") 解析yolov7采用的一項技術(shù):模型結(jié)構(gòu)重參化
解析yolov7采用的一項技術(shù):模型結(jié)構(gòu)重參化

Yolov7問世,刷新了目標檢測內(nèi)卷的新上限!小博此次攜手博世AI大神Zlex做一次解析。今天,我們不準備解析yolov7,而是解析yolov7采用的一項技術(shù):模型結(jié)構(gòu)重參化。
首先,這要從古老的vgg說起,很久很久以前神經(jīng)網(wǎng)絡還沒有很多花樣的時候,他是一個以卷積為主串聯(lián)的網(wǎng)絡結(jié)構(gòu),如下圖所示:

由于見證了神經(jīng)網(wǎng)絡的神奇效果,科學家工程師們前仆后繼開發(fā)了resnet, inception net, 以及自學習產(chǎn)生的efficientnet等等以結(jié)構(gòu)創(chuàng)新為主的系列,以及歸一化系列(ln,bn,gn,in),激活函數(shù)系列, 卷積系列等各種新的計算層,還有各種損失函數(shù)層等等。
隨著思維的展開,除了從計算方法(數(shù)學推理角度)和網(wǎng)絡結(jié)構(gòu)(實驗性創(chuàng)新角度)層面創(chuàng)新,還有哪些腦洞可以打開呢?是否可以實現(xiàn)數(shù)學和網(wǎng)絡結(jié)構(gòu)方面的互相轉(zhuǎn)化?答案是肯定的,數(shù)學推算和結(jié)構(gòu)設計之間是可以相互轉(zhuǎn)化的。
而模型結(jié)構(gòu)重參化就是其中一種。
01
模型結(jié)構(gòu)重參化
模型結(jié)構(gòu)重參化是繼承了深度學習的特性,并作為思考點而展開的,也就是訓練(train)和推斷(deploy)分別思考的策略,通常我們是可以忍受訓練速度較慢,但是推理更加快速的部署方案。
基于這個現(xiàn)實的考慮,是否可能通過增加訓練的復雜度但不增加推斷運行的時間,從而達到模型能力的提升?
其實這一切都經(jīng)不起科學家的推敲,這種思路的可行性答案也是肯定的,其實在很久之前的部署加速技巧—— Conv、BN、Relu 三個層融合(大部分情況是conv和bn融合)也是發(fā)現(xiàn)了——訓練和部署可以在網(wǎng)絡結(jié)構(gòu)不同的情況下實現(xiàn)效果等價,這個數(shù)學公式等價變換思路。而tensorRT等部署加速方案也都融合了這項技術(shù)。
