 英偉達NVIDIA為何可以在高性能計算GPU中處于不敗地位?
英偉達NVIDIA為何可以在高性能計算GPU中處于不敗地位?


英偉達 | GTC2022| 高性能計算
NVIDIA | RTX4090 |液冷服務器
在東數西算、生命科學、遙感測繪、地質勘探、真空羽流、冷凍電鏡等技術的快速發展下,高性能計算的發展逐漸被人們所重視。GTC 2022會上指出高性能計算是推動科學發展的關鍵工具之一。
昨天GeForce RTX 4090顯卡正式公布,是全新GeForce RTX 40系列的旗艦產品,也是全球首款基于全新NVIDIA Ada Lovelace架構。與上一代采用DLSS 2的RTX 3090 Ti相比,采用DLSS 3的RTX 4090的性能提升可達4倍。RTX 4090具有760億個晶體管、16384個CUDA 核心和 24GB 高速美光 GDDR6X 顯存。
本文將從英偉達為何在高性能計算中處于不敗地位、高性能計算發展趨勢、以及高性能計算解決方案為大家解讀。

高端GPU
英偉達獨角戲?
作為通用計算的“加速神器”--——高端GPU正在成為大型數據中心、人工智能、超算等領域的剛需。英偉達在高端GPU市場長期占據主導地位,市場份額一度超過90%。目前國內企業要突破英偉達等國外公司的壟斷還有很長的路要走。而國內基于架構創新的DSA(針對特定領域的可編程處理器)芯片產品日益豐富,可能會帶來一些曙光。
高端GPU與傳統GPU“涇渭分明”
傳統GPU聚焦圖像學,關注幀數、渲染逼真度、對于真實場景的映射程度等指標,主要用于運行游戲、專業圖像處理、加密貨幣處理等場景。而高端GPU是用于計算加速的芯片產品,專注于基礎科學等超算領域和訓練、推理等大規模人工智能計算場景。
衡量高端GPU的主要維度是通用性、易用性和高性能。通用硬件架構應該足夠靈活,以適應人工智能的迭代算法和場景。易用性是指開發門檻更低,開發者更容易上手,結合實際場景進行定制化開發。高性能是指芯片產品的基本性能和性價比必須達到國際先進水平,才能進行市場開拓。
2022年第二季度獨立GPU市場(包括AIB 合作伙伴顯卡)份額
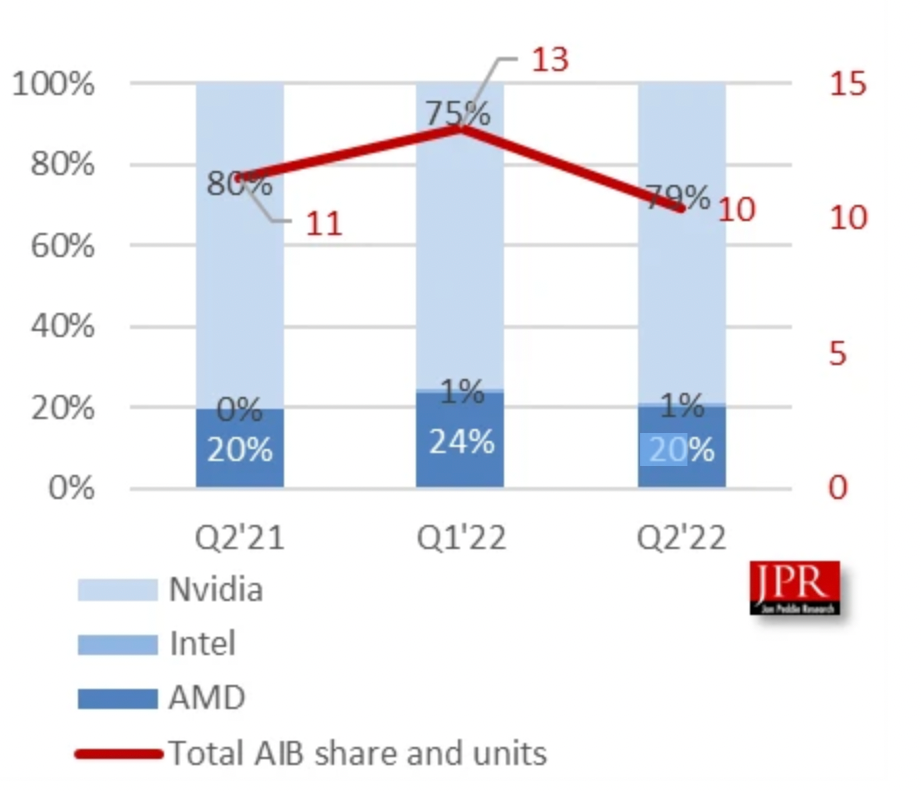
來源:Jon Peddie Research
算力往往是市場對GPU性能優劣的“第一印象”。但高端GPU的性能不等于紙面性能,尤其不能用單一性能的紙面數據來衡量。
在實際使用的過程中,GPU的通用性、易用性、實際性的重要程度遠大于紙面標出的算力這一單一性能。紙面指標標得再高,也要關注內存和帶寬夠不夠,以及芯片之間的互聯等問題解決得好不好。用單一性能來衡量GPU是否高端,是一個常見的誤區。
高性能計算將是主要“競技場”
長期以來,英偉達一直主導著高端GPU市場,市場份額超過90%,尤其是在人工智能計算領域。到目前為止,英偉達已經推出Volta、Ampere、Hopper等用于高性能計算和AI訓練的架構,并在此基礎上推出了V100、A100、H100等高端GPU。面向向量的雙精度浮點運算能力從7.8 TFLOPS一路走到30 TFLOPS。
作為全球第二大獨立GPU供應商,AMD雖在高端GPU的整體份額與英偉達存在差距,但在超算領域闖出了一片天。在最新全球超級計算機TOP500榜單上,世界上最快的超級計算機橡樹嶺國家實驗室(ORNL)前沿、世界排名第三的超級計算機LUMI,都采用了AMD EPYC處理器和AMD Instinct MI250X GPU加速器。
AMD在超算領域的亮眼表現,是建立在針對性的軟硬件設計上,基于CDNA 2架構的GPU加速器、ROCm軟件平臺與開源應用程序資源中心AMD Infinity Hub的組合,構成了對于科研人員更加友好的硬件性能和編程環境。
