") 3D目標檢測中多模態(tài)融合方法的綜述
3D目標檢測中多模態(tài)融合方法的綜述

導(dǎo)讀
本文是一篇關(guān)于3D目標檢測中多模態(tài)融合方法的綜述,總結(jié)了多模態(tài)融合的難點和現(xiàn)有研究中的一些方法。
0 前言
本篇文章主要想對目前處于探索階段的3D目標檢測中多模態(tài)融合的方法做一個簡單的綜述,主要內(nèi)容為對目前幾篇研究工作的總結(jié)和對這個研究方面的一些思考。 在前面的一些文章中,筆者已經(jīng)介紹到了多模態(tài)融合的含義是將多種傳感器數(shù)據(jù)融合。在3D目標檢測中,目前大都是將lidar和image信息做融合。在上一篇文章中,筆者介紹到了目前主要的幾種融合方法,即early-fusion,deep-fusion和late-fusion,并介紹了一種基于Late-fusion的融合方法。但是在大多數(shù)研究工作中,都是以deep-fuion的方法為主要的融合策略。
1 背景知識
1.1 多模態(tài)融合的主要難點
難點一:傳感器視角問題
3D-CVF(ECCV20)的研究提出的做fusion的對做融合工作最大的問題即是在視角上的問題,描述為如下圖所示的問題,camera獲取到的信息是“小孔成像”原理,是從一個視錐出發(fā)獲取到的信息,而lidar是在真實的3D世界中獲取到的信息。這使得在對同一個object的表征上存在很大的不同。

