") 一個(gè)全新的無監(jiān)督不需要明確物體種類的實(shí)例分割算法
一個(gè)全新的無監(jiān)督不需要明確物體種類的實(shí)例分割算法

摘要
對于自動(dòng)駕駛來說,精細(xì)化的場景理解至關(guān)重要。由于在行駛的過程中,場景周圍信息會(huì)發(fā)生劇烈的變化,因此很難識別和理解出場景中的不同對象。盡管有很多工作者在語義/全景分割上推動(dòng)了場景理解的發(fā)展,但目前來說,仍然是一個(gè)挑戰(zhàn)任務(wù)。目前的方法大多依賴于標(biāo)注數(shù)據(jù),對于訓(xùn)練數(shù)據(jù)中缺少的類別,我們將其稱為拖尾(長尾)類。
然而,拖尾(長尾)類對于自動(dòng)駕駛來說缺失至關(guān)重要,如嬰兒車和未知?jiǎng)游铮紩?huì)對自動(dòng)駕駛的安全性能造成巨大的挑戰(zhàn)。在本篇文章中,我們將集中對這種類無關(guān)的實(shí)例分割問題進(jìn)行研究,進(jìn)一步解決這種拖尾(長尾)類問題。我們提出一個(gè)全新的算法和驗(yàn)證算法用的數(shù)據(jù)集,并且在真實(shí)場景數(shù)據(jù)中驗(yàn)證我們算法效果。
算法通過一個(gè)已經(jīng)訓(xùn)練好的自監(jiān)督神經(jīng)網(wǎng)絡(luò)抽取出點(diǎn)特征,構(gòu)建出點(diǎn)云表示對應(yīng)的圖表征。然后,我們用圖割算法來將前后背景分離出來。結(jié)果證明了我們的算法可以實(shí)現(xiàn)實(shí)例分割,并且相比于其他自監(jiān)督算法,我們方法具有不錯(cuò)的競爭力。
主要貢獻(xiàn)
在這篇論文中,我們關(guān)注的問題是基于激光點(diǎn)云的實(shí)例分割,更確切的來說,我們關(guān)注的是不需要明確類別的激光點(diǎn)云實(shí)例分割算法。相比于需要把城鎮(zhèn)街道上所有可能出現(xiàn)的物體打上標(biāo)簽,我們更關(guān)注的是如何擺脫區(qū)分物體的類別屬性而直接將其打上標(biāo)簽。因此,我們的問題被簡化為如何能區(qū)分出點(diǎn)云中的單個(gè)物體,并且將它們分割出來。
這個(gè)問題的最大難度是對未知物體的分割,因?yàn)楸旧聿⒉淮嬖谟跇?biāo)記數(shù)據(jù)中,但在推理過程中,該部分?jǐn)?shù)據(jù)又特別重要。
這個(gè)問題也可以被解讀于:我們?nèi)绾瓮ㄟ^對現(xiàn)實(shí)世界中的部分信息來進(jìn)行訓(xùn)練學(xué)習(xí),實(shí)現(xiàn)對激光點(diǎn)云中的實(shí)例物體進(jìn)行推理。目前先進(jìn)的方法也有通過語義分割的訓(xùn)練預(yù)測器來解決這個(gè)問題,這些方法通過不同的啟發(fā)式方法和優(yōu)化過程來對點(diǎn)進(jìn)行聚類,這些方法依然需要標(biāo)注數(shù)據(jù)。
這篇文章的主要貢獻(xiàn)是提出了一個(gè)全新的無監(jiān)督不需要明確物體種類的實(shí)例分割算法。鑒于目前表示學(xué)習(xí)的發(fā)展,我們可以使用自監(jiān)督的方法來抽取出點(diǎn)對特征,并且通過鄰接圖的方式來表示相鄰點(diǎn)對之間的相似性。然后,我們在不需要任何標(biāo)注的情況下,通過圖割的算法來從背景信息中抽取出實(shí)例物體。
我們將Semantic KITTI benchmark進(jìn)行了擴(kuò)展,分別在已經(jīng)物體類別和未知物體類別下評估了我們的算法。實(shí)驗(yàn)結(jié)果證明了相比于State-Of-Art算法,我們的算法可以在沒有標(biāo)簽,沒有語義背景去除的情況下進(jìn)行實(shí)例分割,并有較好的算法性能。
算法流程
 ?
