 NVIDIA T4 GPU加速VIVO推薦系統部署
NVIDIA T4 GPU加速VIVO推薦系統部署

案例簡介及其應用背景
VIVO AI中臺的最終目的是為2.6億+ VIVO用戶提供極致的智能服務,而NVIDIA則為VIVO推薦系統提供強大的算力支持以實踐優化。
推薦系統的大規模部署帶來了諸多工程化挑戰,借助NVIDIA TensorRT, Triton and MPS (Multi-Process Service) 及單張T4 GPU推理卡,其性能優于約6臺以上的78核CPU服務器,成本方面也降低75%。
團隊共實踐和比較了三種不同的工程方案,其中,性價比最高的“通用GPU方案”充分發揮了MPS和TensorFlow的性能,開創性地解決了推薦場景的難題,包含:如何滿足頻繁的算法迭代需求,如何開發不支持的運算操作插件,以及如何改善低效的推理服務性能等。
VIVO AI平臺致力于建設完整的人工智能中臺,搭建全面的、行業領先的大規模分布式機器學習平臺,應用于內容推薦、商業變現、搜索等多種業務場景,為2.6億+ VIVO用戶提供極致的智能服務。
VIVO AI中臺始終服務于企業往智能化深度發展的需求,在數據中臺基礎上增加了一體化智能服務的概念。并且立足于數據的獲取、存儲、特征處理、分析、模型構建、訓練、評估等智能服務相關的任務環節,使其高度組件化、配置化、自動化。
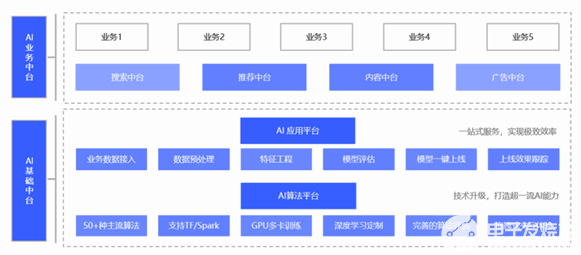
Figure 1. AI中臺系統架構圖 (圖片來源于VIVO研究院授權)
在整個AI中臺架構中,推薦中臺則作為最重要的核心,也是最具商業價值的部分,不僅需承載VIVO億級用戶,日活千萬的數據量也包含在內。本文從推薦系統工程化的角度,解讀了以下三方面內容:VIVO 的智能推薦系統是如何運行的?在實際應用場景中遇到過什么挑戰?NVIDIA GPU如何加速推薦系統的部署?
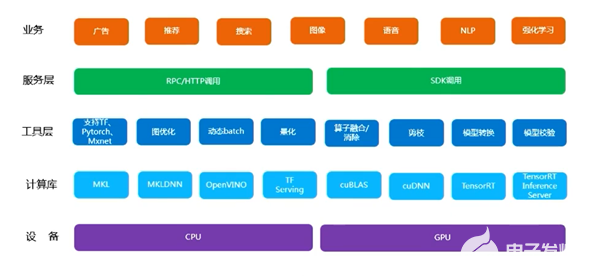
Figure 2. 推薦中臺系統架構圖 (圖片來源于VIVO研究院授權)
經過驗證,本方案可以有效解決推薦業務中GPU通用性問題;同時能更高效的利用GPU。目前已經在部分推薦業務中落地。經過壓測,性能方面,單張T4 GPU推理卡,性能優于約6臺以上的78核CPU服務器。成本方面,VIVO自研通用GPU方案,在TensorRT方案基礎上,取得了更高的QPS和更低的延遲,可節省成本約75%!
本案例主要應用到 NVIDIA T4 GPU 和相關工具包括NVIDA TensorRT, Triton, MPS等。
客戶簡介
VIVO是一家以設計驅動創造偉大產品,打造以智能終端和智慧服務為核心的科技公司,也是一家全球性的移動互聯網智能終端公司。致力于為消費者打造擁有極致拍照、暢快游戲、Hi-Fi音樂的智能手機產品。根據《2020胡潤中國10強消費電子企業》報告顯示,VIVO以1750億人民幣排名第3位。
客戶挑戰
