 圖解目標檢測算法的網絡架構和基本流程
圖解目標檢測算法的網絡架構和基本流程

YOLO v3 是目標檢測各類算法中非常經典的一款,本文試著圖解它的網絡架構和基本流程,給想快速了解它的童鞋提供一些參考。
1引 言
近年來,由于在海量數據與計算力的加持下,深度學習對圖像數據表現出強大的表示能力,成為了機器視覺的熱點研究方向。圖像的表示學習,或者讓計算機理解圖像是機器視覺的中心問題。
具體來說,圖像理解包括分類、定位、檢測與分割等單個或組合任務,如下圖所示。
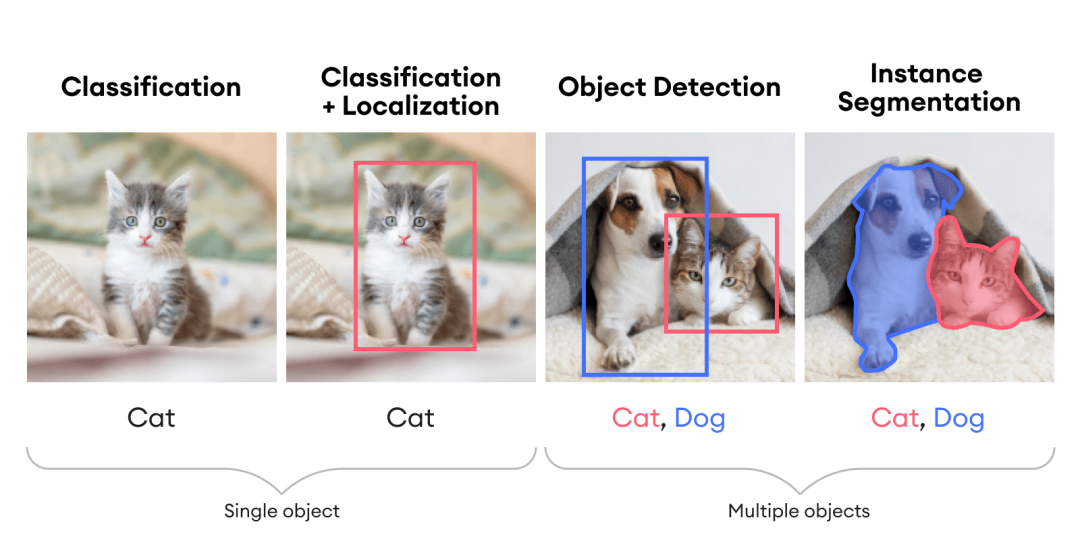
本篇關注目標檢測,它可以認為是一個將分類和回歸相結合的任務。
目標檢測的核心問題可以簡述為圖像中什么位置有什么物體。
1)定位問題:目標出現在圖像中哪個位置(區域)。
2)分類問題:圖像的某個區域里的目標屬于什么類別。
當然,目標(物體)在圖像中還存在其他問題,如尺寸問題,即物體具有不同大小;還有形狀問題,即物體在各種角度下可以呈現各種形狀。
