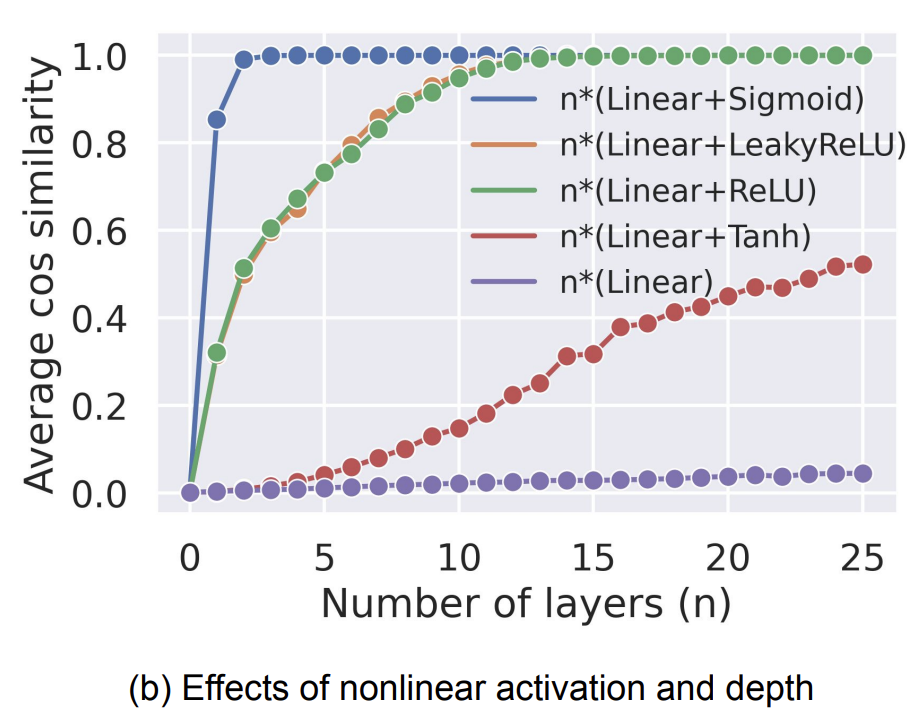
那么為什么深度學習模型會出現(xiàn)cone effect現(xiàn)象呢?文中對比了不同激活函數(shù)、不同網(wǎng)絡層數(shù)的模型形成的cosine均值,發(fā)現(xiàn)層數(shù)越深cosine均值越高,并且當沒有激活函數(shù)的時候就不會出現(xiàn)cosine均值大于0的情況(如下圖所示)。這說明激活函數(shù)和網(wǎng)絡層數(shù)的加深是cone effect現(xiàn)象形成的主要原因。
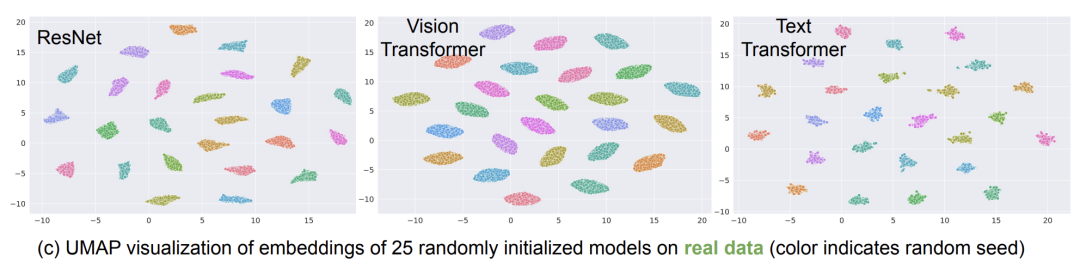
接下來,文中又對比了不同隨機初始化對形成的錐形區(qū)域的影響。文中對多個模型進行了25次隨機初始化,并繪制了每次隨機初始化的embedding區(qū)域。可以看到每次隨機初始化的錐形區(qū)域都是不同的,這說明不同的隨機初始化會導致生成的embedding分布在不同的錐形區(qū)域。
結(jié)合以上的信息就可以推倒出多模態(tài)模型兩個模態(tài)表征存在gap的原因:多模態(tài)對比學習一般是雙塔結(jié)構(gòu),一個模態(tài)一個塔,每個塔進行隨機參數(shù)初始化后,導致每個塔有一個自己的錐形區(qū)域,并且初始化的隨機性導致兩個塔的錐形區(qū)域不同。
