") 一種新的無監(jiān)督時間序列異常檢測方法
一種新的無監(jiān)督時間序列異常檢測方法

摘要:傳統(tǒng)的時間序列異常檢測方法大多以數(shù)據(jù)點作為檢測單位,通過訓練模型預測下一時刻數(shù)據(jù),這類方法的缺點是沒有考慮時間序列數(shù)據(jù)的特性,即序列模式的多樣性。因此文中提出一種基于Seq2Seq深度自編碼器的時間序列異常檢測方法,以更好地挖掘時間序列數(shù)據(jù)中的異常序列模式。此方法使用Bi?LSTM網(wǎng)絡作為深度自編碼器,其輸入輸出均為序列,使用深度自編碼器對時間序列進行編碼壓縮和解碼重建。通過計算重建序列與原始序列之間的重建誤差,并設置重建異常比率以獲取誤差閾值,將重建誤差大于此閾值的時間序列視為異常序列。異常時間序列的發(fā)現(xiàn)取決于模型對原始序列的重建效果,通過在空氣質(zhì)量時間序列數(shù)據(jù)上的實驗,模型初步達到了不錯的檢測效果,證明了所提方法的可行性。文中方法為時間序列異常檢測提供了新的途徑。
0 引 言
時間序列數(shù)據(jù)是生活中常見的一種數(shù)據(jù),在時間順序上具有一定規(guī)律,且大量存在于金融貿(mào)易、工業(yè)生產(chǎn)、環(huán)境保護、網(wǎng)絡安全等眾多領域。時間序列異常檢測在生產(chǎn)和生活中有著重要的作用,如在網(wǎng)絡安全領域中分析網(wǎng)絡異常行為,在金融領域中識別欺詐交易等[1]。
傳統(tǒng)時間序列異常檢測方法(統(tǒng)計學方法或聚類方法),如高斯模型、ARIMA、K?means、IForest等都屬于統(tǒng)計機器學習的范疇[2]。這些方法基本在每個時刻訓練模型以預測下一時刻,若觀測點與預測值相差太遠,則將該點視為異常[3]。這類方法的不足之處在于忽視了時間序列數(shù)據(jù)的序列特性,無法挖掘序列中的異常序列模式。本文提出基于Seq2Seq深度自編碼器的時間序列異常檢測方法,使用Bi?LSTM網(wǎng)絡作為自編碼器對輸入序列進行編碼壓縮和解碼重建,此方法能夠更好地挖掘時序數(shù)據(jù)中的異常序列模式。
1 算法原理
1.1 深度自編碼器
深度自編碼器(Deep Autoencoder,DAE)是一種無監(jiān)督或自監(jiān)督算法,其本質(zhì)是一種數(shù)據(jù)壓縮算法。構(gòu)建一個深度自編碼器需要兩個部分:編碼器(Encoder)和解碼器(Decoder)。編碼器將輸入壓縮為潛在空間表征, 解碼器將潛在空間表征重建為輸出, 編碼器和解碼器都是神經(jīng)網(wǎng)絡[4?5]。編碼和解碼方法都是由模型自動學習輸入數(shù)據(jù)得到的, 深度自編碼器的結(jié)構(gòu)如圖1所示。
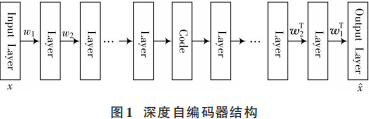
深度自編碼器主要有以下三個特點[6]:
1)數(shù)據(jù)相關性。自編碼器只能編碼與之前類似的數(shù)據(jù)。
2)數(shù)據(jù)有損性。自編碼器解碼得到的輸出與原始輸入相比會有信息損失。
3)自動學習性。自動編碼器從數(shù)據(jù)中自動學習編碼和解碼的方法。
1.2 Bi?LSTM 網(wǎng)絡
長短期記憶(Long Short?Term Memory, LSTM)網(wǎng)絡是為解決循環(huán)神經(jīng)網(wǎng)絡(Recurrent Neural Networks,RNN)中梯度消失的問題提出的一種網(wǎng)絡結(jié)構(gòu)。LSTM單元可以處理長度可變的序列,并捕獲其中的長期依賴性和非線性關系,已成為處理序列數(shù)據(jù)的標準方法[7]。根據(jù)LSTM單元提出的自學習門控方法,能確定LSTM單元是否記憶之前的狀態(tài)或是否存儲當前數(shù)據(jù)中的信息。LSTM單元內(nèi)部運算過程如圖2所示。
設t 時的輸入序列為向量xt,輸出為ht,LSTM單元內(nèi)部計算過程如下:
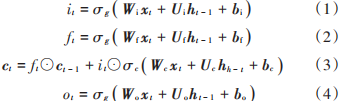

