") 為什么深度學(xué)習(xí)模型經(jīng)常出現(xiàn)預(yù)測概率和真實情況差異大的問題?
為什么深度學(xué)習(xí)模型經(jīng)常出現(xiàn)預(yù)測概率和真實情況差異大的問題?

大家在訓(xùn)練深度學(xué)習(xí)模型的時候,有沒有遇到這樣的場景:分類任務(wù)的準確率比較高,但是模型輸出的預(yù)測概率和實際預(yù)測準確率存在比較大的差異?這就是現(xiàn)代深度學(xué)習(xí)模型面臨的校準問題。在很多場景中,我們不僅關(guān)注分類效果或者排序效果(auc),還希望模型預(yù)測的概率也是準的。例如在自動駕駛場景中,如果模型無法以置信度較高的水平檢測行人或障礙物,就應(yīng)該通過輸出概率反映出來,并讓模型依賴其他信息進行決策。再比如在廣告場景中,ctr預(yù)測除了給廣告排序外,還會用于確定最終的扣費價格,如果ctr的概率預(yù)測的不準,會導(dǎo)致廣告主的扣費偏高或偏低。
那么,為什么深度學(xué)習(xí)模型經(jīng)常出現(xiàn)預(yù)測概率和真實情況差異大的問題?又該如何進行校準呢?這篇文章首先給大家介紹模型輸出預(yù)測概率不可信的原因,再為大家通過10篇頂會論文介紹經(jīng)典的校準方法,可以適用于非常廣泛的場景。
1 為什么會出現(xiàn)校準差的問題
最早進行系統(tǒng)性的分析深度學(xué)習(xí)輸出概率偏差問題的是2017年在ICML發(fā)表的一篇文章On calibration of modern neural networks(ICML 2017)。文中發(fā)現(xiàn),相比早期的簡單神經(jīng)網(wǎng)絡(luò)模型,現(xiàn)在的模型越來越大,效果越來越好,但同時模型的校準性越來越差。文中對比了簡單模型LeNet和現(xiàn)代模型ResNet的校準情況,LeNet的輸出結(jié)果校準性很好,而ResNet則出現(xiàn)了比較嚴重的過自信問題(over-confidence),即模型輸出的置信度很高,但實際的準確率并沒有那么高。
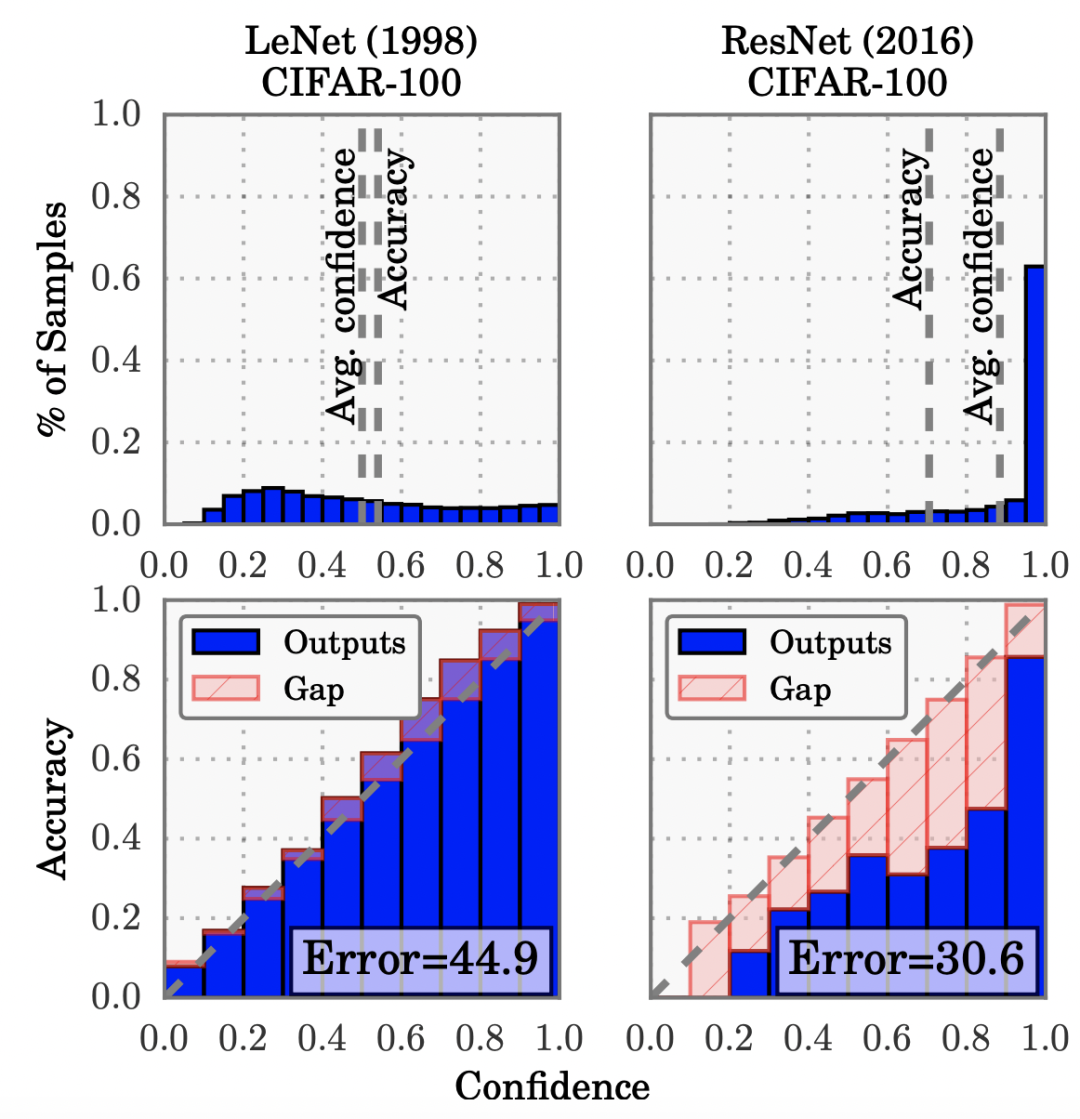
造成這個現(xiàn)象的最本質(zhì)原因,是模型對分類問題通常使用的交叉熵損失過擬合。并且模型越復(fù)雜,擬合能力越強,越容易過擬合交叉熵損失,帶來校準效果變差。這也解釋了為什么隨著深度學(xué)習(xí)模型的發(fā)展,校準問題越來越凸顯出來。
那么為什么過擬合交叉熵損失,就會導(dǎo)致校準問題呢?因為根據(jù)交叉熵損失的公式可以看出,即使模型已經(jīng)在正確類別上的輸出概率值最大(也就是分類已經(jīng)正確了),繼續(xù)增大對應(yīng)的概率值仍然能使交叉熵進一步減小。因此模型會傾向于over-confident,即對于樣本盡可能的讓模型預(yù)測為正確的label對應(yīng)的概率接近1。模型過擬合交叉熵,帶來了分類準確率的提升,但是犧牲的是模型輸出概率的可信度。