2 對比學習loss的影響
第二個造成多模態(tài)表征存在gap的原因是對比學習loss。文中通過一些實驗驗證了對比學習loss會傾向于保持這種模態(tài)之間的gap。為了分析這個問題,文中設計了embedding shift實驗和構(gòu)造mismatch數(shù)據(jù)實驗。
在embedding shift實驗中,會在一個訓練好的CLIP模型基礎上,計算兩個模態(tài)embedding質(zhì)心之間的距離。并且不斷的讓兩個模態(tài)的embedding進行靠近,再計算不同temperature參數(shù)下的對比學習loss。實驗結(jié)果如下圖,CLIP模型訓練好后,兩個模態(tài)embedding的距離為0.82,隨著距離的拉近或遠離,基本都會帶來loss的上升。而當temperature=1時,最小loss則出現(xiàn)在兩個模態(tài)embedding距離更近的位置,這表明對比學習損失對gap的影響是和temperature相關的。
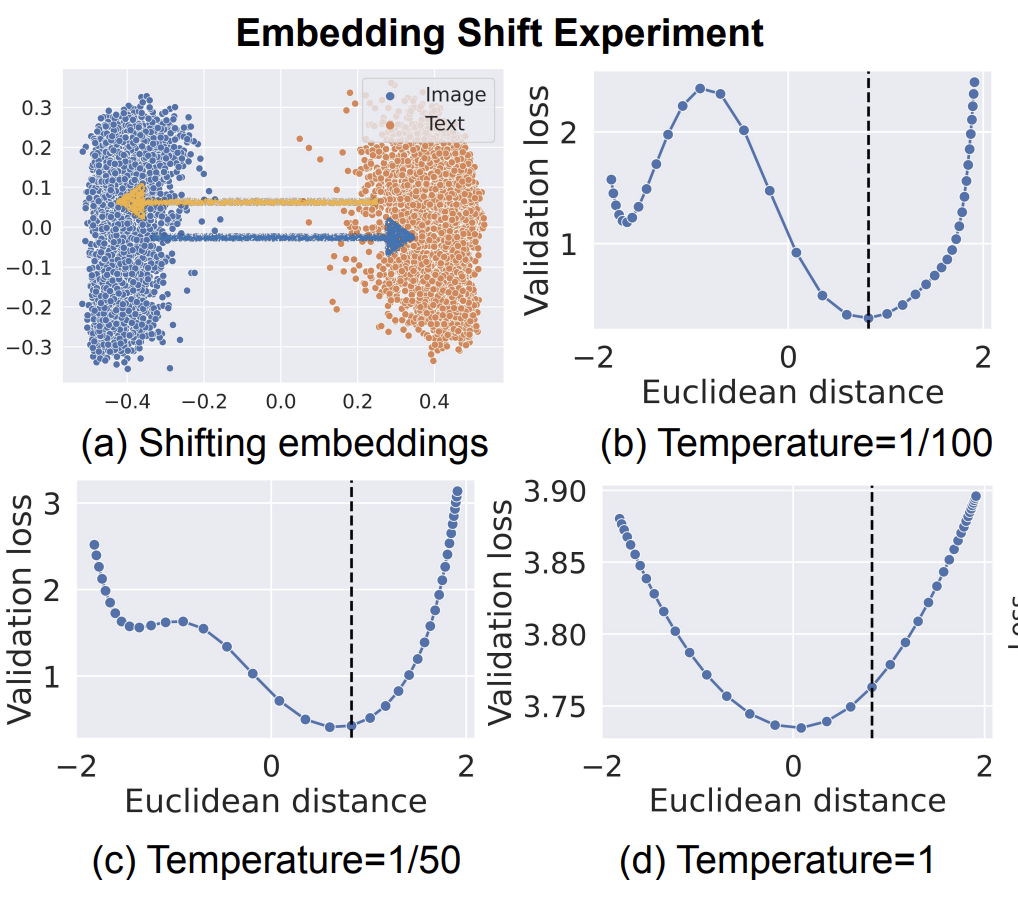
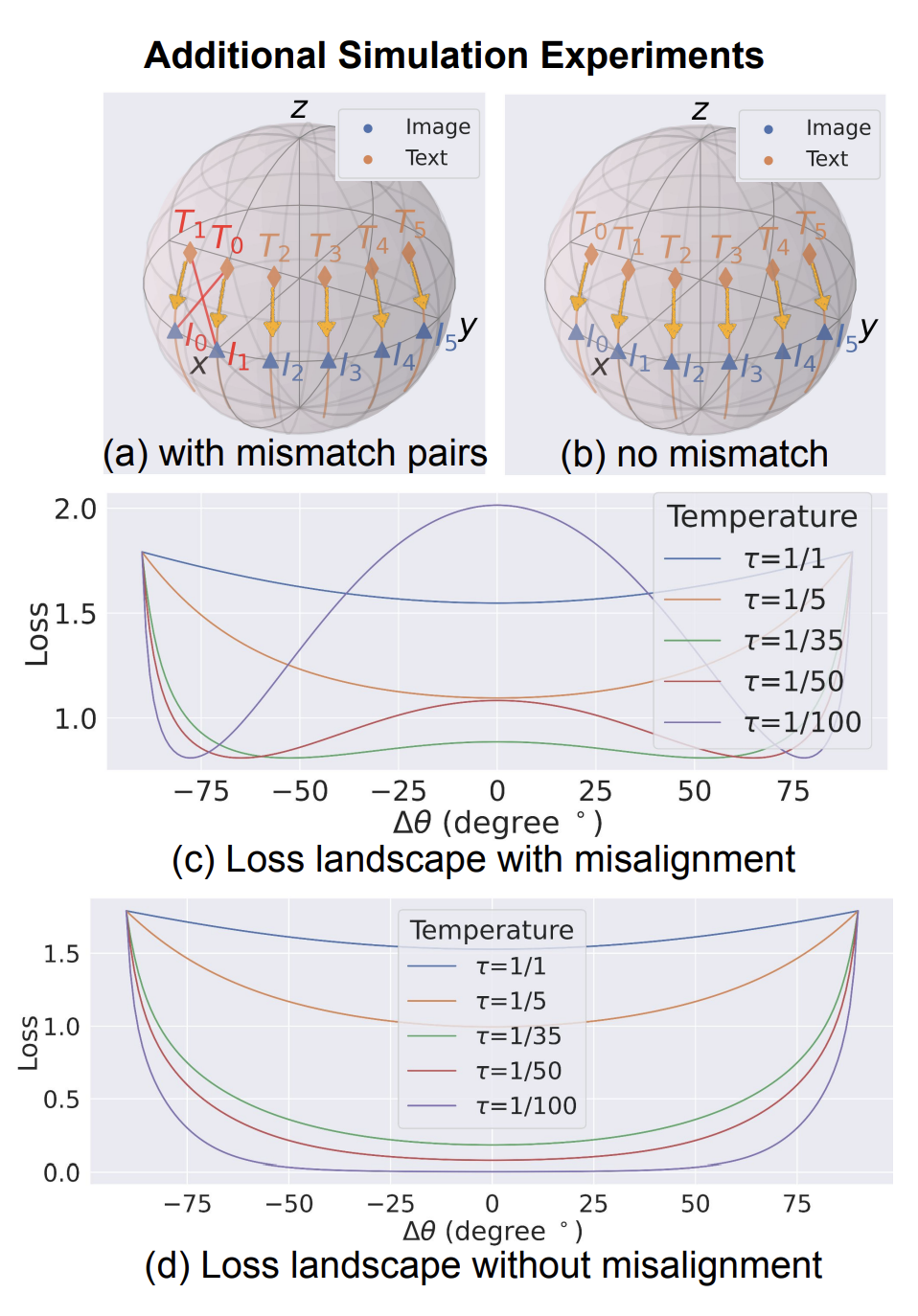
