 基于VLP模型的語義對齊機制
基于VLP模型的語義對齊機制

研究動機
對齊不同模態的語義是多模態預訓練(VLP)模型的一個重要能力。然而,VLP模型的內部對齊機制是不可知的。許多研究已經關注到這個問題,其中一個主流方法是通過精心設計的分類探針實驗來探究模型的對齊能力[1, 2]。但是我們認為簡單的分類任務不能準確地探究的這個問題:第一,這些分類任務仍然將VLP模型當作黑盒子,只能從分類任務的指標上分析模型在某一個方面的對齊效果;第二,很多分類任務只需要使用圖片-文本對中的部分信息就可以完成(例如一個區域,一個詞組或者兩者都使用)。

圖1:給出1張圖片與6個句子,測試不同的VLP模型會選擇哪個句子與圖片最匹配
為了進一步說明這一點,圖1展示了1張圖片和6個句子,其中句子(a)是對圖片的合理描述,(b)-(f)是不可讀的5個句子。令人驚訝的是,我們測試的5個預訓練模型都沒有選擇合理的描述(a),這促使我們去深入研究VLP模型會認為哪一種句子是更符合圖片的,即從文本視角探究多模態預訓練模型的語義對齊機制。
如果人工去生成圖1所示的不可讀的句子,然后再去測試VLP模型是否對其有偏好是非常困難的,本文則考慮利用自動化的方式生成VLP模型偏好的句子。具體而言,我們可以把VLP模型認為哪個句子更好(匹配分數越大)作為一種反饋,來訓練一個多模態生成模型,通過最大化匹配分數來生成為圖片生成描述。通過這種方式,生成模型會放大VLP模型對句子的偏好并反映到生成的句子中。所以我們提出一個新的探針實驗:使用圖像描述(captioning)模型,通過分析生成的句子來探究VLP模型的多模態的語義對齊機制。
02
貢獻
1.我們提出了一個新的探針實驗:使用圖像描述模型,通過分析生成描述來探究VLP模型的多模態的語義對齊機制。
2.我們在5個主流VLP模型上進行了探針實驗,通過captioning模型生成的句子,分析了每一個VLP模型的語義對齊能力。
3.通過5個VLP模型反映出的對齊問題,總結了目前VLP模型存在的3個缺陷并進行了驗證。
03
探針實驗與分析
我們選擇了5個主流的VLP模型,包括UNITER[3],ROSITA[4],ViLBERT[5],CLIP[6]以及LXMERT[7]。
我們使用COCO數據集作為我們探針實驗數據集,使用FC model[8]作為實驗的captioning模型。由于VLP的匹配分數不能直接反饋到圖像描述模型,所以我們使用SCST[8]的方法來優化。
經過VLP模型匹配分數的優化后,captioning模型生成的句子可以獲得很高的匹配分數(表1左邊所示),這說明VLP模型認為這些句子與圖片更匹配了。直覺上,這些句子應該更好地描述了圖像中的內容,但是我們使用圖像描述指標測試這些句子卻發現,它們的指標下降了非常多(表1右邊所示),這促使我們去檢查一下生成的句子發生了哪些變化。
表1:生成句子在圖像描述指標和VLP模型匹配分數上的測試結果。CE表示使用cross-entropy作為loss訓練的基礎模型。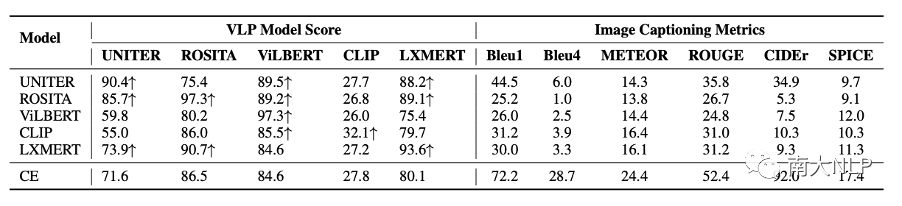
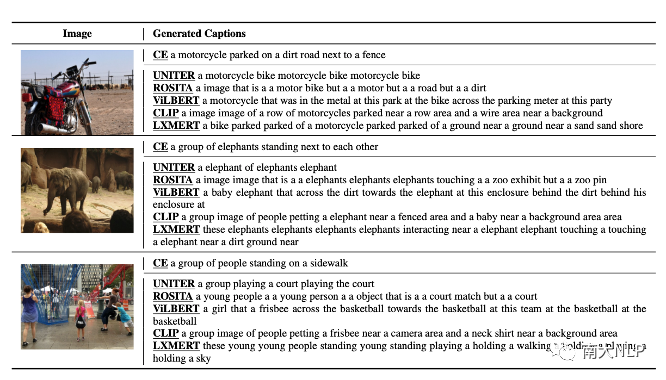 圖2經過不同VLP模型的匹配分數優化后生成的句子
圖2經過不同VLP模型的匹配分數優化后生成的句子
