") 深入理解分布式共識算法 Raft
深入理解分布式共識算法 Raft

“不可靠的網(wǎng)絡(luò)”、“不穩(wěn)定的時鐘”和“節(jié)點(diǎn)的故障”都是在分布式系統(tǒng)中常見的問題,在文章開始前,我們先來看一下:如果在分布式系統(tǒng)中網(wǎng)絡(luò)不可靠會發(fā)生什么樣的問題。
有以下 3 個服務(wù)構(gòu)成的分布式集群,并在 server_1 中發(fā)生寫請求變更 A = 1,“正常情況下” server_1 將 A 值同步給 server_2 和 server_3,保證集群的數(shù)據(jù)一致性:

但是如果在數(shù)據(jù)變更時發(fā)生網(wǎng)絡(luò)問題(延遲、斷連和丟包等)便會出現(xiàn)以下情況:比如有兩個寫操作同時發(fā)生在 server_1 或 server_3 上,即便兩個寫操作有先后順序,但可能由于網(wǎng)絡(luò)延時導(dǎo)致各個服務(wù)中數(shù)據(jù)的不一致:
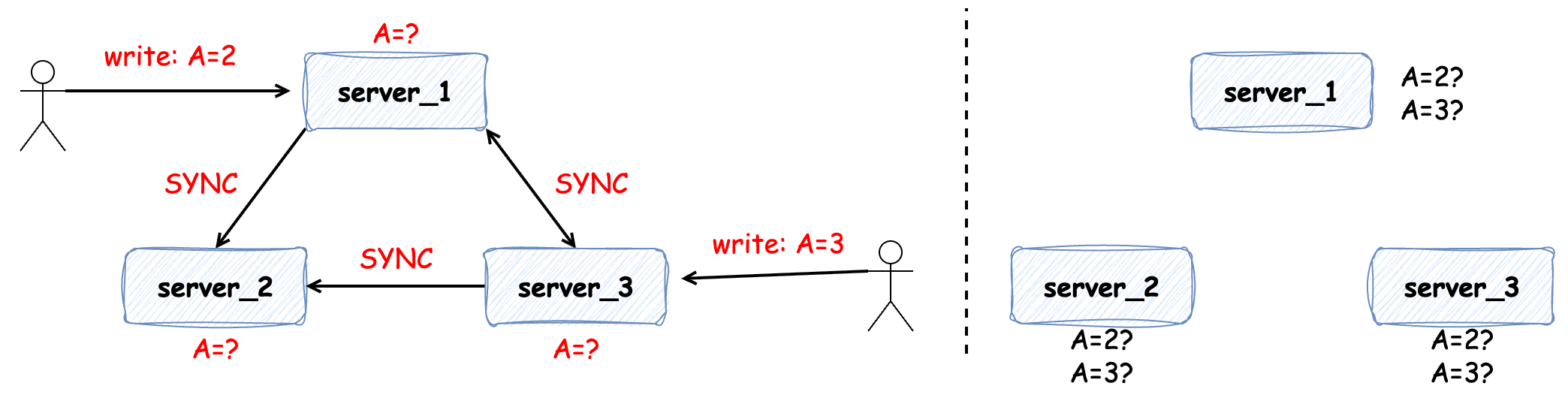
同樣地情況,如果在 server_1 上發(fā)生三次寫操作,在數(shù)據(jù)同步的過程中因?yàn)榫W(wǎng)絡(luò)延時或網(wǎng)絡(luò)丟包也可能會導(dǎo)致數(shù)據(jù)的不一致:
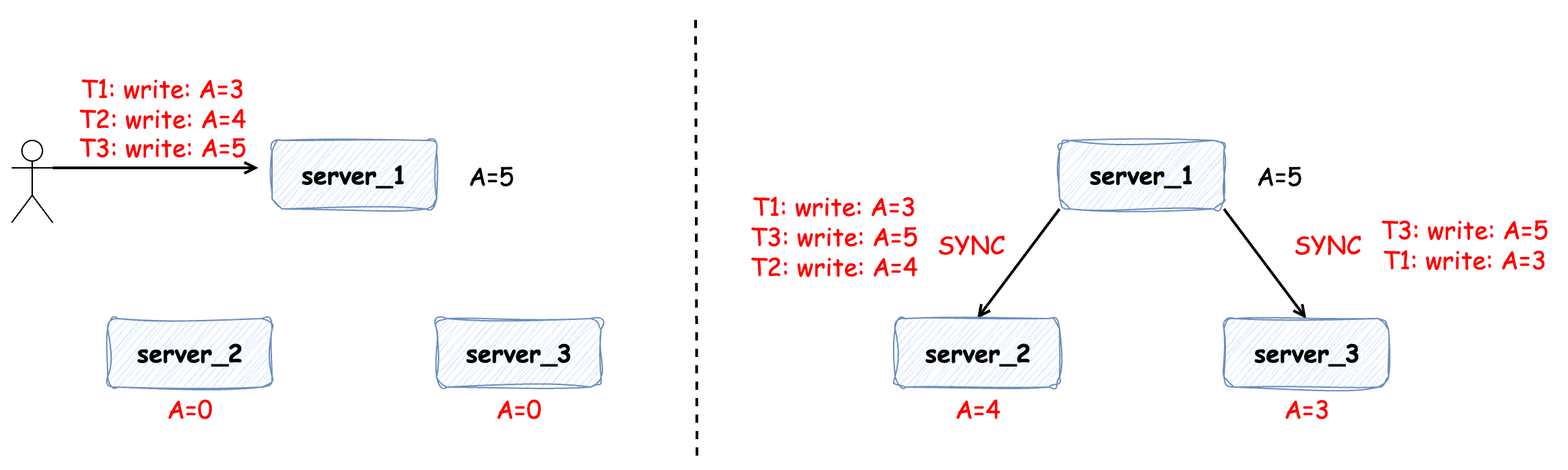
那么為了避免以上這些集群間數(shù)據(jù)不一致的問題,便需要分布式共識算法來協(xié)調(diào)。分布式共識算法簡單來說就是如何在多個服務(wù)器間對某一個值達(dá)成一致,并且當(dāng)達(dá)成一致之后,無論之后這些機(jī)器間發(fā)生怎樣的故障,這個值能保持不變。本篇文章我們便對 Raft 算法進(jìn)行介紹。
理解 Raft 算法
了解和學(xué)習(xí)過 Zookeeper 的同學(xué)可能聽說過 Zab 算法,它用來保證 Zookeeper 中數(shù)據(jù)的 順序一致性。Raft 也是一種分布式共識算法,它易于理解和實(shí)現(xiàn),用于保證數(shù)據(jù)的 線性一致性,是最強(qiáng)一致性模型。
