 利用設計網關的 IP 內核在 Xilinx VCK190 評估套件上加速人工智能應用
利用設計網關的 IP 內核在 Xilinx VCK190 評估套件上加速人工智能應用

Xilinx 的 Versal AI Core 系列器件旨在解決獨特且最困難的 AI 推理問題,方法是使用高計算效率 ASIC 級 AI 計算引擎和靈活的可編程結構來構建具有加速器的 AI 應用,從而最大限度地提高任何給定工作負載的效率,同時提供低功耗和低延遲。
Versal AI Core 系列VCK190 評估套件采用VC1902器件,該器件在產品組合中具有最佳的 AI 性能。該套件專為需要高吞吐量 AI 推理和信號處理計算性能的設計而設計。VCK190 套件的計算能力是當前服務器級 CPU 的 100 倍,并具有多種連接選項,是從云到邊緣的各種應用的理想評估和原型設計平臺。
 圖 1:賽靈思 Versal AI 內核系列 VCK190 評估套件。(圖片來源:AMD, Inc)
圖 1:賽靈思 Versal AI 內核系列 VCK190 評估套件。(圖片來源:AMD, Inc)
VCK190 評估套件的主要特性
- 板載 Versal AI 核心系列設備
- 用于前沿應用開發的最新連接技術
- 協同優化工具和調試方法
利用賽靈思 Versal AI 內核系列器件實現 AI 接口加速