圖2展示了經過匹配分數優化后生成的的句子,我們可以發現幾乎所有的句子都已經變得不可讀。我們從困惑度(perplexity),句子長度,視覺詞的數量等角度對這些句子進行定量分析,發現這些句子已經與CE模型生成的句子有了非常大的變化(如表2所示)。不僅如此,我們還發現每一個VLP模型似乎都對某些固定的句式有偏好,如圖2中,被CLIP優化的captioning模型,生成的句子的前綴帶(prefix)經常含有與“a image of”相關的詞組。我們利用正則表達式,對這些句子的句式(pattern)進行進行總結(表3),可以發現每一個VLP模型都有自己偏好的句式。
表2生成句子的困惑度,長度,視覺詞數量的統計信息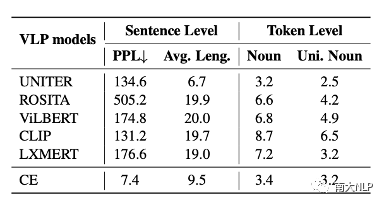
表3生成句子的句式統計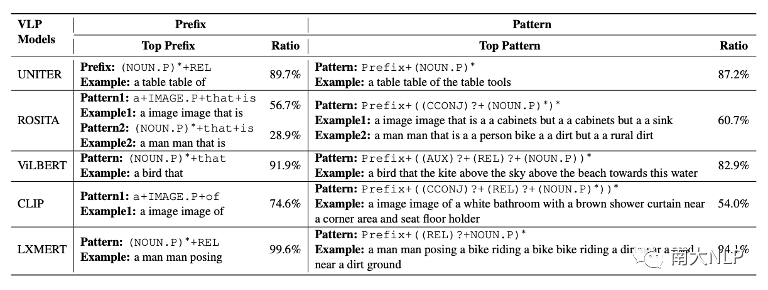
04
VLP模型的缺陷
通過上述對生成句子的定量分析,我們發現現在的預訓練模型主要存在3個缺陷。為了驗證這3個發現,我們使用了COCO測試集中的5000張圖片。
(a)VLP模型在判斷一個圖片-句子對是否匹配的時候過于依賴圖片中的區域特征和句子中的視覺詞,而忽視了全局的語義信息是否對齊。
我們對CE生成的句子進行兩種處理:替換視覺詞(Replacing visual words)和替換非視覺詞(Replacing other words)。從圖3中我們可以發現替換視覺詞會使得VLP模型的匹配分數大幅下降,但是替換非視覺詞只會讓匹配分數下降一點。需要注意的是,替換了非視覺詞后的句子是不可讀的,但是模型還是會認為這些不可讀句子與圖片是匹配的。
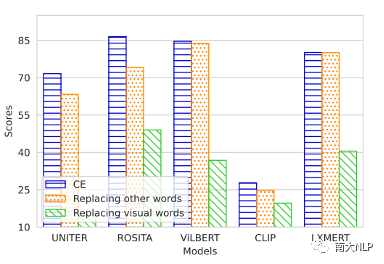
圖3替換視覺詞與替換非視覺詞的匹配分數與原始分數的對比
(b)VLP模型會對偏好某些固定的句式,因此忽視了更重要的文本信息,如流暢度,語法等。
我們利用表3發現的句式,提取出CE句子的視覺詞,把視覺詞填補到這些句式中。我們僅僅是改變了句子的結構,就可以使得這些句子的匹配分數大幅提高(表4所示)。
表4重構后句子的匹配分數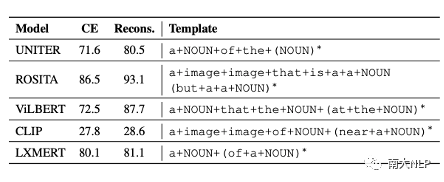
(c)VLP模型認為包含更多視覺詞的句子更匹配圖片,這會弱化圖片中關鍵物體的作用。
我們把每張圖片的ground-truth中的視覺詞先提取出來,然后每次填充k (k=3,4,5,6,7)個到句式模版中。從圖4中可以看出,隨著視覺詞的增加,重構句子的匹配分數越來越高。
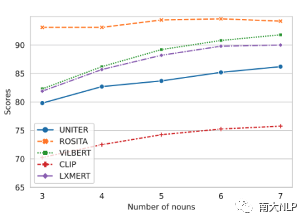
圖4含有k個視覺詞句子的匹配分數
05
總結
在本文中,我們利用圖像描述模型提出一個新穎的探針方法。通過這個方法,我們從文本角度分析了VLP模型的語義對齊機制。我們發現現有的VLP模型在對齊方面有明顯的缺陷。我們希望這些發現可以促進研究者設計更合理的模型結構或預訓練任務。同時,研究者也可以使用我們的探針方法,分析其設計的VLP模型是否存在缺陷。
-
模型
+關注
關注
1文章
3751瀏覽量
52099 -
數據集
+關注
關注
4文章
1236瀏覽量
26189
原文標題:EMNLP'22 Findings | 南大提出:從文本視角探究多模態預訓練模型的語義對齊能力
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
【大語言模型:原理與工程實踐】大語言模型的基礎技術
基于OWL屬性特征的語義檢索研究
語義對等網覆蓋路由模型的研究
基于CAN協議P2P網絡的語義web服務模型
基于語義Web服務的智能電信業務模型
基于四層樹狀語義模型的場景語義識別方法
基于語義網技術的SLA協商機制
基于語音、字形和語義的層次注意力神經網絡模型

意圖和語義槽填充聯合識別模型設計方案





 工商網監
工商網監
評論