? 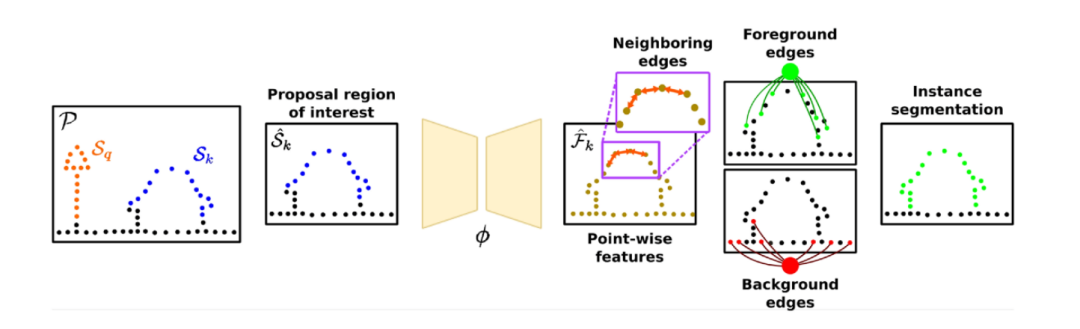
圖2:算法整體流程圖
算法整體流程可以用上圖來表示。我們通過Graph-Cut和自監(jiān)督學(xué)習(xí)特征的方法來講場景中的實(shí)例區(qū)分開。我們將點(diǎn)云整體表示成圖,通過自監(jiān)督網(wǎng)絡(luò)計(jì)算出點(diǎn)顯著性分布圖,來對前景圖和后景圖進(jìn)行采樣,實(shí)現(xiàn)實(shí)例分割。因?yàn)辄c(diǎn)云中可能存在多個(gè)物體實(shí)例,這也給前后背景分離增加了難度。
因此,我們改變策略,先對點(diǎn)云中的地面進(jìn)行分割,區(qū)分出地面點(diǎn)和非地面點(diǎn),并對非地面點(diǎn)進(jìn)行聚類。然后我們迭代地遍歷每個(gè)地方,并對每個(gè)興趣點(diǎn)附近規(guī)劃出一個(gè)立方體區(qū)域。對于這個(gè)區(qū)域,我們將立方體中的實(shí)例作為前景對象,地面點(diǎn)和其他實(shí)例點(diǎn)作為背景區(qū)域。然后我們可以通過該區(qū)域來構(gòu)建圖,并依據(jù)圖分割成前景和背景。
A. 實(shí)例提案
為了更好地分割出實(shí)例,我們的算法依賴于初始猜測(也被稱為提案),隨后可以被精細(xì)化為更好地分割。為了和之前的工作(SegContrast)的符號保持統(tǒng)一,我們定義實(shí)例如下:對于一組N個(gè)點(diǎn)的點(diǎn)云P={p1,p2,...,pN},我們通過地面分割的算法將它分為地面點(diǎn)G和非地面點(diǎn)P′,然后通過HDBSCAN聚類算法來將非地面點(diǎn)聚類成m個(gè)類,被定義成m個(gè)類的過程我們則稱為提案。其中I={S1,...Sm},這里Sk∈P′并且對于不屬于同類來說,Sk∩Sl=?,l≠k。
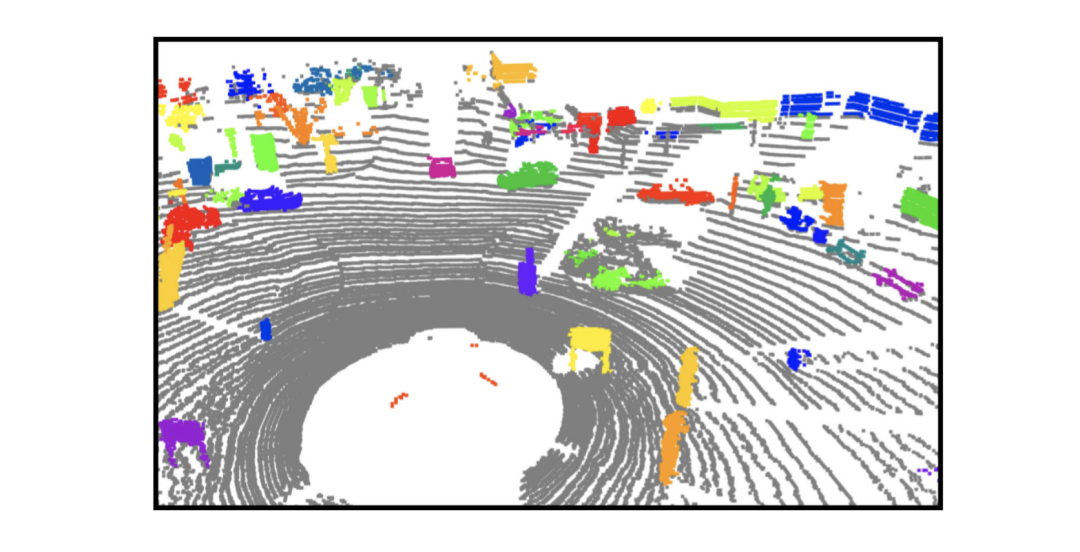
圖3:點(diǎn)云中實(shí)例分割提案
如圖3所示,這些分割是實(shí)例表示的起點(diǎn),并不是實(shí)例表示的最后結(jié)果。我們的算法之后將其映射到特征圖中來計(jì)算相同提案中不同點(diǎn)之間的相似性。之后,我們將從這個(gè)背景圖中分割出這些物體來做為實(shí)例分割。
B.自監(jiān)督特征
我們的方法充分運(yùn)用了自監(jiān)督表征學(xué)習(xí)來抽取出點(diǎn)對特征。我們使用MinkUNet來作為特征抽取模型。該方法是一種自監(jiān)督方法,依賴于對場景中的地面點(diǎn)進(jìn)行去除,并對剩余點(diǎn)進(jìn)行聚類。它的對比損失函數(shù)逐段運(yùn)用,通過判別的方式學(xué)習(xí)出特征空間。
對于每一個(gè)學(xué)習(xí)出的提案Sk∈I,我們定義興趣區(qū)域S^∈P,然后用SegContrast預(yù)訓(xùn)練模型抽取出點(diǎn)對特征F^k,之后我們通過這些特征來計(jì)算出點(diǎn)對相似性,而不是直接計(jì)算出其測量的特征。到此,我們有描述性特征可以用來識別實(shí)例段和背景之間的差異。