雖然直接使用GPU進行高性能或AI計算更方便,但上層應用降本增效的核心需求對底層算力提出了更高的要求。國外AI創業公司推出的AI芯片往往基于一種新的架構,全面提升并側重優化并行計算能力。國內領先的AI芯片公司也出于同樣的考慮,推出了一系列基于DSA架構的人工智能計算芯片。
在國內市場,基于架構創新的DSA芯片產品日益豐富。如華為自研的面向AI計算的架構特色達芬奇,昆侖芯科技推出的第一代架構XPU-K和第二代架構XPU-R,燧原科技的自研架構GCU-CARA等,都已經進入規模落地階段。隨著AI計算的應用場景越來越細分和復雜,定制化和異構化DSA有望在下一代計算平臺中發揮更大的作用。
新應用領域層出不窮
全球災難性氣候事件正在不斷增加,提前預測此類事件對保護人類安全越來越重要,因此未來一年與氣候預測相關的應用程序將在HPC領域備受關注。此外,隨著HPC在云端的使用,將有更多HPC應用于消費導向的軟件程序開發,虛擬世界和元宇宙概念的出現,也讓HPC迎來新的發展機遇,既可用于游戲(AR/VR)等娛樂應用,也可用于數字孿生等模擬應用。
HPC市場正在擴展新的領域,在傳統的模擬和建模過程中加入人工智能(AI)和數據分析技術。新冠疫情的爆發增加了對靈活、可擴展的云端HPC解決方案的需求,這一需求連同各個垂直行業(生命科學、汽車、金融、游戲、制造業、航空航天等)對快速處理數據和高精度日益增長的需求,將會是未來幾年推動HPC應用增長的主要因素。AI、邊緣計算、5G等技術將拓寬HPC的功能,從而形成新的芯片/系統架構,為各個行業提供高效處理和分析能力。
提高HPC安全性將成為關鍵
當市場整體的數字化程度提升,則安全風險也將隨之增加。越來越多的高性能計算正在遠離數據中心,將直接導致無法通過軟件補丁處理的攻擊數量增加。這給開發團隊帶來巨大壓力,迫使他們緊急推出硬件來解決這些問題,由此縮短硬件設計周期。因此提高開發者的生產效率以緊跟上市需求的步伐將成為下一步布局重點。
HPC處理器架構多樣化
隨著數據量增加,不僅是安全性,基礎設施存儲以及數據處理的計算能力必須得到提升。此外,新的架構包括芯片間的連接也是推動新需求所必需的。
受到不斷變化的AI工作負載、靈活的計算(CPU、GPU、FPGA、DPU等)、成本、內存和IO吞吐量等因素共同驅動,HPC架構正在經歷巨變。微架構層面變得互連更快、計算密度更高存儲可拓展、基礎設施效率更高、生態友好性、空間管理和安全性更高。從系統的角度來看,下一代HPC架構將出現分解架構和異構系統的爆炸式增長,不同的專用處理架構將集成在單個節點中,在模塊之間實現精密、靈活的切換。如此復雜的系統也帶來了巨大的驗證挑戰,尤其是系統的IP或節點、軟硬件動態協調、基于工作負載的性能、電源等相關驗證。要滿足這些驗證需求,需要開發新的軟硬件驗證方法。
移動數據對電力和時間有很大的需求,這是系統管理者現在面臨的挑戰之一,減少數據移動量將成為未來的一種趨勢。我們需要繼續擴展資源,利用高級封裝和芯片間接口來支持更高性能的設備,即通過使用多裸晶來擴展設備內的處理能力,這在未來一年內有望真正實現。
高性能計算
液冷解決方案
在深度學習、視覺計算、圖像渲染、數據科學、機器學習的迅猛發展的大背景下,高性能計算HPC、液冷散熱已經不再是少數大公司或大型科研機構的專屬要求,而是被越來越多的包括政府、教育科研、遙感測繪、醫藥研發、小分子研究、細胞治療、圖像識別的客戶所需要和接受。
藍海大腦為滿足客戶需求,結合行業特點從計算節點、網絡、存儲、功耗、擴展、散熱等方面出發,提出完善的解決方案。