難點二 數(shù)據(jù)表征不一樣
這個難點也是所用多模態(tài)融合都會遇到的問題,對于image信息是dense和規(guī)則的,但是對于點云的信息則是稀疏的、無序的。所以在特征層或者輸入層做特征融合會由于domain的不同而導(dǎo)致融合定位困難。
難點三 信息融合的難度
從理論上講,圖像信息是dense和規(guī)則的,包含了豐富的色彩信息和紋理信息,但是缺點就是由于為二維信息。存在因為遠近而存在的sacle問題。相對圖像而言,點云的表達為稀疏的,不規(guī)則的這也就使得采用傳統(tǒng)的CNN感知在點云上直接處理是不可行的。但是點云包含了三維的幾何結(jié)構(gòu)和深度信息,這是對3D目標檢測更有利的,因此二者信息是存在理論上的互補的。此外目前二維圖像檢測中,深度學(xué)習(xí)方法都是以CNN為基礎(chǔ)設(shè)計的方法,而在點云目標檢測中則有著MLP、CNN,GCN等多種基礎(chǔ)結(jié)構(gòu)設(shè)計的網(wǎng)絡(luò),在融合過程中和哪一種網(wǎng)絡(luò)做融合也是比較需要研究的。
1.2 點云和imgae融合的紐帶
既然做多模態(tài)特征融合,那么圖像信息和點云信息之間必然需要聯(lián)系才能做對應(yīng)的融合。就在特征層或者輸入層而言,這種聯(lián)系都來自于一個認知,即是:對于激光雷達或者是相機而言,對同一個物體在同一時刻的掃描都是對這個物體此時的一種表征,唯一不同的是表征形式,而融合這些信息的紐帶就是絕對坐標,也就是說盡管相機和激光雷達所處的世界坐標系下的坐標不一樣,但是他們在同一時刻對同一物體的掃描都僅僅是在傳感器坐標系下的掃描,因此只需要知道激光雷達和相機之間的位置變換矩陣,也就可以輕松的得到得到兩個傳感器的坐標系之間的坐標轉(zhuǎn)換,這樣對于被掃描的物體,也就可以通過其在兩個傳感器下的坐標作為特征聯(lián)系的紐帶。 但是,就聯(lián)系的紐帶而言,由于在做特征提取過程中可能存在feature-map或者domain的大小的改變,所以最原始坐標也會發(fā)生一定的改變,這也是需要研究的問題。
2目前存在的一些融合方法
如果硬要把目前存在的融合方法做一個劃分的話,那么筆者從early-fuion,deep-fusion和late-fusion三個層面對最近的文章做一些簡單介紹。這里把early-fusion和deep-fusion當(dāng)做同一類融合方法介紹,late-fusion當(dāng)做另外一種融合策略介紹。
2.1 early-fusian & deep-fusion
在上一篇文章中,筆者也提及到這種融合方法如下圖所示。在后面,筆者將這兩種方法都統(tǒng)稱為特征融合方法,將late-fusion成為決策融合方法。如下圖所示的融合方法,該融合需要在特征層中做一定的交互。主要的融合方式是對lidar 和image分支都各自采用特征提取器,對圖像分支和lidar分支的網(wǎng)絡(luò)在前饋的層次中逐語義級別融合,做到multi-scale信息的語義融合。
