 一種將知識圖譜與語言模型結合的具體方式分享
一種將知識圖譜與語言模型結合的具體方式分享

知識嵌入(Knowledge Embedding)將知識圖譜中的關系和實體嵌入向量空間進行表示。現有工作主要分為兩類:傳統的基于結構的方法(如TransE)在向量空間建模KG的結構信息,此類方法無法良好地表示真實知識圖譜中大量結構信息匱乏的長尾實體;新興的基于文本的方法(如Kepler)引入額外的文本信息和語言模型, 但該方向的現有工作相較于基于結構的方法存在以下不足,包括效率較低、表現不佳、限制性文本依賴等問題。
知識工場實驗室提出了一個將語言模型用作知識嵌入的方法 LMKE,以期在提升長尾實體表示的同時解決現存基于文本方法的以上問題。LMKE 首次提出將基于文本的知識嵌入學習建模在對比學習框架下,顯著提升了模型在訓練和下游應用中的效率。實驗結果表明,LMKE在多個知識嵌入評價基準上取得了超越現有方法的表現,尤其是針對長尾實體。研究成果《Language Models as Knowledge Embeddings》已被IJCAI 2022錄用。

一、背 景
知識圖譜(Knowledge Graphs)以三元組的形式儲存了大量的知識。其中,三元組(h,r,t)表示,頭實體h與尾實體t間存在關系 r,如(法國,包含,盧浮宮)。
知識嵌入(Knowledge Embeddings, KEs)將知識圖譜上的實體和關系嵌入到向量空間中進行表示,以便在向量空間中推理,用于三元組分類、鏈接預測等任務。比如說,TransE 將實體“法國”、“盧浮宮”和關系“包含”分別表示為向量“法國”、“盧浮宮”、“包含”,而如果“法國”+“包含”≈“盧浮宮”,則認為該三元組為真。近年來,知識嵌入也越來越多地被用于與預訓練語言模型相結合,以賦予語言模型更多的知識。
現有的知識嵌入方法可以被大致分為兩類:傳統的基于結構的方法(Structure-based Methods)和近期興起的基于文本的方法(Description-based Methods)。
基于結構的方法在向量空間中表達知識圖譜的結構信息,包括 TransE、RotatE 等。這類方法可以建模多種特殊的關系模式,如對稱模式、逆模式、組合模式等。比如,已知“A 的父親是 B”,“B 的父親是 C”,且“父親的父親是爺爺”,則這類方法可以推理出“A 的爺爺是 C”,如下圖所示。
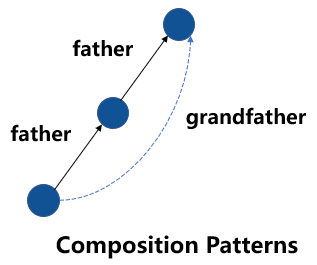
圖1 知識圖譜中的組合模式
然而,這類方法單純依賴知識圖譜的結構信息,因此自然難以良好地表示結構信息匱乏的長尾實體。在真實世界的知識圖譜中,實體的度數分布服從power-law定律,形成一條長長的尾巴,意味著大量實體缺乏充足的結構信息。比如,下方左圖展示了知識圖譜數據集WN18RR中的實體度數分布,其中14.1%的實體度數為1,60.7%的實體度數不超過3,這意味著這些實體在知識圖譜上連邊極少。下方右圖的結果則表明,以RotatE為代表的典型基于結構的方法在長尾實體上表現不佳。
