 基于深度學習的視覺檢測系統的特點及應用
基于深度學習的視覺檢測系統的特點及應用

一、什么是視覺檢測中的深度學習?
在深度學習算法出來之前,對于視覺算法來說,大致可以分為以下5個步驟:特征感知,圖像預處理,特征提取,特征篩選,推理預測與識別。早期的機器學習中,占優勢的統計機器學習群體中,對特征是不大關心的。
深度學習是機器學習技術的一個方面,由人工神經網絡提供支持。深度學習技術的工作原理是教機器通過實例學習。通過為神經網絡提供特定類型數據的標記示例,可以提取這些示例之間的共同模式,然后將其轉換為數學方程。這有助于對未來的信息進行分類。
通過視覺檢測技術,深度學習算法的集成可以區分零件、異常和字符,在運行計算機化系統的同時模擬人類視覺檢測。
那么,這到底是什么意思呢?舉個例子。
如果要為汽車制造創建視覺檢測軟件,你應該開發一種基于深度學習的算法,并使用必須檢測的缺陷示例對其進行訓練。有了足夠的數據,神經網絡最終會在沒有任何額外指令的情況下檢測缺陷。
基于深度學習的視覺檢測系統擅長檢測性質復雜的缺陷。它們不僅可以解決復雜的表面和外觀缺陷,還可以概括和概念化汽車零件的表面。
仿生學角度看深度學習
如果不手動設計特征,不挑選分類器,有沒有別的方案呢?能不能同時學習特征和分類器?即輸入某一個模型的時候,輸入只是圖片,輸出就是它自己的標簽。比如輸入一個明星的頭像,出來的標簽就是一個50維的向量(如果要在50個人里識別的話),其中對應明星的向量是1,其他的位置是0。
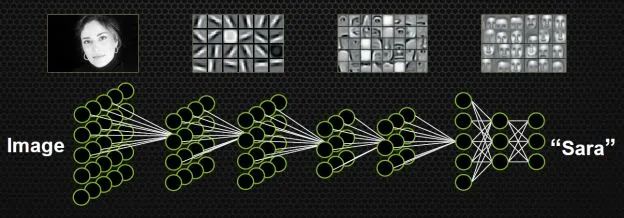
這種設定符合人類腦科學的研究成果。
1981年諾貝爾醫學生理學獎頒發給了David Hubel,一位神經生物學家。他的主要研究成果是發現了視覺系統信息處理機制,證明大腦的可視皮層是分級的。他的貢獻主要有兩個,一是他認為人的視覺功能一個是抽象,一個是迭代。抽象就是把非常具體的形象的元素,即原始的光線像素等信息,抽象出來形成有意義的概念。這些有意義的概念又會往上迭代,變成更加抽象,人可以感知到的抽象概念。
像素是沒有抽象意義的,但人腦可以把這些像素連接成邊緣,邊緣相對像素來說就變成了比較抽象的概念;邊緣進而形成球形,球形然后到氣球,又是一個抽象的過程,大腦最終就知道看到的是一個氣球。
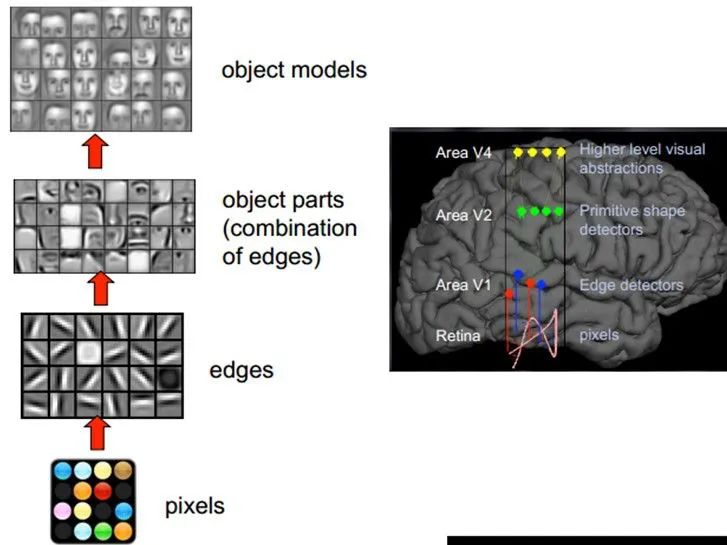
模擬人腦識別人臉,也是抽象迭代的過程,從最開始的像素到第二層的邊緣,再到人臉的部分,然后到整張人臉,是一個抽象迭代的過程。
再比如看到圖片中的摩托車,我們可能在腦子里就幾微秒的時間,但是經過了大量的神經元抽象迭代。對計算機來說最開始看到的根本也不是摩托車,而是RGB圖像三個通道上不同的數字。