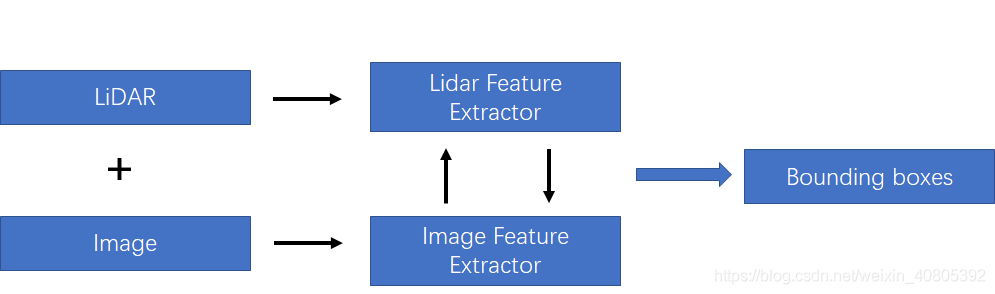
為了方便分析,在該種融合策略下,筆者按照對lidar-3D-detection的分類方法分為point-based的多模態(tài)特征融合和voxel-based的多模態(tài)特征融合。其差別也就是lidar-backbone是基于voxel還是基于point的。就筆者的理解是,基于voxel的方法可以利用強大的voxel-based的backbone(在文章TPAMI20的文章Part-A^2中有研究過point-based方法和voxel-based的方法最大的區(qū)別在于CNN和MLP的感知能力上,CNN優(yōu)于MLP)。但是如果采用voxel-backbone的方法就會需要考慮點到圖像的映射關(guān)系的改變,因為基于point的方法采用原始的點云坐標做為特征載體,但是基于voxel的方法采用voxel中心作為CNN感知特征載體,而voxel中心與原始圖像的索引相對原始點云對圖像的坐標索引還是存在偏差的。
1)基于voxel-based的多模態(tài)特征融合
3D-CVF: Generating Joint Camera and LiDAR Features Using Cross-View Spatial Feature Fusion for 3D Object Detection.文章鏈接: https://arxiv.org/pdf/2004.12636 這篇發(fā)表在ECCV20的多模態(tài)融合的文章網(wǎng)絡(luò)結(jié)構(gòu)圖如下所示,該特征融合階段為對特征進行融合,同時對于點云的backbone采用voxel-based的方法對點云做特征提取。所以這里需要解決的核心問題除了考慮怎么做特征的融合還需要考慮voxel-center作為特征載體和原始點云坐標存在一定的偏差,而如果將圖像信息索引到存在偏差的voxel中心坐標上,是本文解決的另外一個問題。
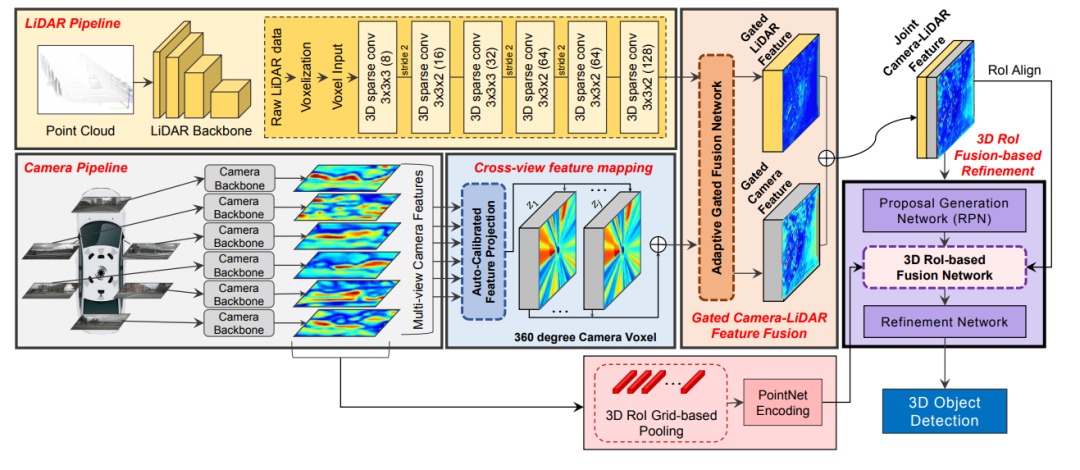
3D-CVF特征融合方法
3D-CVF 將camera的pixel轉(zhuǎn)化到點云的BEV視圖上(voxel-feature-map)時,轉(zhuǎn)化的大小是lidar-voxel-feature-map的x-y各自的兩倍大小,也就是說整體的voxel個數(shù)是Lidar的四倍,即會包含比較多的細節(jié)信息。 以下表示的Auto-Calibrated Projection Method的設(shè)計方案,前面提到的是該結(jié)構(gòu)是將image轉(zhuǎn)化到bev上的網(wǎng)絡(luò)結(jié)構(gòu),具體的做法是: (1)投影得到一個camera-plane,該plane是圖像特征到bev視角的voxel-dense的表達。 (2)將lidar劃分的voxel中心投影到camera-plane上(帶有一個偏移量,不一定是坐標網(wǎng)格正中心) (3)采用近鄰插值,將最近的4個pixel的image特征插值個lidar-voxel。插值的方式采用的是距離為權(quán)重的插值方法。