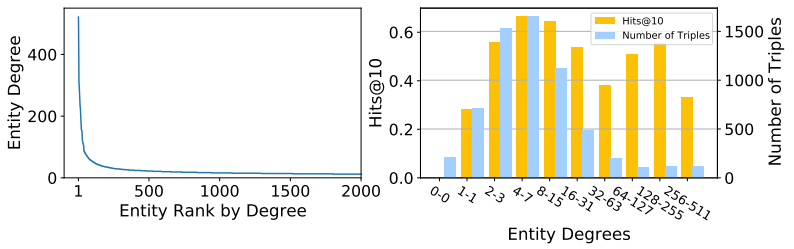
圖2 WN18RR上的節點度數分布及基于結構的方法在該數據集上的表現
基于文本的方法引入了文本信息和語言模型進行知識的嵌入與推理,如 DKRL、KEPLER 等。許多知識圖譜提供了實體和關系的文本描述,而這些豐富的文本信息可以良好地用于實體和關系的表示,并彌補結構信息的不足。同時,近期關于語言模型的相關研究表明:
①語言模型在預訓練時不僅掌握了語言知識,還學會了大量事實知識
②語言模型可以同基于結構的知識嵌入方法一樣,掌握對稱模式、逆模式、隱含模式等部分關系模式[2]。
因此,我們認為語言模型非常適合作為知識嵌入使用。
此前已有工作嘗試將語言模型用于知識嵌入的三元組分類、鏈接預測任務上。然而,現存的基于文本的方法存在以下缺陷:
①效率較低。語言模型規模龐大,因此現有工作在訓練及下游任務中或是時間復雜度過高,或進行了大量的 trade-off。一方面,它們在訓練時限制負采樣率。比如基于文本的 KEPLER 中正樣本和負樣本的數量是 1:1 的,而基于結構的 TransE 中一個正樣本會搭配上千個負樣本。另一方面,現有方法的模型結構在鏈接預測等下游任務上復雜度也過高。
②表現不佳。盡管引入了更多的信息與更大的模型,現存的基于文本的方法在許多數據集和指標上并未超越基于結構的方法,其中效率問題帶來的負采樣率不足等 trade-off 一定程度上造成了負面影響。
③限制性文本依賴。現存方法只適用于有文本描述的實體,而往往舍棄掉大量沒有文本信息(但有結構信息)的實體。現存方法對數據的嚴苛要求限制了他們在下游任務中的使用。
二、方 法
在本文中,我們提出了一個更好地將語言模型用作知識嵌入的方法LMKE(Language Models as Knowledge Embeddings),同時利用結構信息和文本信息,在提升長尾實體表示的同時解決基于文本方法的上述問題。在 LMKE 中,實體和關系被視作額外的詞(token),并從相關實體、關系和文本描述中學習表示。本文進一步提出將基于文本的知識嵌入學習建模在對比學習框架下,使得一個三元組里的實體表示可以作為同 batch 中其他三元組的負樣本,從而避免了編碼負樣本帶來的額外開銷。LMKE 也是一種將知識圖譜與語言模型結合的具體方式。
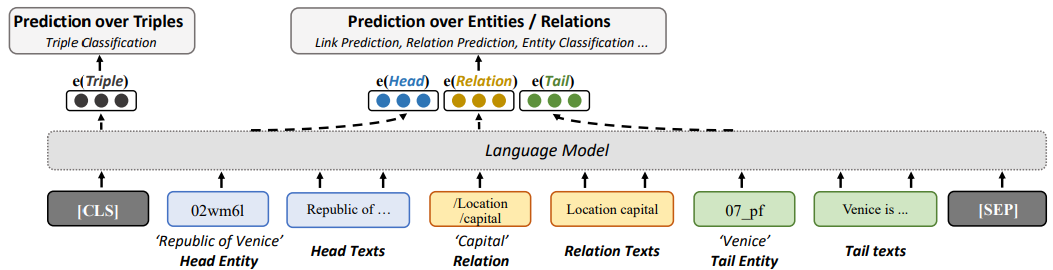
圖3 LMKE的模型結構(用于三元組分類)
LMKE 用語言模型作為知識嵌入,即用語言模型獲得實體和關系的嵌入向量表示,從而對三元組或實體進行預測。在 LMKE 中,實體和關系的嵌入向量與文本中的詞被表示在同一個向量空間中。如圖3所示,給定一個特定的三元組u=(h,r,t),LMKE 利用相應的文本描述信息,將它們拼為一個序列。將該序列作為語言模型的輸入,h,r,t的相應輸出向量 h,r,t,即是相應的實體和關系的嵌入向量。一個實體(或關系)的嵌入向量同時依賴于其自身、其自身的文本描述、其相關實體和關系、以及相關實體和關系的文本描述,對文本信息進行了最大程度的利用。
