") 邏輯推理MRC的兩個(gè)數(shù)據(jù)集和對(duì)應(yīng)方法
邏輯推理MRC的兩個(gè)數(shù)據(jù)集和對(duì)應(yīng)方法

1.背景
機(jī)器閱讀理解(Machine Reading Comprehension, MRC)作為自然語(yǔ)言處理領(lǐng)域中的一個(gè)基本任務(wù),要求模型就給定的一段文本和與文本相關(guān)的問題進(jìn)行作答。正如同我們使用閱讀理解測(cè)驗(yàn)來(lái)評(píng)估人類對(duì)于一段文本的理解程度一樣,閱讀理解同樣可以用來(lái)評(píng)估一個(gè)計(jì)算機(jī)系統(tǒng)對(duì)于人類語(yǔ)言的理解程度。近年來(lái),隨著預(yù)訓(xùn)練語(yǔ)言模型在NLP領(lǐng)域的成功,許多預(yù)訓(xùn)練語(yǔ)言模型在流行的MRC數(shù)據(jù)集上的表現(xiàn)達(dá)到甚至超過了人類,例如:BERT、RoBERTa、XLNet、GPT3等。因此,為了促進(jìn)更深層次的語(yǔ)言理解,許多更加具有挑戰(zhàn)的MRC數(shù)據(jù)集被提出,它們從不同的角度考察模型能力,例如:多文檔證據(jù)整合能力[1]、離散數(shù)值推理能力[2]、常識(shí)推理能力[3]等。
邏輯推理(Logical Reasoning)指對(duì)于日常語(yǔ)言中的論點(diǎn)進(jìn)行檢查、分析和批判性評(píng)價(jià)的能力,其是人類智能的關(guān)鍵組成部分,在談判、辯論、寫作等場(chǎng)景中發(fā)揮著重要作用。然而,流行的MRC數(shù)據(jù)集中沒有或僅有很少的數(shù)據(jù)考察邏輯推理能力,例如,根據(jù)Sugawara和Aizawa[4]的研究,MCTest數(shù)據(jù)集中0%的數(shù)據(jù)和SQuAD中1.2%的數(shù)據(jù)需要邏輯推理能力作答。因此,ReClor[5]和LogiQA[6]這兩個(gè)側(cè)重考察邏輯推理能力的MRC數(shù)據(jù)集被提出。與邏輯推理MRC任務(wù)相關(guān)的一個(gè)任務(wù)是自然語(yǔ)言推理(Natural Language Inference, NLI),其要求模型對(duì)給定句對(duì)的邏輯關(guān)系分類,NLI任務(wù)僅僅考慮了句子級(jí)別的三種簡(jiǎn)單的邏輯關(guān)系(蘊(yùn)含、矛盾、無(wú)關(guān)),而邏輯推理MRC需要綜合篇章級(jí)別的多種復(fù)雜邏輯關(guān)系預(yù)測(cè)答案,因此更加具有挑戰(zhàn)性。
本文介紹了目前邏輯推理MRC的兩個(gè)數(shù)據(jù)集和對(duì)應(yīng)方法。
2.數(shù)據(jù)集簡(jiǎn)介
2.1 LogiQA