在遵循 Raft 算法的集群中,節(jié)點(diǎn)會有 3 種不同的角色。當(dāng)集群在初始化時,每個節(jié)點(diǎn)的角色都是 Follower 跟隨者,它們會等待來自 Leader 節(jié)點(diǎn)的心跳。因?yàn)榇藭r并沒有 Leader 節(jié)點(diǎn),所以會等待心跳超時。等待超時的 Follower 節(jié)點(diǎn)會將角色轉(zhuǎn)變?yōu)?Candidate 候選者,觸發(fā)一次選舉,觸發(fā)選舉時會標(biāo)記 Term 任期變量,并將自己的一票投給自己,通知其他 Follower 節(jié)點(diǎn)發(fā)起投票。經(jīng)過投票后,收到超過半數(shù)節(jié)點(diǎn)票數(shù)的 Candidate 節(jié)點(diǎn)會成為 Leader 領(lǐng)導(dǎo)者節(jié)點(diǎn),其他節(jié)點(diǎn)為 Follower 跟隨者節(jié)點(diǎn),Leader 節(jié)點(diǎn)會不斷地發(fā)送心跳給 Follower 節(jié)點(diǎn)來維持領(lǐng)導(dǎo)地位:
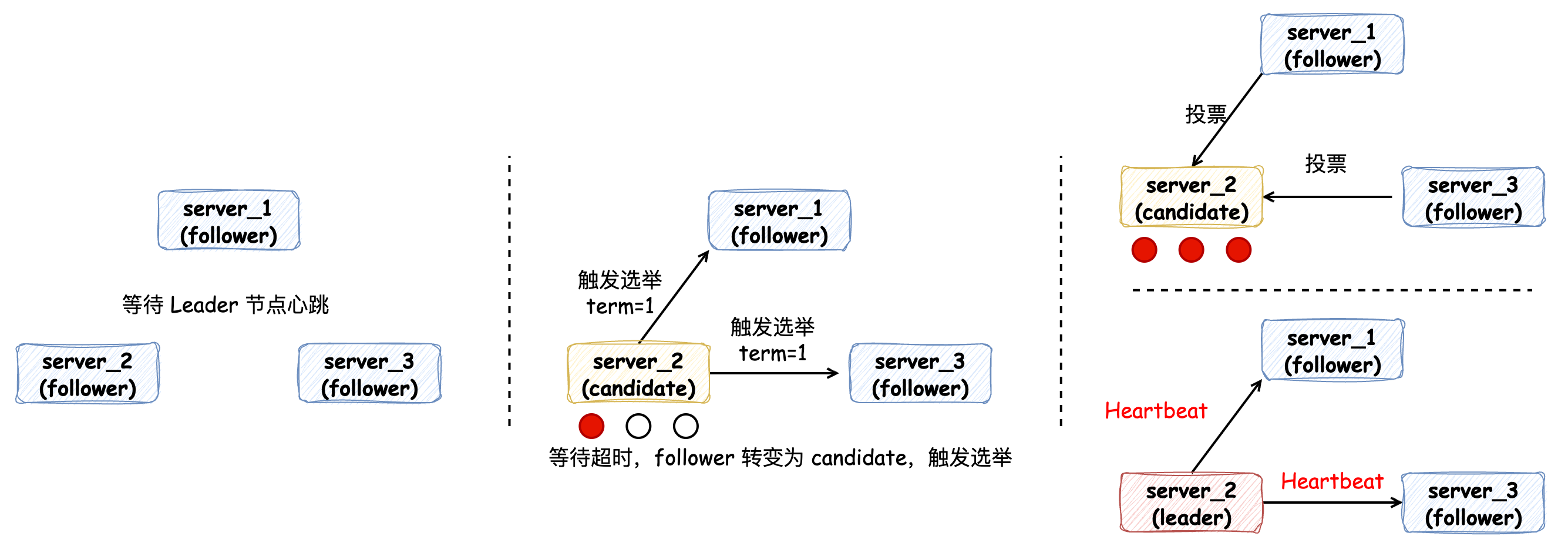
如果每個節(jié)點(diǎn)每次在觸發(fā)選舉時都是同時超時,這樣是不是導(dǎo)致不能完成一次選舉,產(chǎn)生 “活鎖” 問題?的確可能,不過活鎖問題也很好解決:即節(jié)點(diǎn)超時時間在合理的范圍內(nèi)取隨機(jī)值,這樣由于它的隨機(jī)性就不太可能再同時發(fā)起競選了,這個時候其他節(jié)點(diǎn)便有足夠的時間向其他節(jié)點(diǎn)索要選票。
寫變更請求
當(dāng)發(fā)生寫變更請求時,由 Leader 節(jié)點(diǎn)負(fù)責(zé)處理,即使是請求到 Follower 節(jié)點(diǎn),也需要轉(zhuǎn)發(fā)給 Leader 節(jié)點(diǎn)處理。當(dāng) Leader 節(jié)點(diǎn)接收到寫請求時,它并不立即對這個請求進(jìn)行處理,而是先將請求信息 按順序追加到日志文件中(WAL: write-ahead-log),如圖中標(biāo)記的 log_index 表示追加到的最新一條日志的序號:
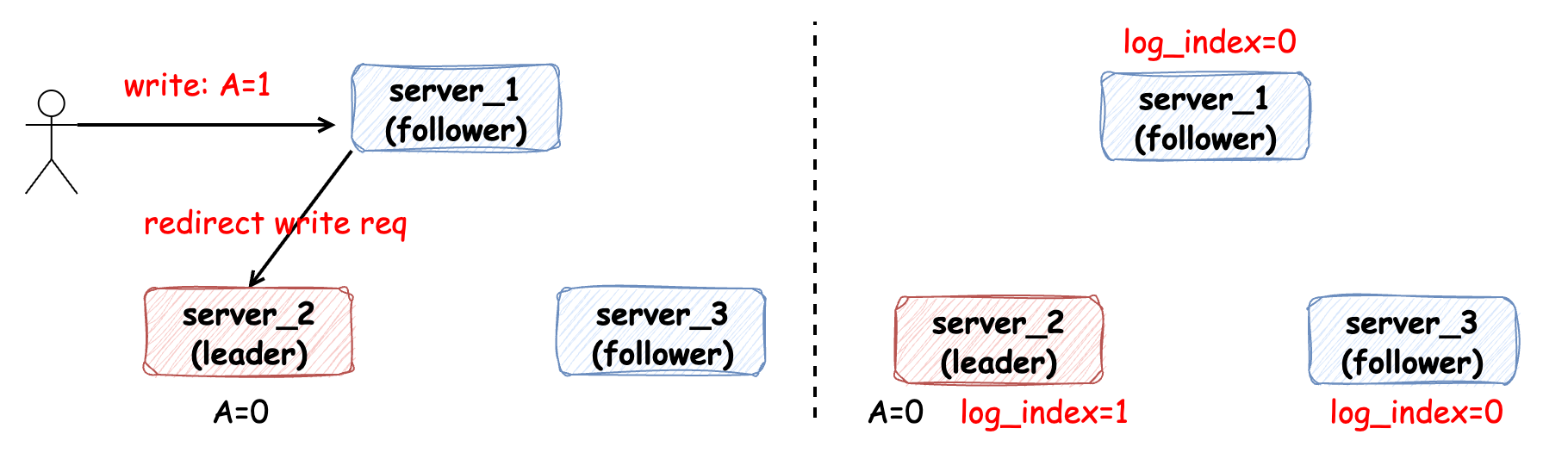
在這個過程中,日志必須持久化存儲。隨后,Leader 節(jié)點(diǎn)通過 RPC 請求將日志同步到各個 Follower 節(jié)點(diǎn),當(dāng)超過半數(shù)節(jié)點(diǎn)成功將日志記錄時,便認(rèn)為同步成功。在這里可知 Raft 算法采用的是單主復(fù)制的模型,所以它也就會存在以下缺點(diǎn):
面對大量寫請求負(fù)載時系統(tǒng)比較難擴(kuò)展,因?yàn)橄到y(tǒng)只有一個主節(jié)點(diǎn),寫請求的性能瓶頸由單個節(jié)點(diǎn)決定
當(dāng)主節(jié)點(diǎn)宕機(jī)時,從節(jié)點(diǎn)提升為主節(jié)點(diǎn)不是即時的,可能會造成一些停機(jī)時間
隨后,Leader 節(jié)點(diǎn)會更新最新同步日志的索引 commit_index 為 1,并通過心跳下發(fā)給各個 Follower 節(jié)點(diǎn):

在這個過程中可以發(fā)現(xiàn) Follower 節(jié)點(diǎn)只是聽從并響應(yīng) Leader 節(jié)點(diǎn),沒有任何主動性。現(xiàn)在,已經(jīng)完成了日志在集群間的同步,但是請求對變量 A 的修改還沒有被應(yīng)用(Apply)。Apply 是在 Raft 算法中經(jīng)常出現(xiàn)的一個名詞,在多數(shù)與 Raft 算法相關(guān)的文章中經(jīng)常會看到 “將已提交的日志條目應(yīng)用到狀態(tài)機(jī)” 等類似的表述。其實(shí) “狀態(tài)機(jī)” 理解起來并不復(fù)雜,通俗的理解是 業(yè)務(wù)邏輯的載體 或 業(yè)務(wù)邏輯的執(zhí)行者,它的職責(zé)包括:
接收來自日志文件中有序的命令
執(zhí)行具體的業(yè)務(wù)邏輯,在本次寫請求中,業(yè)務(wù)邏輯指的便是變更 A 的值
變更應(yīng)用程序的狀態(tài)
返回執(zhí)行結(jié)果