在工程實踐中,VIVO推薦系統面臨的第一個問題是如何平滑的把多種推薦業務邏輯從CPU平臺向GPU平臺遷移。鑒于當前已經存在多個推薦業務場景,包括應用商店,手機瀏覽器,負一屏信息流等。每個場景都有自己的算法模型和業務流程,如何把多種分散的智能服務整合到一個統一的推薦中臺,同時要兼顧當前的業務的無損遷移是一個巨大的挑戰。
一直以來,CPU是客戶主要的支撐推薦業務場景的主流硬件平臺。但VIVO工程團隊卻發現在推理服務中,CPU的表現始終無法達到要求標準,不僅算力較弱,應對復雜模型時,響應延遲和QPS也無法滿足實時性和高并發的需求。
此時,客戶嘗試改用NVIDIA GPU來實現推薦業務的推理服務,有效解決CPU算力和性能的瓶頸的同時,也期待更大的成本優勢。經過大量的工程實踐,結果表明,單臺基于NVIDIA T4 GPU的推理服務器,性能可以等同于24臺CPU機器。毋庸置疑, GPU的整體表現皆具有性能和成本的優勢。據此,客戶也認為使用GPU作為推薦業務場景的推理平臺,已成為了公司乃至行業的共識。
應用方案
由于GPU芯片架構的獨特性,不經優化的原始TensorFlow模型,很難高效利用GPU的算力。為了解決這個問題,VIVO工程團隊投入了大量的人力和時間進行推薦模型優化及轉換。而首先著手設計的是TensorRT方案,即是使用NVIDIA推理加速工具TensorRT,結合 Triton的serving方式,以最大化GPU整體收益。
具體來說,把訓練導出的TensorFlow模型經過Onnx轉換成TensorRT模型,進而使用NVIDIA提供的推理服務框架Triton加載TensorRT模型。業務代碼使用VIVO封裝Triton的JNI接口,將業務請求輸入TensorRT模型去做推理計算。
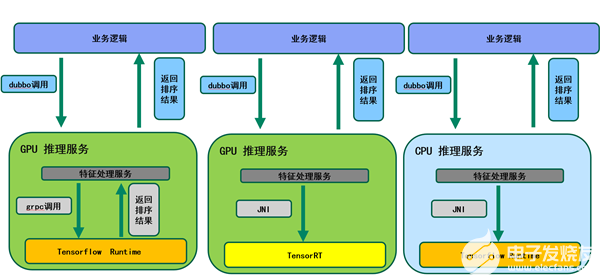
Figure 3. 推薦業務流程圖 (圖片來源于VIVO研究院授權)
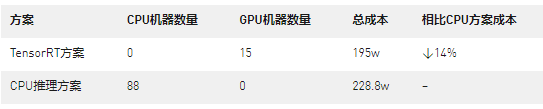
實測結果表明,該方案取得了預期的線上收益。性能方面,單張T4 GPU推理卡,性能優于約6臺以上的78核CPU服務器。以如下場景為例,在相同的精排服務請求:QPS為600,BatchSize為3000時,不同方案的成本,TensorRT方案可節省成本約14%:
為了進一步提升線上收益,最大化GPU利用率,NVIDIA機器學習團隊配合 VIVO繼續優化現有效果,探索更多的技術方案可行性。
經過深入探討,我們發現目前的方案(Triton+TensorRT)確實可以有效利用GPU,但是也存在一些問題。比如很多推薦業務場景,算法模型迭代更新頻率高,工程化開發周期無法滿足頻繁更新的需求。此外,部分推薦模型存在算子不支持的情況,需要手動開發TensorRT plugin,短時間內也無法上線。總體來說,這樣的開發流程通用性不夠好,也較難有效的支持算法持續迭代。
因此,我們迫切需要實現一套機制,既要保證GPU的推理性能,更要具備良好的通用性。經過多次工程化嘗試,我們針對性提出適合自身的推薦系統推理加速方案,即VIVO自研通用GPU方案。
本方案通過多進程 + MPS + TensorFlow runtime的方式,有效的提高了GPU的使用率,且部分場景無需轉換TensorRT模型。該方案的主要設計目標是:
多進程模型,管理和守護模型服務進程,有序的更新模型
添加原生TensorFlow中不支持GPU的算子
加載模型時,動態替換原來的不支持GPU的算子
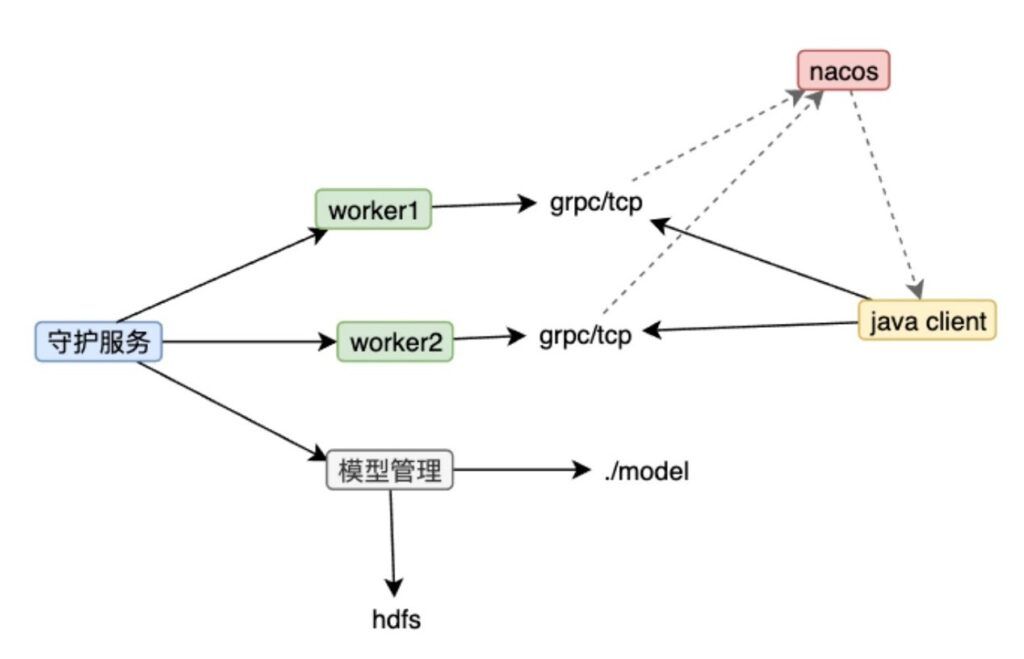
Figure 4. 自研通用GPU方案示意圖 (圖片來源于VIVO研究院授權)
此外,考慮到具體工程實踐中,VIVO算法部門和工程部門需要同步開發,如何解耦算法工程團隊和推理加速團隊的開發任務,因此推出了可配置的推理引擎服務,加速迭代開發效率。
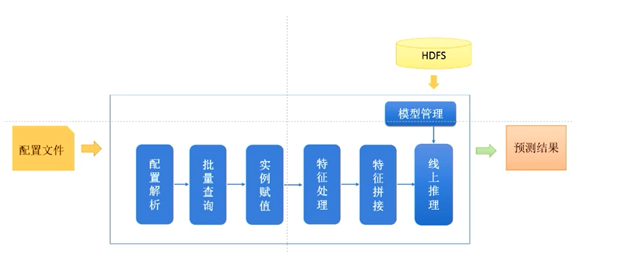
Figure 5. 自研可配置推理引擎示意圖 (圖片來源于VIVO研究院授權)
方案效果及影響
經過驗證,本方案可以有效解決推薦業務中GPU通用性問題;同時能更高效的利用GPU。目前已經在部分推薦業務中落地。經過壓測,VIVO自研通用GPU方案,在TensorRT方案基礎上,取得了更高的QPS和更低的延遲,可節省成本約75%!
下表詳細對比了在相同精排請求:QPS為600,BatchSize為3000時,不同方案的成本。
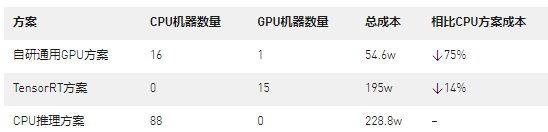
同時,我們測試了負一屏信息流推薦場景,結果同樣表明,無論是QPS或是推理延遲(測試選用業界標準P99/P95指標),自研通用GPU方案都優于TensorRT方案和CPU方案。
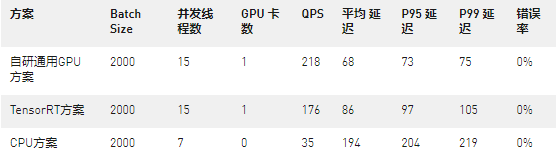
展望未來,VIVO推薦系統工程團隊會繼續探索新技術,持續積累 GPU工程經驗,并且沉淀到平臺中,最終賦能到各個業務線。
審核編輯:郭婷
-
cpu
+關注
關注
68文章
11293瀏覽量
225334 -
NVIDIA
+關注
關注
14文章
5627瀏覽量
109879 -
gpu
+關注
關注
28文章
5213瀏覽量
135625
發布評論請先 登錄
NVIDIA推出BlueField-4 STX存儲架構
NVIDIA RTX PRO 5000 Blackwell GPU的深度評測

NVIDIA Omniverse基于Container的部署推流方案

NVIDIA RTX PRO 2000 Blackwell GPU性能測試

NVIDIA推出NVQLink高速互連架構
FPGA和GPU加速的視覺SLAM系統中特征檢測器研究

OpenAI和NVIDIA宣布達成合作,部署10吉瓦NVIDIA系統

Cadence 借助 NVIDIA DGX SuperPOD 模型擴展數字孿生平臺庫,加速 AI 數據中心部署與運營
NVIDIA RTX PRO 4500 Blackwell GPU測試分析

NVIDIA桌面GPU系列擴展新產品
如何在魔搭社區使用TensorRT-LLM加速優化Qwen3系列模型推理部署
NVIDIA NVLink 深度解析
使用NVIDIA RTX PRO Blackwell系列GPU加速AI開發
Cognizant將與NVIDIA合作部署神經人工智能平臺,加速企業人工智能應用




 工商網監
工商網監
評論