") 利用NVIDIA Triton推理服務(wù)器加速語音識別的速度
利用NVIDIA Triton推理服務(wù)器加速語音識別的速度

網(wǎng)易互娛 AI Lab 的研發(fā)人員,基于 Wenet 語音識別工具進行優(yōu)化和創(chuàng)新,利用 NVIDIA Triton 推理服務(wù)器的 GPU Batch Inference 機制加速了語音識別的速度,并且降低了成本。
2001 年正式成立的網(wǎng)易游戲·互動娛樂事業(yè)群在經(jīng)歷了近 20 年的發(fā)展歷程后,以“創(chuàng)新無邊界,匠心造精品”為文化基石,創(chuàng)造了一系列大家耳熟能詳?shù)拇碜髌罚鐗艋梦饔蜗盗小⒋笤捨饔蜗盗小ⅰ蛾庩枎煛贰ⅰ兜谖迦烁瘛贰ⅰ痘囊靶袆印贰ⅰ堵释林疄I》、《哈利波特:魔法覺醒》等。在 data.ai 公布的 2021 全球發(fā)行商 52 強榜單中,網(wǎng)易排名第二。
語音識別 AI 算法服務(wù)目前已經(jīng)成為各個領(lǐng)域不可或缺的基礎(chǔ)算法服務(wù)。網(wǎng)易互娛 AI Lab 為所有互娛游戲的玩家,CC 直播平臺用戶等提供完善的語音識別服務(wù)。語音識別服務(wù)每天都有大量的調(diào)用量,AI 推理的計算量繁重。
在網(wǎng)易游戲中,語音識別是一個調(diào)用量龐大的基礎(chǔ)算法服務(wù),如果在語音識別算法服務(wù)這里出現(xiàn)時耗或吞吐瓶頸的話,會因為語音內(nèi)容識別過慢,使得用戶使用體驗大幅下降。
服務(wù)是基于開源框架 Wenet 優(yōu)化開發(fā),但是 Wenet 框架中非流式部署方案是基于 libtorch 和 C++ 的,并且熱詞和語言模型部分均采用了 Openfst,速度較慢,也不太方便使用。經(jīng)過測試 CPU Float32 模式下解碼,onnxruntime 要比 libtorch 快了近 20%。在 GPU 部署時還需要有拼接 Batch 的機制,batch inference 雖然在使用 CPU 做推理時沒有太大的提升,但是能大大提升 GPU 的利用率。
基于以上的挑戰(zhàn),網(wǎng)易互娛 AI Lab 選擇了采用 NVIDIA 在 Wenet 中開源的 Triton 部署方案來改進優(yōu)化后進行 GPU 部署,使得語音識別速度提高,大幅降低時延和運營成本。
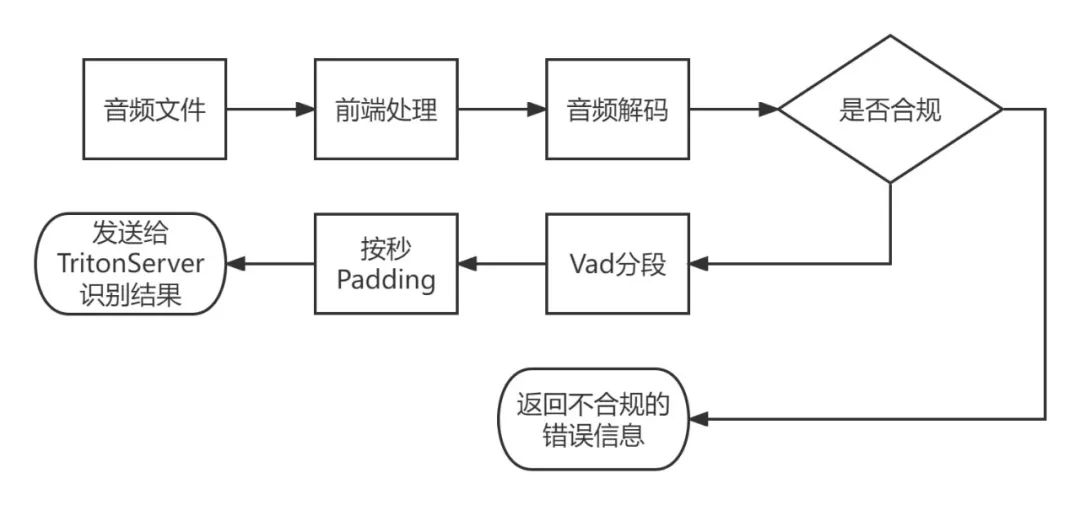
由于 Wenet 開源框架下的 Triton 推理服務(wù)器并沒有考慮音頻解碼,顯存溢出等問題,所以需要有個前端邏輯做音頻解碼處理和音頻分段處理。并且因為 Triton 推理服務(wù)器組 batch 的機制是相同音頻長度才會自動組成 batch 做推理,所以前端處理邏輯這塊還加上了按秒 padding 的操作。整體流程如圖所示。