更加通俗的講就是 讓請求生效。將已經(jīng)提交的日志應(yīng)用到狀態(tài)機(jī)是比較簡單且自主的過程,各個服務(wù)實(shí)例會記錄 apply_index 來標(biāo)記應(yīng)用索引,當(dāng) apply_index 小于 commit_index 時,那么證明日志文件中記錄的請求信息還有部分沒生效,所以需要按順序應(yīng)用,直到 apply_index = commit_index:
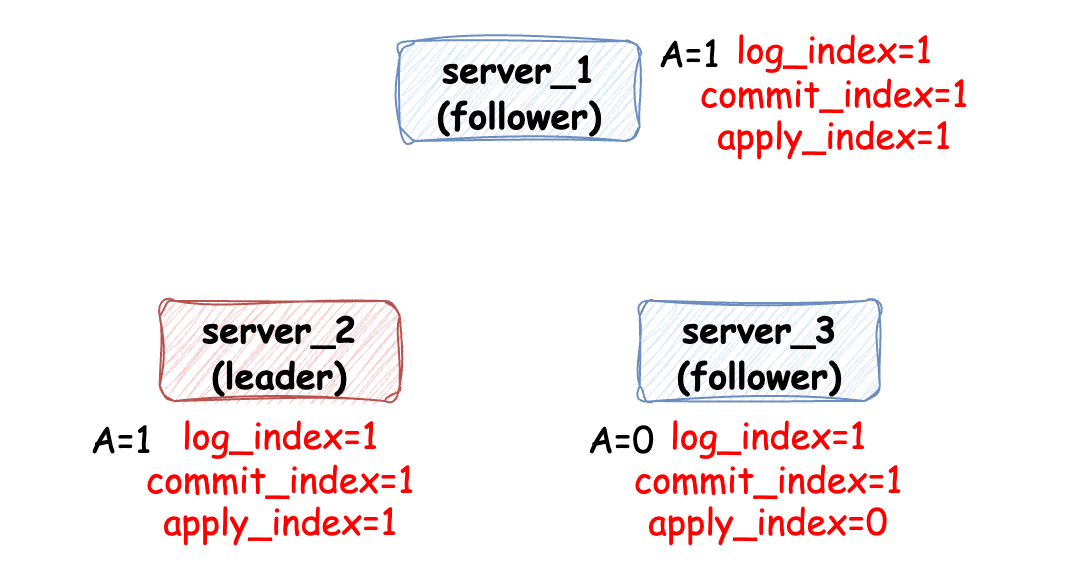
在這個過程中,我一直在強(qiáng)調(diào) “按順序”,不論是日志的追加還是日志的被應(yīng)用都是按順序來的,因此才能保證數(shù)據(jù)的線性一致性。
讀請求
Raft 集群處理讀請求會保證讀請求的線性一致性,所謂線性一致性讀就是在 t1 的時間寫入了一個值,那么在 t1 之后,讀一定能讀到這個值,不可能讀到 t1 之前的值,在 Raft 算法中實(shí)現(xiàn)線性一致性讀有以下兩種方式:
ReadIndex Read
在這種方式下,當(dāng) Leader 節(jié)點(diǎn)處理讀請求時:
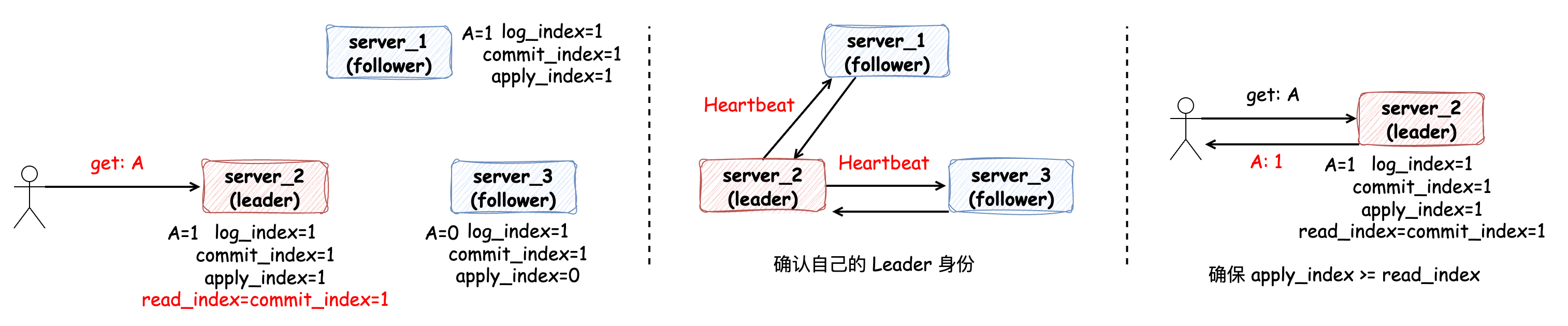
首先將 commit_index 記錄到本地的 read_index 變量里
向其他節(jié)點(diǎn)發(fā)送一次 Heartbeat,確認(rèn)自己仍然是 Leader 角色
Leader 節(jié)點(diǎn)等待自己的狀態(tài)機(jī)執(zhí)行,直到 apply_index 超過了 read_index,這樣就能夠安全的提供線性一致性讀了
Leader 執(zhí)行 read 請求,將結(jié)果返回
在第三步中,保證 apply_index >= read_index 是為了保證所有小于等于 read_index 的請求都已經(jīng)生效。
如果是 Follower 節(jié)點(diǎn)處理讀請求也和以上過程類似,當(dāng) Follower 節(jié)點(diǎn)收到讀請求后,直接給 Leader 發(fā)送一個獲取此時 read_index 的請求,Leader 節(jié)點(diǎn)仍然處理以上流程然后將 read_index 返回,此時 Follower 節(jié)點(diǎn)等到當(dāng)前的狀態(tài)機(jī) apply_index 超過 read_index 后,就可以返回結(jié)果了。