基于深度學習的目標檢測算法目前主要分為兩類:Two-stage和One-stage。
Tow-stage
先生成區域(region proposal,簡稱 RP),即一個可能包含待檢物體的預選框,再通過卷積神經網絡進行分類。
任務流程:特征提取 --> 生成 RP --> 分類/定位回歸。
常見Two-stage目標檢測算法有:R-CNN、Fast R-CNN、Faster R-CNN、SPP-Net 和 R-FCN 等。
One-stage
直接用網絡提取圖像特征來預測物體位置和分類,因此不需要 RP。
任務流程:特征提取–> 分類/定位回歸。
常見的One-stage目標檢測算法有:YOLO 系列、SSD 和 RetinaNet 等。不過,為了得到最終目標的定位和分類,往往需要后處理。
本篇主要來看 YOLO 系列中的 v3 版本。
2基本原理
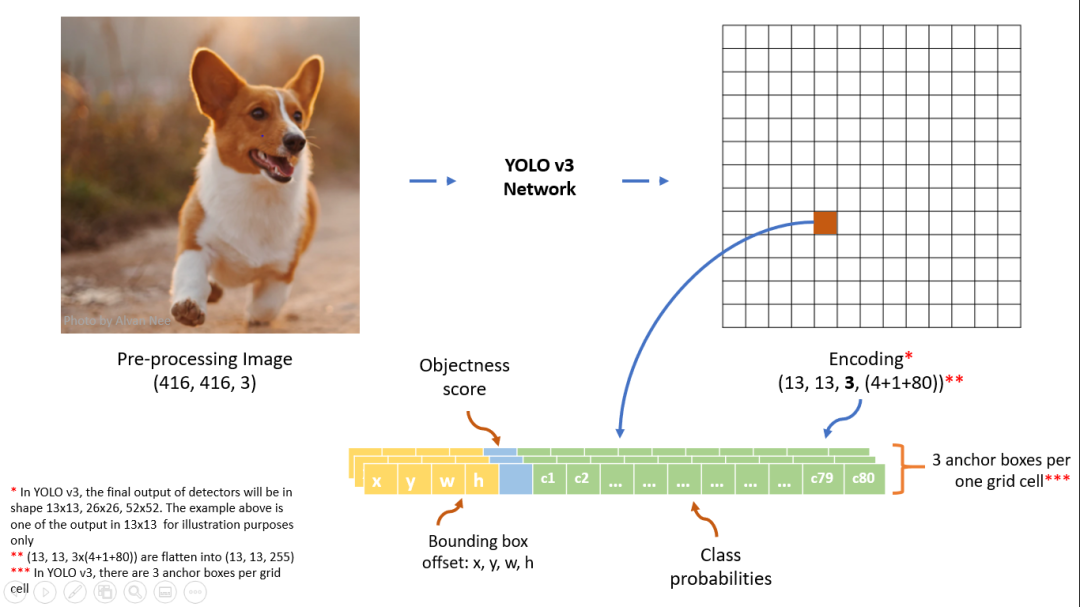