其中前端處理流程如圖所示:
NVIDIA Triton 推理服務(wù)器處理流程:
(圖片來源于網(wǎng)易互娛授權(quán))
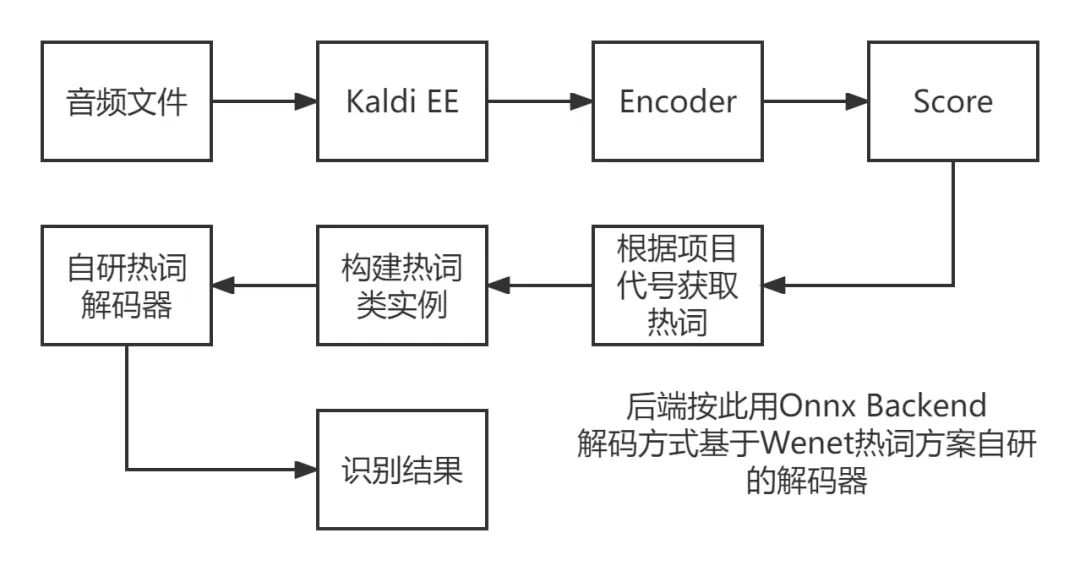
其中 Triton 推理服務(wù)器中解碼器部分是基于 Wenet 的熱詞方案而自研實現(xiàn)的熱詞解碼器方案。
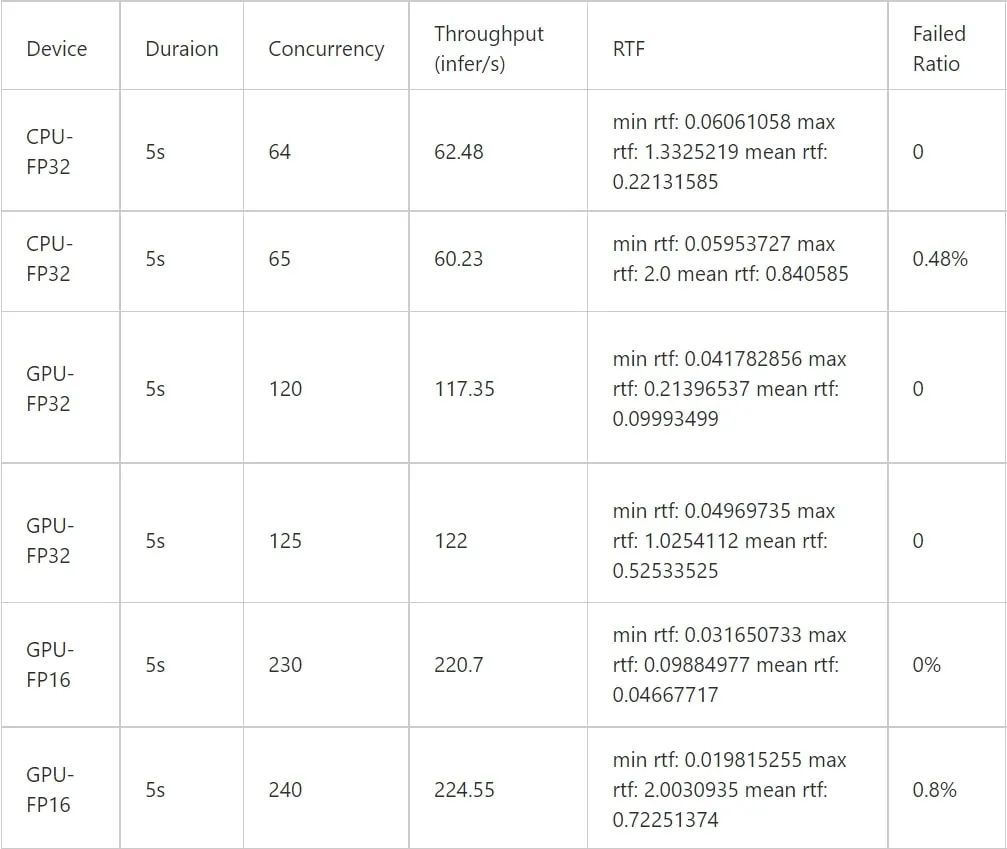
QPS,RTF 在 5 秒音頻下,CPU 設(shè)備和 GPU 設(shè)備對比,CPU 為 36 核機器, GPU 為單卡 T4:
(圖片來源于網(wǎng)易互娛授權(quán))
由表格可知,對比 CPU-FP32 與 GPU-FP16,單卡 T4 的推理能力基本相當于 36 核 CPU(Intel(R) Xeon(R) CPU E5-2630 v4 @ 2.20GHz)機器的 4 倍。并且實驗測試可以得知 FP16 與 FP32 的 WER 基本無損。
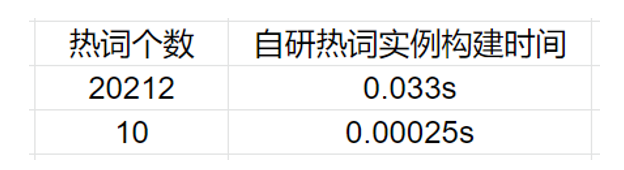
自研熱詞解碼器的方法結(jié)果展示:
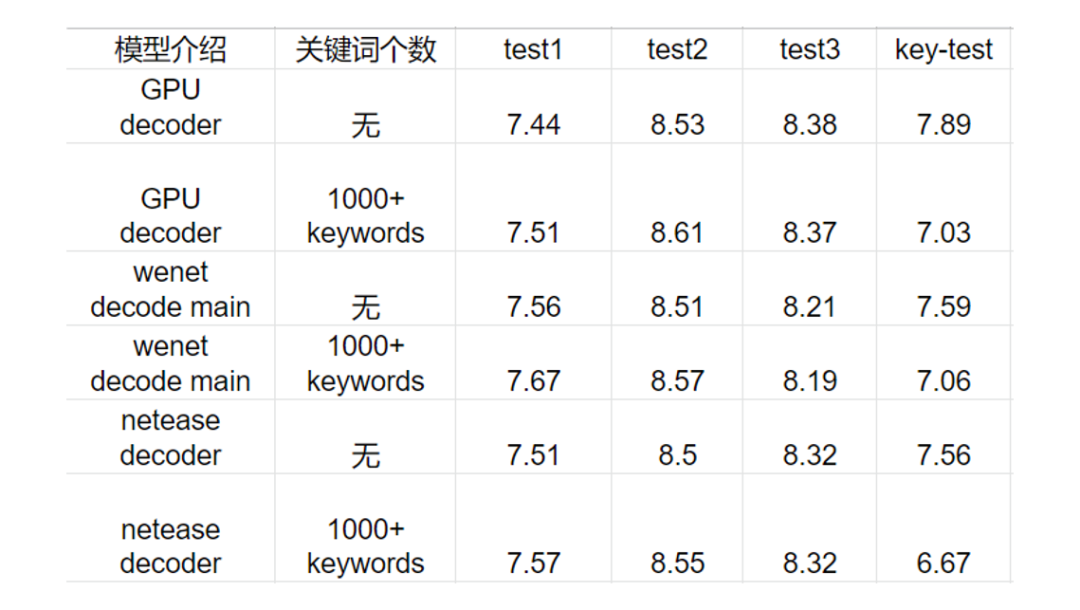
(圖片來源于網(wǎng)易互娛授權(quán))
這里 GPU 的效果采用自研的熱詞增強的方法,識別率在熱詞這塊能有絕對 0.8% 的性能提升,而 Wenet 開源的方法大概是 0.5%。并且自研熱詞實例的構(gòu)建耗時基本可以忽略不計。