所謂的特征或者視覺特征,就是把這些數值給綜合起來用統計或非統計的形式,把摩托車的部件或者整輛摩托車表現出來。深度學習的流行之前,大部分的設計圖像特征就是基于此,即把一個區域內的像素級別的信息綜合表現出來,利于后面的分類學習。
如果要完全模擬人腦,我們也要模擬抽象和遞歸迭代的過程,把信息從最細瑣的像素級別,抽象到“種類”的概念,讓人能夠接受。
卷積的概念
計算機視覺里經常使卷積神經網絡,即CNN,是一種對人腦比較精準的模擬。
什么是卷積?卷積就是兩個函數之間的相互關系,然后得出一個新的值,他是在連續空間做積分計算,然后在離散空間內求和的過程。實際上在計算機視覺里面,可以把卷積當做一個抽象的過程,就是把小區域內的信息統計抽象出來。
比如,對于一張愛因斯坦的照片,我可以學習n個不同的卷積和函數,然后對這個區域進行統計。可以用不同的方法統計,比如著重統計中央,也可以著重統計周圍,這就導致統計的和函數的種類多種多樣,為了達到可以同時學習多個統計的累積和。
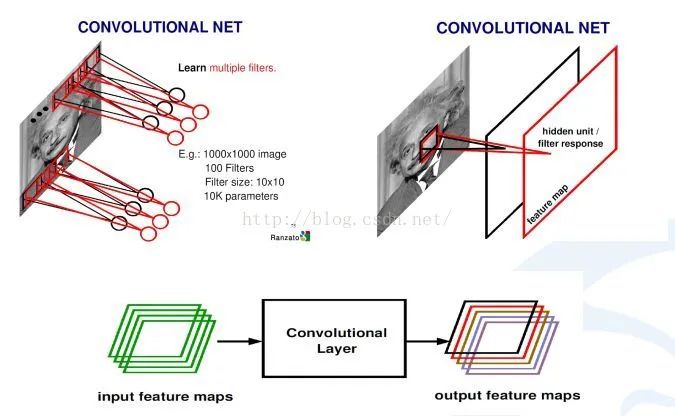
上圖中是,如何從輸入圖像怎么到最后的卷積,生成的響應map。首先用學習好的卷積和對圖像進行掃描,然后每一個卷積和會生成一個掃描的響應圖,我們叫response map,或者叫feature map。如果有多個卷積和,就有多個feature map。也就說從一個最開始的輸入圖像(RGB三個通道)可以得到256個通道的feature map,因為有256個卷積和,每個卷積和代表一種統計抽象的方式。
在卷積神經網絡中,除了卷積層,還有一種叫池化的操作。池化操作在統計上的概念更明確,就是一個對一個小區域內求平均值或者求最大值的統計操作。
帶來的結果是,如果之前我輸入有兩個通道的,或者256通道的卷積的響應feature map,每一個feature map都經過一個求最大的一個池化層,會得到一個比原來feature map更小的256的feature map。
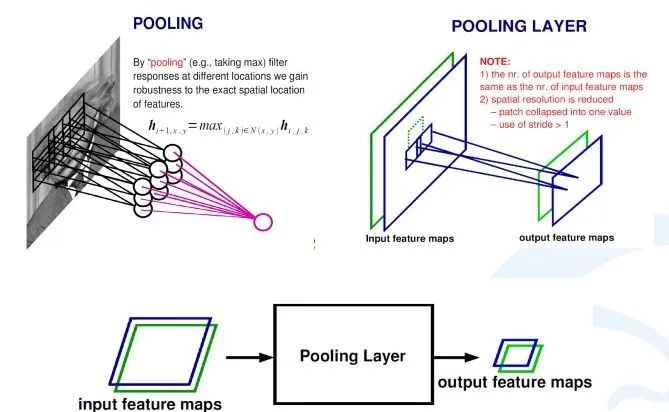
在上面這個例子里,池化層對每一個2X2的區域求最大值,然后把最大值賦給生成的feature map的對應位置。如果輸入圖像是100×100的話,那輸出圖像就會變成50×50,feature map變成了一半。同時保留的信息是原來2X2區域里面最大的信息。
操作的實例:LeNet網絡
Le顧名思義就是指人工智能領域的大牛Lecun。這個網絡是深度學習網絡的最初原型,因為之前的網絡都比較淺,它較深的。LeNet在98年就發明出來了,當時Lecun在AT&T的實驗室,他用這一網絡進行字母識別,達到了非常好的效果。