如何解決校準性差的問題,讓模型輸出可信的概率值呢?業(yè)內(nèi)的主要方法包括后處理和在模型中聯(lián)合優(yōu)化校準損失兩個方向,下面給大家分別進行介紹。
2 后處理校準方法
后處理校準方法指的是,先正常訓(xùn)練模型得到初始的預(yù)測結(jié)果,再對這些預(yù)測概率值進行后處理,讓校準后的預(yù)測概率更符合真實情況。典型的方法包括Histogram binning(2001)、Isotonic regression(2002)和Platt scaling(1999)。
Histogram binning是一種比較簡單的校準方法,根據(jù)初始預(yù)測結(jié)果進行排序后分桶,每個桶內(nèi)求解一個校準后的結(jié)果,落入這個桶內(nèi)的預(yù)測結(jié)果,都會被校準成這個值。每個桶校準值的求解方法是利用一個驗證集進行擬合,求解桶內(nèi)平均誤差最小的值,其實也就是落入該桶內(nèi)正樣本的比例。
Isotonic regression是Histogram binning一種擴展,通過學(xué)習(xí)一個單調(diào)增函數(shù),輸入初始預(yù)測結(jié)果,輸出校準后的預(yù)測結(jié)果,利用這個單調(diào)增函數(shù)最小化預(yù)測值和label之間的誤差。保序回歸就是在不改變預(yù)測結(jié)果的排序(即不影響模型的排序能力),通過修改每個元素的值讓整體的誤差最小,進而實現(xiàn)模型糾偏。
Platt scaling則直接使用一個邏輯回歸模型學(xué)習(xí)基礎(chǔ)預(yù)測值到校準預(yù)測值的函數(shù),利用這個函數(shù)實現(xiàn)預(yù)測結(jié)果校準。在獲得基礎(chǔ)預(yù)估結(jié)果后,以此作為輸入,訓(xùn)練一個邏輯回歸模型,擬合校準后的結(jié)果,也是在一個單獨的驗證集上進行訓(xùn)練。這個方法的問題在于對校準前的預(yù)測值和真實值之間的關(guān)系做了比較強分布假設(shè)。
3 在模型中進行校準
除了后處理的校準方法外,一些在模型訓(xùn)練過程中實現(xiàn)校準的方法獲得越來越多的關(guān)注。在模型中進行校準避免了后處理的兩階段方式,主要包括在損失函數(shù)中引入校準項、label smoothing以及數(shù)據(jù)增強三種方式。
基于損失函數(shù)的校準方法最基礎(chǔ)的是On calibration of modern neural networks(ICML 2017)這篇文章提出的temperature scaling方法。Temperature scaling的實現(xiàn)方式很簡單,把模型最后一層輸出的logits(softmax的輸入)除以一個常數(shù)項。這里的temperature起到了對logits縮放的作用,讓輸出的概率分布熵更大(溫度系數(shù)越大越接近均勻分布)。同時,這樣又不會改變原來預(yù)測類別概率值的相對排序,因此理論上不會對模型準確率產(chǎn)生負面影響。