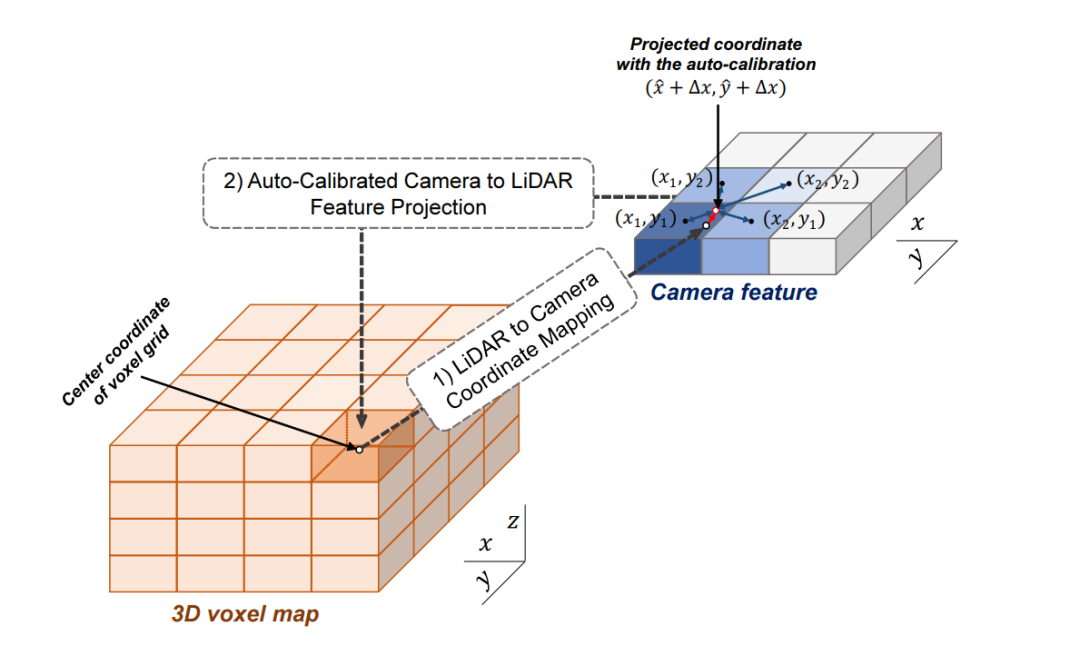
這樣,作者就得到了了image信息的feature-map在lidar-voxel上的表示,值得提到的是前面說的偏移值是為了更好的使camera和lidar對齊。這里的第二步也就是為了解決上面提到的做標偏差的問題。
如下圖所示,
2)基于point-based的多模態(tài)融合方法
由于point-based的方法在特征提取過程也是基于原始點為載體(encoder-decoder的結(jié)構(gòu)會點數(shù)先減少再增加但是點是從原始點中采樣得到,對于GCN的結(jié)構(gòu)則是點數(shù)不改變),所以在做特征融合時,可以直接利用前面提到的轉(zhuǎn)化矩陣的索引在絕對坐標系上做特征融合,所以目前基本也都是基于point的方法比較好融合,研究工作也多一些。PI-RCNN: An Efficient Multi-sensor 3D Object Detector with Point-based Attentive Cont-conv Fusion Module.文章鏈接: https://arxiv.org/pdf/1911.06084 發(fā)表在AAAI20,point分支和image分支分別做3D目標檢測任務(wù)和語義分割任務(wù),然后將圖像語義分割的特征通過索引加到proposals的內(nèi)部的點云上做二次優(yōu)化。
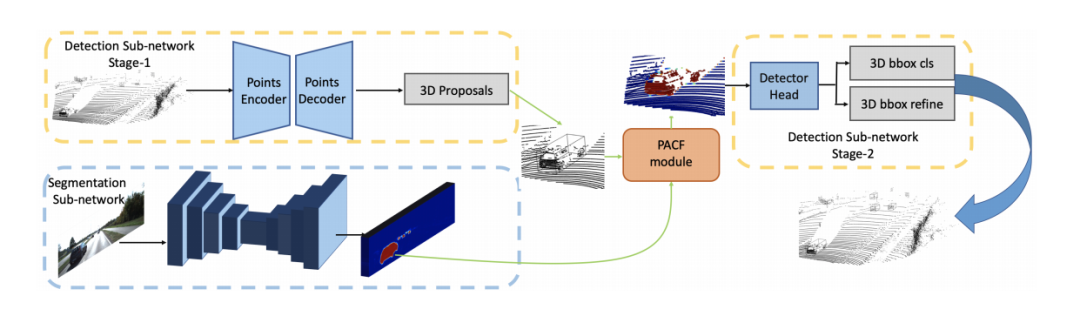
PointPainting: Sequential Fusion for 3D Object Detection文章鏈接: https://arxiv.org/pdf/1911.10150 發(fā)表在CVPR20,該工作的fusion方式是采用二維語義分割信息通過lidar信息和image信息的變換矩陣融合到點上,再采用baseline物體檢測;可以理解為對于語義分割出的物體多了一些信息作為引導(dǎo),得到更好的檢測精度。和上面的pi-rcnn的不同之處是該融合是一個串聯(lián)的網(wǎng)絡(luò)結(jié)構(gòu),將語義分割后的特征和原始點云一起送入深度學(xué)習(xí)網(wǎng)絡(luò)中。
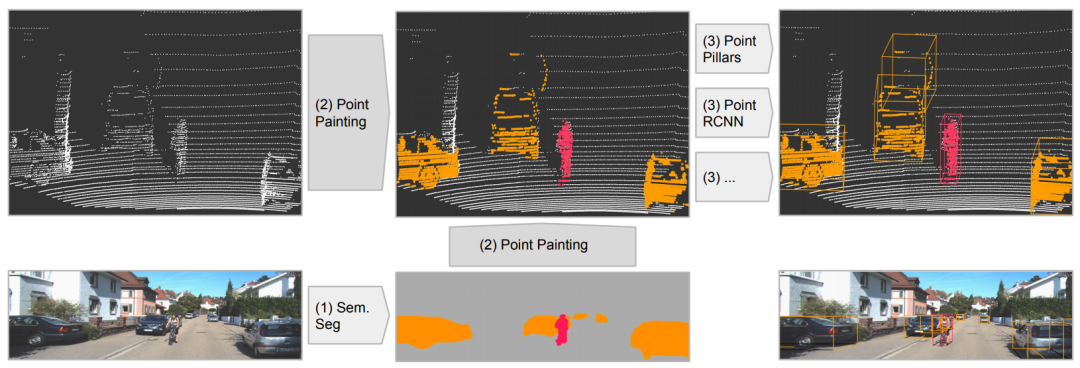
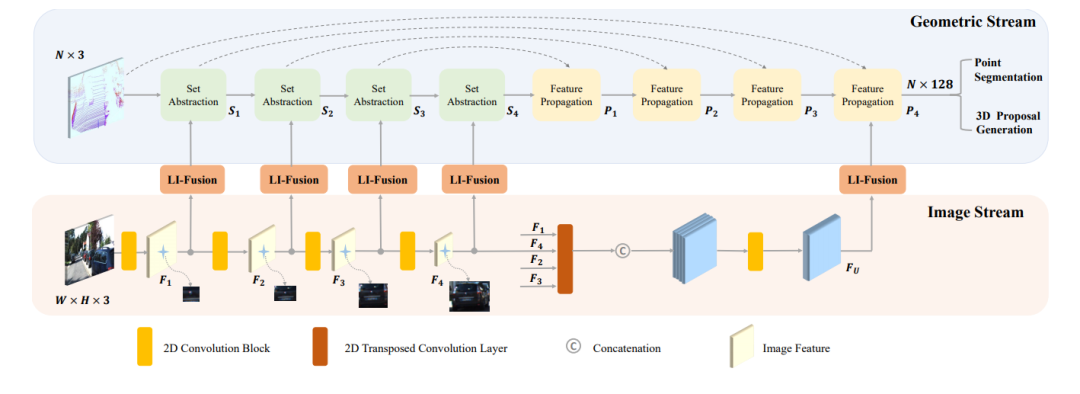
EPNet: Enhancing Point Features with Image Semantics for 3D Object Detection文章鏈接: https://arxiv.org/pdf/2007.08856 發(fā)表在ECCV20的文章,如下圖所示,其網(wǎng)絡(luò)結(jié)構(gòu)點云分支是point encoder-decoder的結(jié)構(gòu),圖像分支則是一個逐步encoder的網(wǎng)絡(luò),并且逐層做特征融合。