LogiQA[5]是一個(gè)四選一的單項(xiàng)選擇問答數(shù)據(jù)集,針對(duì)輸入的問題、篇章和四個(gè)選項(xiàng),模型需要根據(jù)問題和篇章找出唯一正確的選項(xiàng)作為答案。LogiQA的數(shù)據(jù)來(lái)自于中國(guó)的國(guó)家公務(wù)員考試題目,其旨在考察公務(wù)員候選人的批判性思維和解決問題的能力。原始數(shù)據(jù)經(jīng)過篩選、過濾后得到8678條數(shù)據(jù),這些數(shù)據(jù)被五名專業(yè)的英文使用者由中文翻譯到英文,數(shù)據(jù)集的中文版本Chinese LogiQA也被同時(shí)發(fā)布。LogiQA的例子如圖1所示,這些數(shù)據(jù)按照81的比例隨機(jī)劃分為訓(xùn)練集、開發(fā)集和測(cè)試集。
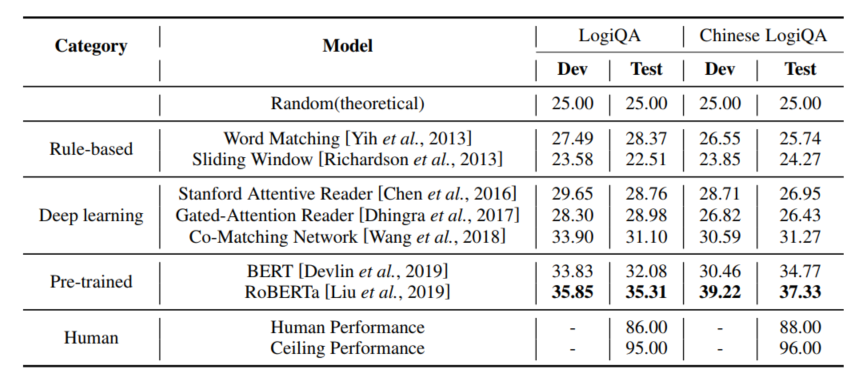
作者評(píng)估了基于規(guī)則的方法、深度學(xué)習(xí)方法以及基于預(yù)訓(xùn)練語(yǔ)言模型的方法在LogiQA上的表現(xiàn),實(shí)驗(yàn)結(jié)果如表1所示,可以看到人類(研究生)在LogiQA上可以取得86%的平均準(zhǔn)確率,這說明該數(shù)據(jù)集的難度對(duì)于人類受試者來(lái)說并不高,而另一方面,被測(cè)試的所有方法的表現(xiàn)均顯著低于人類,即便是表現(xiàn)最好的RoBERTa模型也僅能取得35.31%的準(zhǔn)確率,這說明目前的預(yù)訓(xùn)練語(yǔ)言模型的邏輯推理能力還相當(dāng)弱。

圖1 LogiQA中的例子(正確選項(xiàng)使用紅色標(biāo)出)
表1 各類方法在LogiQA上的實(shí)驗(yàn)結(jié)果(accuracy%)
2.2 ReClor
ReClor[6]與LogiQA一樣,是一個(gè)四選一的單項(xiàng)選擇問答數(shù)據(jù)集,其來(lái)自于美國(guó)的兩個(gè)標(biāo)準(zhǔn)化研究生入學(xué)考試:研究生管理科入學(xué)考試(GMAT)和法學(xué)院入學(xué)考試(LSAT),經(jīng)過篩選、過濾得到6138條考察邏輯推理能力的數(shù)據(jù),這些數(shù)據(jù)被隨機(jī)劃分為4638,500,1000條來(lái)分別用作訓(xùn)練集、開發(fā)集和測(cè)試集。ReClor數(shù)據(jù)集的一個(gè)具體例子如圖2所示,可以看到只有基于篇章、問題和選項(xiàng)進(jìn)行邏輯推理和分析才能得到正確的答案。
正如上面介紹的那樣,ReClor來(lái)自側(cè)重考察邏輯推理的考試,由人類的專家構(gòu)建,這意味著biases有可能被引入,這導(dǎo)致模型可能無(wú)需真正理解文本,僅僅利用這些biases就可以在任務(wù)上取得很好的表現(xiàn)。而將這些biased數(shù)據(jù)與unbiased數(shù)據(jù)區(qū)分開可以更加全面的評(píng)價(jià)模型在ReClor上的表現(xiàn)。為此,作者去除掉問題和篇章,僅僅將選項(xiàng)作為預(yù)訓(xùn)練語(yǔ)言模型的輸入,如果模型僅僅依賴選項(xiàng)就可以成功預(yù)測(cè)出正確選項(xiàng),那么這樣的biased數(shù)據(jù)就被歸為EASY-SET,其余數(shù)據(jù)被歸為HARD-SET,這樣,ReClor的測(cè)試集被分為了EASY-SET和HARD-SET兩部分。