首先,我們先從整體上來看一下 YOLO v3 是如何工作的。YOLO v3 算法通過將圖像劃分為個網格(grid)單元來工作,每個網格單元具有相同大小的區域。這個網格單元中的每一個都負責對包含該網格的目標的檢測和定位。
相應地,這些網格預測個相對于它們所在單元格的包圍盒相對坐標,以及目標標簽和目標出現在單元格中的概率。
由于網格的分辨率比起原圖來說已經大大降低,而檢測和識別步驟都是針對網格單元來處理的,因此這個方案大大降低了計算量。但是,由于多個單元格用不同的包圍盒來預測同一個對象,因此會帶來了很多重復的預測框。YOLO v3 使用非最大值抑制(Non-Maximum Suppression,NMS)來處理這個問題。
下圖給出了一個例子,展示了當時的個網格以及由此檢測圖中目標的大致流程。會涉及很多個包圍盒,最后選出三個包圍盒來定位和識別目標。

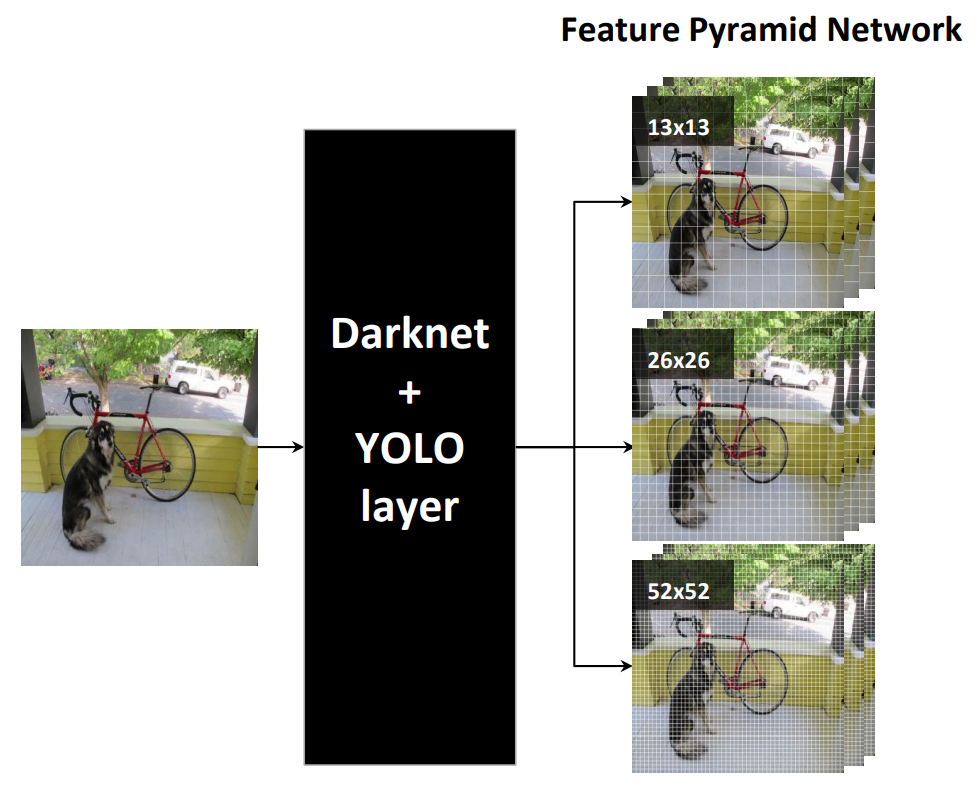
