") 常見的11個(gè)分類變量編碼方法
常見的11個(gè)分類變量編碼方法

機(jī)器學(xué)習(xí)算法只接受數(shù)值輸入,所以如果我們遇到分類特征的時(shí)候都會(huì)對(duì)分類特征進(jìn)行編碼,本文總結(jié)了常見的11個(gè)分類變量編碼方法。
1、ONE HOT ENCODING
最流行且常用的編碼方法是One Hot Enoding。一個(gè)具有n個(gè)觀測(cè)值和d個(gè)不同值的單一變量被轉(zhuǎn)換成具有n個(gè)觀測(cè)值的d個(gè)二元變量,每個(gè)二元變量使用一位(0,1)進(jìn)行標(biāo)識(shí)。
例如:
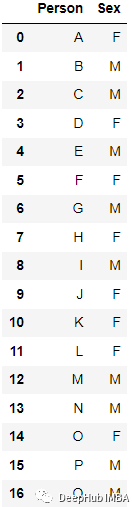
編碼后:
最簡(jiǎn)單的實(shí)現(xiàn)是使用pandas的' get_dummies
new_df=pd.get_dummies(columns=[‘Sex’], data=df)
2、Label Encoding
為分類數(shù)據(jù)變量分配一個(gè)唯一標(biāo)識(shí)的整數(shù)。這種方法非常簡(jiǎn)單,但對(duì)于表示無序數(shù)據(jù)的分類變量是可能會(huì)產(chǎn)生問題。比如:具有高值的標(biāo)簽可以比具有低值的標(biāo)簽具有更高的優(yōu)先級(jí)。
例如上面的數(shù)據(jù),我們編碼后得到了下面的結(jié)果:
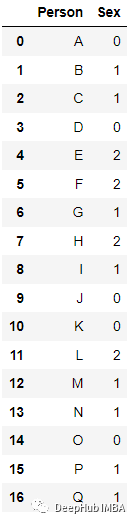
sklearn的LabelEncoder 可以直接進(jìn)行轉(zhuǎn)換:
from sklearn.preprocessing import LabelEncoder le=LabelEncoder() df[‘Sex’]=le.fit_transform(df[‘Sex’])
3、Label Binarizer
LabelBinarizer 是一個(gè)用來從多類別列表創(chuàng)建標(biāo)簽矩陣的工具類,它將把一個(gè)列表轉(zhuǎn)換成一個(gè)列數(shù)與輸入集合中惟一值的列數(shù)完全相同的矩陣。
例如這個(gè)數(shù)據(jù):
轉(zhuǎn)化后結(jié)果為:
from sklearn.preprocessing import LabelBinarizer lb = LabelBinarizer() new_df[‘Sex’]=lb.fit_transform(df[‘Sex’])
4、Leave one out Encoding
Leave One Out 編碼時(shí),目標(biāo)分類特征變量對(duì)具有相同值的所有記錄會(huì)被平均以確定目標(biāo)變量的平均值。在訓(xùn)練數(shù)據(jù)集和測(cè)試數(shù)據(jù)集之間,編碼算法略有不同。因?yàn)榭紤]到分類的特征記錄被排除在訓(xùn)練數(shù)據(jù)集外,因此被稱為“Leave One Out”。
對(duì)特定類別變量的特定值的編碼如下。
ci = (Σj != i tj / (n — 1 + R)) x (1 + εi) where ci = encoded value for ith record tj = target variable value for jth record n = number of records with the same categorical variable value R = regularization factor εi = zero mean random variable with normal distribution N(0, s)
例如下面的數(shù)據(jù):
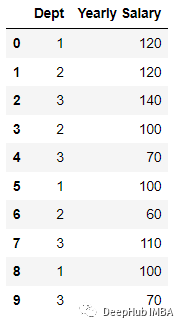
編碼后:
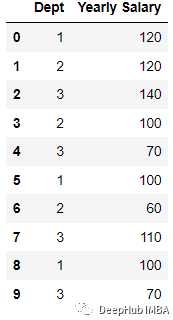
為了演示這個(gè)編碼過程,我們創(chuàng)建數(shù)據(jù)集:
importpandasaspd; data = [[‘1’, 120], [‘2’, 120], [‘3’, 140], [‘2’, 100], [‘3’, 70], [‘1’, 100],[‘2’, 60], [‘3’, 110], [‘1’, 100],[‘3’, 70] ] df = pd.DataFrame(data, columns = [‘Dept’,’Yearly Salary’])
然后進(jìn)行編碼:
import category_encoders as ce tenc=ce.TargetEncoder() df_dep=tenc.fit_transform(df[‘Dept’],df[‘Yearly Salary’]) df_dep=df_dep.rename({‘Dept’:’Value’}, axis=1) df_new = df.join(df_dep)