作者在ReClor的EASY-SET和HARD-SET上分別評(píng)估了預(yù)訓(xùn)練語(yǔ)言模型和人類的表現(xiàn),實(shí)驗(yàn)結(jié)果如圖3所示,實(shí)驗(yàn)結(jié)果顯示:預(yù)訓(xùn)練語(yǔ)言模型在EASY-SET上可以取得很好的表現(xiàn),但是在HARD-SET上表現(xiàn)很差,而人類則在兩個(gè)集合上取得了相當(dāng)?shù)谋憩F(xiàn),這說明目前的模型雖然擅長(zhǎng)利用數(shù)據(jù)集中存在的biases,但是還遠(yuǎn)遠(yuǎn)做不到真正的邏輯推理。

圖2 ReClor中的一個(gè)例子(修改自2019年的LSAT)
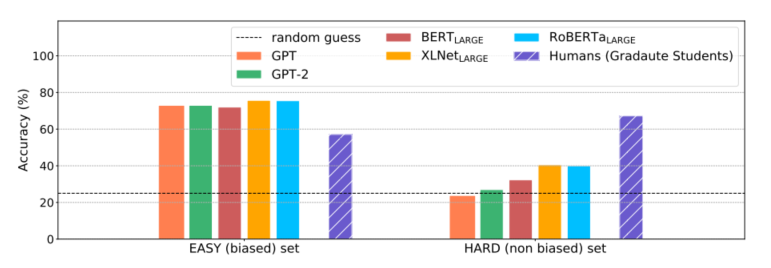
圖3 預(yù)訓(xùn)練語(yǔ)言模型與人類(研究生)在ReClor測(cè)試集的EASY-SET和HARD-SET上的表現(xiàn)對(duì)比
3.方法
下面將介紹幾篇近兩年邏輯推理MRC的相關(guān)工作,目前的已有方法可以大致分為兩類:一類方法是利用預(yù)定義的規(guī)則基于篇章、選項(xiàng)構(gòu)建圖結(jié)構(gòu),圖中節(jié)點(diǎn)對(duì)應(yīng)文本中的邏輯單元(這里的邏輯單元指有意義的句子、從句或文本片段),而圖中的邊則表示邏輯單元間的關(guān)系,然后利用GNN、Graph Transformer等方法建模邏輯推理過程,從而增強(qiáng)模型的邏輯推理能力。另一類則是從預(yù)訓(xùn)練角度出發(fā),基于一些啟發(fā)式規(guī)則捕捉大規(guī)模文本語(yǔ)料中存在的邏輯關(guān)系,針對(duì)其設(shè)計(jì)相應(yīng)的預(yù)訓(xùn)練任務(wù),對(duì)已有的預(yù)訓(xùn)練語(yǔ)言模型進(jìn)行二次預(yù)訓(xùn)練,從而增強(qiáng)預(yù)訓(xùn)練語(yǔ)言模型的邏輯推理能力。
3.1 基于圖的精調(diào)方法
3.1.1 DAGN
針對(duì)邏輯推理MRC篇章中復(fù)雜的邏輯關(guān)系,僅僅關(guān)注句子級(jí)別tokens之間的交互是不夠的,需要在篇章級(jí)別對(duì)句子之間的關(guān)系進(jìn)行建模。但是邏輯結(jié)構(gòu)隱式存在與文本中,難以直接抽取,大多數(shù)數(shù)據(jù)集也并不包含對(duì)文本中邏輯結(jié)構(gòu)的標(biāo)注。因此,DAGN提出使用語(yǔ)篇關(guān)系(discourse relation)來(lái)表示文本中的邏輯信息,語(yǔ)篇關(guān)系分為顯式和隱式兩類,顯式語(yǔ)篇關(guān)系指文本中的語(yǔ)篇狀語(yǔ)(如“instead”)、從屬連詞(如“because”),而隱式語(yǔ)篇關(guān)系則指連接文本片段的標(biāo)點(diǎn)符號(hào)(句號(hào)、逗號(hào)、分號(hào)等)。語(yǔ)篇關(guān)系一定程度上對(duì)應(yīng)著文本中的邏輯關(guān)系,例如:“because”指示因果關(guān)系,“if”指示假設(shè)關(guān)系等。