圖 2:賽靈思 Versal AI 內核 VC1902 ACAP 器件框圖。(圖片來源:AMD, Inc)
Versal? AI Core 自適應計算加速平臺 (ACAP) 是一款高度集成的多核異構設備,可在硬件和軟件級別動態適應各種 AI 工作負載,使其成為 AI 邊緣計算應用或云加速器卡的理想選擇。該平臺集成了用于嵌入式計算的下一代標量引擎、用于硬件靈活性的自適應引擎,以及由 DSP 引擎和用于推理和信號處理的革命性 AI 引擎組成的智能引擎。其結果是一個適應性強的加速器,其性能、延遲和能效超過了傳統 FPGA 和 GPU 的性能、延遲和能效,適用于 AI/ML 工作負載。
Versal ACAP 平臺亮點
VCK190 人工智能推理性能
與當前服務器級 CPU 相比,VCK190 能夠提供超過 100 倍的計算性能。下面是基于 C32B6 DPU 內核的 AI 引擎實現的性能示例,批處理 = 6。有關 VCK190 上各種神經網絡樣本的吞吐量性能(以幀/秒或 fps 為單位),DPU 以 1250 MHz 運行,請參閱下表。
| no | 神經網絡 | 輸入大小 | 共和黨 | 性能(幀率)(多線程) |
|---|---|---|---|---|
| 1 | face_landmark | 96x72 | 0.14 | 24605.3 |
| 2 | facerec_resnet20 | 112×96 | 3.5 | 5695.3 |
| 3 | inception_v2 | 224×224 | 4 | 1845.8 |
| 4 | medical_seg_cell_tf2 | 128×128 | 5.3 | 3036.3 |
| 5 | MLPerf_resnet50_v1.5_tf | 224×224 | 8.19 | 2744.2 |
| 6 | 精煉Medical_EDD_tf | 320x320 | 9.8 | 1283.6 |
| 7 | tiny_yolov3_vmss | 416×416 | 5.46 | 1424.4 |
| 8 | yolov2_voc_pruned_0_77 | 448×448 | 7.8 | 1366.0 |
表 1:VCK190 AI 推理性能示例。
有關 VCK190 AI 性能的更多詳細信息,請參閱 Vitis AI 庫用戶指南 (UG1354), r2.5.0 athttps://docs.xilinx.com/r/en-US/ug1354-xilinx-ai-sdk/VCK190-Evaluation-Board
設計網關的 IP 核如何提高 AI 應用程序性能?
設計網關的IP 核設計用于處理網絡和數據存儲協議,無需 CPU 干預。這使得將CPU系統從復雜的協議處理中完全卸載成為理想的選擇,并使它們能夠將大部分計算能力用于AI應用程序,包括AI推理,前后數據處理,用戶界面,網絡通信和數據存儲訪問,以獲得最佳性能。
 圖 3:具有設計網關 IP 核的示例 AI 應用程序的框圖。(圖片來源:設計網關)
圖 3:具有設計網關 IP 核的示例 AI 應用程序的框圖。(圖片來源:設計網關)
設計網關的 TCP 卸載引擎 IP (TOExxG-IP) 性能
傳統 CPU 系統處理超過 10GbE 或 25GbE 的高速、高吞吐量 TCP 數據流需要超過 50% 的 CPU 時間,這會降低 AI 應用程序的整體性能。根據賽靈思MPSoC Linux系統上的10G TCP性能測試,10GbE TCP傳輸過程中的CPU使用率超過50%,TCP發送和接收數據傳輸速度可以達到10GbE速度的40%至60%左右或400 MB / s至600 MB / s。
通過實施設計網關的TOExxG-IP 內核,通過 10GbE 和 25GbE 傳輸的 CPU 使用率可以降低到幾乎 0%,同時以太網帶寬利用率可以達到接近 100%。這允許通過純硬件邏輯直接通過 TCP 網絡發送和接收數據,并以最小的 CPU 使用率和盡可能低的延遲饋送到 Versal AI 引擎。下面的圖 4 顯示了 TOExxG-IP 和 MPSoC Linux 系統之間的 CPU 使用率和 TCP 傳輸速度比較。
 圖 4:MPSoC Linux 系統和 Design Gateway 的 TOExxG-IP 內核對 10G/25G TCP 傳輸的性能比較。(圖片來源:設計網關)
圖 4:MPSoC Linux 系統和 Design Gateway 的 TOExxG-IP 內核對 10G/25G TCP 傳輸的性能比較。(圖片來源:設計網關)
設計網關的 TOExxG-IP for Versal 設備
 圖 5:TOExxG-IP 系統概述。(圖片來源:設計網關)
圖 5:TOExxG-IP 系統概述。(圖片來源:設計網關)
TOExxG-IP 內核實現了 TCP/IP 堆棧(硬線邏輯),并與賽靈思的 EMAC 硬 IP 和以太網子系統模塊連接,以實現 10G/25G/100G 以太網速度的下層硬件接口。TOExxG-IP 的用戶界面由用于控制信號的寄存器接口和用于數據信號的 FIFO 接口組成。TOExxG-IP 設計用于通過 AXI4-ST 接口與賽靈思以太網子系統連接。用戶界面的時鐘頻率取決于以太網接口速度(例如,156.625 MHz 或 322.266 MHz)。
TOExxG-IP的特點
- 完整的 TCP/IP 堆棧實現,無需 CPU
- 支持一個會話與一個 TOExxG-IP
- 可以使用多個 TOExxG-IP 實例實現多會話
- 支持服務器和客戶端模式(被動/主動打開和關閉)
- 支持巨型幀
- 通過標準先進先出接口實現簡單的數據接口
- 通過單端口 RAM 接口實現簡單的控制接口
XCVC1902-VSVA2197-2MP-ES FPGA 器件上的 FPGA 資源使用情況如下表 2 所示。
| 家庭 | 示例設備 | 最大頻率 (兆赫 | 負載均衡注冊 | 負載均衡 LUT | 片 | IOB | 布拉姆蒂勒^1^ | 烏蘭 | 設計工具 |
|---|---|---|---|---|---|---|---|---|---|
| Versal AI Core | XCVC1902-VSVA2197-2MP-ES | 350 | 11340 | 10921 | 2165 | - | 51.5 | - | 萬歲2021.2 |
表 2:Versal 設備的實現統計信息示例。
TOExxG-IP 的更多詳細信息在其數據表中進行了描述,可通過以下鏈接從設計網關的網站下載:
Design Gateway's NVMe Host Controller IP performance
NVMe Storage interface speed with PCIe Gen3 x4 or PCIe Gen4 x4 has data rates up to 32 Gbps and 64 Gbps. This is three to six times higher than 10GbE Ethernet speed. Processing complicated NVMe storage protocol by the CPU to achieve the highest possible disk access speed requires more CPU time than TCP protocol over 10GbE.
Design Gateway solved this problem by developing the NVMe IP core that is able to run as a standalone NVMe host controller, able to communicate with an NVMe SSD directly without the CPU. This enables a high efficiency and performance of the NVMe PCIe Gen3 and Gen4 SSD access, which simplifies the user interface and standard features for ease of usage without needing knowledge of the NVMe protocol. NVMe PCIe Gen4 SSD performance can achieve up to a 6 GB/s transfer speed with NVMe IP as shown in Figure 6.
 Figure 6: Performance comparison of NVMe PCIe Gen3 and Gen4 SSD with Design Gateway's NVMe-IP Core. (Image source: Design Gateway)
Figure 6: Performance comparison of NVMe PCIe Gen3 and Gen4 SSD with Design Gateway's NVMe-IP Core. (Image source: Design Gateway)
Design Gateway's NVMe-IP’s for Versal devices
 Figure 7: NVMe-IP systems overview. (Image source: Design Gateway)
Figure 7: NVMe-IP systems overview. (Image source: Design Gateway)
NVMe-IP’s features
- Able to implement application layer, transaction layer, data link layer, and some parts of the physical layer to access the NVMe SSD without a CPU or external DDR memory
- Operates with Xilinx PCIe Gen3 and Gen4 Hard IP
- 能夠利用BRAM和URAM作為數據緩沖區,而無需外部存儲器接口
- 支持六個命令:識別、關機、寫入、讀取、SMART 和刷新(提供可選的附加命令支持)
XCVC1902-VSVA2197-2MP-E-S FPGA 器件上的 FPGA 資源使用情況如表 2 所示。
| 家庭 | 示例設備 | 最大頻率 (兆赫) | 負載均衡注冊 | 負載均衡 LUT | 片 | IOB | 布拉姆蒂勒^1^ | 烏蘭 | 設計工具 |
|---|---|---|---|---|---|---|---|---|---|
| Versal AI Core | XCVC1902-VSVA2197-2MP-ES | 375 | 6280 | 3948 | 1050 | - | 4 | 8 | 萬歲2022.1 |
表 3:Versal 設備的實現統計信息示例。
有關 Versal 器件的 NVMe-IP 的更多詳細信息,請參見其數據表,可通過以下鏈接從 Design Gateway 的網站下載:
結論
TOExxG-IP 和 NVMe-IP 內核都可以通過將 CPU 系統從計算和內存密集型協議(如 TCP 和 NVMe 存儲協議)中完全卸載來幫助加速 AI 應用程序性能,這對于實時 AI 應用程序至關重要。這使得賽靈思的 Versal AI Core 系列器件能夠執行 AI 推理和高性能計算應用,而不會出現網絡和數據存儲協議處理的瓶頸或延遲。
VCK190 評估套件和 Design Gateway 的網絡和存儲 IP 解決方案可在 Xilinx 的 Versal AI Core 器件上以盡可能低的 FPGA 資源使用量和極高的能效在 AI 應用中實現最佳性能。
-
測試
+關注
關注
9文章
6201瀏覽量
131345
發布評論請先 登錄
淺談人工智能(2)