C. Saliency Maps.
Saliency Map通常是分析網(wǎng)絡(luò)學(xué)習(xí)到的特征空間。為了計(jì)算顯著性地圖,我們通常計(jì)算它的梯度并可視化對它影響更大的區(qū)域。這些年也有人通過transformer來提取和制作對應(yīng)的可視化,即使在沒有標(biāo)簽的情況下也可以很好的計(jì)算出對應(yīng)的對象邊界。盡管在SegContrast中使用的是稀疏卷積神經(jīng)網(wǎng)絡(luò),我們觀察到它也可以在顯著性圖中找到實(shí)例注意力的地方。這種顯著性的值可以更好地解釋為哪里是前景,哪里是背景,是后面用于GraphCut的隨機(jī)初始種子。
對于前面的實(shí)例提案,我們計(jì)算出每個(gè)特征向量中的均值δ。
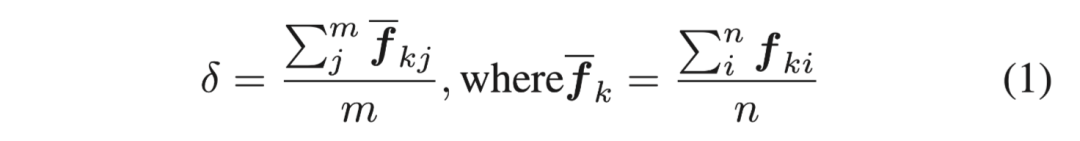
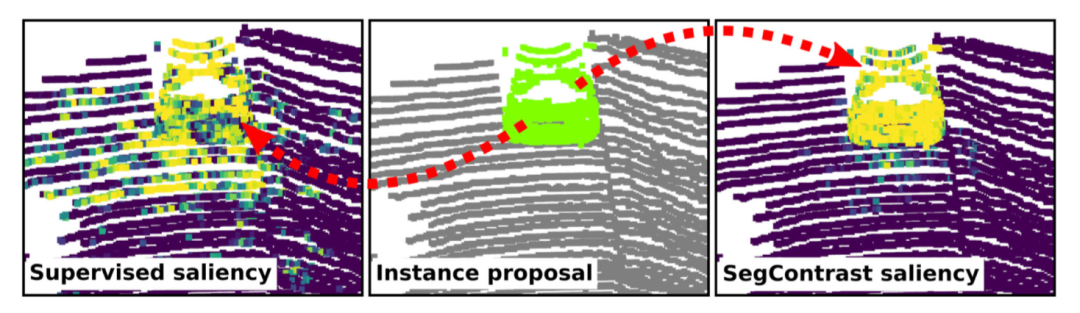
圖4. 受監(jiān)督的語義分割網(wǎng)絡(luò)與用SegContrast進(jìn)行自我監(jiān)督的網(wǎng)絡(luò),兩個(gè)網(wǎng)絡(luò)得到的顯著性圖(saliency map,左圖與右圖)與該算法得到的proposal實(shí)例點(diǎn)特征圖(中間)進(jìn)行對比。該圖用不同顏色區(qū)分不同物體,因此最好查看原本彩圖
通過計(jì)算δ的梯度變化,我們得到每個(gè)提案附近的顯著性圖。如上圖所示,通過該方法得到的顯著性地圖可以更精細(xì)地區(qū)分出場景中的實(shí)例對象。
D. Seeds Sampling.
我們采用實(shí)例提案Sk和他們對應(yīng)的顯著性值來做前景和背景信息的采樣。由于實(shí)例信息中對應(yīng)的是不同的物體,所以固定數(shù)量的采樣方式并不一定合適。因此,我們依據(jù)提案Sk和他們對應(yīng)的興趣區(qū)域大小來定義具體的采樣點(diǎn)數(shù)量。這里我們選取τ_f=nf/γf作為前景種子,選取τ_b=nb/γb作為背景種子,這里γf和γb都是預(yù)先定義的參數(shù)。
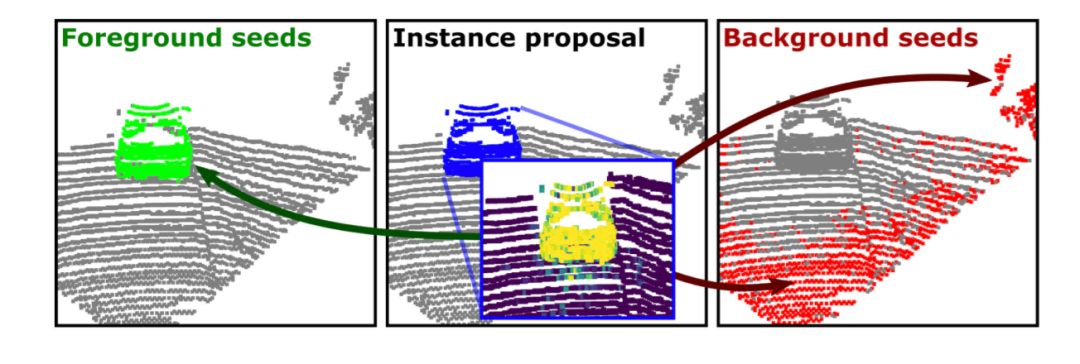
圖5.我們基于藍(lán)色點(diǎn)的提議下,將前景點(diǎn)和背景點(diǎn)計(jì)算出來,分辨用綠色和紅色來表示.