DAGN[7]使用來(lái)自PDTB2.0[8]中的語(yǔ)篇關(guān)系中作為分隔符,將文本劃分為多個(gè)基本語(yǔ)篇單元(Elementary Discourse Units, EDUs),以EDUs作為節(jié)點(diǎn)、EDUs間的語(yǔ)篇關(guān)系作為邊就得到了語(yǔ)篇圖結(jié)構(gòu),語(yǔ)篇圖的構(gòu)建過程實(shí)例如圖4的左半部分所示。然后,作者利用圖網(wǎng)絡(luò)來(lái)從語(yǔ)篇圖中學(xué)習(xí)篇章的語(yǔ)篇特征,該特征與由預(yù)訓(xùn)練語(yǔ)言模型得到的上下文表示合并,共同預(yù)測(cè)問題的答案。
DAGN使用EDUs作為基本的推理單元,利用學(xué)習(xí)得到的基于語(yǔ)篇的特征增強(qiáng)預(yù)訓(xùn)練語(yǔ)言模型上下文表示,在ReClor和LogiQA兩個(gè)數(shù)據(jù)集上取得了有競(jìng)爭(zhēng)力的表現(xiàn)。
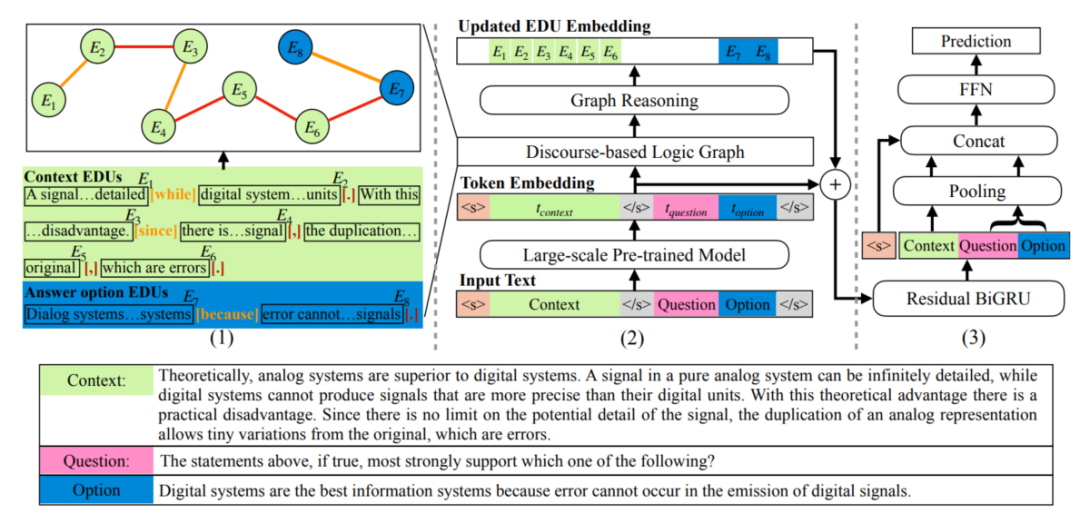
圖4 DAGN結(jié)構(gòu)
3.1.2 AdaLoGN
傳統(tǒng)的神經(jīng)模型無(wú)法很好地建模邏輯推理,而能夠進(jìn)行邏輯推理的符號(hào)推理器卻無(wú)法直接應(yīng)用于文本。同時(shí),前面介紹的DAGN模型雖然基于語(yǔ)篇關(guān)系構(gòu)建了語(yǔ)篇圖結(jié)構(gòu),但是語(yǔ)篇關(guān)系能否充分表示基于邏輯關(guān)系的符號(hào)推理仍然有待商榷,且該圖結(jié)構(gòu)十分稀疏,由長(zhǎng)路徑組成,這限制了GNN模型中節(jié)點(diǎn)與節(jié)點(diǎn)間的消息傳遞,導(dǎo)致篇章和選項(xiàng)間的交互不夠充分。
為了解決上述挑戰(zhàn),AdaLoGN[9]這一神經(jīng)-符號(hào)方法被提出,其整體框架與DAGN類似,由圖構(gòu)建和基于圖的推理兩部分組成,區(qū)別在于采用有向的文本邏輯圖(Text Logic Graph,TLG)代替DAGN中的語(yǔ)篇圖,TLG仍然將EDUs作為節(jié)點(diǎn),邊則采用了六種預(yù)定義的邏輯關(guān)系,其中合取(conj)、析取(disj)、蘊(yùn)含(impl)、否定(neg)是命題邏輯中的標(biāo)準(zhǔn)邏輯連接詞,而rev表示反向的蘊(yùn)含關(guān)系,unk表示未知的關(guān)系。作者首先使用Graphene[10]這一信息抽取工具抽取EDUs之間的修辭關(guān)系,然后將部分修辭關(guān)系映射為邏輯關(guān)系,具體映射如表2所示。
表2 Graphene中修辭關(guān)系到TLG中邏輯關(guān)系的映射

