 SemEval 2022: 多語種慣用語識別評測冠軍系統簡介
SemEval 2022: 多語種慣用語識別評測冠軍系統簡介

在前不久落下帷幕的第十六屆國際語義評測比賽(The 16th International Workshop on Semantic Evaluation,SemEval 2022)中,哈工大社會計算與信息檢索研究中心(HIT-SCIR)與哈工大訊飛聯合實驗室的聯合團隊在多語種慣用語識別任務子賽道SubtaskA(one-shot)中獲得冠軍。本期我們將對這個任務的奪冠系統進行簡要介紹,更多具體細節請參考我們的論文。
論文標題:HITat SemEval-2022 Task 2: Pre-trained Language Model for Idioms Detection
論文作者:初征,楊子清,崔一鳴,陳志剛,劉銘
論文鏈接:http://arxiv.org/abs/2204.06145


任務介紹
Task 2 Subtask A子賽道是跨語言慣用語檢測任務。任務給出多種語言的含多字短語的語句,參賽隊伍需要利用模型判斷目標句子中的多字短語的使用方法是慣用語用法 (Idiomatic)還是字面用法(Literal)。任務共覆蓋三種語言,包括英語、葡萄牙語和加利西亞語。與普通的慣用語檢測任務相比,該評測更加強調考察模型的跨語言遷移能力。在zero-shot設置下,不提供加利西亞語的訓練數據,需要模型通過英語和葡萄牙語的數據集進行zero-shot遷移;在one-shot下提供少量加利西亞語的訓練數據,需要模型具備在不同語言之下良好的few-shot遷移能力。
圖1是任務數據示例。在第一句中,big fish為字面義,表示大魚;第二句中,big fish為隱含義(慣用語),表示大人物。模型需要利用訓練數據對這兩種用法做出區分。

