Linux內核內存分配
Linux系統使用了一種稱為“虛擬內存”的機制。虛擬內存機制使得每個內存地址都是虛擬的,這意味著它們不會直接指向RAM中的任何地址。這樣我們訪問內存中的存儲單元時,都會進行地址轉換以匹配相應的物理內存
在Linux系統中,內核中的每個進程都表示為一個task_struct結構體實例,該結構體實例表征并描述了這個進程。在進程開始運行之前,系統會為其分配一個內存映射表,該表存放在struct mm_struct類型的變量中。在內核中,全局變量current時鐘指向當前進程,current->mm字段指向當前的進程內存映射表,struct mm_struct結構定義參見include/linux/mm_types.h
地址轉換和MMU
MMU不僅可以將虛擬地址轉換為物理地址,還可以保護內存免受未經授權的訪問。給定一個進程,需要從此進程訪問的任何頁都必須位于一個VMA中,且必須位于進程的頁表中
由于最近訪問的數據存放在緩存中,因此最近轉換的地址也存放在緩存中。數據緩存加快了數據訪問過程,TLB則加快了虛擬地址的轉換過程。TLB是內容可尋址內存,其中鍵是虛擬地址,值是物理地址,其運作過程如下圖所示
內存分配機制
下圖展示了Linux系統中不同的內存分配器。最低級別的分配器是頁分配器,它以頁為單位分配內存,然后是Slab分配器,它建立在頁分配器的基礎上,從中獲取頁并將它們拆分為較小的內存實體,kmalloc分配器依賴于Slab分配器
實現DMA支持
DMA是計算機系統的一種特性,它允許設備在沒有CPU干預的情況下訪問主系統內存,使CPU嫩鞏固專注于其他任務。它的使用示例包括網絡流量加速、音頻數據或視頻幀抓取等,它的使用并不限于特定領域。負責管理DMA事務的外圍設備是DMA控制器,它存在于大多數現代處理器和微控制器中。
DMA的工作方式如下:當驅動程序需要傳輸數據塊時,便使用源地址、目標地址和要復制的總字節數設置DMA控制器,然后DMA控制器自動將數據地址從源地址傳輸到目標地址,而不會占用CPU周期。當剩余字節數為0時,數據塊傳輸結束并通知驅動程序。
DMA引擎API
DMA控制器接口由兩部分組成:控制器和通道。控制器執行內存傳輸,通道則是客戶端驅動程序向控制器提交作業的方式
DMA控制器在Linux內核中別抽象為dma_device結構體實例,其定義如下
struct dma_device {
struct kref ref;
unsigned int chancnt;
unsigned int privatecnt;
struct list_head channels;
struct list_head global_node;
struct dma_filter filter;
dma_cap_mask_tcap_mask;
enum dma_desc_metadata_mode desc_metadata_modes;