怎么構成呢?輸入圖像是32×32的灰度圖,第一層經過了一組卷積和,生成了6個28X28的feature map,然后經過一個池化層,得到得到6個14X14的feature map,然后再經過一個卷積層,生成了16個10X10的卷積層,再經過池化層生成16個5×5的feature map。
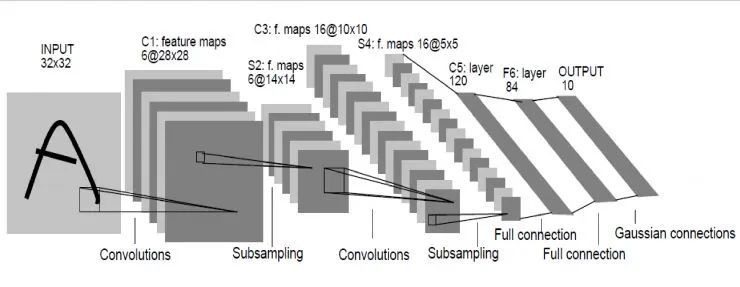
從最后16個5X5的feature map開始,經過了3個全連接層,達到最后的輸出,輸出就是標簽空間的輸出。由于設計的是只要對0到9進行識別,所以輸出空間是10,如果要對10個數字再加上26個大小字母進行識別的話,輸出空間就是62。62維向量里,如果某一個維度上的值最大,它對應的那個字母和數字就是就是預測結果。
壓在駱駝身上的最后一根稻草
從98年到本世紀初,深度學習興盛起來用了15年,但當時成果泛善可陳,一度被邊緣化。到2012年,深度學習算法在部分領域取得不錯的成績,而壓在駱駝身上最后一根稻草就是AlexNet。
AlexNet由多倫多大學幾個科學家開發,在ImageNet比賽上做到了非常好的效果。當時AlexNet識別效果超過了所有淺層的方法。此后,大家認識到深度學習的時代終于來了,并有人用它做其它的應用,同時也有些人開始開發新的網絡結構。
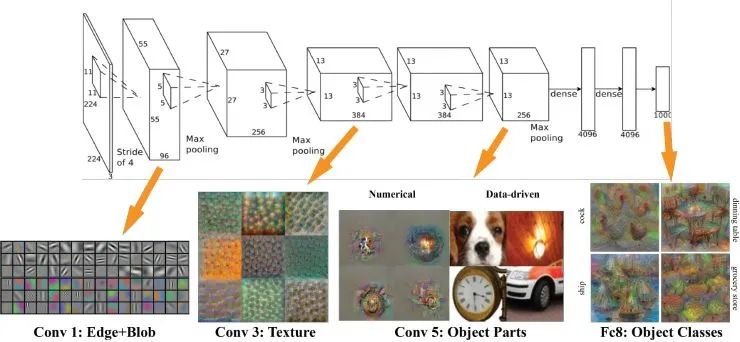
其實AlexNet的結構也很簡單,只是LeNet的放大版。輸入是一個224X224的圖片,是經過了若干個卷積層,若干個池化層,最后連接了兩個全連接層,達到了最后的標簽空間。
去年,有些人研究出來怎么樣可視化深度學習出來的特征。那么,AlexNet學習出的特征是什么樣子?在第一層,都是一些填充的塊狀物和邊界等特征;中間的層開始學習一些紋理特征;更高接近分類器的層級,則可以明顯看到的物體形狀的特征。
最后的一層,即分類層,完全是物體的不同的姿態,根據不同的物體展現出不同姿態的特征了。
可以說,不論是對人臉,車輛,大象或椅子進行識別,最開始學到的東西都是邊緣,繼而就是物體的部分,然后在更高層層級才能抽象到物體的整體。整個卷積神經網絡在模擬人的抽象和迭代的過程。
二、如何集成AI視覺檢測系統
1. 明確需求:
視覺檢測開發通常從業務和技術分析開始。這里的目標是確定系統應該檢測什么樣的缺陷。
需要提前明確的重要問題包括:
什么是AI視覺檢測系統的環境?
AI檢測應該是實時的還是延時的?
AI視覺檢測應該如何徹底檢測缺陷,是否應該按類型區分?
是否有任何現有的軟件可以集成視覺檢測功能,還是需要從頭開始開發?
系統應如何將檢測到的缺陷通知用戶?
AI視覺檢測系統是否應該記錄缺陷檢測統計數據?
關鍵問題是:是否存在用于深度學習模型開發的數據,包括“好”和“壞”產品的圖像以及不同類型的缺陷?
