") 基于DSP改進邊緣的本地語音激活
基于DSP改進邊緣的本地語音激活

如果您曾經(jīng)使用過虛擬助手,您可能會認為您正在與一臺非常智能的設(shè)備交談,它幾乎可以回答您提出的任何問題。嗯,實際上,Amazon Echos、Google Homes 和其他類似的設(shè)備通常不知道你在說什么。
是的,這些設(shè)備利用了人工智能。但不是你期望的那樣。端點硬件通常會簡單地檢測到喚醒詞或觸發(fā)短語并打開與自然語言處理引擎分析請求的云的連接。在許多情況下,他們不只是傳輸您的問題的記錄。
“我們將其稱為邊緣的‘弱喚醒詞’,”加利福尼亞州帕洛阿爾托的 Knowles Intelligent Audio 物聯(lián)網(wǎng)營銷高級總監(jiān) Vikram Shrivastava 說。“你仍然需要將整個錄音發(fā)送到云端,以獲得真正可靠的第二秒,即有人真正說‘好吧,谷歌’或有人真正說出了相關(guān)的觸發(fā)詞。
“這將產(chǎn)生我們稱之為檢測和錯誤接受的真陽性率 (TPR),”他繼續(xù)說道。“所以,如果你沒有說 Alexa,但它還是向云端發(fā)送了一條消息,那么云端就會說,‘不,你沒有。我仔細檢查過,你錯了。那是因為邊緣設(shè)備的邊緣檢測算法不夠復雜。”
換句話說,許多虛擬助手至少會訪問云端兩次:一次是為了驗證他們是否被尋址,第二次是為了響應(yīng)請求。
沒那么聰明吧?
邊緣對話
這種架構(gòu)有幾個缺點。將請求發(fā)送到云會增加時間和成本,還會使?jié)撛诘拿舾袛?shù)據(jù)面臨安全和隱私威脅。但這種方法的最大限制因素是打開和維護這些網(wǎng)絡(luò)連接會消耗能量,這會阻止語音 AI 部署在所有電池供電的產(chǎn)品中。
挑戰(zhàn)就在這里。許多邊緣設(shè)備使用的節(jié)能技術(shù)不具備在本地運行 AI 的性能,因此必須將語音命令發(fā)送到云端,這會招致前面提到的懲罰。為了擺脫這個循環(huán),Knowles 和其他地方的音頻工程師正在將數(shù)字信號處理器 (DSP) 的傳統(tǒng)效率與新興的神經(jīng)網(wǎng)絡(luò)算法相結(jié)合,以提高邊緣智能。
“我們現(xiàn)在看到的是邊緣設(shè)備開始向內(nèi)置生態(tài)系統(tǒng)過渡,”Shrivastava 解釋說。“所以現(xiàn)在你可以擁有多達 10、20、30 條命令,這些命令都可以在邊緣本身執(zhí)行。
“一些觸發(fā)詞改進顯著改善了邊緣的 TPR,”他繼續(xù)說道。“音頻 DSP 實際上發(fā)揮了重要作用,而邊緣的音頻算法發(fā)揮了重要作用,這只是在嘈雜環(huán)境中檢測這些觸發(fā)詞的性能。因此,如果我的真空吸塵器正在運行并且我正在嘗試發(fā)出命令,或者您在廚房并且排氣扇正在運行并且您正在嘗試與您的 Alexa 設(shè)備交談。
“這就是我們所說的低信噪比,這意味著你所處的環(huán)境中的噪音非常高,平均談話會低于平均噪音。”
Knowles 是一家無晶圓半導體公司,以其高端麥克風和最近的音頻處理解決方案而聞名。后者始于 2015 年 Knowles 收購 Audience Inc.,該公司成立于計算聽覺場景分析 (CASA) 的學術(shù)研究,研究人類如何對與其他頻率混合的聲音進行分組和區(qū)分。這項研究導致專門的音頻處理器能夠以 Shrivastava 描述的方式從背景噪聲中提取一個清晰的語音信號。