因此,長尾實體可以利用文本信息而被良好表示,而缺乏文本信息的實體則可以利用相關實體和關系(結構信息)以及它們的文本描述被良好表示。語言模型中的CLS token(或 BOS token)對應的向量聚合了整個序列的信息,因此我們將其視作代表整個三元組u的向量u。
與KG-BERT相似,LMKE 將向量u輸入一個線性層,來計算三元組為真的概率p(u):知識嵌入的主要應用是預測缺失的鏈接(鏈接預測)和對可能的三元組進行分類(三元組分類)。其中,三元組分類基于上述p(u)即可進行。鏈接預測則需要預測出不完整三元組(?,r,t)或(h,r,?)的缺失實體。具體來說,模型需要將候選實體(一般為所有實體)填入不完整三元組,并將相應的三元組進行打分,從而對候選實體按照得分進行排序。然而,對于上述 LMKE 模型,以及大部分現有的基于文本的方法,這一流程的計算時間復雜度都過高,如表1所示。
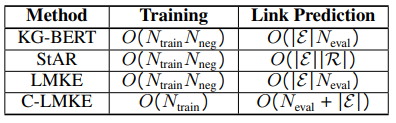
表1 部分基于文本的方法在訓練和鏈接預測上的時間復雜度
為了將語言模型高效地用于鏈接預測任務,一個簡單的方法是不完整地編碼三元組,而僅編碼部分三元組。實體遮蓋模型(MEM-KGC)可以視為 LMKE 的 masked變體,將待預測的缺失實體和其文本描述 mask,并將相應的向量表示q輸入一個線性層來預測缺失實體。因為僅需要編碼一個不完整的三元組,MEM-KGC顯著降低了時間復雜度。然而,MEM-KGC 忽視了待預測實體的文本信息,降低了文本信息的利用率。
我們提出了一個對比學習框架來更充分地利用文本信息。在我們的對比學習框架中,給定的實體關系對被視作查詢q,而目標實體被視作鍵k,我們通過匹配q和k進行對比學習。在這一框架的視角下,MEM-KGC 中的向量q即為查詢的向量表示,而MEM-KGC的線性層權重的每一行則是每一個實體作為鍵的向量表示。因此,將q輸入到線性層即為查詢q匹配鍵。差別在于,MEM-KGC的鍵是用可學習的向量表示,而非像查詢一樣是文本信息的語言模型編碼。我們提出的對比學習框架也使得語言模型能夠被高效地用于鏈接預測。
C-LMKE是對比學習框架下的LMKE變體,將MEM-KGC中的可學習實體權重改進為目標實體的文本描述編碼,如圖4所示。C-LMKE進行批次內的對比匹配,從而避免了編碼負樣本帶來的額外開銷。具體來說,對于 batch 中的第i個三元組,它的給定實體關系對q和目標實體k構成一個正樣本,而同batch內其他三元組的目標實體k’與q構成負樣本。由表1可見,C-LMKE在訓練和鏈接預測時的時間復雜度均顯著優于現有基于文本的方法。
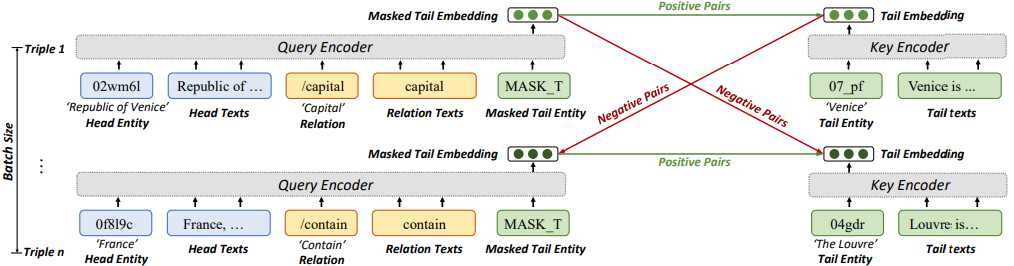
圖4 C-LMKE的模型結構(用于鏈接預測)