使用TLG相比起語(yǔ)篇圖的優(yōu)勢(shì)在于可以使用符號(hào)化的推理規(guī)則對(duì)原始語(yǔ)篇圖進(jìn)行擴(kuò)展,基于已知推理得到未知的邏輯關(guān)系,AdaLoGN中作者使用的推理規(guī)則如圖5所示,包括命題邏輯中的假言三段論、置換規(guī)則以及作者自定義的一條規(guī)則。上述符號(hào)化推理過程得到的新關(guān)系可能對(duì)于后續(xù)GNN消息傳遞過程提供關(guān)鍵連接,幫助正確答案的預(yù)測(cè),即符號(hào)推理增強(qiáng)了神經(jīng)推理。而對(duì)基于推理規(guī)則得到的演繹閉包全盤接受也可能會(huì)引入不相關(guān)的連接,誤導(dǎo)后續(xù)的消息傳遞過程,因此,作者提出使用神經(jīng)推理計(jì)算得到的信號(hào)來(lái)自適應(yīng)地接納相關(guān)擴(kuò)展,即神經(jīng)推理增強(qiáng)了符號(hào)推理。
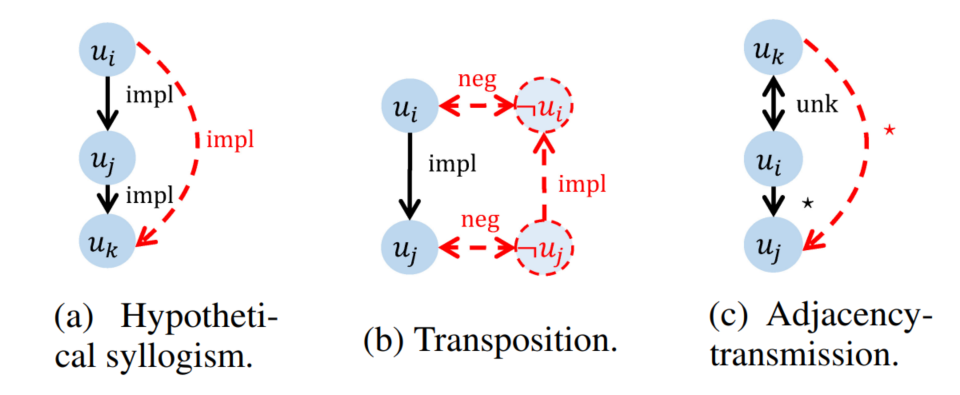
圖5 AdaLoGN中使用的推理規(guī)則,推理得到的新的節(jié)點(diǎn)與關(guān)系用紅色虛線表示
AdaLoGN的整體結(jié)構(gòu)如圖6所示,可以看到自適應(yīng)地?cái)U(kuò)展TLG、消息傳遞過程通過迭代多輪來(lái)使得符號(hào)推理和神經(jīng)推理彼此充分交互。最終每一輪得到的擴(kuò)展TLG表示和由RoBERTa得到的上下文token特征共同用于答案預(yù)測(cè)。AdaLoGN在LogiQA和ReClor數(shù)據(jù)集上取得了比DAGN更好的表現(xiàn)。
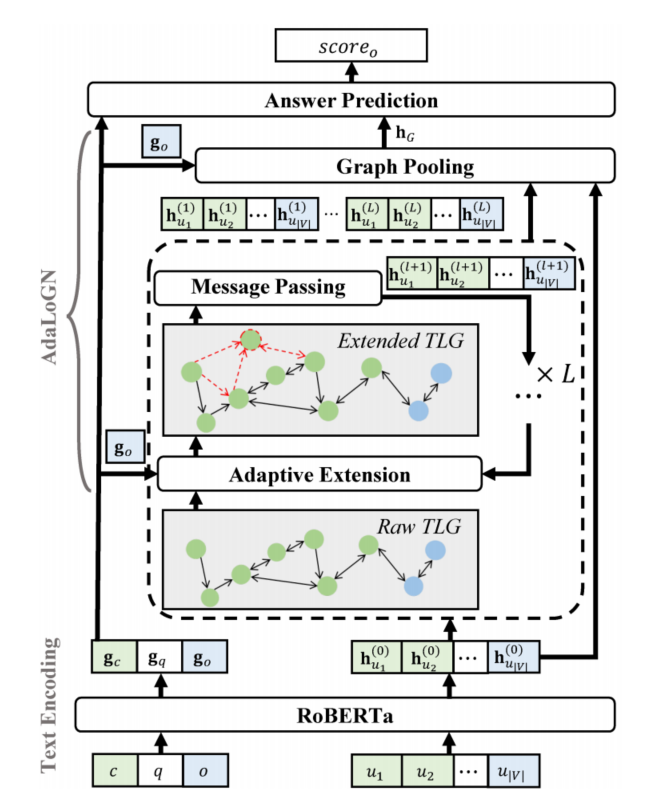
圖6 AdaLoGN結(jié)構(gòu)
3.1.3 Loigformer
Logiformer[11]的作者認(rèn)為,對(duì)于邏輯推理MRC任務(wù)來(lái)說,除了需要從文本中抽取邏輯單元外,還需要對(duì)邏輯單元間的長(zhǎng)距離依賴進(jìn)行建模,如圖7中展示的一個(gè)來(lái)自ReClor數(shù)據(jù)集的具體例子,從中可以看到因果關(guān)系與否定、共現(xiàn)關(guān)系普遍存在于邏輯推理任務(wù)中,針對(duì)這一點(diǎn),作者提出基于篇章分別構(gòu)建邏輯圖和句法圖,對(duì)上述的因果關(guān)系以及共現(xiàn)關(guān)系分別進(jìn)行表示,然后使用一個(gè)兩支的graph transformer網(wǎng)絡(luò)來(lái)從兩個(gè)角度建模長(zhǎng)距離依賴。

圖7 來(lái)自ReClor的具體例子及上下文中邏輯單元間的關(guān)系