式中:ct是t時記憶單元中的狀態(tài)向量;ct-1是t-1時記憶單元中的狀態(tài)向量;W, U和b是參數(shù)矩陣和偏差向量;“⊙”表示元素積運算。此外,ft 表示遺忘門(ForgetGate),其作用是存儲舊信息的權重向量;it表示輸入門(Input Gate),用于獲取新信息的權重向量;ot示輸出門(Output Gate),用于輸出待輸出的候選向量[8?9]。在激活函數(shù)中,σg表示sigmoid函數(shù);σc和σh表示tanh函數(shù)。
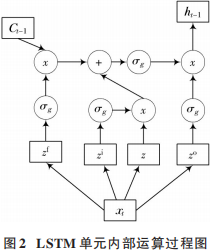
雙向長短期記憶(Bi?directional Long Short?TermMemory,Bi?LSTM)網(wǎng)絡通過引入第二層LSTM單元來擴展單向LSTM網(wǎng)絡[10],其可以在前后兩個方向上同時處理輸入序列。在第二層中,隱含層單元的序列順序相反,因此該網(wǎng)絡可以同時利用過去和未來的序列信息。Bi?LSTM網(wǎng)絡結(jié)構(gòu)圖如圖3所示。
1.3 基于 Seq2Seq 的 Bi?LSTM 深度自編碼器時間序列
異常檢測模型Seq2Seq模型屬于自編碼器結(jié)構(gòu)中的一類[11],常用于文本翻譯、語音生成等自然語言處理領域。基本思想是用編碼器將輸入序列壓縮成指定長度的向量,再用解碼器將編碼向量解碼成指定長度的序列[12]。
針對時間序列異常檢測而言,假設樣本中異常序列數(shù)量相對于正常序列來說是極少數(shù)的。在使用深度自動編碼器的情況下,訓練模型以學習正常時間序列中的序列模式[13?14]。那么當時間序列輸入深度自編碼器中時,對于多數(shù)正常序列,模型可以很容易地發(fā)現(xiàn)并記住其中的序列模式,其重建誤差相對可能較小;反之對于少數(shù)異常序列,模型很難對其序列模式進行挖掘,則重建誤差相對可能較大。
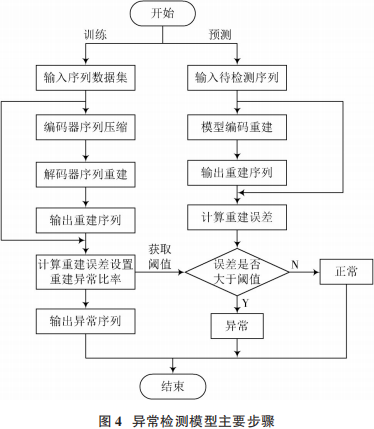
因此對于輸入的時間序列,若經(jīng)過模型編碼重建后與原始序列差異較大的話,則可以認為當前序列中可能存在異常,并可以進一步發(fā)現(xiàn)異常數(shù)據(jù)點。基于Seq2Seq深度自編碼器的時間序列異常檢測模型,使用Bi?LSTM網(wǎng)絡作為自編碼器對輸入序列進行編碼和重建。通過計算重建序列與原始序列之間的重建誤差,并設置重建異常比率以獲取誤差閾值,將重建誤差大于閾值的序列視為異常序列。異常檢測模型的主要步驟如圖4所示。