在Trainable calibration measures for neural networks from kernel mean embeddings(2018)這篇文章中,作者直接定義了一個可導(dǎo)的校準loss,作為一個輔助loss在模型中和交叉熵loss聯(lián)合學(xué)習(xí)。本文定義的MMCE原理來自評估模型校準度的指標,即模型輸出類別概率值與模型正確預(yù)測該類別樣本占比的差異。
在Calibrating deep neural networks using focal loss(NIPS 2020)中,作者提出直接使用focal loss替代交叉熵損失,就可以起到校準作用。Focal loss是表示學(xué)習(xí)中的常用函數(shù),對focal loss不了解的同學(xué)可以參考之前的文章:表示學(xué)習(xí)中的7大損失函數(shù)梳理。作者對focal loss進行推倒,可以拆解為如下兩項,分別是預(yù)測分布與真實分布的KL散度,以及預(yù)測分布的熵。KL散度和一般的交叉熵作用相同,而第二項在約束模型輸出的預(yù)測概率值熵盡可能大,其實和temperature scaling的原理類似,都是緩解模型在某個類別上打分太高而帶來的過自信問題:
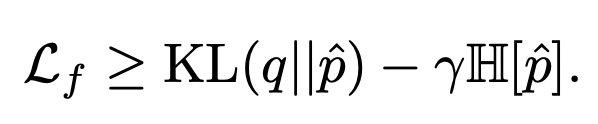
除了修改損失函數(shù)實現(xiàn)校準的方法外,label smoothing也是一種常用的校準方法,最早在Regularizing neural networks by penalizing confident output distributions(ICLR 2017)中提出了label smoothing在模型校準上的應(yīng)用,后來又在When does label smoothing help? (NIPS 2019)進行了更加深入的探討。Label smoothing通過如下公式對原始的label進行平滑操作,其原理也是增大輸出概率分布的熵:
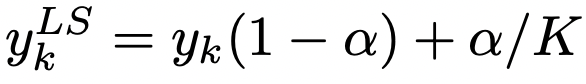
此外,一些研究也研究了數(shù)據(jù)增強手段對模型校準的影響。On mixup training: Improved calibration and predictive uncertainty for deep neural networks(NIPS 2019)提出mixup方法可以有效提升模型校準程度。Mixup是一種簡單有效的數(shù)據(jù)增強策略,具體實現(xiàn)上,隨機從數(shù)據(jù)集中抽取兩個樣本,將它們的特征和label分別進行加權(quán)融合,得到一個新的樣本用于訓(xùn)練:
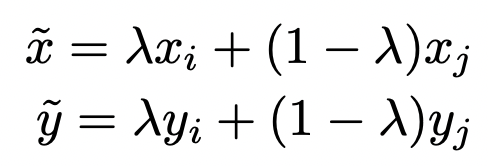
文中作者提出,上面融合過程中對label的融合對取得校準效果好的預(yù)測結(jié)果是非常重要的,這和上面提到的label smoothing思路比較接近,讓label不再是0或1的超低熵分布,來緩解模型過自信問題。
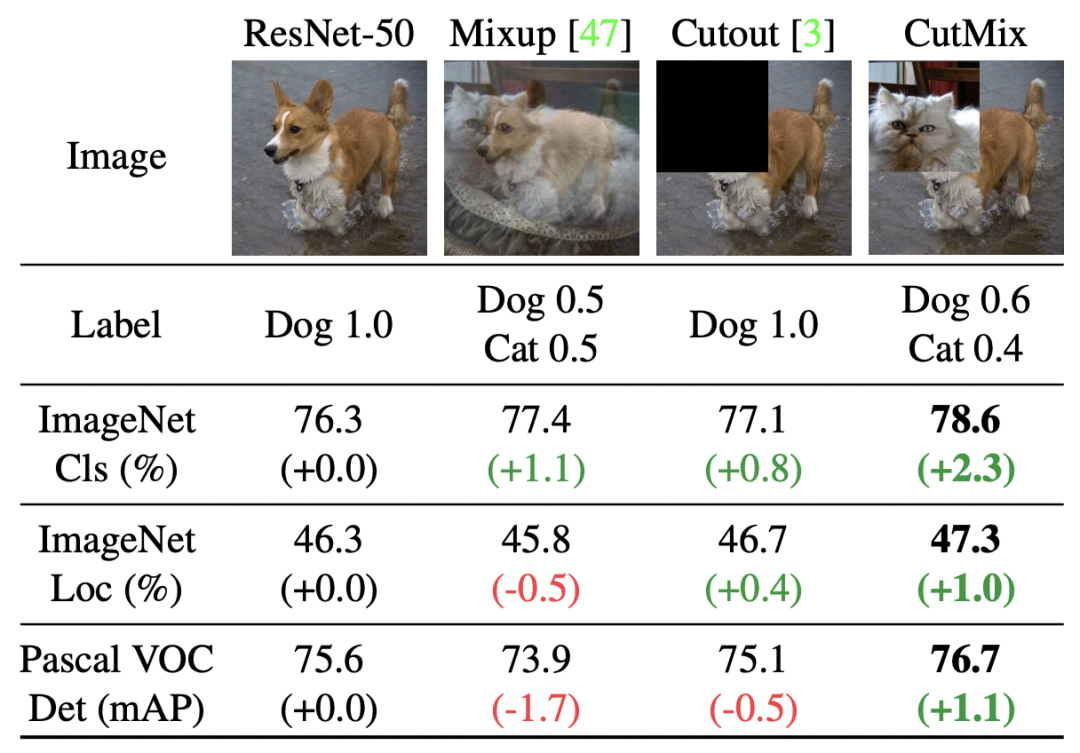
類似的方法還包括CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features(ICCV 2019)提出的一種對Mixup方法的擴展,隨機選擇兩個圖像和label后,對每個patch隨機選擇是否使用另一個圖像相應(yīng)的patch進行替換,也起到了和Mixup類似的效果。文中也對比了Mixup和CutMix的效果,Mixup由于每個位置都進行插值,容易造成區(qū)域信息的混淆,而CutMix直接進行替換,不同區(qū)域的差異更加明確。
4 總結(jié)
本文梳理了深度學(xué)習(xí)模型的校準方法,包含10篇經(jīng)典論文的工作。通過校準,可以讓模型輸出的預(yù)測概率更加可信,可以應(yīng)用于各種類型、各種場景的深度學(xué)習(xí)模型中,適用場景非常廣泛。
審核編輯:劉清
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4838瀏覽量
107794
原文標題:不要相信模型輸出的概率打分......
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
揭秘TEE深度休眠喚醒“低概率報錯”:從概念到解決方案的全解析

從數(shù)據(jù)到模型:如何預(yù)測細節(jié)距鍵合的剪切力?
機器學(xué)習(xí)和深度學(xué)習(xí)中需避免的 7 個常見錯誤與局限性

穿孔機頂頭檢測儀 機器視覺深度學(xué)習(xí)
大模型賦能物資需求精準預(yù)測與采購系統(tǒng):功能特點與平臺架構(gòu)解析
世界模型是讓自動駕駛汽車理解世界還是預(yù)測未來?

攻擊逃逸測試:深度驗證網(wǎng)絡(luò)安全設(shè)備的真實防護能力
設(shè)備出現(xiàn)通信問題的概率大嗎?

如何在機器視覺中部署深度學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)

自動駕駛中Transformer大模型會取代深度學(xué)習(xí)嗎?

晶圓切割深度動態(tài)補償?shù)闹悄軟Q策模型與 TTV 預(yù)測控制
瑞芯微3576,使用FP16模型進行訓(xùn)練,瑞芯微官方接口概率崩潰
大模型推理顯存和計算量估計方法研究
大模型時代的深度學(xué)習(xí)框架




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論