Logiformer的結(jié)構(gòu)如圖8所示,與之前的方法類似其首先基于文本中表示因果關(guān)系的邏輯單詞(如:if、unless、because等)以及標(biāo)點(diǎn)符號(hào)構(gòu)建邏輯圖,并基于因果關(guān)系為條件節(jié)點(diǎn)到結(jié)果節(jié)點(diǎn)間插入邊。句法圖則以文本中的句子作為節(jié)點(diǎn),然后基于句子之間的token級(jí)別的重疊度來(lái)判斷句子之間的共現(xiàn)關(guān)系,為具有共現(xiàn)關(guān)系的節(jié)點(diǎn)插入邊。接著,作者使用兩個(gè)獨(dú)立的graph transformer分別對(duì)邏輯圖和句法圖中的依賴關(guān)系進(jìn)行建模,并通過將圖對(duì)應(yīng)的鄰接矩陣引入attention計(jì)算過程從而將圖的結(jié)構(gòu)信息引入。邏輯圖的graph transformer示意圖如圖9所示。最后使用得到的token級(jí)別表示、句法節(jié)點(diǎn)表示和邏輯節(jié)點(diǎn)表示共同預(yù)測(cè)答案。Logiformer在LogiQA和ReClor數(shù)據(jù)集上取得了目前單模型的SOTA表現(xiàn)。
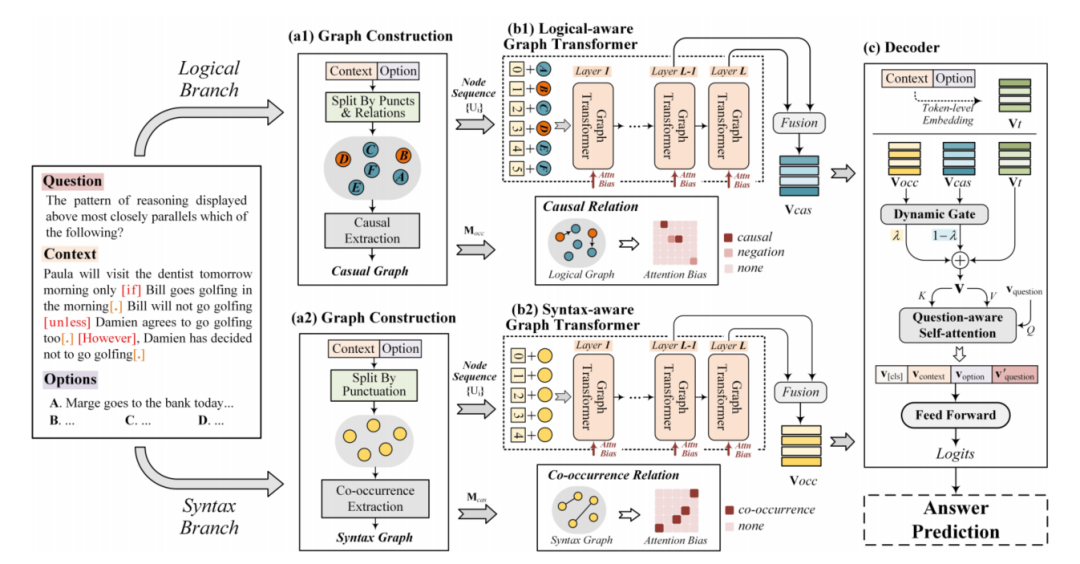
圖8 Logiformer結(jié)構(gòu)
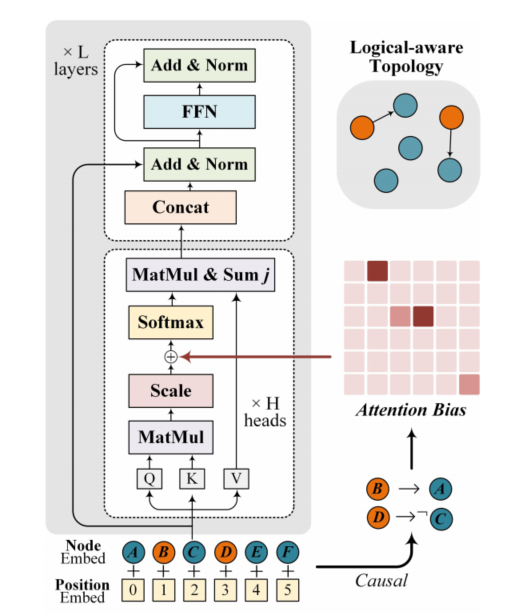
圖9 邏輯圖對(duì)應(yīng)的graph transformer示意圖(句法圖對(duì)應(yīng)的計(jì)算過程類似)
3.2 預(yù)訓(xùn)練方法
3.2.1 MERIt
3.1節(jié)中介紹的基于圖的方法將關(guān)于邏輯關(guān)系的先驗(yàn)知識(shí)引入模型,依賴于標(biāo)注好的訓(xùn)練數(shù)據(jù),導(dǎo)致其在標(biāo)注數(shù)據(jù)不足的情況下存在過擬合以及泛化性差的問題。MERIt[12]提出利用規(guī)則基于大量無(wú)標(biāo)簽的文本數(shù)據(jù)仿照邏輯推理MRC任務(wù)形式構(gòu)造用于對(duì)比學(xué)習(xí)自監(jiān)督預(yù)訓(xùn)練的數(shù)據(jù),MERIt整體框架如圖10所示,其主要基于這樣一個(gè)直覺:文本中邏輯結(jié)構(gòu)可以被由一系列關(guān)系三元組構(gòu)成的推理路徑表示,而實(shí)體之間的元路徑(meta-path)先天地提供了表示邏輯一致性的手段。
MERIt的目標(biāo)是基于大規(guī)模無(wú)標(biāo)簽文本,構(gòu)建上下文和選項(xiàng),正確選項(xiàng)應(yīng)當(dāng)與上下文邏輯一致,而錯(cuò)誤選項(xiàng)與上下文邏輯相悖,模型借助對(duì)比學(xué)習(xí)作為預(yù)訓(xùn)練目標(biāo)。MERIt首先識(shí)別文本中的實(shí)體,并基于實(shí)體在文本中的共現(xiàn)關(guān)系構(gòu)建圖,對(duì)于該圖結(jié)構(gòu)中直接相鄰任意兩個(gè)節(jié)點(diǎn),如果它們之間具有其他元路徑,則將該節(jié)點(diǎn)這兩個(gè)節(jié)點(diǎn)之間的邊對(duì)應(yīng)的句子作為正確選項(xiàng),將元路徑上邊對(duì)應(yīng)的句子作為上下文,這樣就得到了正例。