unsigned short max_xor;
unsigned short max_pq;
enum dmaengine_alignment copy_align;
enum dmaengine_alignment xor_align;
enum dmaengine_alignment pq_align;
enum dmaengine_alignment fill_align;
#define DMA_HAS_PQ_CONTINUE (1 << 15)
int dev_id;
struct device *dev;
struct module *owner;
struct ida chan_ida;
u32 src_addr_widths;
u32 dst_addr_widths;
u32 directions;
u32 min_burst;
u32 max_burst;
u32 max_sg_burst;
bool descriptor_reuse;
enum dma_residue_granularity residue_granularity;
int (*device_alloc_chan_resources)(struct dma_chan *chan);
int (*device_router_config)(struct dma_chan *chan);
void (*device_free_chan_resources)(struct dma_chan *chan);
struct dma_async_tx_descriptor *(*device_prep_dma_memcpy)(
struct dma_chan *chan, dma_addr_t dst, dma_addr_t src,
size_t len, unsigned long flags);
struct dma_async_tx_descriptor *(*device_prep_dma_xor)(
struct dma_chan *chan, dma_addr_t dst, dma_addr_t *src,
unsigned int src_cnt, size_t len, unsigned long flags);
struct dma_async_tx_descriptor *(*device_prep_dma_xor_val)(
struct dma_chan *chan, dma_addr_t *src,unsigned int src_cnt,
size_t len, enum sum_check_flags *result, unsigned long flags);
struct dma_async_tx_descriptor *(*device_prep_dma_pq)(