人工智能+工業物聯網網關有什么功能作用
探索CY8CKIT - 062S2 - AI PSoC? 6人工智能評估套件
探索AMD XILINX Versal Prime Series VMK180評估套件,開啟硬件創新之旅
利用超微型 Neuton ML 模型解鎖 SoC 邊緣人工智能
AI 邊緣計算網關:開啟智能新時代的鑰匙?—龍興物聯
挖到寶了!人工智能綜合實驗箱,高校新工科的寶藏神器
挖到寶了!比鄰星人工智能綜合實驗箱,高校新工科的寶藏神器!
在AMD Versal自適應SoC上使用QEMU+協同仿真示例
超小型Neuton機器學習模型, 在任何系統級芯片(SoC)上解鎖邊緣人工智能應用.
最新人工智能硬件培訓AI 基礎入門學習課程參考2025版(大模型篇)
STM32N6570-DK:邊緣人工智能開發的全能探索板

Cognizant將與NVIDIA合作部署神經人工智能平臺,加速企業人工智能應用

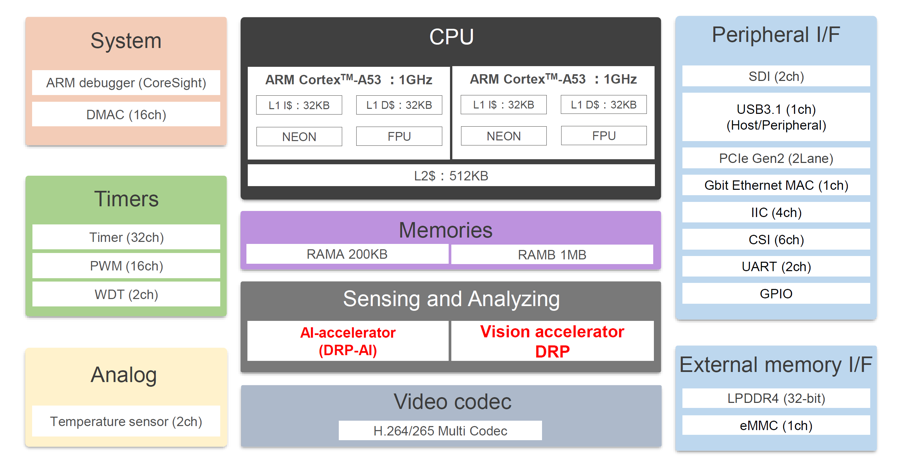
支持實時物體識別的視覺人工智能微處理器RZ/V2MA數據手冊



 工商網監
工商網監
評論