2. 收集和準備數據:
在深度學習模型開發開始之前,數據科學工程師必須收集和準備訓練未來模型所需的數據。對于制造流程,實施物聯網數據分析非常重要。在談論AI視覺檢測模型時,數據通常是視頻記錄,其中視覺檢測模型處理的圖像包括視頻幀。數據收集有多種選擇,但最常見的是:
現有視頻記錄,適用于特定目的的開源視頻記錄,根據深度學習模型要求從頭開始收集數據。
這里最重要的參數是視頻記錄的質量。更高質量的數據將導致更準確的結果。一旦我們收集了數據,我們就為建模做好準備、清理、檢查異常并確保其相關性。
3. 開發深度學習模型
深度學習模型開發方法的選擇取決于任務的復雜性、所需的交付時間和預算限制。有幾種方法:
1)使用深度學習模型開發(例如:Google Cloud ML Engine、Amazon ML 等)
當缺陷檢測功能的要求與給定服務提供的模板一致時,這種類型的方法是有意義的。這些服務可以節省時間和預算,因為無需從頭開始開發模型。只需要根據相關任務上傳數據并設置模型選項。
問題就是這些類型的模型不可定制。模型的功能僅限于給定服務提供的選項。
2) 使用預訓練模型
預訓練模型是一種已經創建的深度學習模型,它可以完成與我們想要執行的任務類似的任務。我們不必從頭開始構建模型,因為它使用基于用戶自己的數據訓練模型。
預訓練模型可能不會 100% 符合我們的所有任務,但它可以節省大量時間和成本。使用之前在大型數據集上訓練過的模型,用戶可以根據自己的問題定制這些解決方案。
3)從零開始深度學習模型開發
這種方法非常適用于復雜且安全的視覺檢測系統。這種方法可能需要大量時間和精力,但結果是值得的。
在開發自定義視覺檢測模型時,數據科學家會使用一種或多種計算機視覺算法。這些包括圖像分類、對象檢測和實例分割。
許多因素會影響深度學習算法的選擇。這些包括:
業務目標;
物體/缺陷的大小;
光照條件;
檢驗產品數量;
缺陷類型;
圖像分辨率;
假設我們正在開發用于建筑物質量評估的目視檢查模型。主要重點是檢測墻壁上的缺陷。需要大量數據集才能獲得準確的視覺檢查結果,因為缺陷類別可能非常多樣化,從油漆剝落和霉菌到墻壁裂縫。這里的最佳方法是從頭開始開發基于實例分割的模型。在某些情況下,預先訓練的模型方法也是可行的。
4. 訓練和評估
開發視覺檢測模型后的下一步是對其進行訓練。在這個階段,數據科學家驗證和評估模型的性能和結果準確性。測試數據集在這里很有用。對于視覺檢測系統,它可能是一組過已有的或類似于要在部署后處理的視頻資料。
5. 部署和改進
在部署視覺檢測模型時,重要的是要考慮軟件和硬件系統架構如何與模型容量對應。
1)軟件
視覺檢測驅動軟件的結構基于用于數據傳輸的 Web 解決方案和用于神經網絡處理的 Python 框架的組合。這里的關鍵參數是數據存儲。有三種常見的數據存儲方式:在本地服務器、云服務或無服務器架構上。
AI視覺檢測系統涉及視頻記錄的存儲。數據存儲解決方案的選擇通常取決于深度學習模型功能。例如,如果視覺檢測系統使用大型數據集,則最佳選擇可能是云服務。
2)硬件
根據行業和自動化流程,集成視覺檢測系統所需的設備可能包括:
攝像頭。關鍵的攝像頭選項是實時視頻流。一些示例包括 IP Camera 和 CCTV。
網關。專用硬件設備和軟件程序都適用于視覺檢測系統。
CPU/GPU。如果需要實時結果,GPU 將是比 CPU 更好的選擇,因為前者在基于圖像的深度學習模型方面具有更快的處理速度。可以優化 CPU 來運行視覺檢查模型,但不能優化用于訓練。
光度計(可選)。根據視覺檢測系統環境的照明條件,可能需要使用光度計。
色度計(可選)。在檢測光源的顏色和亮度時,成像色度計始終具有高空間分辨率,可進行詳細的AI視覺檢測。
熱像儀(可選)。在蒸汽/水管道和設施的自動檢查的情況下,擁有熱像儀數據是個好主意。熱像儀數據為熱/蒸汽/水泄漏檢測提供了有價值的信息。熱像儀數據也可用于隔熱檢查。