在構(gòu)造mismatch數(shù)據(jù)實驗中,作者會構(gòu)造一些mismatch數(shù)據(jù)(如下圖中I0和T0是正樣本,I1和T1是正樣本,但是I0和T1更接近,I1和T0更接近),然后讓文本表示逐漸向圖像表示靠近。并繪制不同temperature下的loss曲線,可以看到和之前類似的效果,距離為0時loss最大,并且temperature為1時這種現(xiàn)象并不明顯。同時,如果刪除mismatch的數(shù)據(jù),這個現(xiàn)象就消失了,這說明mismatch數(shù)據(jù)是導致對比學習loss傾向于保持多模態(tài)表征gap的關鍵因素。
3 Gap和模型效果
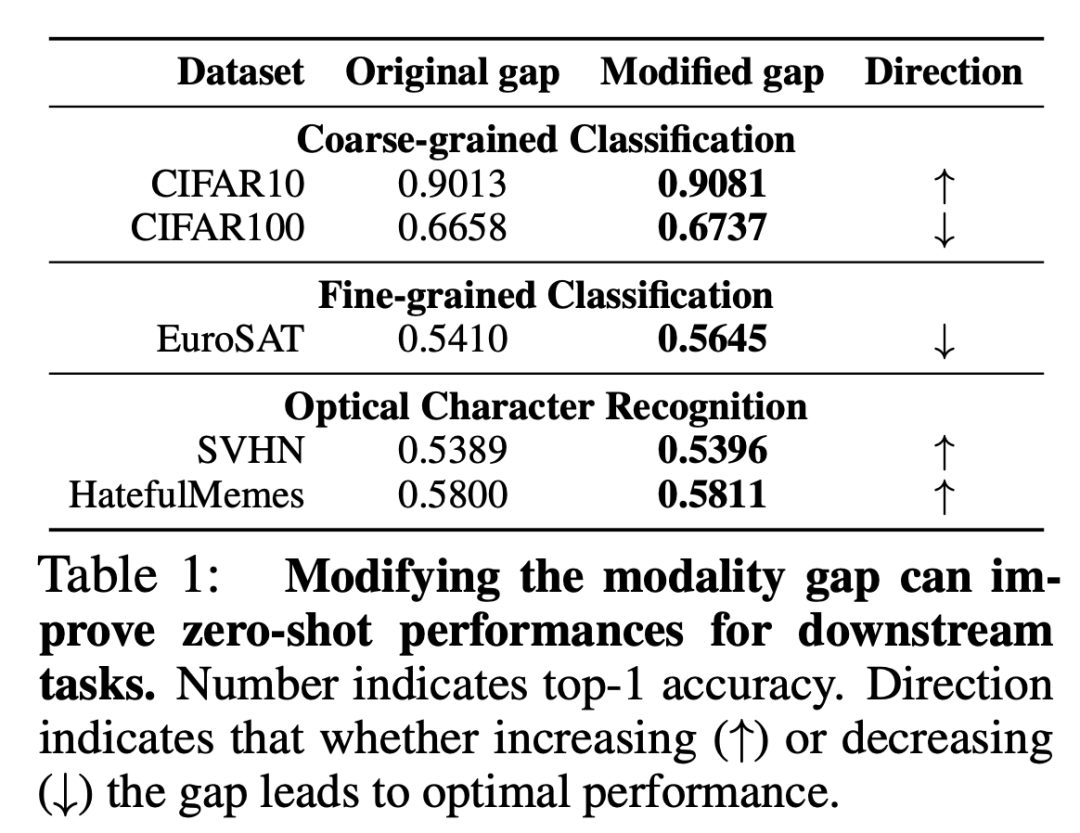
那么多模態(tài)表征的gap對模型效果有什么影響呢?首先作者對比了預訓練CLIP在zero-shot任務的效果。下表表示的是如何通過增大或縮小多模態(tài)表征gap來提升模型的效果。從下表可以看出,在各類數(shù)據(jù)集下,通過增大或減小多模態(tài)表征的gap,是可以對下游任務產(chǎn)生比較顯著的效果影響的。
4 總結(jié)
這篇文章從一個多模態(tài)表征存在gap的現(xiàn)象出發(fā),詳細分析了這個現(xiàn)象產(chǎn)生的原因,設計了豐富的實驗進行分析和驗證,并最終得到如何通過修改表征gap影響模型效果的方法。此外,文中的附錄還有大量的補充實驗,感興趣的同學可以進一步深入閱讀。
審核編輯:劉清
-
Clip
+關注
關注
0文章
34瀏覽量
7260 -
深度學習
+關注
關注
73文章
5598瀏覽量
124396
原文標題:多模態(tài)預訓練常見問題:為什么不同模態(tài)表征存在gap?
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
如何在KEIL軟件中將變量定義在特定的RAM空間中
【「基于大模型的RAG應用開發(fā)與優(yōu)化」閱讀體驗】+Embedding技術(shù)解讀
怎么在代碼與數(shù)據(jù)空間中放置常量
可不可以在同一個內(nèi)存空間中存儲不同的數(shù)據(jù)類型呢
Hilbert空間中κ-嚴格偽壓縮的強收斂定理
Banach空間中非擴張非自映象不動點的粘滯迭代逼近
本體在個人數(shù)據(jù)空間中的應用研究
從one-hot、word embedding、rnn、seq2seq、transformer一步步逼近bert

覆蓋近似空間中的核及性質(zhì)綜述
關于Flash程序空間中的數(shù)據(jù)訪問的實驗

KUKA系統(tǒng)函數(shù)FORWARD()是如何計算空間中笛卡爾位置的
VR虛擬空間中的3D 技術(shù)



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論