上圖是種子信息選取的過程。我們對每個(gè)前景種子周圍的k個(gè)鄰居點(diǎn)進(jìn)行采樣,來計(jì)算前景信息的相似性。同時(shí)我們在提案之內(nèi)刪除任何背景種子,在提案之外刪除任何前景種子來避免顯著性圖中產(chǎn)生異常值。通過這樣的方式,我們可以避免錯(cuò)誤的種子采樣從而影響到圖割算法的性能。
E.圖割算法
為了更好地從點(diǎn)云中分割出實(shí)例對象,我們采用圖割算法,一種用于圖像分割的經(jīng)典算法,現(xiàn)在用在點(diǎn)云數(shù)據(jù)上。這種方法主要通過一種圖的表示來描述各個(gè)節(jié)點(diǎn)中和他們鄰節(jié)點(diǎn)之間的關(guān)系,從而找出前景和背景數(shù)據(jù)。然后,我們再對圖用最小切歌方法,切除當(dāng)中最弱的關(guān)系數(shù)據(jù)。我們采用SegContrast算法來計(jì)算每個(gè)點(diǎn)上的特征,然后計(jì)算相鄰點(diǎn)之間的相似性作為非終端邊緣。最后我們計(jì)算顯著性圖以對種子進(jìn)行采樣并確定點(diǎn)和終端節(jié)點(diǎn)之間的邊。
在我們的定義下,一個(gè)圖包含一系列的節(jié)點(diǎn)Z={z1,...,zn+2},其中每個(gè)節(jié)點(diǎn)表示的一個(gè)點(diǎn)信息在提出的區(qū)域Sk中,對應(yīng)著n個(gè)點(diǎn)和2個(gè)虛擬的節(jié)點(diǎn),分別代表著前景信息和背景信息。
(1)終端邊緣
每一個(gè)點(diǎn)都有兩個(gè)虛擬的邊緣節(jié)點(diǎn),我們根據(jù)這些節(jié)點(diǎn)的歸類方式對這些變進(jìn)行加權(quán)。每一個(gè)邊緣的初始概率我們設(shè)置成0,然后選擇的節(jié)點(diǎn)和對應(yīng)的終端邊緣節(jié)點(diǎn)我們設(shè)置為1.0。最后,節(jié)點(diǎn)i和一個(gè)終端節(jié)點(diǎn)t的權(quán)重可以定義為:
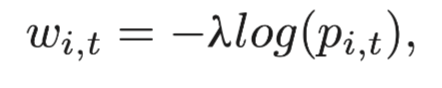
其中λ是預(yù)先定義的參數(shù),pi,t的定義表示節(jié)點(diǎn)i屬于終端節(jié)點(diǎn)t的概率值的大小。
(2)非終端邊緣
對于非終端節(jié)點(diǎn),我們通過坐標(biāo)選取每個(gè)點(diǎn)和它周圍的k歌鄰居點(diǎn)來確定變。為了對邊進(jìn)行加權(quán),我們計(jì)算每個(gè)點(diǎn)的特征并計(jì)算它與相鄰點(diǎn)之間的差異。我們使用L1范數(shù)來定義fi和fj之間的特征區(qū)別。
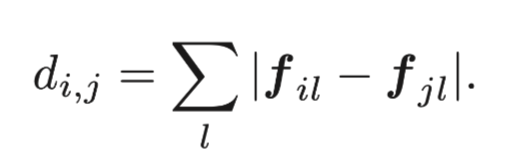
兩點(diǎn)之間的權(quán)重也是依據(jù)給定出的dij計(jì)算出來:
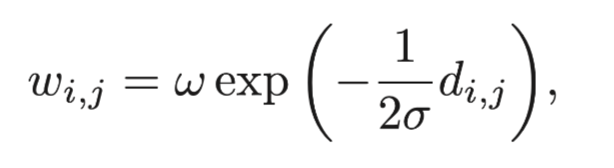
其中σ和w都是預(yù)先定義的參數(shù)。按照以上的定義,我們可以將點(diǎn)和邊構(gòu)建清楚,然后通過最小圖割算法來將實(shí)例從背景信息中分割出來。我們迭代地重復(fù)以上過程,最后將物體從背景信息中分割出來。
實(shí)驗(yàn)分析
在這一節(jié)中,我們主要介紹我們基于SemanticKITTI的擴(kuò)展。
A. 問題定義
現(xiàn)有的實(shí)例分割模型假設(shè)在推理過程中出現(xiàn)的所有對象類都被手動(dòng)標(biāo)記并在訓(xùn)練時(shí)出現(xiàn)。我們將這些對象類稱為已知類。在本文中,我們還想關(guān)注那些可能只在推理過程中出現(xiàn)的對象實(shí)例分割,我們把它們表示為未知類。
更正式地說,所有對象類的集合X有可能很大,并且許多實(shí)例會(huì)很少出現(xiàn)。在實(shí)踐中,我們無法記錄、標(biāo)記和評估在所有可能的對象類別上的算法性能,因?yàn)檫@些會(huì)出現(xiàn)在對象類別分布中的拖尾類。因此,實(shí)際上只有對這些類別的固定子集進(jìn)行標(biāo)記才是可行的。