整體來看 GPU 的方案在識別率基本無損的情況下,單卡 T4 比 36 核 CPU 機器提高近 4 倍的 QPS,單個音頻 RTF 測試下,包含音頻解碼等損耗情況下也能提高近 3 倍,并且也能夠支持熱詞增強功能,讓機器成本和識別速度都得到了很好的優(yōu)化。
網(wǎng)易互娛廣州 AI Lab 資深 AI 算法工程師丁涵宇表示:“目前該方案已在網(wǎng)易互娛 AI Lab 語音識別服務(wù)落地,大大的降低了識別時延和機器成本。后續(xù),我們還將與英偉達一起研究將熱詞增強的方法在 GPU 中實現(xiàn),探索的極致的語音識別推理性能。”
原文標題:NVIDIA Triton 助力網(wǎng)易互娛 AI Lab,改善語音識別效率及成本
文章出處:【微信公眾號:NVIDIA英偉達】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
審核編輯:湯梓紅
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5592瀏覽量
109719 -
AI
+關(guān)注
關(guān)注
91文章
39755瀏覽量
301361 -
語音識別
+關(guān)注
關(guān)注
39文章
1812瀏覽量
116045
原文標題:NVIDIA Triton 助力網(wǎng)易互娛 AI Lab,改善語音識別效率及成本
文章出處:【微信號:NVIDIA_China,微信公眾號:NVIDIA英偉達】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