除了這些音頻處理器之外,Knowles AISonic 音頻邊緣處理器等產(chǎn)品還集成了來自 Cadence Design Systems 的 DSP IP 內(nèi)核。Cadence 的 Tensilica HiFi 音頻 DSP 產(chǎn)品組合因其高能效和高效數(shù)字前端和神經(jīng)網(wǎng)絡(luò)處理能力而在智能邊緣語音應(yīng)用中廣受歡迎。
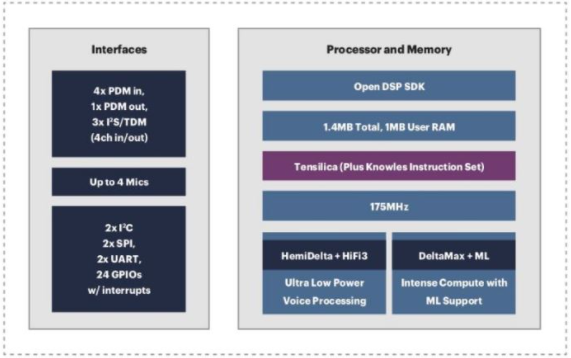
圖 1. Knowles 將 Cadence Tensilica HiFi DSP 內(nèi)核集成到其 AISonic 音頻邊緣處理器中。
Knowles 將這些基于 Tensilica 的音頻處理解決方案部署到從單麥克風 AISonic SmartMics 到高端設(shè)備(如高端 Honeywell 或 Nest 級恒溫器)的所有設(shè)備中,它們可以管理三到七個麥克風。
“麥克風是數(shù)字的,DSP 是數(shù)字的,DSP 和主處理器之間的通信也是數(shù)字的,”Shrivastava 說。“我們就說它是一個 Ecobee 設(shè)備。那里有一個基于 Arm 的主機處理器,它運行一個小的 Alexa 堆棧,它將接受來自 Knowles 子系統(tǒng)的命令短語。
“我們可以接收核心麥克風數(shù)據(jù),我們可以進行波束成形,我們可以找出你在哪個方向說話,我們可以只改善和放大來自那個方向的信號,忽略來自另一個方向的噪聲,做一些其他噪聲抑制也是如此,然后準確地檢測到觸發(fā)詞,”他繼續(xù)說道。“在一個經(jīng)過良好調(diào)整的系統(tǒng)中,我們在 24 小時內(nèi)會出現(xiàn)少于三個錯誤檢測。我們可以在 1 MB 的內(nèi)存中完成這一切。
“擁有所有這些背后的價值主張,只是為了給你一個想法,如果你需要一個運行在 1 GHz 的 Arm 內(nèi)核來進行語音處理,我們將在我們的 DSP 上以大約 50 MHz 運行相同的進程,所以幾乎是 20 倍,”Knowles 工程師解釋道。“這直接轉(zhuǎn)化為功耗。”
顯然,Tensilica 核心無法提供 Shrivastava 所描述的開箱即用的效率水平。應(yīng)用工程師必須針對最終用例調(diào)整系統(tǒng)。對于 Cadence Tensilica 客戶,此過程因定制說明的可用性而得到簡化。
“Tensilica 的獨特之處之一是能夠使用 Tensilica 指令擴展或 TIE,”Cadence 產(chǎn)品營銷總監(jiān)、Knowles 前員工 Adam Abed 說。“Knowles 廣泛使用它來定制和構(gòu)建非常高效的浮點處理。
“因此,我們共同打造了這款非常出色、獨特的產(chǎn)品,它不僅能夠從 MEMS 和麥克風的角度提供高質(zhì)量的音頻,而且還可以在不醒來的情況下以超低功耗的方式進行清理或語音觸發(fā)等操作系統(tǒng)的大部分內(nèi)容,”他補充道(圖 2)。
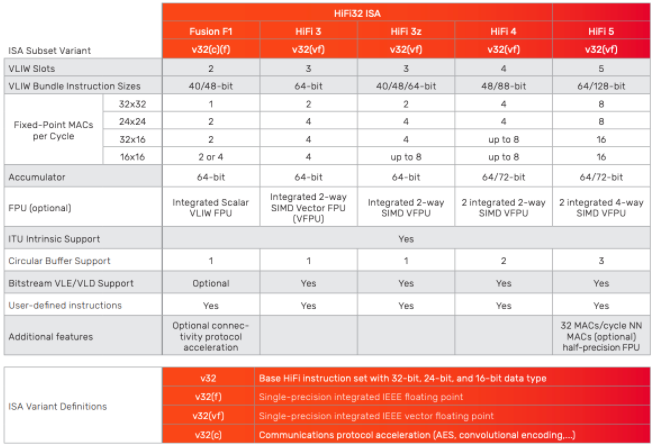
圖 2. Cadence 的 Tensilica HiFi 系列 DSP 提供性能可擴展性和指令定制,以滿足一系列智能語音處理系統(tǒng)的要求。
為了最大限度地提高電源效率和 AI 性能,Abed 提到的喚醒過程通常根據(jù)系統(tǒng)分階段實施。正如他的同事、Cadence 產(chǎn)品工程總監(jiān)劉一鵬所解釋的那樣,像 HiFi 5 這樣的 IP 需要“結(jié)合傳統(tǒng) DSP 以及處理神經(jīng)網(wǎng)絡(luò)本身的能力。