模型結(jié)構(gòu)重參化(structural re-parameterization)是丁霄漢近年來提出的一種通用深度學習模型設計方法論。該方法論首先指出了構(gòu)造一系列用于訓練的結(jié)構(gòu),并將其結(jié)構(gòu)等價轉(zhuǎn)換為另一種用于測試的結(jié)構(gòu),也就是訓練和測試的結(jié)構(gòu)不再相同,但是效果等效。
該理論是假設在訓練資源相對豐富的條件下,在不降低推理能力的前提下又能達到提速的目的。因此訓練時的模型可以足夠復雜,且具備優(yōu)秀的性質(zhì)。而轉(zhuǎn)換得到的推理時模型可以簡化,但能力不會減弱,也就是實現(xiàn)無損壓縮。
為什么要以vgg為例,而不是以目前各種先進復雜的結(jié)構(gòu)為例解析這一設計呢?其原因在于:模型結(jié)構(gòu)復雜提升了精度,但不利于硬件的各種并行加速計算。但vgg這種單一的結(jié)構(gòu)更容易做很多的變形和加速操作,Repvgg就是基于vgg網(wǎng)絡的模型結(jié)構(gòu)重參化。
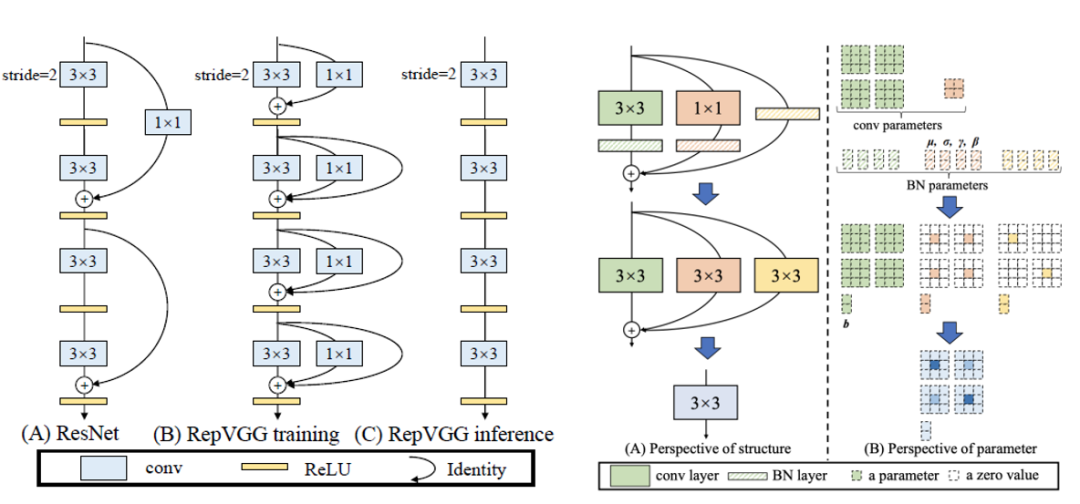
論文中對比了resnet的參差結(jié)構(gòu)和rep結(jié)構(gòu)的不同,以及訓練和推理網(wǎng)絡如何轉(zhuǎn)化,如下圖所示:
以上設計方法論基于的數(shù)學關(guān)系是:
(i+c+b)*w=i*w + c*w + b*w的等式理論。
該等式畫成結(jié)構(gòu)圖是:
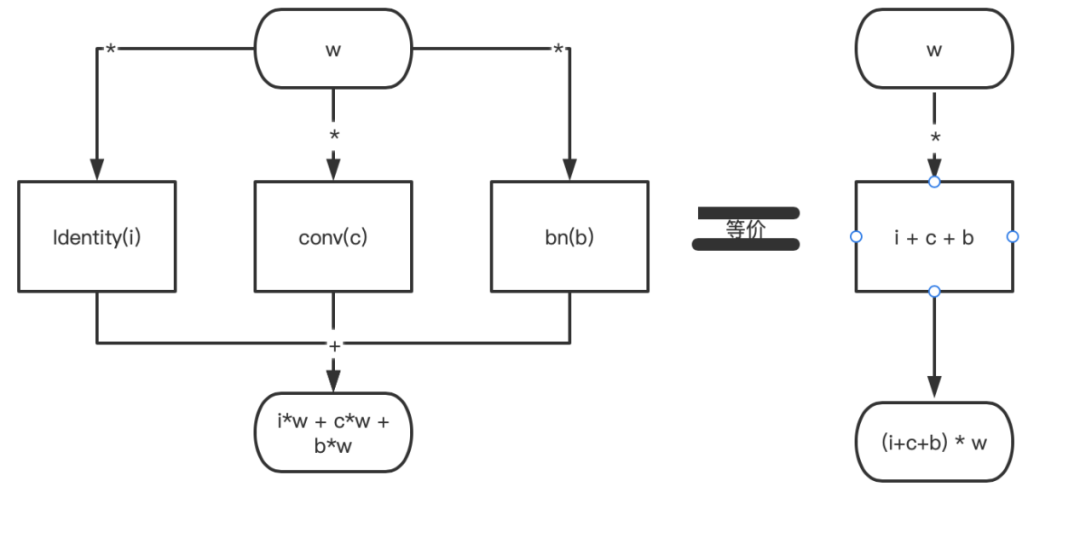
只不過在卷積的世界里,a和b表示的是一個n*n的核;而在一些設計里面,a和b的大小是不一致的。這個時候就需要把現(xiàn)在a和b的維度進行一致性轉(zhuǎn)換,也就是repvgg作者采用的:把1*1的核通過pad的方法補0操作變成3*3的核,達到a、b維度一致。
identity的操作相當于是1*1的單位矩陣卷積pad后就可以轉(zhuǎn)化為3*3的卷積核。還應該值得注意的是:每個卷積后面還跟著bn層,這是就用到了上述提到的conv和bn的融合計算方法。
02
Yolov7在這項技術(shù)上的發(fā)現(xiàn)和創(chuàng)新
Yolov7中的模型結(jié)構(gòu)重參化做了哪些創(chuàng)新?
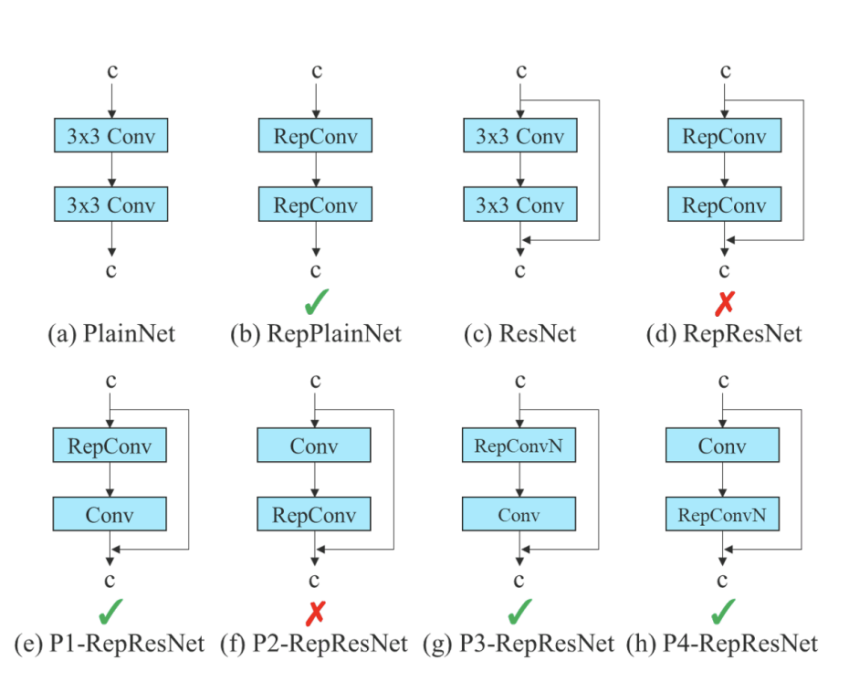