struct dma_chan *chan, dma_addr_t *dst, dma_addr_t *src,
unsigned int src_cnt, const unsigned char *scf,
size_t len, unsigned long flags);
struct dma_async_tx_descriptor *(*device_prep_dma_pq_val)(
struct dma_chan *chan, dma_addr_t *pq, dma_addr_t *src,
unsigned int src_cnt, const unsigned char *scf, size_t len,
enum sum_check_flags *pqres, unsigned long flags);
struct dma_async_tx_descriptor *(*device_prep_dma_memset)(
struct dma_chan *chan, dma_addr_t dest, int value, size_t len,
unsigned long flags);
struct dma_async_tx_descriptor *(*device_prep_dma_memset_sg)(
struct dma_chan *chan, struct scatterlist *sg,
unsigned int nents, int value, unsigned long flags);
struct dma_async_tx_descriptor *(*device_prep_dma_interrupt)(
struct dma_chan *chan, unsigned long flags);
struct dma_async_tx_descriptor *(*device_prep_slave_sg)(
struct dma_chan *chan, struct scatterlist *sgl,
unsigned int sg_len, enum dma_transfer_direction direction,
unsigned long flags, void *context);
struct dma_async_tx_descriptor *(*device_prep_dma_cyclic)(
struct dma_chan *chan, dma_addr_t buf_addr, size_t buf_len,
size_t period_len, enum dma_transfer_direction direction,
unsigned long flags);
struct dma_async_tx_descriptor *(*device_prep_interleaved_dma)(