Lease Read
因?yàn)?ReadIndex Read 需要發(fā)送一次 Heartbeat 來確認(rèn) Leader 身份,存在 RPC 請求的開銷,為了進(jìn)一步優(yōu)化,便可以采用租約(Lease)讀。租約其實(shí)指的是 Leader 節(jié)點(diǎn)身份的過期約定時間,所以這種讀請求只針對 Leader 節(jié)點(diǎn),F(xiàn)ollower 節(jié)點(diǎn)沒有租約的概念,它通過以下公式計算:
lease_end = current_time() + election_timeout / clock_drift_bound
其中 election_timeout 為選舉的超時時間,clock_drift_bound 表示時鐘漂移,指的是在分布式系統(tǒng)中,兩個或多個節(jié)點(diǎn)上的時鐘以不同的速率運(yùn)行,導(dǎo)致它們之間的時間差隨時間不斷累積和變化(也就是分布式系統(tǒng)中不穩(wěn)定的時鐘問題)。
舉個簡單的例子,假如選舉過期時間是 10s,時鐘漂移為 1.1,那么租約過期時間為:lease_end = current_time() + 10s / 1.1 ≈ current_time() + 9s,如果在處理讀請求時,在租約時間內(nèi),則無需發(fā)送 Heartbeat 來明確 Leader 身份,直接等待 apply_index >= commit_index 后返回請求結(jié)果。
在以上讀寫流程中,Raft 分布式共識算法能讓每個節(jié)點(diǎn)對日志的值和順序達(dá)成共識,每個節(jié)點(diǎn)都存儲相同的日志副本,使整個系統(tǒng)中的每個節(jié)點(diǎn)都能有一致的狀態(tài)和輸出,使得這些節(jié)點(diǎn)看起來就像一個單獨(dú)的,高可用的狀態(tài)機(jī)。在上文中我們提到過 Zookeeper 使用的 Zab 共識算法保證的是順序一致性,Raft 算法保證的是線性一致性,所以借著這個引子也來談?wù)勎覍σ恢滦缘睦斫狻?/p>
一致性