什么是離線語音識別芯片(離線語音識別芯片有哪些優(yōu)點)
新加坡服務(wù)器的網(wǎng)絡(luò)速度和延遲表現(xiàn)如何?
云加速是如何隱藏源服務(wù)器ip的
NVIDIA三臺計算機解決方案如何協(xié)同助力機器人技術(shù)
如何在魔搭社區(qū)使用TensorRT-LLM加速優(yōu)化Qwen3系列模型推理部署
使用NVIDIA Triton和TensorRT-LLM部署TTS應(yīng)用的最佳實踐

明遠智睿SSD2351開發(fā)板:語音機器人領(lǐng)域的變革力量
基于RAKsmart云服務(wù)器的AI大模型實時推理方案設(shè)計
AI 推理服務(wù)器都有什么?2025年服務(wù)器品牌排行TOP10與選購技巧

推理服務(wù)器的7大可靠性指標,寬溫/抗震/EMC防護實測數(shù)據(jù)分享

國產(chǎn)推理服務(wù)器如何選擇?深度解析選型指南與華頡科技實戰(zhàn)案例

英偉達GTC2025亮點:Oracle與NVIDIA合作助力企業(yè)加速代理式AI推理

英偉達GTC25亮點:NVIDIA Dynamo開源庫加速并擴展AI推理模型
Oracle 與 NVIDIA 合作助力企業(yè)加速代理式 AI 推理

支持實時物體識別的視覺人工智能微處理器RZ/V2MA數(shù)據(jù)手冊



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論