不同于一般的對比學習方法,C-LMKE采用一個雙層MLP而非余弦相似度來計算q和k的匹配度。假設查詢q=(法國,包含)同時與=(盧浮宮)和=(巴黎)匹配,則基于相似度的得分會迫使和的表示相似,這在知識嵌入的場合是不被期望的。同時,我們還發現,引入度數信息和(相應實體在訓練集中的三元組個數)對于鏈接預測任務相當有幫助。
基于得分 p(q, k),我們使用二元交叉熵作為損失函數進行訓練,并參考RotatE 中提出的自對抗負采樣來提高難負樣本的損失權重。
三、實驗結果
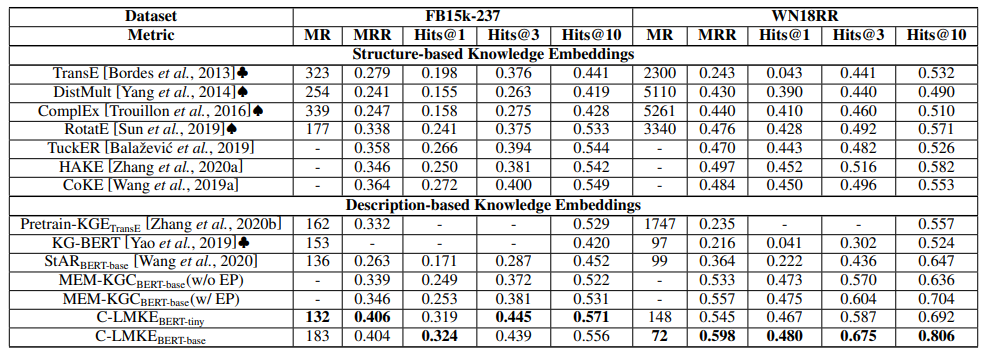
表2 FB15k-237及WN18RR上的鏈接預測結果
我們在鏈接預測和三元組分類兩個任務上對我們的方法進行了實驗,以BERT-tiny和BERT-base作為基本模型。在鏈接預測上,我們的模型顯著超越了現有模型。使用BERT-BASE的C-LMKE在WN18RR上取得了80.6%的 Hits@10,而此前最好的結果僅為70.4%。即使我們使用 BERT-tiny 作為語言模型,我們的方法取得的表現也優于或相當于使用更大模型的現有方法。同時,使用BERT-tiny的C-LMKE在FB15k-237上取得了57.1%的Hits@10,是首個超越基于結構方法的基于文本方法。
一個有趣的現象是,基于文本的方法在WN18RR上顯著超越基于結構的方法,但在FB15k-237上卻不然。我們認為背后的原因是數據集的差異。WN18RR來源于字典知識圖譜WordNet,其中的實體是詞而文本描述是詞的定義,而從詞的定義中可以很容易推出詞之間的關系。相對地,FB15k-237來源于真實知識圖譜Freebase,其中的文本僅部分地描述了一個實體最廣為人知的知識,比如(愛因斯坦,是,和平主義者)這一知識就不被它們的文本描述所涵蓋。因此,過度依賴于文本而非結構信息可能導致模型表現不佳。這也解釋了在該數據集上使用BERT-tiny替換 BERT-base后表現沒有下降。
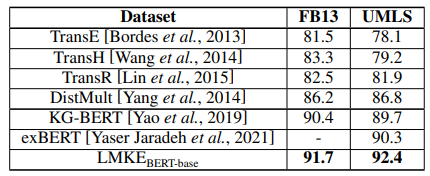
表3 FB13和UMLS上的三元組分類結
LMKE 在三元組分類任務上也取得了最優的表現。其中,LMKE和KG-BERT的差距代表了引入實體和關系作為特殊詞的有效性。
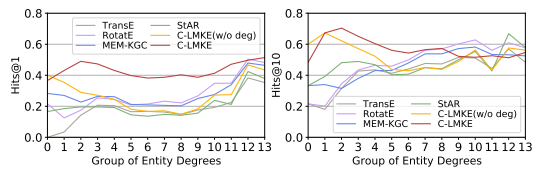
圖5 不同模型對于FB15k-237中包含不同度數實體的三元組的平均表現
為了展示我們的方法在長尾實體表示上的有效性,我們將實體按度數的對數進行分組,統計包含不同度數實體的三元組,并研究包含不同度數實體的三元組上的表現。實驗結果表明,基于文本的方法在低度數組 0,1,2(即包含度數低于 4 的實體的三元組)上的表現顯著優于基于結構的方法,而C-LMKE又顯著優于其他的基于文本的方法。同時,在加入了度數信息后,C-LMKE在中高度數組上的表現有了顯著提升。
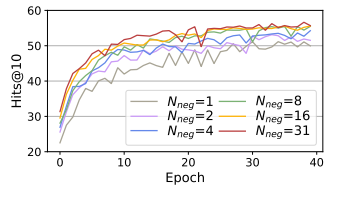
圖6 不同負采樣率下C-LMKE在FB15k-237上的表現