“第一層是檢測是否真的有聲音,所以這是一個非常輕量級的語音活動檢測,”劉說。“如果它檢測到語音,那么您就會喚醒下一層處理,稱為關(guān)鍵字識別。這可以是非常輕量級的處理。它只是說,‘我聽到了一個聽起來像我正在聽的詞。’”
“然后是第三層,一旦你檢測到一個觸發(fā)詞,你可能想要喚醒另一個處理層來驗證,‘是的,我確實聽到了我認為我聽到的內(nèi)容。這實際上是一個非常重的處理負載,”她繼續(xù)說道,“從那里你繼續(xù)聽,這變成了一個重負載的神經(jīng)網(wǎng)絡(luò)處理。
“它可能需要 1 MHz,也可能需要 50 MHz。這真的取決于。”
選擇最佳語音 AI 堆棧:“視情況而定”
當談到 AI 和 ML 技術(shù)評估時,這真的取決于。
當然,確定智能音頻系統(tǒng)的多少兆赫、多少功耗、關(guān)鍵字檢測準確度等關(guān)鍵性能指標因設(shè)計而異。Liu 繼續(xù)解釋說,這種多樣性使得評估智能語音系統(tǒng)組件甚至 DSP 的可行性變得困難,因為在處理高度專業(yè)化的 DSP 時,每秒萬億次操作 (TOPS) 等指標“實際上并不重要”。
“你可以做 1000 TOPS,但所有的操作都是錯誤的類型。但是您可能只需要 200 MHz 來進行某些類型的處理。或者,如果您編寫說明并且一臺設(shè)備需要 50 MHz 而不是 200 MHz,即使它們具有相同數(shù)量的頂部,本質(zhì)上您擁有更有效的頂部,”她補充道。
不過,最近,MLCommons 已經(jīng)通過與 EEMBC 合作開發(fā)一個新的系統(tǒng)級基準測試來簡化評估邊緣 AI 組件的過程:MLPerf Tiny Inference。作為 ML Commons 從云到邊緣的一系列訓練和推理基準中的最新版本,MLPerf Tiny Inference 目前為四個用例提供了標準框架和參考實現(xiàn):關(guān)鍵字定位、視覺喚醒詞、圖像分類和異常檢測。
MLPerf Tiny 工作負載是圍繞預(yù)先訓練的 32 位浮點參考模型 (FP32) 設(shè)計的,哈佛大學邊緣計算實驗室的博士生兼 MLPerf Tiny 推理工作組聯(lián)合主席 Colby Banbury 將其識別為當前的“準確性的黃金標準”。但是,MLPerf Tiny Inference 也提供了一個量化的 8 位整數(shù)模型 (INT-8)。
MLPerf Tiny 作為系統(tǒng)級基準的不同之處在于它的靈活性,它有助于避免對計算性能進行單點性能評估,例如,允許組織提交 ML 堆棧中的任何組件。這包括編譯器、框架或其他任何東西。
但是對于基準測試而言,過于靈活可能是不利的,因為您很快就會得到多個不相關(guān)的向量。MLPerf Tiny 通過兩個不同的部門(開放式和封閉式)解決了這個問題,它們?yōu)樘峤徽吆陀脩籼峁┝酸槍μ囟康幕蛳嗷ズ饬?ML 技術(shù)的能力。
“MLPerf 通常有這么多規(guī)則。它源于靈活性和可比性之間的基準測試中這種不斷拉動的因素,”班伯里說。“封閉式基準更具可比性。您采用預(yù)先訓練的模型,然后您可以根據(jù)已概述的某些特定規(guī)則以與參考模型等效的方式將其實施到您的硬件上。所以這實際上是硬件平臺的一對一比較。”
“但 Tiny ML 的前景需要如此高的效率,因此許多軟件供應(yīng)商甚至硬件供應(yīng)商都在堆棧中的所有不同點提供價值,”MLPerf Tiny 聯(lián)合主席繼續(xù)說道。“因此,為了讓人們能夠證明他們有更好的模型設(shè)計,或者他們可能能夠在訓練階段提供更好的數(shù)據(jù)增強,甚至是不同類型的量化,開放式劃分允許你基本上只解決以任何你想要的方式。我們測量準確性、延遲和可選的能量,因此您可以達到產(chǎn)品預(yù)期的任何優(yōu)化點。”