為此,我們進(jìn)行了如下劃分。我們將SemanticKITTI提供的標(biāo)簽用于整個(gè)數(shù)據(jù)集(訓(xùn)練集、驗(yàn)證集和測試集)的已知類集。這個(gè)集合包含經(jīng)常出現(xiàn)的物體類別,如汽車、人、卡車和類似的物體。我們只在驗(yàn)證集和測試集中標(biāo)注一個(gè)額外的、不相交的對象實(shí)例集,即未知的對象實(shí)例U?X, 且U∩K=?。
因此,我們的測試集提供了一個(gè)“代理”,用于評估算法在只在很少情況下出現(xiàn)的未知物體上的性能。我們注意到,這些實(shí)例的例子可能出現(xiàn)在訓(xùn)練集和驗(yàn)證集中,但沒有被標(biāo)記為實(shí)例。
由于我們解決了實(shí)例分割的問題,我們只標(biāo)記了事物(thing)類:在文獻(xiàn)[21]中,東西(stuff)類被認(rèn)為是不可計(jì)數(shù)的類,例如,植被或道路。而事物類,如汽車和行人,通常有明確的邊界,在單個(gè)掃描中是可見的,并且是可計(jì)算的。
B. 評價(jià)
對于開放世界的實(shí)例分割,我們評估了 算法能將LiDAR點(diǎn)云分解為單獨(dú)一組物體實(shí)例的能力。為了量化性能,一種可能性是采用基于召回(recall)的變體:泛光質(zhì)量(Panoptic Quality, PQ)的,未知質(zhì)量(Unknown Quality, UQ),他們基于召回(recall)用的方法代替了識別質(zhì)量(recognition quality,RQ)項(xiàng)(F1-Score)。
然而,這種度量將點(diǎn)云的東西(stuff)區(qū)域作為一個(gè)單一的實(shí)例,這并不可取[29]。例如,植被類可以被分解成幾個(gè)實(shí)例(樹干、小灌木)--這些沒有被手工注釋者標(biāo)記,但可以依據(jù)任務(wù)的不同,被認(rèn)為是有效的實(shí)例,例如, segment-based LiDAR odometry或SLAM[16]。
我們轉(zhuǎn)而采用LiDAR分段和跟蹤質(zhì)量( LiDAR Segmentation and Tracking Quality,LSTQ)指標(biāo)。它由兩個(gè)術(shù)語組成,一個(gè)分類Scls和一個(gè)分割Sassoc。然而,由于我們?nèi)蝿?wù)與類別無關(guān),我們刪除了Scls,只依靠Sassoc來評估實(shí)例段的質(zhì)量如何。
關(guān)聯(lián)項(xiàng)Sassoc衡量我們將點(diǎn)分配給它們的實(shí)例的程度,與語義無關(guān):
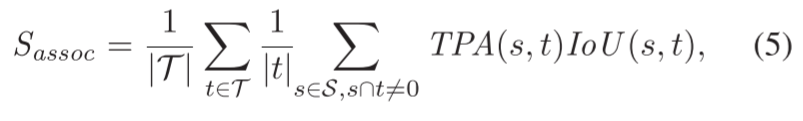
其中,IoU輸入是真值物體t∈T和預(yù)測s∈S對、這個(gè)對通過真陽性關(guān)聯(lián)(TPA)、假陰性關(guān)聯(lián)(FNA)和假陽性關(guān)聯(lián)(FPA)的集合來計(jì)算的。這些集合是以class-agnostic的方式評估的,但與Aygün等人[1]的工作不同,因?yàn)檫@些集合由每個(gè)掃描都進(jìn)行計(jì)算得來而不是按整個(gè)序列計(jì)算的。
直觀地說,TPA集量化了有多少個(gè)點(diǎn)被正確地分配給它們相應(yīng)的實(shí)例,TPA和FPA集表面兩種不同類型的“點(diǎn)到實(shí)例”關(guān)聯(lián)錯(cuò)誤。更確切地說,TPA集包含所有相互重疊的點(diǎn)。FPA集表示s中所有與t不重疊的點(diǎn),最后,F(xiàn)NA代表屬于t中但不包含在s中的點(diǎn)(Aygün等)。