2.2 late-fuion
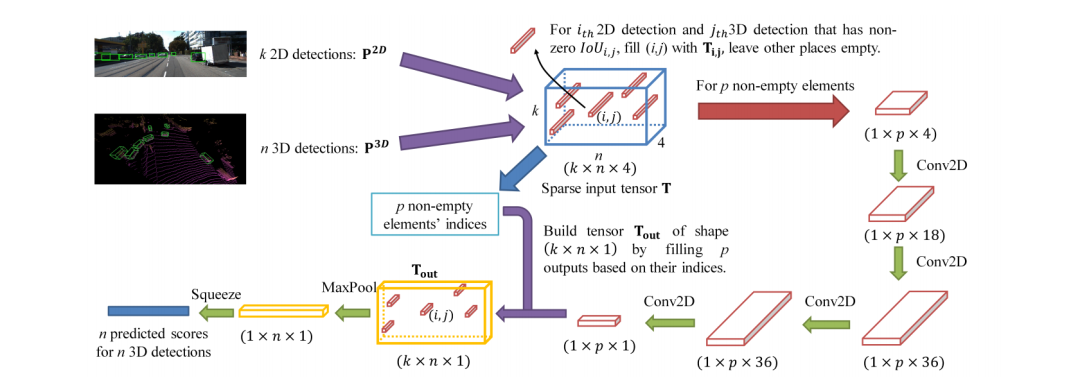
在決策層面的融合相對簡單很多,不需要考慮在信息層面的融合和互補,也就是說,只要是兩種網(wǎng)絡(luò)做同樣的任務(wù),那么在得到各自的結(jié)果后,對結(jié)果做決策上的選擇融合。CLOCs: Camera-LiDAR Object Candidates Fusion for 3D Object Detectionhttps://arxiv.org/pdf/2009.00784.pdf 這就是筆者上一篇分享的文章,從下圖可以看出該網(wǎng)絡(luò)經(jīng)歷了三個主要的階段: (1)2D和3D的目標檢測器分別提出proposals (2)將兩種模態(tài)的proposals編碼成稀疏張量 (3)對于非空的元素采用二維卷積做對應(yīng)的特征融合。
3 筆者總結(jié)
本文主要就目前的幾篇做多模態(tài)融合的文章做了一定的介紹,從大層面上的fusion的階段講起,然后進一步在deep-fuion階段劃分為基于point-based和voxel-based的融合方法,基于point的方法具有先天的優(yōu)勢是具有和image 的索引和不具有空間變化,而voxel的方法可以更有效的利用卷積的感知能力。最后大家如果對自動駕駛場景感知的研究比較感興趣和想要找文章的話,可以去以下鏈接找最新的研究。
審核編輯 :李倩
-
傳感器
+關(guān)注
關(guān)注
2576文章
55041瀏覽量
791383 -
3D
+關(guān)注
關(guān)注
9文章
3011瀏覽量
115065 -
目標檢測
+關(guān)注
關(guān)注
0文章
233瀏覽量
16496
原文標題:綜述:3D目標檢測多模態(tài)融合算法
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
一文掌握3D IC設(shè)計中的多物理場效應(yīng)

Vitrox的v510i系列的3D AOI光學(xué)檢測設(shè)備
技術(shù)資訊 I 多板系統(tǒng) 3D 建模,提升設(shè)計精度和性能

半導(dǎo)體“HBM和3D Stacked Memory”技術(shù)的詳解

玩轉(zhuǎn) KiCad 3D模型的使用

iTOF技術(shù),多樣化的3D視覺應(yīng)用
3D激光輪廓儀可實現(xiàn)在線3D測量和檢測

EtherCAT科普系列(17):EtherCAT技術(shù)在多自由度 3D 打印領(lǐng)域應(yīng)用

海伯森3D閃測傳感器,工業(yè)檢測領(lǐng)域的高精度利器

商湯日日新SenseNova融合模態(tài)大模型 國內(nèi)首家獲得最高評級的大模型
海康威視發(fā)布多模態(tài)大模型AI融合巡檢超腦
3D閃存的制造工藝與挑戰(zhàn)



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論