struct dma_chan *chan, struct dma_interleaved_template *xt,
unsigned long flags);
struct dma_async_tx_descriptor *(*device_prep_dma_imm_data)(
struct dma_chan *chan, dma_addr_t dst, u64 data,
unsigned long flags);
void (*device_caps)(struct dma_chan *chan,
struct dma_slave_caps *caps);
int (*device_config)(struct dma_chan *chan,
struct dma_slave_config *config);
int (*device_pause)(struct dma_chan *chan);
int (*device_resume)(struct dma_chan *chan);
int (*device_terminate_all)(struct dma_chan *chan);
void (*device_synchronize)(struct dma_chan *chan);
enum dma_status (*device_tx_status)(struct dma_chan *chan,
dma_cookie_t cookie,
struct dma_tx_state *txstate);
void (*device_issue_pending)(struct dma_chan *chan);
void (*device_release)(struct dma_device *dev);
/* debugfs support */
void (*dbg_summary_show)(struct seq_file *s, struct dma_device *dev);
struct dentry *dbg_dev_root;
};
DMA通道的結構體定義如下
struct dma_chan {
int dev_id;/* this channel is allocated if >= 0, */
/* free otherwise */
void __iomem *io;
const char *dev_str;
int irq;
void *irq_dev;
unsigned int fifo_addr;
unsigned int mode;
};
請求DMA通道
dma_request_channel()函數用于請求一個通道
struct dma_chan *dma_request_channel(dma_cap_mask_t mask,
dma_filter_fn filter_fn,