這樣就得到了上面的結(jié)果。
5、Hashing
當(dāng)使用哈希函數(shù)時(shí),字符串將被轉(zhuǎn)換為一個(gè)惟一的哈希值。因?yàn)樗褂玫膬?nèi)存很少可以處理更多的分類數(shù)據(jù)。對(duì)于管理機(jī)器學(xué)習(xí)中的稀疏高維特征,特征哈希是一種有效的方法。它適用于在線學(xué)習(xí)場(chǎng)景,具有快速、簡(jiǎn)單、高效、快速的特點(diǎn)。
例如下面的數(shù)據(jù):
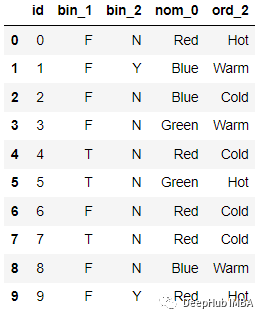
編碼后:
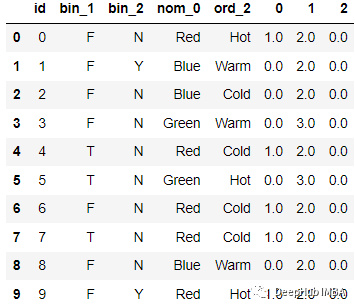
代碼如下:
from sklearn.feature_extraction import FeatureHasher # n_features contains the number of bits you want in your hash value. h = FeatureHasher(n_features = 3, input_type =’string’) # transforming the column after fitting hashed_Feature = h.fit_transform(df[‘nom_0’]) hashed_Feature = hashed_Feature.toarray() df = pd.concat([df, pd.DataFrame(hashed_Feature)], axis = 1) df.head(10)
6、Weight of Evidence Encoding
(WoE) 開發(fā)的主要目標(biāo)是創(chuàng)建一個(gè)預(yù)測(cè)模型,用于評(píng)估信貸和金融行業(yè)的貸款違約風(fēng)險(xiǎn)。證據(jù)支持或駁斥理論的程度取決于其證據(jù)權(quán)重或 WOE。
如果P(Goods) / P(Bads) = 1,則WoE為0。如果這個(gè)組的結(jié)果是隨機(jī)的,那么P(Bads) > P(Goods),比值比為1,證據(jù)的權(quán)重(WoE)為0。如果一組中P(Goods) > P(bad),則WoE大于0。
因?yàn)長(zhǎng)ogit轉(zhuǎn)換只是概率的對(duì)數(shù),或ln(P(Goods)/P(bad)),所以WoE非常適合于邏輯回歸。當(dāng)在邏輯回歸中使用wo編碼的預(yù)測(cè)因子時(shí),預(yù)測(cè)因子被處理成與編碼到相同的尺度,這樣可以直接比較線性邏輯回歸方程中的變量。
例如下面的數(shù)據(jù):
會(huì)被編碼為:
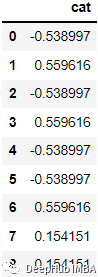
代碼如下:
from category_encoders import WOEEncoder df = pd.DataFrame({‘cat’: [‘a(chǎn)’, ‘b’, ‘a(chǎn)’, ‘b’, ‘a(chǎn)’, ‘a(chǎn)’, ‘b’, ‘c’, ‘c’], ‘target’: [1, 0, 0, 1, 0, 0, 1, 1, 0]}) woe = WOEEncoder(cols=[‘cat’], random_state=42) X = df[‘cat’] y = df.target encoded_df = woe.fit_transform(X, y)
7、Helmert Encoding
Helmert Encoding將一個(gè)級(jí)別的因變量的平均值與該編碼中所有先前水平的因變量的平均值進(jìn)行比較。
反向 Helmert 編碼是類別編碼器中變體的另一個(gè)名稱。它將因變量的特定水平平均值與其所有先前水平的水平的平均值進(jìn)行比較。
會(huì)被編碼為:
代碼如下:
import category_encoders as ce encoder=ce.HelmertEncoder(cols=’Dept’) new_df=encoder.fit_transform(df[‘Dept’]) new_hdf=pd.concat([df,new_df], axis=1) new_hdf
8、Cat Boost Encoding
是CatBoost編碼器試圖解決的是目標(biāo)泄漏問題,除了目標(biāo)編碼外,還使用了一個(gè)排序概念。它的工作原理與時(shí)間序列數(shù)據(jù)驗(yàn)證類似。當(dāng)前特征的目標(biāo)概率僅從它之前的行(觀測(cè)值)計(jì)算,這意味著目標(biāo)統(tǒng)計(jì)值依賴于觀測(cè)歷史。