我們進一步研究了負采樣率對基于文本的知識嵌入學習的影響。我們將batch size 設為32,因此 1 個正樣本最多配有31個負樣本,而我們進一步限制可見負樣本數為{1, 2, 4, 8, 16}。實驗結果表明,更大的負采樣率能顯著提升模型的表現,證明了負采樣率對基于文本的方法的重要性。然而,現有基于文本方法受限于負樣本編碼代價,一般僅使用1個或5個負樣本。
總結起來,我們的貢獻主要有以下三點:
①我們注意到基于結構的知識嵌入在表示長尾實體上的不足,并首次提出利用文本信息和語言模型來提升長尾實體的表示。
②我們提出了一個基于文本的新模型LMKE,解決了現有基于文本方法的三個不足之處。同時,我們也首次提出將基于文本的知識嵌入學習建模為對比學習問題。
③我們在多個知識嵌入數據集上進行了廣泛實驗,實驗結果表明LMKE 在三元組分類和鏈接預測任務上取得了state-of-the-art 的表現,顯著超越現有知識嵌入方法,使得基于文本的方法首次在數據集FB15K-237 上超越基于結構的方法。
筆者認為,LMKE提出的對比學習框架將是基于文本的知識嵌入的發展方向。在這一方向上,我們仍可參考對比學習領域的優秀方法來取得進一步提升。同時,信息檢索、實體鏈接在本質上也是鏈接預測任務,近年來也越來越多地采用了對比學習,我們也可以從這些領域的工作中吸取經驗。
最后,我們注意到被 ACL 2022 接收的同期工作SimKGC同樣提出了基于文本的知識嵌入的對比學習框架,在 WN18RR 上取得了與我們相當的表現,并研究了負采樣對于基于文本方法的重要性。這進一步說明了對比學習框架在基于文本的知識嵌入的發展上的必然性。SimKGC相較于LMKE,使用了更龐大的算力(32 倍的 batch size)、余弦相似度度量、InfoNCE損失以及基于圖的Reranking策略,產出了值得我們借鑒的結果,不過他們在事實知識圖譜FB15k-237上的表現仍未超越基于結構的方法。LMKE相較于SimKGC,則還關注了長尾實體表示、三元組分類任務以及度信息的重要性。
審核編輯:劉清
-
編碼
+關注
關注
6文章
1039瀏覽量
56976 -
CLS
+關注
關注
0文章
9瀏覽量
9884 -
語言模型
+關注
關注
0文章
571瀏覽量
11314
原文標題:語言模型用作知識嵌入
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
實力認證!行云創新入圍《AI 中國生態圖譜 2025》大模型開放平臺板塊

什么是大模型,智能體...?大模型100問,快速全面了解!

UPS電源供電方式詳解:3大核心類型+工作原理,一看就懂

潤和軟件入選大模型一體機產業圖譜

RAG實踐:一文掌握大模型RAG過程
指令集測試的一種糾錯方法
【「AI芯片:科技探索與AGI愿景」閱讀體驗】+AI的未來:提升算力還是智力
一種帶通濾波器在無位置傳感器轉子檢測中的應用
如何使用Docker部署大模型
輕輕松松學電工(識圖篇)
電路識圖從入門到精通高清電子資料
?VLM(視覺語言模型)?詳細解析




 工商網監
工商網監
評論