圖1:SemEval-2022 Task2 SubtaskA任務數據示例
系統介紹
提交的系統使用XLM-RoBERTa作為編碼器,在預處理過程中對訓練數據的慣用語短語(MWE)進行特殊標記,在訓練過程中使用R-Drop作為輔助訓練目標,在訓練結束后,根據訓練數據的統計信息制定了啟發式規則對模型預測結果進行校正。此外還嘗試了數據增強、對比學習輔助訓練、對抗訓練等方法,整體結構如圖2所示:
1. 預處理:對輸入的樣本進行截斷、標記MWE、數據增強等操作。
2. 模型訓練:采用XLM-R作為基模型,以cross-entropy損失作為主要訓練目標,以R-drop等方式優化輔助目標。
3. 后處理:根據訓練數據特征對模型預測結果進行校正。
下面將針對部分主要優化技巧進行簡要介紹。
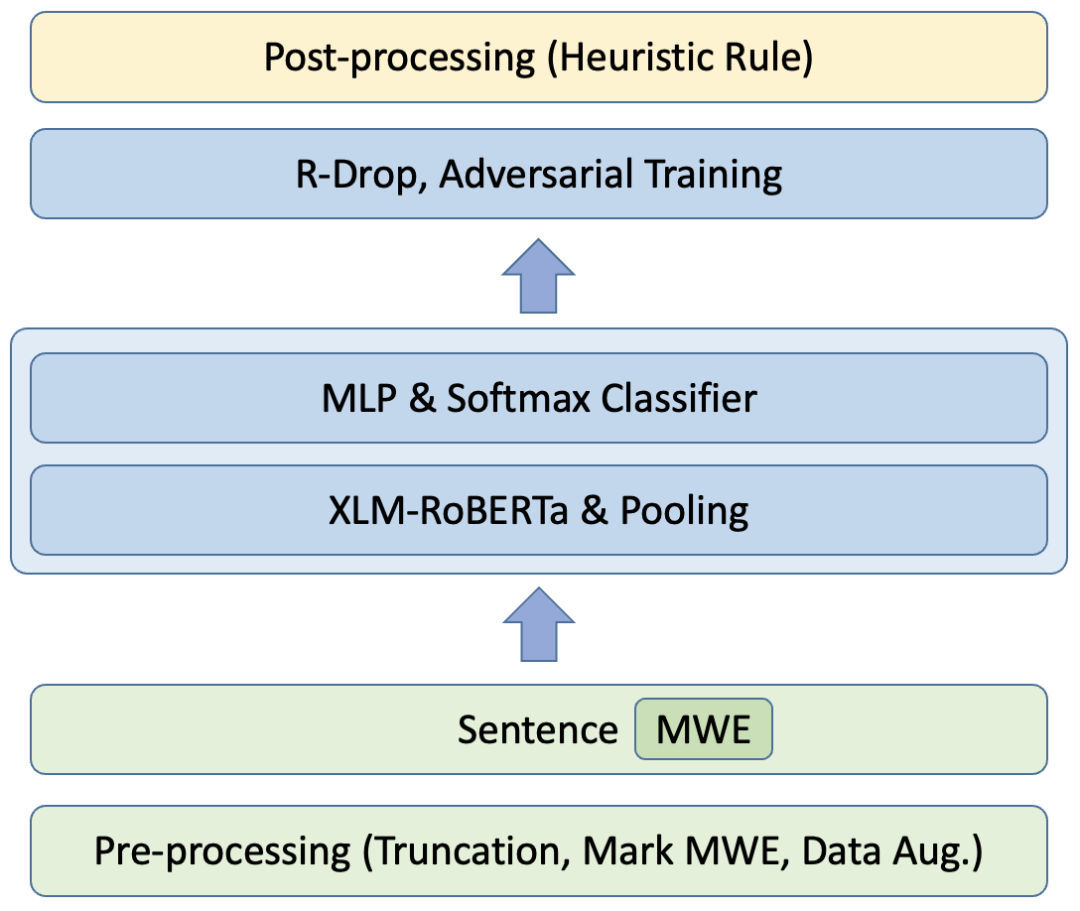
圖2:SemEval-2022 Task2 Subtask A 系統結構
1、數據預處理
數據截斷:為了盡可能地減少截斷所產生的文本信息丟失,在設定句子最大長度前對長度信息進行了統計,最終確定使用128作為最大長度可保證絕大多數句子不被截斷。
短語標記:任務的每一條數據提供了目標句子中要被預測的慣用語短語,為了能夠讓模型能夠關注到慣用語,對句子中的慣用語使用特殊符號進行標記。例如,包含慣用語bigfish的文本 caught some bigfish along the way 將被標記為caught some[SEP] big fish [SEP] along the way。由于預訓練對于命名實體具有識別能力,而在該任務的數據中,命名實體幾乎都進行首字母大寫變形并且標注為非慣用語用法,在后續的實驗中改善了慣用語標注方法,僅標注未經過變形的慣用語短語。對比實驗結果如圖3所示,I表示標記慣用語,C表示使用上下文文本。對比w/ I 和 w/o I的實驗,可驗證這一改動能夠提高性能效果。
上下文信息:此外,我們還發現,不使用任務提供的額外上下文文本數據,而僅使用包含慣用語的句子(w/o C),能取得更優的效果,如圖3第三行所示。原因可能為不包含上下文文本數據的短文本能使模型更聚焦于待判別的慣用短語。
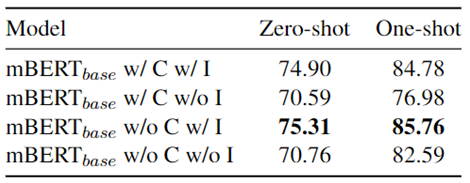
圖3: 上下文以及標注慣用語對結果的影響
2、模型訓練
訓練過程使用XLM-RoBERTa作為編碼器,接池化層和softmax分類器。對不同池化方法進行了實驗,結果表明池化方法對最終結果沒有顯著影響,為了簡便,使用[SEP]作為句子向量表示。訓練過程中嘗試了多種輔助手段,包括R-Drop、對抗訓練、數據增強、對比學習輔助目標等。實驗結果表明,R-Drop以及對抗訓練能夠顯著提高模型表現,并且相較于對抗訓練,R-Drop能夠取得更大的性能提升,結果詳見下一節。
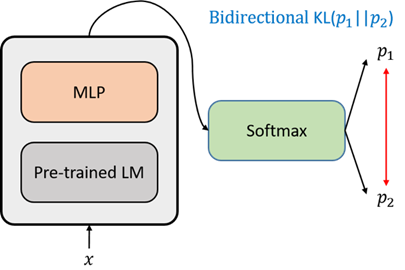
圖4:R-Drop示意圖
3、后處理
在訓練結束后,根據訓練數據的分布統計信息制定了啟發式規則。對于在訓練集中僅出現過一次的短語,因缺乏不同標簽對應的訓練數據,我們采用訓練集中僅出現過的標簽作為預測標簽,以減少訓練集的人工標記偏差對結果的影響。
實驗結果
模型的最終效果及消融實驗如圖5所示。
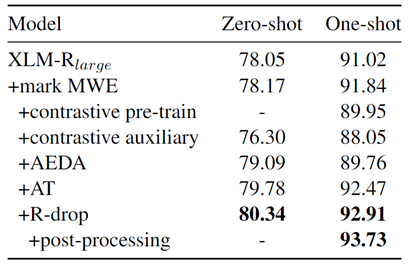
圖5:不同方法對結果的影響
標記MWE(mark MWE)可以同時提升zero-shot和one-shot效果;我們還嘗試了對比學習方法,然而在zero-shot和one-shot上均沒有提升;AEDA是一個簡單的操作標點符號的數據增強策略,對zero-shot有一定幫助;在兩種提升模型穩定性的方法(對抗訓練和R-drop)中,R-drop有更好的表現。最后,后處理策略對訓練集中出現的偏差做了很好的校正。顯著地提升了效果。
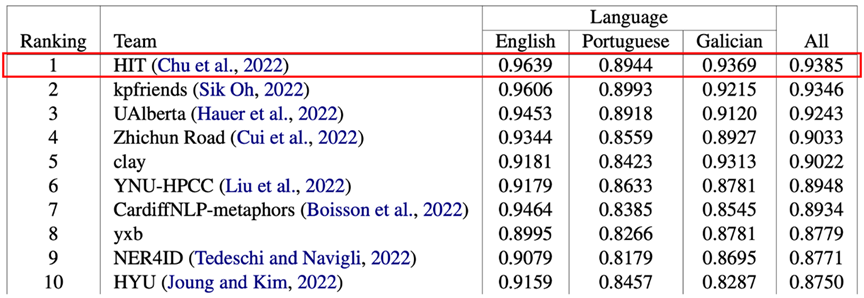
多語種慣用語識別任務子賽道Subtask A(one-shot)最終榜單:HIT-SCIR與HFL聯合團隊排名第一
結論
基于多語言預訓練模型,我們構建了一個多語言慣用語識別系統。通過對輸入格式、模型訓練方式、預測結果后處理等方面的優化,最終系統整體性能較baseline有較為顯著的提升,并在one-shot賽道上取得最優成績。在后續研究中,可嘗試探索如何讓預訓練模型利用訓練數據之外的語料,如慣用語詞典等,以進一步提升預測效果,并降低對標注數據資源的需求,發揮多語言模型的zero-shot能力。
審核編輯 :李倩
-
編碼器
+關注
關注
45文章
3953瀏覽量
142658 -
數據
+關注
關注
8文章
7335瀏覽量
94778
原文標題:競賽 | SemEval 2022: 多語種慣用語識別評測冠軍系統簡介
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
京東多語言質量解決方案
給智能門鎖“裝個移動硬盤”:廣州唯創電子WTV語音芯片外置SPI Flash方案破解多語種語音存儲困局