產品特性
機架式液冷設計,即插即用,快速輕松投入使用;
支持最多9塊GPU圖形卡和2顆CPU處理器;
機架的存儲空間可大大擴展,可用于云存儲服務;
液冷系統密度更高、更節能、防噪音效果更好;
高效節能、綠色環保
客戶收益
超融合架構承擔著計算資源池和分布式存儲資源池的作用,極大地簡化了數據中心的基礎架構,通過軟件定義的計算資源虛擬化和分布式存儲架構實現無單點故障、無單點瓶頸、彈性擴展、性能線性增長等能力。
通過簡單方便的統一管理界面,實現對數據中心計算、存儲、網絡、虛擬化等資源的統一監控、管理和運維。
超融合基礎架構形成的計算資源池和存儲資源池直接可以被云計算平臺進行調配,服務于OpenStack、EDP、Docker、Hadoop、R、HPC等IaaS、PaaS、SaaS平臺,對上層的應用系統或應用集群等進行支撐。
分布式存儲架構簡化容災方式,實現同城數據雙活和異地容災。現有的超融合基礎架構可以延伸到公有云,可以輕松將私有云業務遷到公有云服務。
審核編輯 黃昊宇
-
NVIDIA
+關注
關注
14文章
5594瀏覽量
109757 -
gpu
+關注
關注
28文章
5194瀏覽量
135474 -
高性能計算
+關注
關注
0文章
96瀏覽量
13813
發布評論請先 登錄
每塊GPU對應16TB SSD,英偉達KV緩存虹吸高性能TLC SSD
如何在NVIDIA CUDA Tile中編寫高性能矩陣乘法

NVIDIA RTX PRO 5000 Blackwell GPU的深度評測

NVIDIA RTX PRO 4000 Blackwell GPU性能測試

在Python中借助NVIDIA CUDA Tile簡化GPU編程

NVIDIA RTX PRO 2000 Blackwell GPU性能測試

NVIDIA新聞:英偉達10億美元入股諾基亞 英偉達推出全新量子設備
英偉達發布 NVQLink 開放系統架構;國內首個汽車芯片標準驗證平臺投入使用
傳英偉達自研HBM基礎裸片
英偉達:我們的芯片不存監控軟件 NVIDIA官方發文 NVIDIA芯片不存在后門、終止開關和監控軟件
aicube的n卡gpu索引該如何添加?
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】+NVlink技術從應用到原理
英偉達擬再推中國特供GPU,今年6月量產!
GPU 維修干貨 | 英偉達 GPU H100 常見故障有哪些?




 工商網監
工商網監
評論