一致性 通常指的就是數(shù)據(jù)一致性,在分布式系統(tǒng)中的讀寫請求,表現(xiàn)得像在單機(jī)系統(tǒng)上一樣,符合直覺和預(yù)期。一致性模型有很多種,在這里我們只談以下常見的幾種:
線性一致性 是最強(qiáng)的一致性模型,也被稱為強(qiáng)一致性,在 CAP 定理中的 C 表達(dá)的一致性含義便是線性一致性。這種一致性模型要求系統(tǒng)要像單一節(jié)點(diǎn)一樣工作,并且所有操作是原子的,它有兩個約束條件:
順序記錄中的任何一次讀必須讀到最近一次寫入的數(shù)據(jù)
順序記錄要跟全局時鐘下的順序保持一致
順序一致性 要比線性一致性弱,它只要求 同一客戶端或進(jìn)程的操作在排序后保持先后順序不變,但 不同客戶端之間的先后順序是可以任意改變的,順序一致性與線性一致性的主要區(qū)別在于 沒有全局時間的限制。比如在社交網(wǎng)絡(luò)場景下,一個人通常不關(guān)注他看到的所有朋友的帖子的順序,但是對于某個具體朋友,仍然以正確的順序顯示帖子的順序。
因果一致性 則是比 順序一致性 更弱的一致性模型,因果一致性要求必須以相同的順序看到因果相關(guān)的操作,而沒有因果關(guān)系的并發(fā)操作可以被不同的進(jìn)程以不同的順序觀察到。典型的例子就是社交網(wǎng)絡(luò)中發(fā)帖和評論的關(guān)系:必須先有發(fā)帖才能對該帖子進(jìn)行評論,所以發(fā)帖操作必須在評論操作之前。
最終一致性 是常見的最弱的一致性模型,所謂最終表達(dá)的含義是“對于系統(tǒng)到達(dá)穩(wěn)定狀態(tài)并沒有硬性要求”,即便這聽起來很不靠譜,但是在業(yè)務(wù)中被應(yīng)用的很多也很好,而且這種一致性模型能使系統(tǒng)的性能很高。
CAP 定理:C 代表一致性,當(dāng)客戶端訪問所有節(jié)點(diǎn)時,返回的都是同一份最新的數(shù)據(jù);A 代表可用性,指每次請求都能獲取到非錯誤的響應(yīng),但不保證獲取的數(shù)據(jù)是最新的;P 代表分區(qū)容錯性,節(jié)點(diǎn)之間由于網(wǎng)絡(luò)分區(qū)而導(dǎo)致消息丟失的情況下,系統(tǒng)仍能正常運(yùn)行。