負(fù)例的構(gòu)建則是通過對(duì)已有正例進(jìn)行修改完成的,為了防止模型在預(yù)訓(xùn)練過程中基于自身掌握的常識(shí)知識(shí)而非邏輯一致性做出判斷,作者還采用了反事實(shí)的數(shù)據(jù)增強(qiáng)對(duì)文本中的實(shí)體進(jìn)行替換,迫使模型基于邏輯進(jìn)行預(yù)測(cè)。基于MERIt構(gòu)造的數(shù)據(jù)二次預(yù)訓(xùn)練得到的模型在下游任務(wù)上取得了相較于原預(yù)訓(xùn)練模型更好的表現(xiàn),且模型可以與3.1節(jié)中的方法同時(shí)使用來(lái)取得更優(yōu)的結(jié)果。
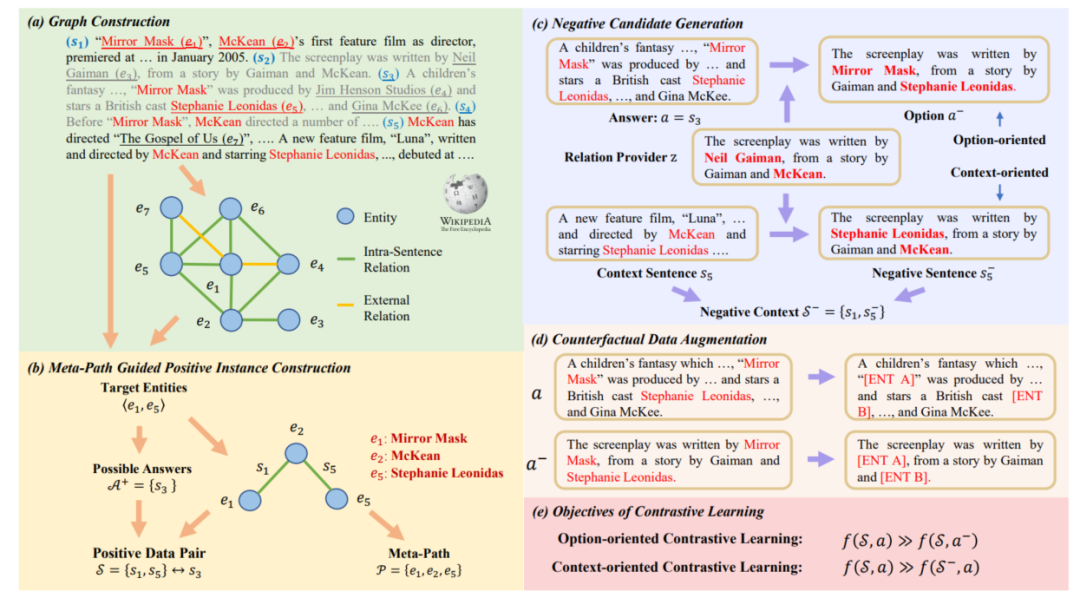
圖10 MERIt框架
3.2.2 LogiGAN
LogiGAN[13]將視線轉(zhuǎn)向了生成式模型(T5)以及包括邏輯推理MRC在內(nèi)的多種需要推理能力任務(wù)上,旨在通過對(duì)MLM預(yù)訓(xùn)練任務(wù)進(jìn)行改進(jìn)來(lái)強(qiáng)化模型的邏輯推理能力,并引入驗(yàn)證器(verifier)來(lái)為生成式模型提供額外反饋,同時(shí)其通過簡(jiǎn)單的策略規(guī)避了序列GAN中beam search帶來(lái)的不可導(dǎo)問題。
LogiGAN首先使用預(yù)先指定的邏輯指示器(例如:“therefore”、“due to”、“we may infer that”)來(lái)從大規(guī)模無(wú)標(biāo)簽文本中識(shí)別邏輯推理現(xiàn)象,然后對(duì)邏輯指示器后面的表達(dá)進(jìn)行mask,訓(xùn)練生成式模型對(duì)被mask的表達(dá)(statement)進(jìn)行恢復(fù)。例如對(duì)于“Bob made up his mind to lose weight. Therefore, he decides to go on a diet.”這段話中Therefore就是一個(gè)邏輯指示器,因此其后面的表達(dá)“he decides to go on a diet.”就會(huì)被mask然后交給模型預(yù)測(cè)。這種基于已知推出未知的訓(xùn)練目標(biāo)相比起隨機(jī)的MLM更能增強(qiáng)模型的邏輯推理能力。
LogiGAN的框架如圖11所示,模型由生成器和驗(yàn)證器兩部分組成,驗(yàn)證器執(zhí)行一個(gè)文本分類任務(wù):以上下文和表達(dá)作為輸入,判斷該表達(dá)來(lái)自于原文的真實(shí)表達(dá)還是構(gòu)造得到偽表達(dá),判別器本質(zhì)上就是在判斷上下文和表達(dá)的邏輯一致性。偽表達(dá)有兩個(gè)來(lái)源:從生成器中通過beam search得到的生成概率較高的句子(self-sampling)和基于真實(shí)表達(dá)從語(yǔ)料庫(kù)中檢索得到的近似表達(dá)(retrieved)。生成器除了需要學(xué)習(xí)生成真實(shí)表達(dá)外,還要讓自己生成偽表達(dá)的似然得分分布與判別器給出邏輯一致性得分分布盡可能一致。LogiGAN在包括LogiQA和ReClor在內(nèi)的12個(gè)需要推理的下游任務(wù)上相較于vanilla T5都取得了明顯的提升。