void *filter_param);
配置DMA通道
DMA引擎框架使用struct dma_slave_config數據結構進行配置,該數據結構表示DMA通道的運行時配置,這樣客戶端就可以指定諸如DMA方向、DMA地址、總線寬度和DMA突發成都等外設的參數,struct dma_slave_config數據結構定義如下
struct dma_slave_config {
enum dma_transfer_direction direction;
phys_addr_t src_addr;
phys_addr_t dst_addr;
enum dma_slave_buswidth src_addr_width;
enum dma_slave_buswidth dst_addr_width;
u32 src_maxburst;
u32 dst_maxburst;
u32 src_port_window_size;
u32 dst_port_window_size;
bool device_fc;
void *peripheral_config;
size_t peripheral_size;
};
通過dmaengine_slave_config()函數將這種配置作用于底層硬件上
static inline int dmaengine_slave_config(struct dma_chan *chan,
struct dma_slave_config *config)
{
if (chan->device->device_config)
return chan->device->device_config(chan, config);
return -ENOSYS;
}
配置DMA傳輸
這一步用于確認DMA傳輸的方式,要進行一次DMA傳輸,就需要用到與DMA通道對應的控制器中的一些函數,這些函數名為device_prep_dma_*,例如對于內存到內存的傳輸,使用device_prep_dma_memcpy()
struct dma_async_tx_descriptor *tx;
struct dma_chan *chan = acdev->dma_chan;
dma_cookie_t cookie;
unsigned long flags = DMA_PREP_INTERRUPT;
int ret = 0;
tx = chan->device->device_prep_dma_memcpy(chan, dest, src, len, flags);
if (!tx) {
dev_err(acdev->host->dev, \"device_prep_dma_memcpy failed\\\\n\");
return -EAGAIN;
}
提交DMA傳輸
為了把事務放到驅動程序的事務待處理隊列中,可以使用dmaengine_submit()函數