接下來我們再來談?wù)勀X裂問題:
腦裂問題
當(dāng)集群中發(fā)生網(wǎng)絡(luò)通訊問題時,讀、寫請求只能在超過半數(shù)節(jié)點(diǎn)的集群內(nèi)生效,過半數(shù)機(jī)制 在數(shù)學(xué)上保證不可能同時存在兩個Leader:
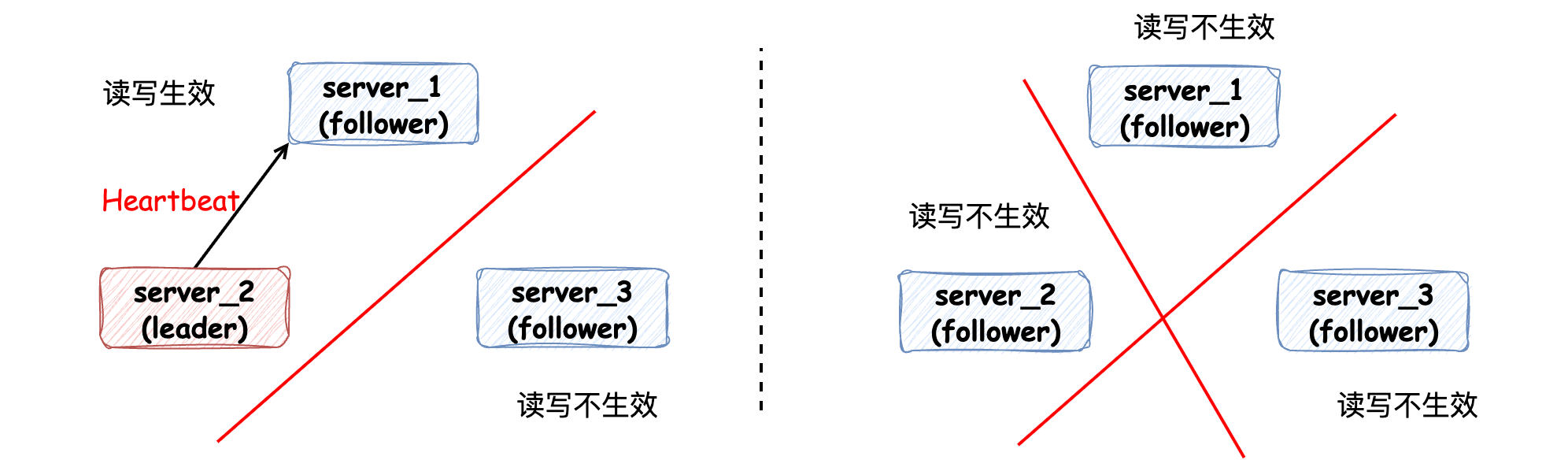
除此之外還有以下機(jī)制來避免腦裂問題:
Term機(jī)制:時間上保證舊Leader會自動讓位給新Leader
主動stepDown:Leader無法聯(lián)系到過半數(shù)節(jié)點(diǎn)時主動放棄領(lǐng)導(dǎo)權(quán)
嚴(yán)格的投票規(guī)則:每個term每個節(jié)點(diǎn)只能投票給一個候選人
當(dāng)網(wǎng)絡(luò)問題恢復(fù)時,F(xiàn)ollower 節(jié)點(diǎn)能通過 Leader 節(jié)點(diǎn)的日志同步重新追回期間錯過的數(shù)據(jù)。此外,一般采用 Raft 算法的集群在部署的時都是 “奇數(shù)個節(jié)點(diǎn)”,而不是偶數(shù)個節(jié)點(diǎn),這其實(shí)是數(shù)學(xué)的體現(xiàn),性價比更高:
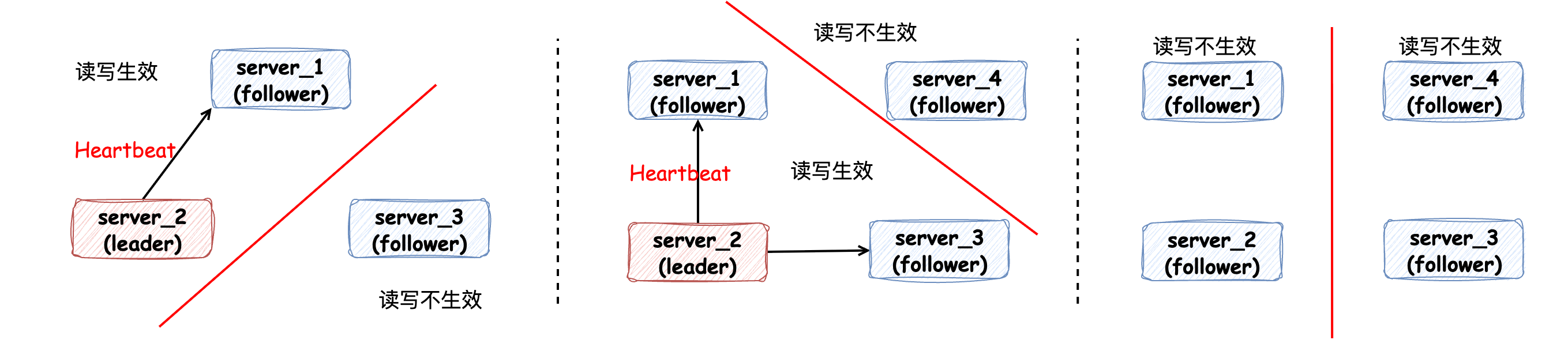
如上圖所示,雖然部署 4 個節(jié)點(diǎn)多出一個節(jié)點(diǎn),但是和 3 節(jié)點(diǎn)集群相比,容錯能力是相同的:只能容忍 1 個節(jié)點(diǎn)故障。在容錯能力沒有被提高的情況下又花費(fèi)了更多的服務(wù)器成本和運(yùn)維管理成本。
以上我們基本了解了 Raft 算法的內(nèi)容,如果想使用 Raft 算法,對系統(tǒng)模型有以下要求:
服務(wù)可能宕機(jī)、停止運(yùn)行,但過段時間能夠恢復(fù),但不能存在 拜占庭故障
消息可能丟失、延遲亂序或重復(fù);可能有網(wǎng)絡(luò)分區(qū),并在一段時間之后恢復(fù)
巨人的肩膀
SOFAJRaft
The Raft Consensus Algorithm
TiKV 功能介紹 – Lease Read