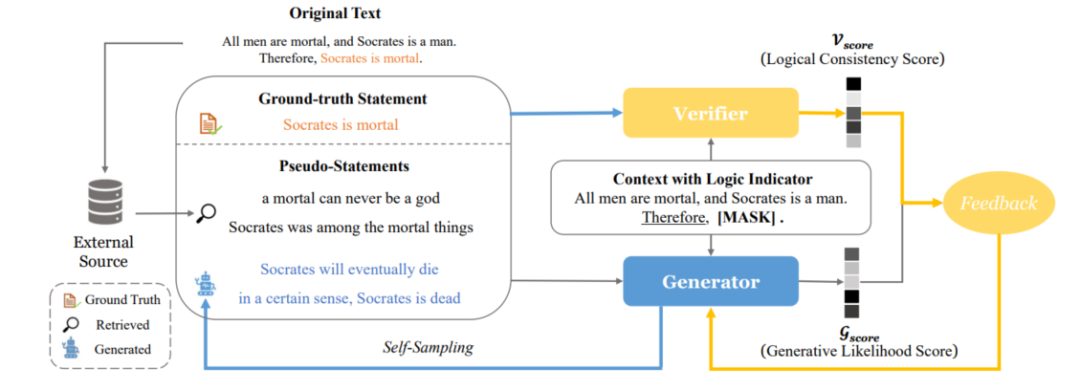
圖11 LogiGAN框架
4.總結(jié)
目前針對(duì)邏輯推理MRC任務(wù)主要從精調(diào)和預(yù)訓(xùn)練兩個(gè)角度出發(fā),精調(diào)階段的方法主要圍繞圖的構(gòu)建與使用展開,如何將文本劃分為邏輯單元,指定邏輯單元之間的邏輯關(guān)系,引入符號(hào)化的推理規(guī)則是這類工作的重點(diǎn)。而預(yù)訓(xùn)練階段的方法則側(cè)重于如何發(fā)掘大規(guī)模無(wú)標(biāo)簽文本中蘊(yùn)含的邏輯推理現(xiàn)象,設(shè)計(jì)合理的預(yù)訓(xùn)練任務(wù)。已有方法在兩個(gè)邏輯推理MRC數(shù)據(jù)集上的表現(xiàn)距離人類仍有較大差距,期待未來(lái)能有更大規(guī)模的新數(shù)據(jù)集和更有效的新方法被提出。
審核編輯:郭婷
-
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1236瀏覽量
26201 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5599瀏覽量
124400
原文標(biāo)題:邏輯推理閱讀理解任務(wù)及方法
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
兩個(gè)RS485-Modbus主站如何通訊
LLM推理模型是如何推理的?

兩個(gè)MCU之間快速傳輸數(shù)據(jù)的方法
使用博圖(TIA Portal)監(jiān)控PROFINET從站通訊狀態(tài)的兩個(gè)方法
信而泰×DeepSeek:AI推理引擎驅(qū)動(dòng)網(wǎng)絡(luò)智能診斷邁向 “自愈”時(shí)代
如何使用 SPI 全雙工在兩個(gè) 5LP MPU 之間連接 RAM?
大模型推理顯存和計(jì)算量估計(jì)方法研究
數(shù)據(jù)集下載失敗的原因?
邏輯推理AI智能體的實(shí)際應(yīng)用
企業(yè)使用NVIDIA NeMo微服務(wù)構(gòu)建AI智能體平臺(tái)
飛凌嵌入式ElfBoard ELF 1板卡-內(nèi)核空間與用戶空間的數(shù)據(jù)拷貝之數(shù)據(jù)拷貝介紹
百度發(fā)布文心大模型4.5和文心大模型X1
富士康A(chǔ)I中文推理大模型FoxBrain,性能接近世界一流水平

如何使用OpenVINO運(yùn)行DeepSeek-R1蒸餾模型




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論