2 實證分析
2.1 時間序列數(shù)據(jù)集
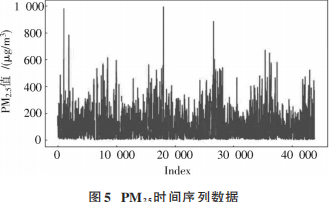
實驗中所用到的時間序列數(shù)據(jù)為北京地區(qū)每小時PM2.5數(shù)據(jù), 數(shù)據(jù)集來自UCI Machine LearningRepository, 范圍為2010?01?01—2014?12?31。數(shù)據(jù)集共43824個樣本,對于缺失值使用同一天數(shù)據(jù)的平均值替換,經(jīng)過處理后的時間序列數(shù)據(jù)如圖5所示。
對數(shù)據(jù)進行2天重采樣,即用時間窗口大小為48h的時序數(shù)據(jù)作為輸入序列,重采樣后的數(shù)據(jù)集共913個樣本。其中使用70%作為訓練集,20%作為驗證集,10%作為測試集。
2.2 Bi?LSTM 深度自編碼器構(gòu)建
本文使用基于Python的Tensorflow 2深度學習庫構(gòu)建Bi?LSTM深度自編碼器模型。實驗環(huán)境為Windows1064位,CPU為I7?8750h,顯卡為GTX10606GB,內(nèi)存為8 GB。
首先使用MinMaxScaler方法將數(shù)據(jù)歸一化,采用順序方式(Sequential)構(gòu)建網(wǎng)絡模型。編碼器和解碼器均定義為Bi?LSTM層,共7層,其單元數(shù)量分別為64,48,32,12,32,48,64,前6層均返回序列。接下來定義Dropout層,Dropout比率為0.2。最后一層定義Dense全連接層, 共有48個單元,激活函數(shù)為線性整流函數(shù)(ReLU)。模型編譯時,使用均方誤差(Mean Square Error,MSE)作為損失函數(shù)(Loss),使用Adam作為和優(yōu)化算法(Optimizer),學習率(LR)設為0.0001。模型訓練時,設置批次訓練樣本數(shù)(Batch_size)為32,訓練輪次(Epoch)為50。
2.3 實驗結(jié)果
在實驗中,使用重建序列和原始序列對應元素差值的二范數(shù)(2?Norm)作為重建誤差指標。設序列重建前后對應的元素差為向量X=(x1,x2,…,xn),該數(shù)值越大說明重建誤差越大。重建誤差指標如下:

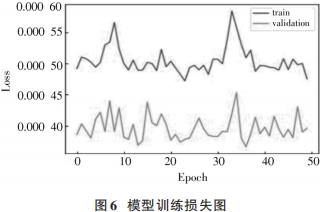
經(jīng)過50輪訓練后,模型在訓練集和驗證集上的損失見圖6。從圖6可以看出,模型在訓練集上的最終損失約為0.00051,在測試集上的最終損失約為0.00039。
模型訓練完成后,將重建異常比率設為0.99,得到重建誤差閾值約為0.4005。模型在訓練集和驗證集上的異常檢測結(jié)果如圖7所示。
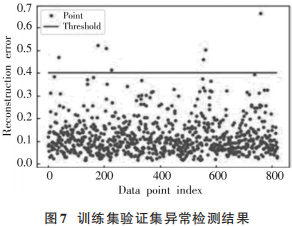
從圖7可以知道,模型在訓練集和驗證集上共檢測到10個異常序列,其編號分別為22,39,40,227,334,376,555,562,711,779。對異常序列711重建前后進行可視化如圖8所示。
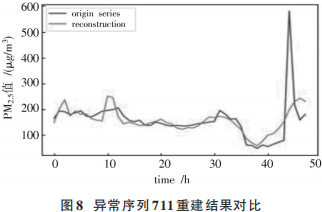
從圖8可以看出,異常序列711在前42h一直處于較平緩狀態(tài),PM2.5值最大在200 μg/m3左右。因此模型可以較好地重建這一部分序列,重建誤差較小。在43~47h之間,PM2.5值先劇增后迅速減少,序列出現(xiàn)劇烈變化。模型無法重建預測這一部分序列,重建誤差過大,因此將此序列視為異常。接下來使用模型在測試集上進行檢測,結(jié)果如圖9所示。從圖9可以看出,模型在測試集上共檢測到12個異常序列,對異常序列 901重建前后進行可視化,如圖10所示。
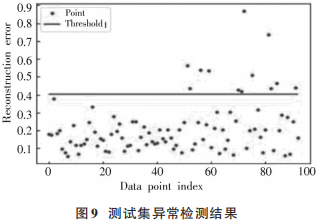
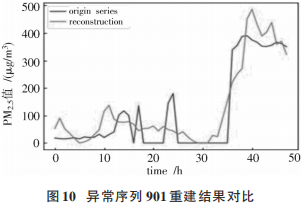
從圖10可以看出,異常序列901在20h左右和25~35h的PM2.5值均為0μg/m3,且在 35h后序列急速上升。模型較好地重建了35h后的上升序列,但無法有效重建兩段為0的時間序列,重建誤差大于閾值,因此將此序列視為異常。
3 結(jié) 語
在時間序列異常檢測任務中,除了監(jiān)督算法外,基于無監(jiān)督的異常檢測方法也值得考慮。本文提出一種新的無監(jiān)督時間序列異常檢測方法,此方法基于Seq2Seq模型,利用Bi?LSTM深度自編碼器對序列的重建效果來發(fā)現(xiàn)異常序列。異常序列的發(fā)現(xiàn)取決于模型對原始序列的重建效果,該方法能更好地挖掘時間序列中的異常序列模式。通過在空氣質(zhì)量數(shù)據(jù)上的實驗,證明了該方法的可行性,模型初步達到了不錯的檢測效果,為時間序列異常檢測提供了新的方法。
作者簡介:
爨 瑩(1968—),女,陜西西安人,博士,教授,研究方向為智能可視化計算。
吳 越(1996—),男,陜西西安人,碩士研究生,研究方向為數(shù)據(jù)挖掘、機器學習。
審核編輯:湯梓紅
-
編碼器
+關注
關注
45文章
3985瀏覽量
143095 -
時間序列
+關注
關注
0文章
31瀏覽量
10703
原文標題:基于 Seq2Seq深度自編碼器的時間序列異常檢測方法研究 | 論文速覽
文章出處:【微信號:現(xiàn)代電子技術,微信公眾號:現(xiàn)代電子技術】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
基于transformer和自監(jiān)督學習的路面異常檢測方法分享

提高IT運維效率,深度解讀京東云AIOps落地實踐(異常檢測篇)
【「時間序列與機器學習」閱讀體驗】全書概覽與時間序列概述
科學數(shù)據(jù)時間序列的預測方法
一種快速的視頻序列運動分割方法
一種有效的視頻序列拼接方法
寶信利用Spark Analytics Zoo對基于LSTM的時間序列異常檢測的探索
如何使用頻繁模式發(fā)現(xiàn)進行時間序列異常檢測詳細方法概述
基于時間卷積網(wǎng)絡的通用日志序列異常檢測框架

一種多維時間序列汽車駕駛異常點檢測模型
使用MATLAB進行異常檢測(下)
智能電網(wǎng)時間序列異常檢測:a survey

基于一種用于JumpStarter的抗離群的采樣算法



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論