關(guān)聯(lián)項(xiàng)是class-agnostic的,并且只表征將點(diǎn)分配給標(biāo)記的物體實(shí)例的表現(xiàn)如何。這使我們能夠評估區(qū)別于語義的實(shí)例分割,使這個(gè)指標(biāo)獨(dú)特地適用于開放世界LiDAR實(shí)例分割的評估。
C. 開放世界的SemanticKITTI數(shù)據(jù)集和基準(zhǔn)
為了合理評價(jià)將出現(xiàn)在對象分布中拖尾類物體分割出來的算法,其對應(yīng)數(shù)據(jù)集應(yīng)該為最常見的物體(如交通參與者)提供實(shí)例標(biāo)簽,并為東西(stuff)類提供語義標(biāo)簽。SemanticKITTI[3]或nuScenes-lidarseg[7]提供了這樣的標(biāo)簽,與之相反的是對象檢測數(shù)據(jù)集,只提供三維邊界框。
我們選擇了SemanticKITTI數(shù)據(jù)集,該數(shù)據(jù)集擴(kuò)展了KITTI數(shù)據(jù)集,對每個(gè)LiDAR掃描都進(jìn)行了密集的逐點(diǎn)語義和實(shí)例標(biāo)簽。它包含訓(xùn)練中的23,000個(gè)標(biāo)記掃描和測試集中的20,000個(gè)標(biāo)記掃描,為6,315個(gè)屬于幾個(gè)已知物體類別的物體實(shí)例,總共418,649個(gè)邊界框,提供語義和物體實(shí)例標(biāo)簽。
我們建立了開放世界的SemanticKITTI基準(zhǔn),該基準(zhǔn)適合于評估開放世界環(huán)境中的算法性能。我們用3,587個(gè)實(shí)例擴(kuò)展了SemanticKITTI的隱藏測試集,總共有292,871個(gè)額外的對象實(shí)例標(biāo)簽,這些對象類別不一定屬于原來的對象類別中語義類別--未知對象。
參見Tab. I以了解關(guān)于類別分布的統(tǒng)計(jì)數(shù)據(jù)。我們還在驗(yàn)證集中為未知類的實(shí)例貼上標(biāo)簽,但是只提供了一種用服務(wù)端(server-side)評估的方式來評估性能,以便在訓(xùn)練時(shí)保持實(shí)例的未知。

V. 試驗(yàn)評估
我們工作的主要重點(diǎn)是一個(gè)與類別無關(guān)的實(shí)例分割。與以前的方法不同,我們的工作不需要實(shí)例或語義標(biāo)簽來去除背景。我們展示了我們的實(shí)驗(yàn),以顯示我們的方法它能夠在不去除語義背景的情況下分割實(shí)例的能力,并且與最先進(jìn)的監(jiān)督方法相比,性能不弱下風(fēng)。
在我們所有的實(shí)驗(yàn)中,我們使用相同的參數(shù),這些參數(shù)根據(jù)經(jīng)驗(yàn)來定義。對于實(shí)例,我們使用預(yù)先定義的大小為實(shí)例周圍1米的余量來定義感興趣的區(qū)域。對于種子采樣,我們使用γf=2, γb=2。對于GraphCut,我們使用σ=1,ω=10和λ=0.1,我們選擇k=8個(gè)最近的鄰居來定義非終端的邊緣,并建立圖形。對于自我監(jiān)督的預(yù)訓(xùn)練模型,我們使用SegContrast[28]中描述的相同預(yù)訓(xùn)練。訓(xùn)練了200個(gè)epochs。
我們在兩種設(shè)置中比較了我們的方法:只使用來自GraphCut的分割,命名為Ours;以及使用后處理步驟,即從用于生成proposals的地面分割中過濾點(diǎn),命名為Ors?。我們將我們的結(jié)果與不同的無監(jiān)督聚類方法和基于監(jiān)督學(xué)習(xí)的方法進(jìn)行比較。
對于聚類方法,我們使用與我們的方法相同的實(shí)例proposals過程,即去除地面,然后對剩余的點(diǎn)進(jìn)行聚類。我們評估了HDBSCAN[8]和Euclidean聚類[30]。此外,我們還比較了一種在點(diǎn)云的鳥瞰圖上操作的技術(shù)、帶有快速移動(dòng)算法的聚類以及一種基于快速范圍圖像的建議生成方法。