static inline dma_cookie_t dmaengine_submit(struct dma_async_tx_descriptor *desc)
{
return desc->tx_submit(desc);
}
發出待處理的DMA請求并等待回調通知
啟動傳輸是DMA傳輸設置的最后一步,可以通過在通道上調用dma_async_issue_pending()來激活通道待處理隊列中的傳輸。
static inline void dma_async_issue_pending(struct dma_chan *chan)
{
chan->device->device_issue_pending(chan);
}
發表于 02-04 22:30
在汽車電子系統中,如何充分發揮 GTM IP的功能,以滿足復雜的系統級應用場景,是用戶實現高效控制與精確響應的關鍵。本文將聚焦幾個典型且核心的應用實例,探討GTM IP在車載系統中的具體實現方式與優勢。
![的頭像]() 發表于
發表于 12-30 17:36
?701次閱讀
12月22日,云天勵飛與360集團簽署戰略合作協議。雙方將圍繞“納米AI”算力底座建設、大模型安全能力提升以及智慧生活產品打造等方向,充分發揮各自在資源、場景與技術方面的優勢,聯合打造國產生態下的AI推理協同生態。
![的頭像]() 發表于
發表于 12-25 17:09
?519次閱讀
近日,經緯恒潤與長春富維海拉車燈有限公司(以下簡稱“富維海拉”)順利完成戰略合作協議簽約。未來,雙方將充分發揮各自在車載智能燈光領域的互補優勢和資源,共同推動創新燈光解決方案在智能汽車領域
![的頭像]() 發表于
發表于 07-15 17:08
?732次閱讀

百度將充分發揮技術優勢,進一步加大在遼投資布局力度,深化人工智能大模型、企業數字化轉型、數字政府建設等領域合作,帶動更多同業伙伴走進遼寧、深耕遼寧,為遼寧產業轉型升級、經濟社會高質量發展貢獻力量。
![的頭像]() 發表于
發表于 07-15 10:35
?919次閱讀
的優勢,如高效、徹底、節能、環保等。本文將重點介紹非標超聲波清洗設備的最大優勢以及如何充分發揮其特點。一、高效清洗非標超聲波清洗設備通過高頻聲波的作用,能夠在短時
![的頭像]() 發表于
發表于 07-08 16:58
?627次閱讀

近日,江西贛鋒鋰電科技股份有限公司(簡稱“贛鋒鋰電”)與江西龍源新能源有限公司(簡稱“江西龍源”)正式簽署戰略合作協議。此次聯手,雙方將充分發揮各自優勢,深度布局新能源項目開發,為新能源產業發展注入新活力。
![的頭像]() 發表于
發表于 07-05 16:19
?1435次閱讀
(文章來自CRDE PDM研究中心) 摘要 PDM是制造企業產品數據管理的核心工具,并逐漸發展出了PLM、云PLM等新形態,在功能增加的同時成本也有大幅降低,已經成為企業研發管理的最優選擇,并逐漸被