簡而言之,封閉部分允許用戶根據(jù)特定特征評估 ML 組件,而開放部分可用于測量解決方案的一部分或全部。在開放分區(qū)中,可以修改模型、訓練腳本、數(shù)據(jù)集和參考實現(xiàn)的其他部分以適應(yīng)提交要求。
使用經(jīng)典信號處理清晰聆聽
但回到聲音。音頻 AI 的最終目標是能夠完全在邊緣執(zhí)行成熟的自然語言處理 (NLP)。當然,這需要比當今市場準備的更多的處理能力、更多的內(nèi)存、更多的功率和更多的成本。
“我想說,我們距離真正的自然語言邊緣還有兩年的時間,”Knowles 的 Shrivastava 說。“我們現(xiàn)在看到成功的地方是低功耗、基于電池的設(shè)備,這些設(shè)備希望增加語音和語音處理功能。因此,擁有其中一些本地命令或內(nèi)置功能。
“現(xiàn)在還處于早期階段,因為你需要大量資源來理解邊緣的自然語言,而這仍然是云的領(lǐng)域,”他繼續(xù)說道。“在過去的五年里,我們?nèi)匀粵]有看到很多自然語言來到邊緣。但肯定的是,我們正在將特定于上下文的命令的子集移向邊緣。而且我認為我們會看到越來越多的這些命令,因為它們適合某些嵌入式流程。
正在開發(fā)的 AI 處理引擎有望更有效地執(zhí)行語音激活、識別和關(guān)鍵字定位,并在邊緣支持更高級、基于自然語言的工作負載。事實上,Knowles 和 Cadence 都在積極開發(fā)此類解決方案。
但在中短期內(nèi),仍然需要實時做出語音觸發(fā)驗證等本地決策,同時消耗更少的電量。因此,憑借其對流數(shù)據(jù)進行高效浮點處理的傳統(tǒng),為什么不嘗試將傳統(tǒng) DSP 用于新穎的新應(yīng)用呢?
審核編輯:郭婷
-
dsp
+關(guān)注
關(guān)注
561文章
8244瀏覽量
366614 -
嵌入式
+關(guān)注
關(guān)注
5198文章
20445瀏覽量
333996 -
AI
+關(guān)注
關(guān)注
91文章
39768瀏覽量
301371
發(fā)布評論請先 登錄
高通X85的本地48 TOPS邊緣AI加上云端大模型,到底能干啥?
Ceva 添加 Sensory 的 TrulyHandsfree 語音激活功能, 增強 NeuPro-Nano NPU 生態(tài)系統(tǒng)

探索Renesas VK - RA8M1 V2語音套件:開啟邊緣語音交互新旅程
基于i.MX RT106V跨界MCU的智能語音UI邊緣就緒解決方案
打造本地化智能的“最強大腦”, 米爾RK3576 AI邊緣計算盒

什么是離線語音識別芯片(離線語音識別芯片有哪些優(yōu)點)

邊緣計算網(wǎng)關(guān)的公式計算功能體現(xiàn)在哪
邊緣AI關(guān)鍵驅(qū)動與應(yīng)用場景講解
邊緣智能網(wǎng)關(guān)在水務(wù)行業(yè)中的應(yīng)用—龍興物聯(lián)

邊緣AI盒子技術(shù)解析:ASIC/FPGA/GPU芯片及邊緣-云端協(xié)同與自適應(yīng)推理
明遠智睿SSD2351開發(fā)板:語音機器人領(lǐng)域的變革力量
芯資訊|廣州唯創(chuàng)電子WTK6900P語音識別芯片:離線語音交互的革新者




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論