Zlex發(fā)現(xiàn)Rep的結(jié)構(gòu)策略直接用到resnet等結(jié)構(gòu)的網(wǎng)絡中達不到預期效果,分析后發(fā)現(xiàn)identity層的使用破壞了resnet的參差結(jié)構(gòu)和densenet的級聯(lián)結(jié)構(gòu),因此去掉identity層,采用如下圖(g和h)的結(jié)構(gòu)方式有效。
03
Yolov7工業(yè)應用領(lǐng)域的改善空間
俗話說,極致的項目一般是“既要,也要,還要”的模式——既要推理速度快!也要推理精度高!還要訓練速度也不能太慢!
Yolov7無疑是吸收了很多仙氣修煉成的佳作,但也存在些許缺點,這些缺點也是該設計本質(zhì)性的東西,Yolov7的訓練速度經(jīng)過Zlex親測,比其他yolo系列慢了很多。對于資源有限型的AI愛好者也形成了一定的障礙,單元時間可以跑的實驗次數(shù)少了很多,驗證一些想法的節(jié)奏也慢了很多。
Yolov7給博世工業(yè)檢測、自動駕駛、數(shù)字化等領(lǐng)域又注入了新的超能力,應用過程中也會發(fā)現(xiàn)這樣或者那樣的問題,比方說訓練資源有限,速度跟不上項目的節(jié)奏,能力提升的trick不夠適應自己的應用場景,小數(shù)據(jù)訓練效果不佳,不同平臺的移植工作量大等等,需要我們博世工程師在適配、融合和改進的路上堅定的前進。
審核編輯 :李倩
-
模型
+關(guān)注
關(guān)注
1文章
3751瀏覽量
52097 -
深度學習
+關(guān)注
關(guān)注
73文章
5598瀏覽量
124392
原文標題:博采眾長 | 在提升深度學習模型能力方面的那些魔鬼細節(jié):模型結(jié)構(gòu)重參化
文章出處:【微信號:rbacinternalevents,微信公眾號:博世蘇州】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
是德科技與聯(lián)發(fā)科技聯(lián)合完成一項工作原型驗證
使用ROCm?優(yōu)化并部署YOLOv8模型
單板挑戰(zhàn)4路YOLOv8!米爾瑞芯微RK3576開發(fā)板性能實測
基于瑞芯微RK3576的 yolov5訓練部署教程

知行科技機器人業(yè)務新獲一項合作
在K230中,如何使用AI Demo中的object_detect_yolov8n,YOLOV8多目標檢測模型?
請問yolov8訓練模型如何寫雙線程?
yolov5訓練部署全鏈路教程

如何提高yolov8模型在k230上運行的幀率?
RV1126 yolov8訓練部署教程



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論