《深入理解分布式系統(tǒng)》
審核編輯 黃宇
-
算法
+關(guān)注
關(guān)注
23文章
4786瀏覽量
98188 -
分布式
+關(guān)注
關(guān)注
1文章
1095瀏覽量
76632
發(fā)布評論請先 登錄
如何解決分布式光伏計量難題?
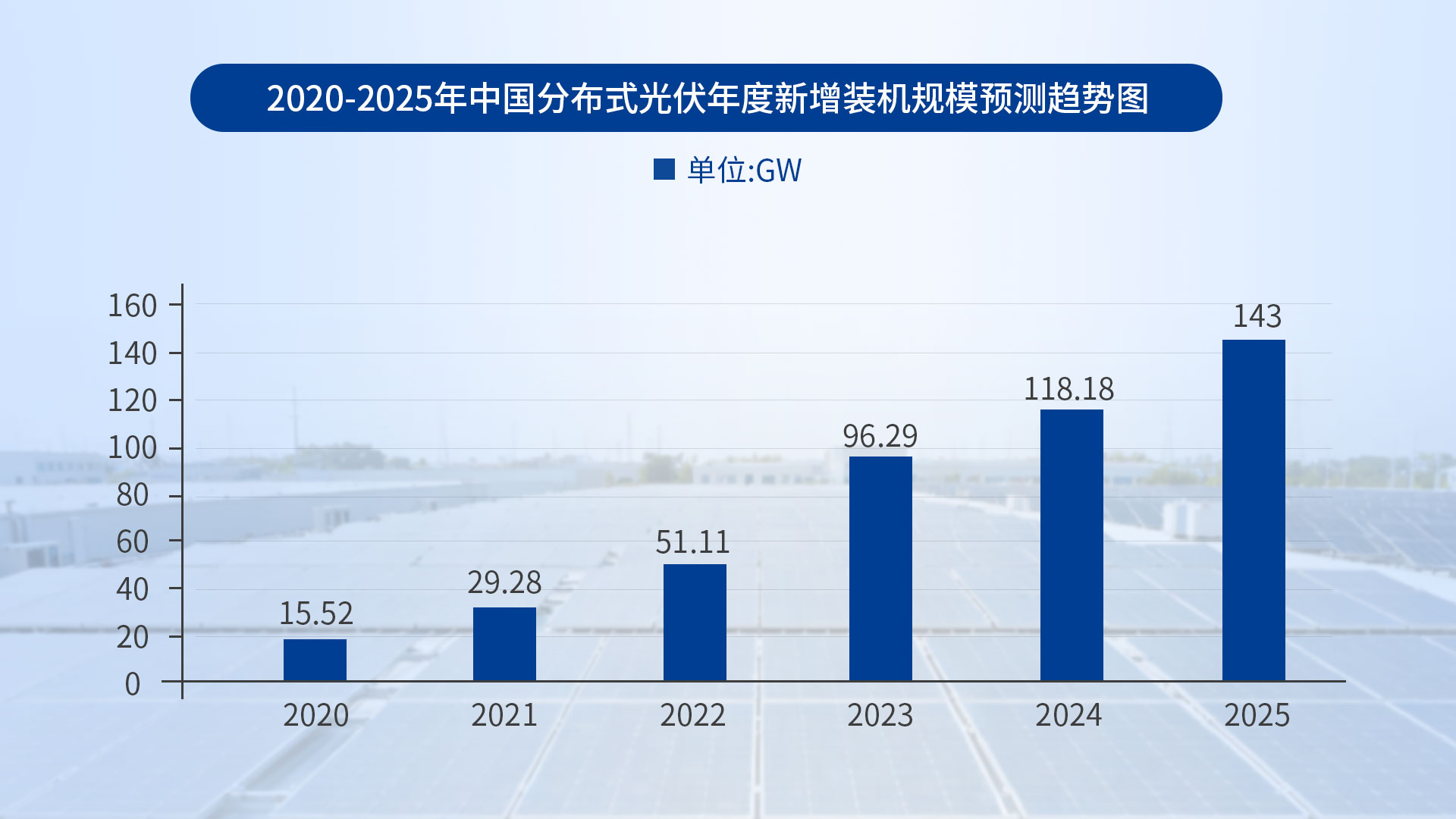
【節(jié)能學(xué)院】Acrel-1000DP分布式光伏監(jiān)控系統(tǒng)在奉賢平高食品 4.4MW 分布式光伏中應(yīng)用

分布式光伏發(fā)電監(jiān)測系統(tǒng)技術(shù)方案

安科瑞分布式光伏監(jiān)控系統(tǒng):賦能園區(qū)企業(yè)光伏用電智能化管理
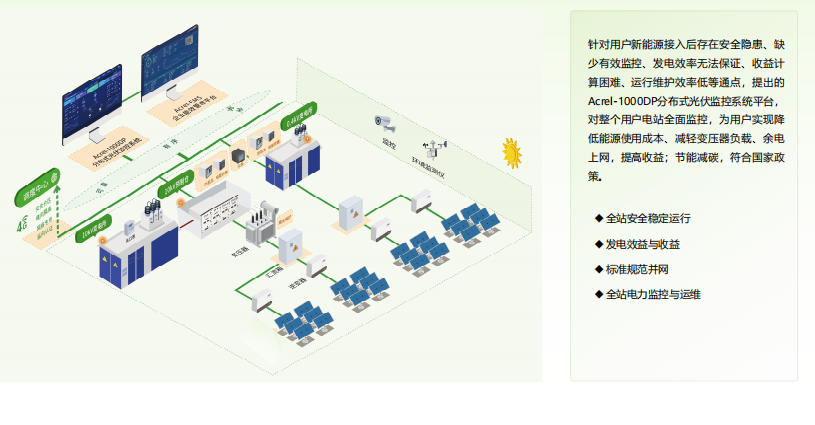
分布式光伏總出問題?安科瑞分布式光伏監(jiān)控系統(tǒng)來“救場”
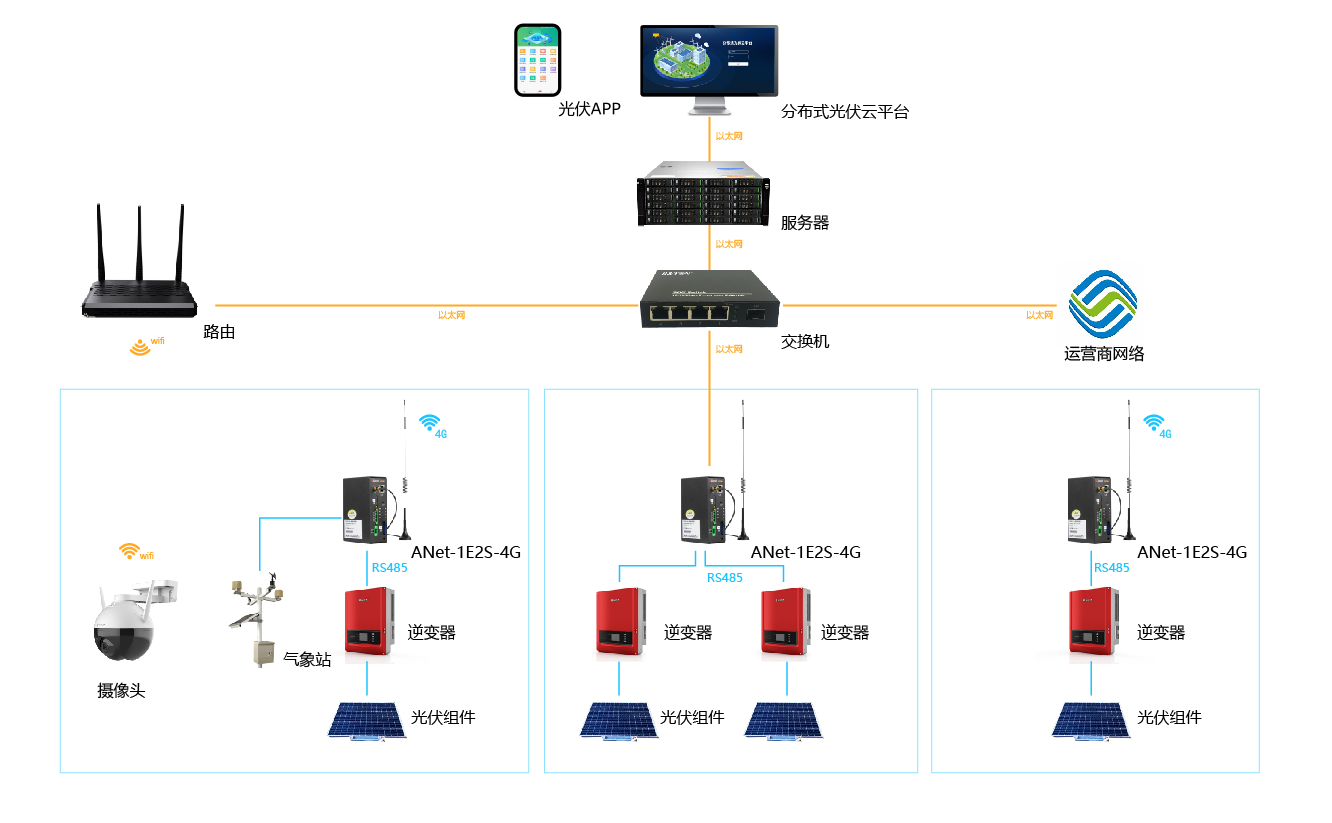
分布式IO選型指南:2025年分布式無線遠(yuǎn)程IO品牌及采集控制方案詳解
雙電機(jī)分布式驅(qū)動汽車高速穩(wěn)定性機(jī)電耦合控制
曙光存儲領(lǐng)跑中國分布式存儲市場
多通道電源管理芯片在分布式能源系統(tǒng)中的優(yōu)化策略
分布式光伏電力問題層出不窮?安科瑞分布式光伏運(yùn)維系統(tǒng)來“救場”
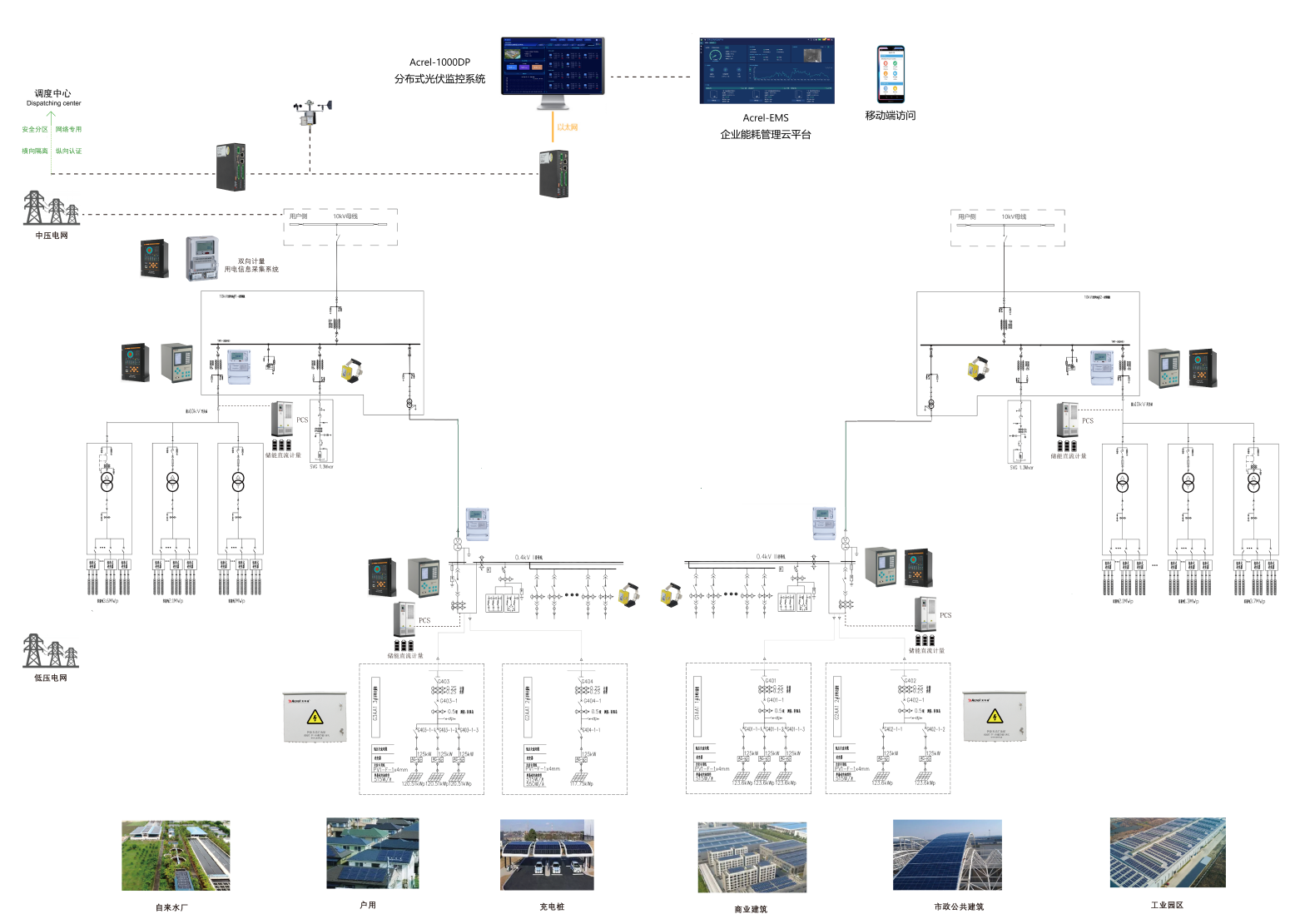
安科瑞Acrel-1000DP分布式光伏監(jiān)控系統(tǒng)在嘉興亨泰分布式光伏項(xiàng)目中的應(yīng)用
使用VirtualLab Fusion中分布式計算的AR波導(dǎo)測試圖像模擬
分布式光伏發(fā)運(yùn)維系統(tǒng)實(shí)際應(yīng)用案例分享
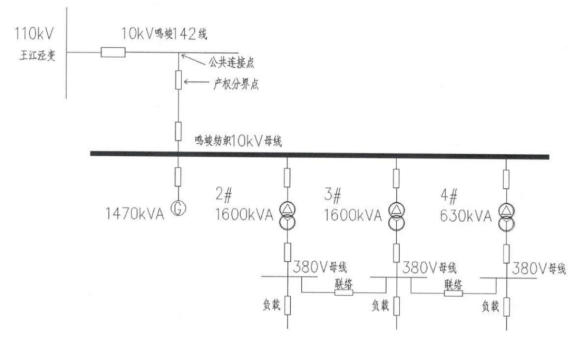
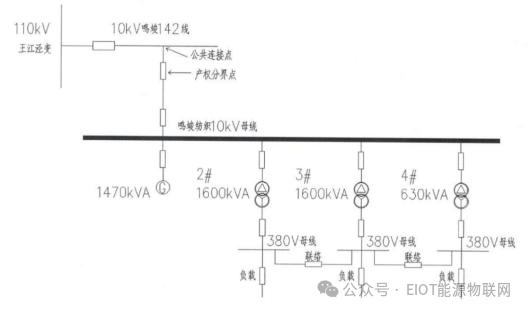
淺談分布式光伏系統(tǒng)在工業(yè)企業(yè)的設(shè)計及應(yīng)用




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論