TargetCount:某個(gè)類別特性的目標(biāo)值的總和(到當(dāng)前為止)。
Prior:它的值是恒定的,用(數(shù)據(jù)集中的觀察總數(shù)(即行))/(整個(gè)數(shù)據(jù)集中的目標(biāo)值之和)表示。
featucalculate:到目前為止已經(jīng)看到的、具有與此相同值的分類特征的總數(shù)。
編碼后的結(jié)果如下:
代碼:
import category_encoders category_encoders.cat_boost.CatBoostEncoder(verbose=0, cols=None, drop_invariant=False, return_df=True, handle_unknown=’value’, handle_missing=’value’, random_state=None, sigma=None, a=1) target = df[[‘target’]] train = df.drop(‘target’, axis = 1) # Define catboost encoder cbe_encoder = ce.cat_boost.CatBoostEncoder() # Fit encoder and transform the features cbe_encoder.fit(train, target) train_cbe = cbe_encoder.transform(train)
9、James Stein Encoding
James-Stein 為特征值提供以下加權(quán)平均值:
觀察到的特征值的平均目標(biāo)值。
平均期望值(與特征值無關(guān))。
James-Stein 編碼器將平均值縮小到全局的平均值。該編碼器是基于目標(biāo)的。但是James-Stein 估計(jì)器有缺點(diǎn):它只支持正態(tài)分布。
它只能在給定正態(tài)分布的情況下定義(實(shí)時(shí)情況并非如此)。為了防止這種情況,我們可以使用 beta 分布或使用對(duì)數(shù)-比值比轉(zhuǎn)換二元目標(biāo),就像在 WOE 編碼器中所做的那樣(默認(rèn)使用它,因?yàn)樗芎?jiǎn)單)。
10、M Estimator Encoding:
Target Encoder的一個(gè)更直接的變體是M Estimator Encoding。它只包含一個(gè)超參數(shù)m,它代表正則化冪。m值越大收縮越強(qiáng)。建議m的取值范圍為1 ~ 100。
11、 Sum Encoder
Sum Encoder將類別列的特定級(jí)別的因變量(目標(biāo))的平均值與目標(biāo)的總體平均值進(jìn)行比較。在線性回歸(LR)的模型中,Sum Encoder和ONE HOT ENCODING都是常用的方法。兩種模型對(duì)LR系數(shù)的解釋是不同的,Sum Encoder模型的截距代表了總體平均值(在所有條件下),而系數(shù)很容易被理解為主要效應(yīng)。在OHE模型中,截距代表基線條件的平均值,系數(shù)代表簡(jiǎn)單效應(yīng)(一個(gè)特定條件與基線之間的差)。
-
編碼
+關(guān)注
關(guān)注
6文章
1039瀏覽量
56967 -
變量
+關(guān)注
關(guān)注
0文章
616瀏覽量
29505
原文標(biāo)題:11 個(gè)常見的分類特征的編碼技術(shù)
文章出處:【微信號(hào):vision263com,微信公眾號(hào):新機(jī)器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
機(jī)器學(xué)習(xí)特征工程:分類變量的數(shù)值化處理方法

如何規(guī)范用、但不濫用局部變量(Local Variable)
PEC11J系列12mm SMD長(zhǎng)壽命編碼器:特性、參數(shù)與應(yīng)用全解析
用戶對(duì)變量或寄存器進(jìn)行位操作的方法
LED顯示屏常見故障分類及處理方法

增量式編碼器:精準(zhǔn)測(cè)量背后的分類智慧
PLC中Static和Temp變量的區(qū)別
量子機(jī)器學(xué)習(xí)入門:三種數(shù)據(jù)編碼方法對(duì)比與應(yīng)用

常見的PFC拓?fù)浼軜?gòu)及控制方法
編碼器常見的故障詳細(xì)說明
各類電機(jī)有沒有編碼器?如何分類?
伺服電機(jī)編碼器怎么選型




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論