無人機(可選)。如今,很難想象在沒有無人機的情況下對難以到達的區域進行自動檢查:建筑物內部結構、天然氣管道、油輪目視檢查、火箭/航天飛機檢查。無人機可能配備高分辨率相機,可以進行實時缺陷檢測。
深度學習模型在部署后可以改進。深度學習方法可以通過新數據的迭代收集和模型重新訓練來提高神經網絡的準確性。結果是一個“更智能”的視覺檢測模型,它通過增加操作期間的數據量來學習。
三、AI視覺檢測的應用示例
通用安防:
適用于社區、樓宇、企業園區等場所的安防管理場景,如:人員進出、車輛進出、周界防范、危險區域闖入、可疑徘徊等,提高場所的安全管理水平。
明廚亮灶:
基于多種算法(廚師帽/廚師服識別、抽煙識別、玩手機識別、垃圾桶未蓋檢測、動火離人檢測、陌生人檢測、貓/狗/老鼠識別等),可以有效監測餐飲行業后廚的食品安全、環境衛生、四害防治等是否有違規或異常情況出現,并能實時發出告警信息。
森林防火:
可對前端設備采集的圖像、視頻等數據進行實時風險監測與煙火識別分析,根據火災煙霧火焰特征,可準確識別出煙霧、火焰、火點,并立即觸發告警。 智慧安監:適用于企業安全生產監管場景,如:工地、煤礦、危化品、加油站、煙花爆竹、電力等行業,有助于降低生產過程中的安全隱患、保障生命財產安全。 智慧景區:適用于景區、公園等場景,可實時統計監控范圍內的人流量、預警人群擁擠事件、防止危險區域有人員闖入、識別煙火等,助力景區智能化監管。 智慧校園:可用于校園內部及周邊的安防監測場景,包括師生人臉門禁、車輛進出、周界防范、翻越圍墻、危險區域闖入、人員擁擠、異常聚集、煙火等。 區域安全監測:適用于重點場所的安全監測場景,如:政府機構、軍事區域、機場、變電站、工業重地、看守所、農場養殖等,監測周界入侵、人員闖入、徘徊等事件。
無人值守:可用于野外遠程監控場景,如:水利、電力等,防范可疑人員靠近、人員破壞/偷盜設備、闖入危險區域等,可聯動語音等裝置進行驅離提醒。 在崗離崗:可用于需要人員時刻在崗的監測場景中,能實時檢測固定工作崗位的人員在崗離崗情況,當檢測到離崗時,可立即觸發告警提醒。 加油站安全監管:用于加油站安全監管,對加油區、卸油區、儲油罐等區域進行重點監測,可對區域內的安全風險,如:抽煙、打電話、煙火、靜電釋放等進行告警提醒。 公共防疫:協助公共區域防疫工作的開展,實時監測區域內人員是否佩戴口罩,并可結合語音裝置發出提醒,可應用于樓宇、商場、車站、公交、出租車、地鐵、廣場、景區、工廠、園區等場景。
審核編輯:郭婷
-
計算機
+關注
關注
19文章
7807瀏覽量
93198 -
AI
+關注
關注
91文章
39793瀏覽量
301389 -
深度學習
+關注
關注
73文章
5599瀏覽量
124398
原文標題:基于深度學習算法的AI智能視覺檢測技術
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
友思特案例 | 金屬行業視覺檢測案例一:彩涂鋼板卷對卷檢測

【精選活動】缺陷系統檢測不走坑!10年+資深LabVIEW視覺專家全套珍藏

穿孔機頂頭檢測儀 機器視覺深度學習
【團購】獨家全套珍藏!龍哥LabVIEW視覺深度學習實戰課(11大系列課程,共5000+分鐘)
【團購】獨家全套珍藏!龍哥LabVIEW視覺深度學習實戰課程(11大系列課程,共5000+分鐘)
從0到1,10+年資深LabVIEW專家,手把手教你攻克機器視覺+深度學習(5000分鐘實戰課)
如何深度學習機器視覺的應用場景
友思特案例 | 醫療設備行業視覺檢測案例集錦(四)

機器視覺檢測PIN針
如何在機器視覺中部署深度學習神經網絡

地鐵隧道病害智能巡檢系統——機器視覺技術的深度應用

鋰電行業視覺檢測案例集錦(二)

當CAN握手EtherCAT:視覺檢測系統的“雙芯合璧”時代來了
【「# ROS 2智能機器人開發實踐」閱讀體驗】視覺實現的基礎算法的應用
行業首創:基于深度學習視覺平臺的AI驅動輪胎檢測自動化




 工商網監
工商網監
評論