此外,我們評估了兩種基于監(jiān)督學(xué)習(xí)的方法:Hu等人提出的方法[20]用語義分割網(wǎng)絡(luò)去除背景,并給定一個(gè)學(xué)習(xí)的對象性值對剩余的點(diǎn)進(jìn)行聚類,還有一種完全數(shù)據(jù)驅(qū)動(dòng)的方法4D-PLS[1]用于封閉世界的實(shí)例分割。
A. 關(guān)聯(lián)質(zhì)量
這個(gè)實(shí)驗(yàn)評估了測試集上的預(yù)測實(shí)例和基礎(chǔ)真值實(shí)例之間的關(guān)聯(lián)。結(jié)果表明,我們的方法,即使不使用標(biāo)簽,也達(dá)到了非常先進(jìn)的性能。
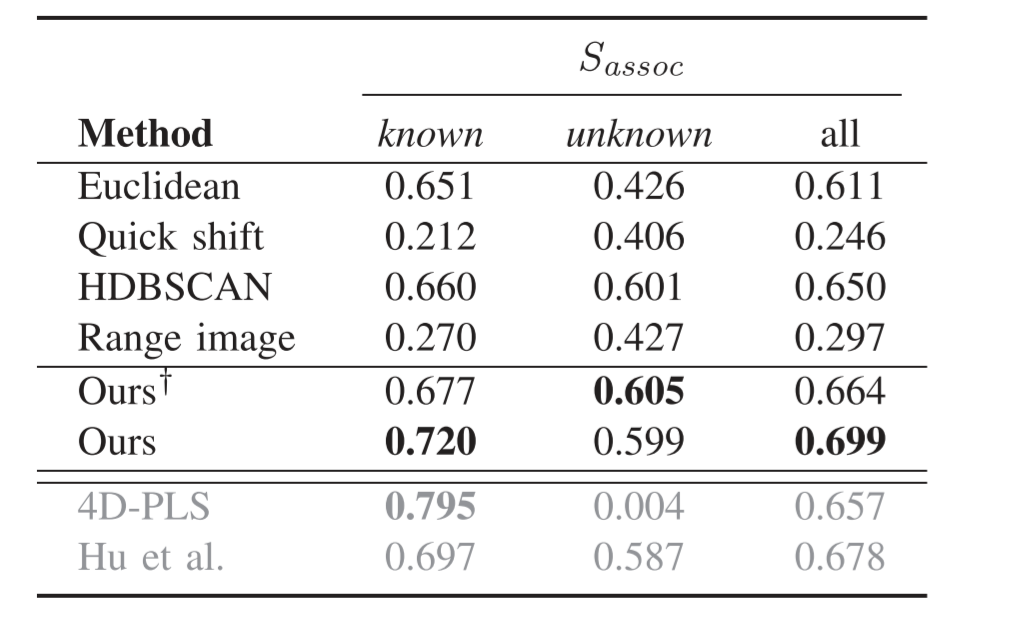
表二顯示了用度量對不同方法,在已知和未知實(shí)例以及class-agnostic的情況(即已知和未知)三種情況下的性能評估。通過比較不同的聚類方法,我們發(fā)現(xiàn),HDBSCAN呈現(xiàn)出最好的性能,這也側(cè)面說明了我們選擇使用它來進(jìn)行實(shí)例proposal的理由。
4D-PLS方法在已知實(shí)例方面取得了最好的性能,而我們的方法在無監(jiān)督的情況下具有最好的性能。我們的方法在很大程度上改善了HDBSCAN的實(shí)例建議,甚至超過了Hu的方法。對于未知實(shí)例,有監(jiān)督的方法的性能下降。我們的方法在去除地面點(diǎn)后,對未知實(shí)例取得了最好的性能。
當(dāng)看class-agnostic的情況時(shí),我們的方法在去除地面的情況下比無監(jiān)督方法好,不去除地面也比有監(jiān)督方法好。
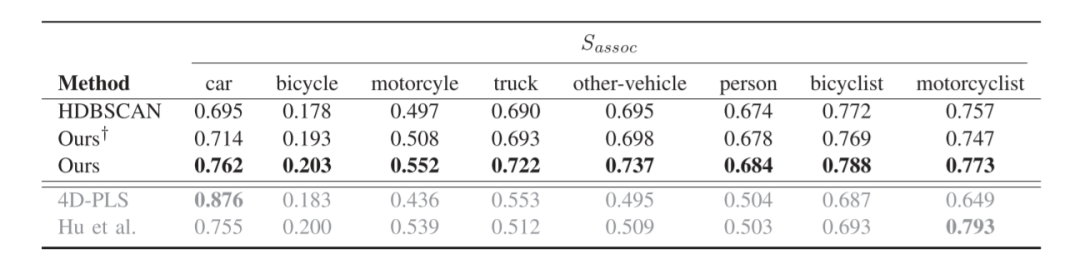
表三顯示了每個(gè)已知類別的Sassoc。監(jiān)督方法的性能在最有代表性的類別,即汽車上呈現(xiàn)出最佳性能。對于其他類別,它們的性能會(huì)下降,因?yàn)檫@些類別在訓(xùn)練集中的樣本較少。我們的方法在大多數(shù)類別上超過了HDBSCAN實(shí)例proposal和監(jiān)督方法。通過使用無監(jiān)督學(xué)習(xí)的特征,我們的方法對經(jīng)常出現(xiàn)的類的過擬合程度較低,更適合于對class-agnostic的實(shí)例分割。
B. 實(shí)例分割質(zhì)量
本實(shí)驗(yàn)評估了預(yù)測實(shí)例和地面實(shí)況之間的交叉聯(lián)合(intersection-over-union, IoU)和召回率。我們通過不同的IoU閾值來計(jì)算IoU和召回率,并計(jì)算不同閾值的平均值來評估方法的整體性能。
表四顯示了不同閾值的IoU和召回率的結(jié)果。在高閾值下,即IoU90,有監(jiān)督的方法比其他方法表現(xiàn)更好。由于4D-PLS是一種全景分割方法,其在所有的閾值上對已知實(shí)例取得了最好的性能。然而,它在分割未知實(shí)例時(shí)失敗了。隨著閾值的降低,我們的方法性能越來越接近監(jiān)督方法,并在未知實(shí)例中超過了它們。在整體評估中,我們的方法與監(jiān)督方法不相上下,并且在召回率方面表現(xiàn)最好。
C. 限制條件
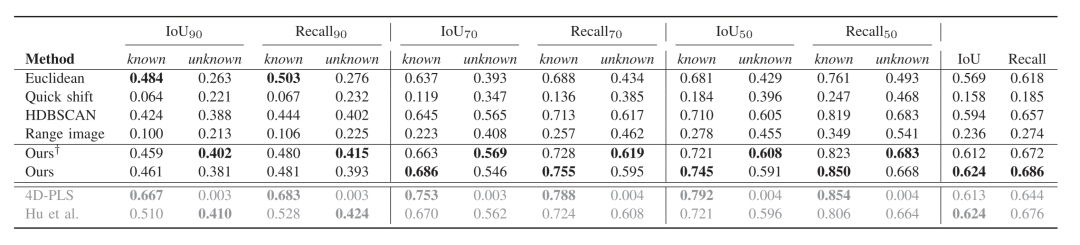
此外,我們還比較了我們的方法在有和沒有去除地面后處理的情況下,討論了其局限性。從上一節(jié)中可以看出,在沒有去除地面后處理的情況下,我們的方法取得了最好的整體性能,特別是對已知實(shí)例。然而,在去除地面的情況下,它在未知實(shí)例上的表現(xiàn)更好。
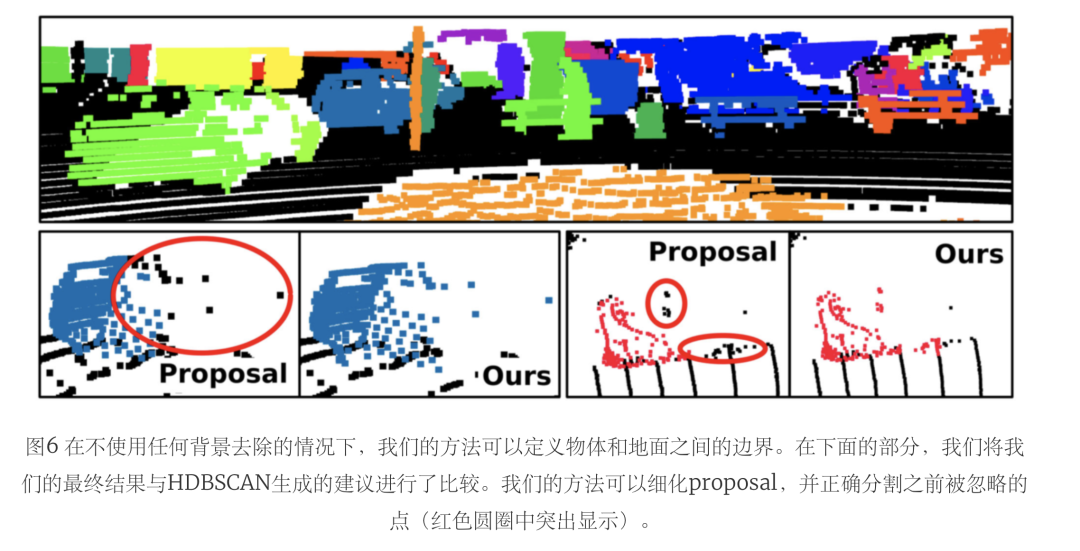
表五將這兩種設(shè)置與HDBSCAN proposal進(jìn)行了比較。盡管去除地面點(diǎn)會(huì)導(dǎo)致對未知實(shí)例的更好分割,但它對已知實(shí)例的影響更大,使性能下降了很多。在圖7中,我們舉了一個(gè)例子來解釋這種行為。由于地面分割是由一個(gè)無監(jiān)督的方法完成的,它可能會(huì)有點(diǎn)被錯(cuò)誤分配為地面和非地面。