江蘇省委書記一行到訪思必馳調研
AR智能眼鏡定制_ar眼鏡PCBA硬件設計與AI賦能

聲智科技多語種AI翻譯耳機亮相中美產業交流會
NVIDIA推出多語種語音AI開放數據集與模型
云知聲多項業務營收大漲
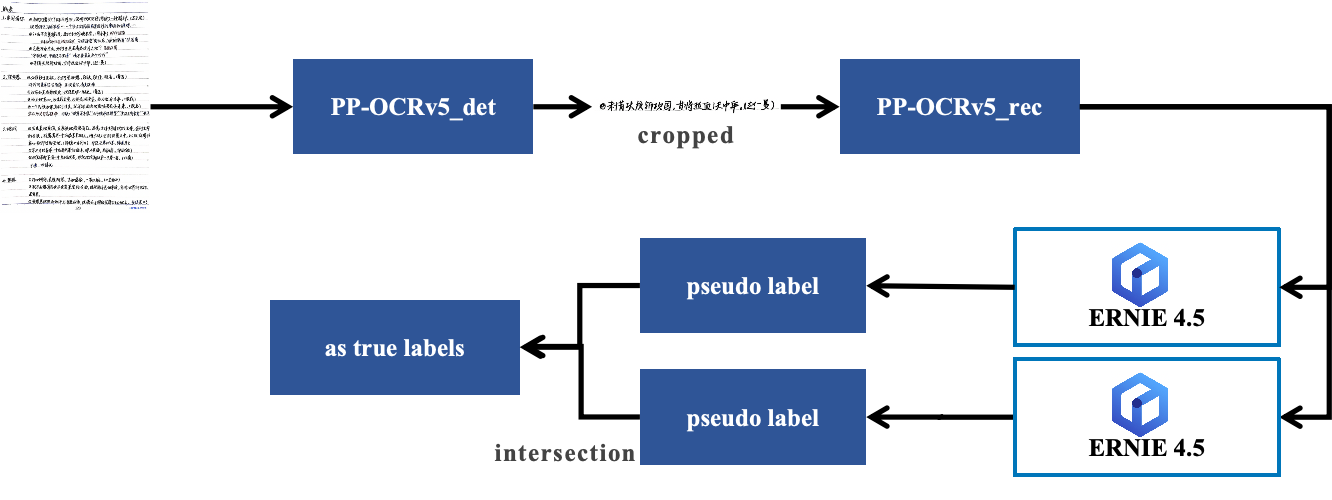
小語種OCR標注效率提升10+倍:PaddleOCR+ERNIE 4.5自動標注實戰解析
聲智科技出席2025年北京市多語種AI語音翻譯大賽
傳音斬獲WMT 2025國際機器翻譯大賽四項冠軍
廣和通發布自研端側語音識別大模型FiboASR
EASY EAl Orin Nano(RK3576) whisper語音識別訓練部署教程

普強智能語音技術重新定義車載交互邊界
給智能門鎖“裝個移動硬盤”:WTV外置SPI Flash方案破解多語種語音存儲困局



 工商網監
工商網監
評論