![的頭像]() 發表于
發表于 06-19 17:46
?2082次閱讀
,使得其響應速度較慢,無法充分發揮NVMe SSD的速度優勢。若想要在嵌入式系統中充分發揮NVMe協議的高速讀寫性能,一方面可以通過優化軟件執行流程,來提高傳輸性能,但嵌入式處理器的性能較低,性能提升
發表于 06-02 23:28
中小企業選擇云MES實現數字化轉型是順應時代發展的必然選擇。通過充分發揮云MES系統的優勢,結合企業自身實際情況,科學規劃、穩步實施,中小企業能夠在激烈的市場競爭中提升競爭力,實現可持續發展。
![的頭像]() 發表于
發表于 05-06 14:51
?646次閱讀
在選型M12航空插座時,需綜合考慮環境適應性與耐用性等多方面因素。德索精密工業豐富的產品型號與先進技術,能夠滿足不同使用環境與插拔頻次要求。只有精準匹配德索的產品,才能充分發揮M12航空插座的性能優勢,保障設備長期穩定運行。
![的頭像]() 發表于
發表于 04-12 09:35
?726次閱讀

面對多樣化的市場需求,MCX 連接器充分發揮自身優勢,為不同行業量身定制適配的解決方案。展望未來,隨著科技的持續創新與進步,MCX 連接器必將繼續在各個領域發揮重要作用,以其可靠的性能為科技發展注入強勁動力,推動各行業邁向新的高
![的頭像]() 發表于
發表于 04-02 13:54
?707次閱讀
近日,蘿卜快跑宣布與阿聯酋自動駕駛出行公司Autogo達成戰略合作,雙方將充分發揮各自優勢,共同為阿布扎比提供安全、綠色、高效的無人駕駛出行服務。這是蘿卜快跑在中東市場的進一步拓展。
![的頭像]() 發表于
發表于 04-01 14:29
?897次閱讀
學習如何通過優化PCB布局來充分發揮HT4088電源管理芯片的性能和穩定性。
![的頭像]() 發表于
發表于 03-08 15:09
?1513次閱讀
為滿足客戶對電子設備日益增長的功率和功能的期望,連接器的小型化發揮了關鍵作用。然而,尺寸縮減絕不能以犧牲產品的耐用性為代價。材料科學在開發堅固耐用小型連接器中至關重要,使其即使在嚴苛環境中也能保持
發表于 03-07 11:28
?683次閱讀
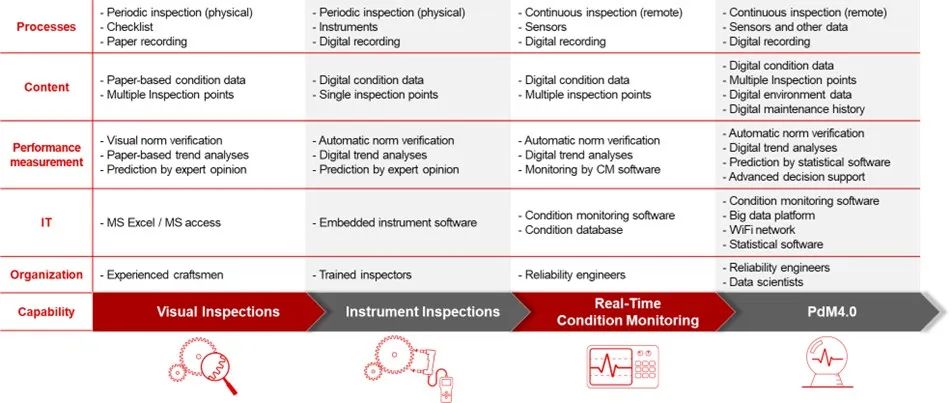
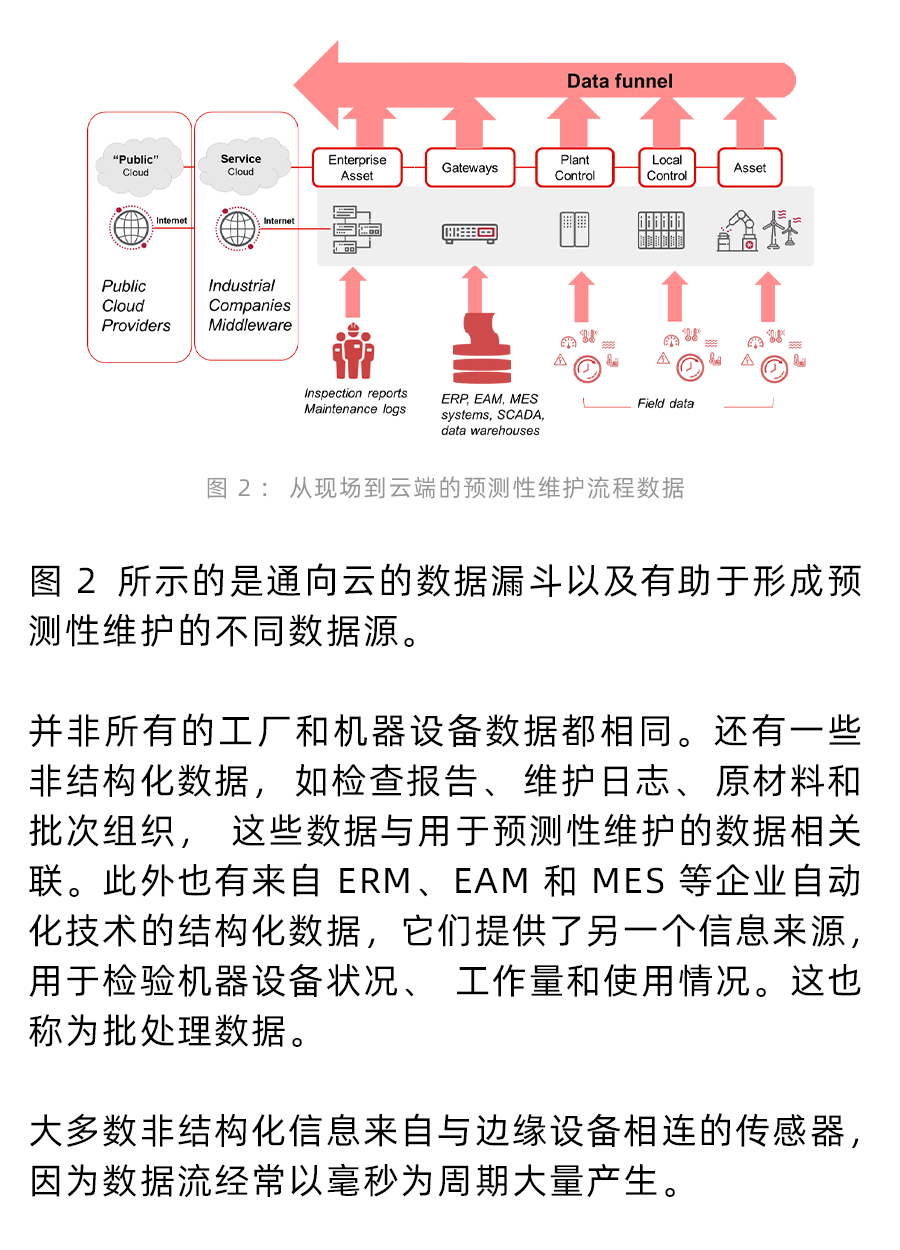
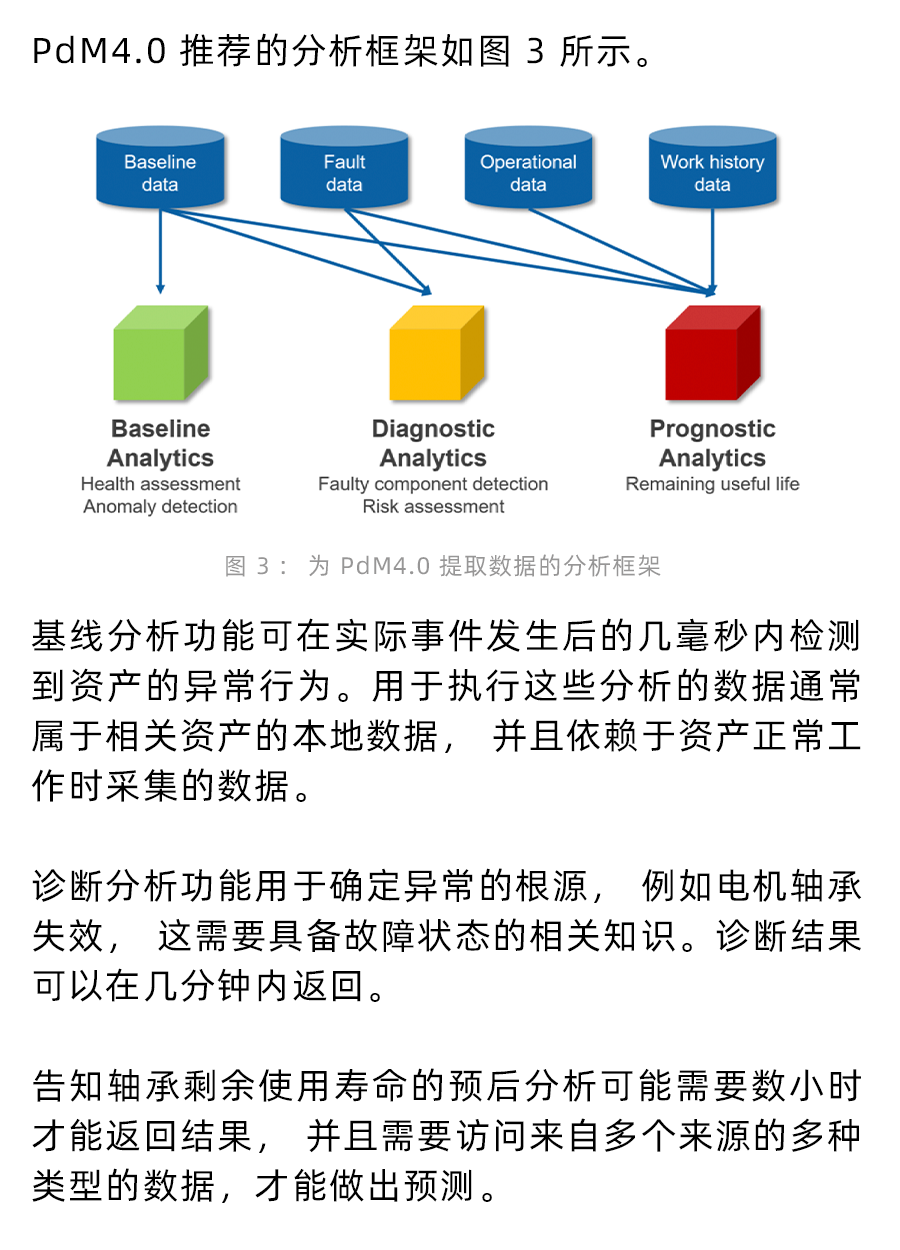
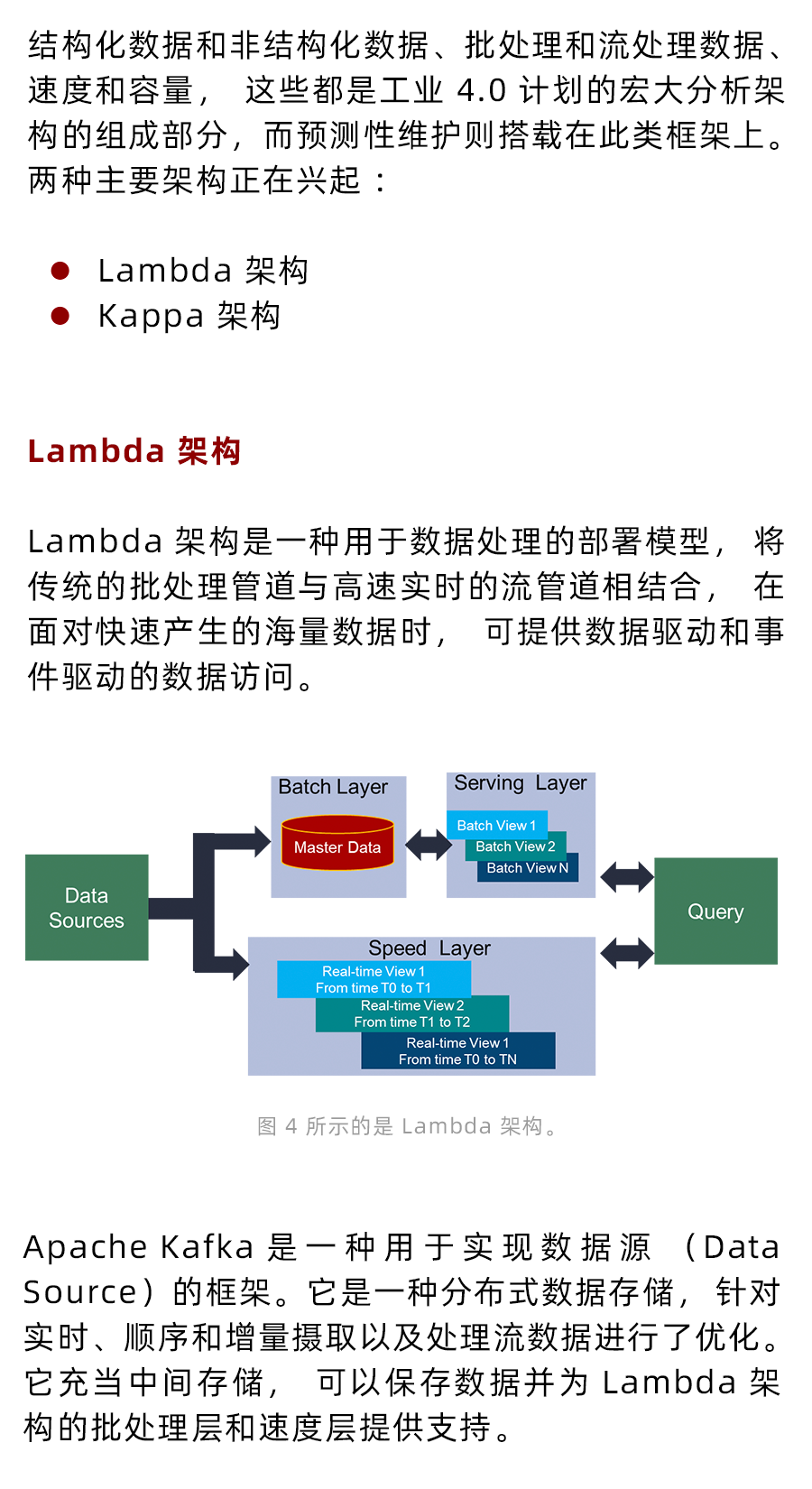
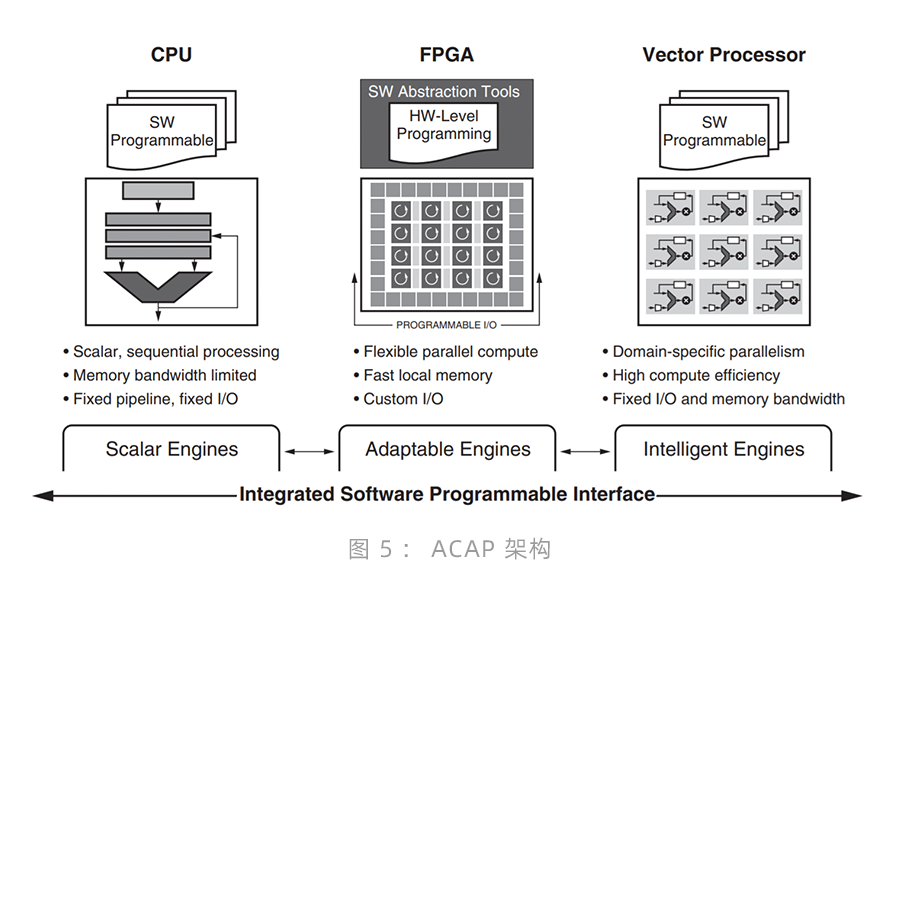
 如何充分發揮PHM和PdM4.0的優勢?
如何充分發揮PHM和PdM4.0的優勢?









 工商網監
工商網監
評論