因此,我們的方法可以通過正確分配以前被錯(cuò)誤地認(rèn)為是地面的實(shí)例點(diǎn)來改善分割。然而,由于地面分割的不完善,一些proposal可能會(huì)將地面視為實(shí)例點(diǎn)。在這種情況下,我們的方法可能會(huì)將地面點(diǎn)作為前景種子進(jìn)行采樣,導(dǎo)致會(huì)將更廣泛的地面區(qū)域分割做為實(shí)例的一部分。
通過后處理去除地面,我們過濾了被采樣為前景的地面區(qū)域,同時(shí)也過濾了被正確分配為實(shí)例的點(diǎn),這些點(diǎn)之前被錯(cuò)誤地標(biāo)記為地面。因此,我們的方法的主要局限性依賴于用于采樣前景和背景種子的初始proposal。

結(jié)論
在本文中,我們提出了一種新的無監(jiān)督的、class-agnostic的實(shí)例分割方法。我們的方法使用無監(jiān)督聚類來定義實(shí)例proposal,并使用圖形優(yōu)化算法來完善這些建議,以便更恰當(dāng)?shù)剡M(jìn)行實(shí)例分割。我們的方法將點(diǎn)云表示為一個(gè)圖,并利用自我監(jiān)督的表示學(xué)習(xí)法來提取點(diǎn)的特征,從而映射圖中的點(diǎn)鄰域相似性。
這使我們能夠從背景點(diǎn)中分離出前景實(shí)例,而不需要標(biāo)簽。此外,我們還提出了一個(gè)新的開放世界數(shù)據(jù)集,以評估已知和未知實(shí)例類的class-agnostic實(shí)例分割,并提出了該基準(zhǔn)的評估程序。實(shí)驗(yàn)表明,我們的方法更適合于class-agnostic的實(shí)例分割,因?yàn)樗〉昧伺c最先進(jìn)的監(jiān)督方法相競爭的性能,甚至在未知類中超過了它。我們希望我們的工作能激勵(lì)對自監(jiān)督實(shí)例分割的進(jìn)一步研究,并且希望我們的基準(zhǔn)對研究界能有所貢獻(xiàn)。
審核編輯:劉清
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4838瀏覽量
107752 -
圖像分割
+關(guān)注
關(guān)注
4文章
182瀏覽量
18775 -
LIDAR
+關(guān)注
關(guān)注
11文章
367瀏覽量
31454
原文標(biāo)題:3DUIS-基于激光點(diǎn)云的無監(jiān)督類無關(guān)實(shí)例分割算法
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
算法工程師需要具備哪些技能?
C語言增量式PID的通用算法
系統(tǒng)c盤滿了怎么清理不需要文件
有一個(gè)轉(zhuǎn)向燈是12V電池供電的產(chǎn)品,那ESD測試工作模式不需要包含24V吧?
光纖線需不需要套管
EL非監(jiān)督分割白皮書丨5張OK圖、1分鐘建模、半小時(shí)落地的異常檢測工具!

深控技術(shù)“不需要點(diǎn)表”工業(yè)網(wǎng)關(guān):模溫機(jī)數(shù)據(jù)采集難題的終結(jié)者與效率倍增器
設(shè)備數(shù)據(jù)的采集可以實(shí)現(xiàn)用“不需要點(diǎn)表的網(wǎng)關(guān)”嗎
使用MATLAB進(jìn)行無監(jiān)督學(xué)習(xí)

cypress3014視頻格式改變的話,GPIF狀態(tài)機(jī)需不需要重新配置?
目前國內(nèi)有哪些廠家是做不需要點(diǎn)表的工業(yè)網(wǎng)關(guān)的?
深控技術(shù)不需要點(diǎn)表的工業(yè)數(shù)采動(dòng)態(tài)產(chǎn)線重構(gòu)支持方案




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論