另外,為了兼顧圖像中各種尺度的目標,可以使用多個不同分辨率的個網格。很快將會看到,YOLO v3 中使用了 3 個尺度。
3總體架構
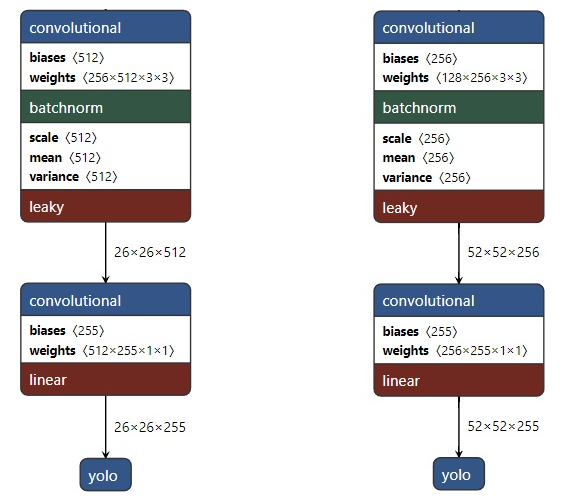
先看一下網絡架構,注意它有三個不同分辨率的輸出分支。
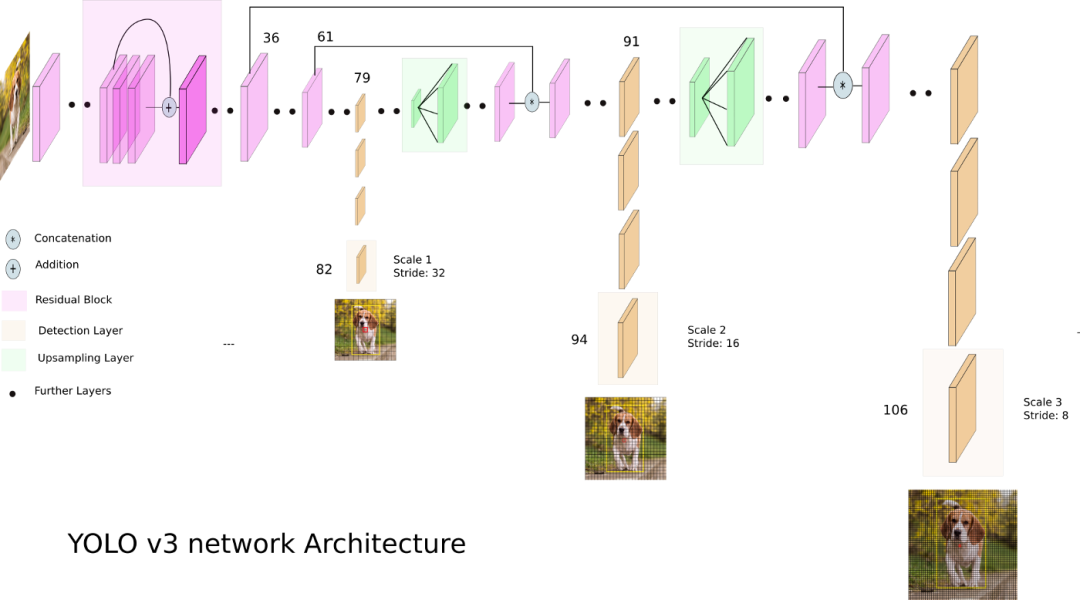
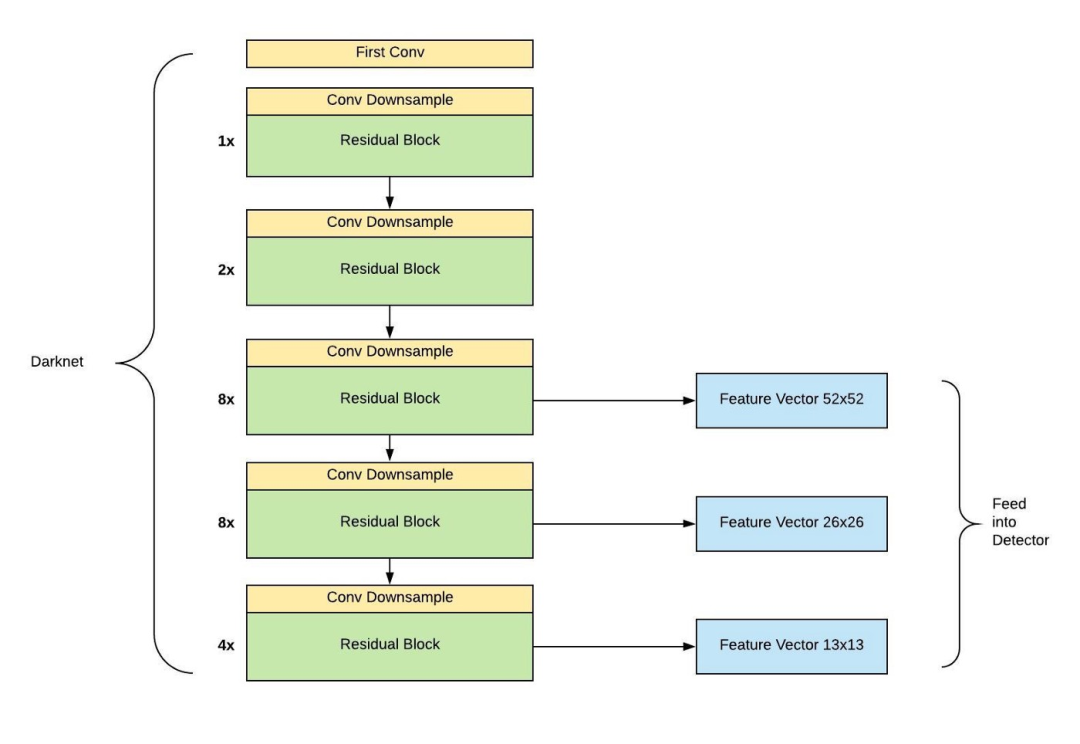
從 Yolo v3 的流程圖可以看到,總共有 106 層,實現了對每張圖像在大、中、小三個尺度上檢測目標。這個網格有三個出口,分別是 82 層、94 層、106 層。
下面看一下更加詳細的網絡架構圖,注意有三個檢測結果(Detection Result)。
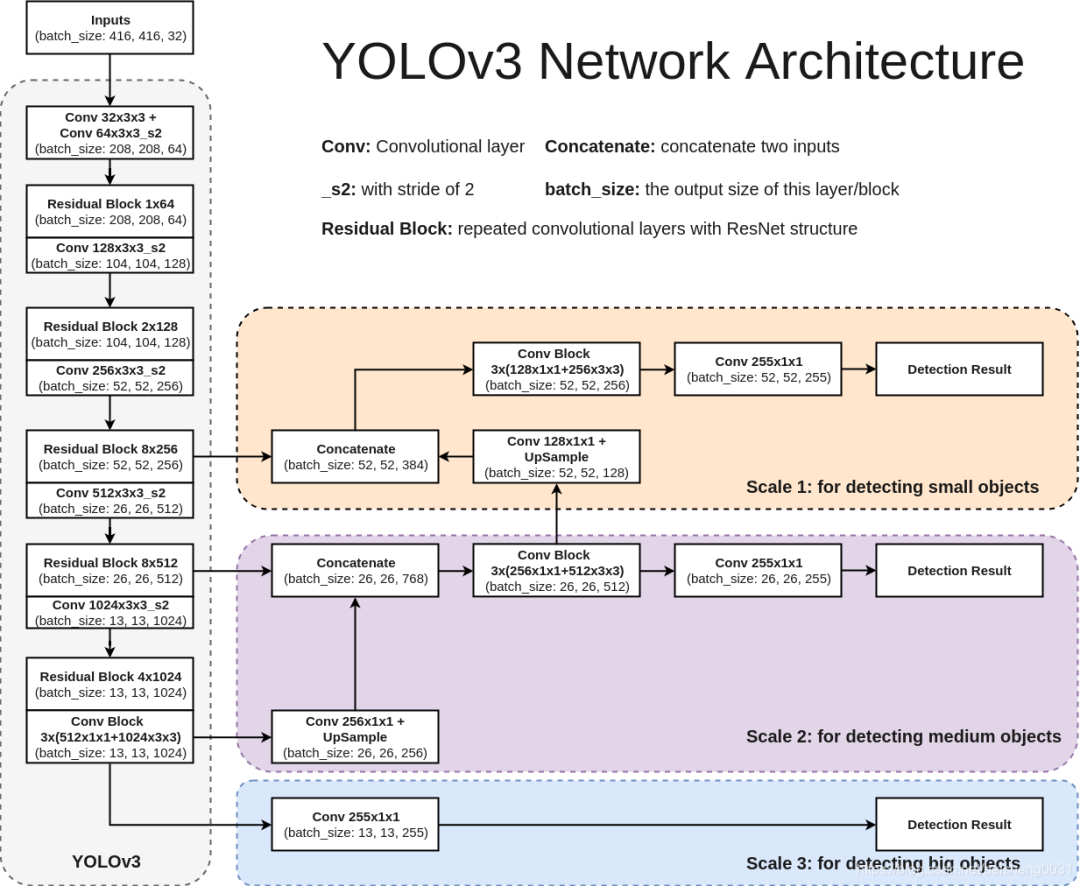
上圖左邊是 DarkNet-53,是一個深度為 53 層的卷積神經網絡,具體的殘差塊和卷積層如下圖所示。
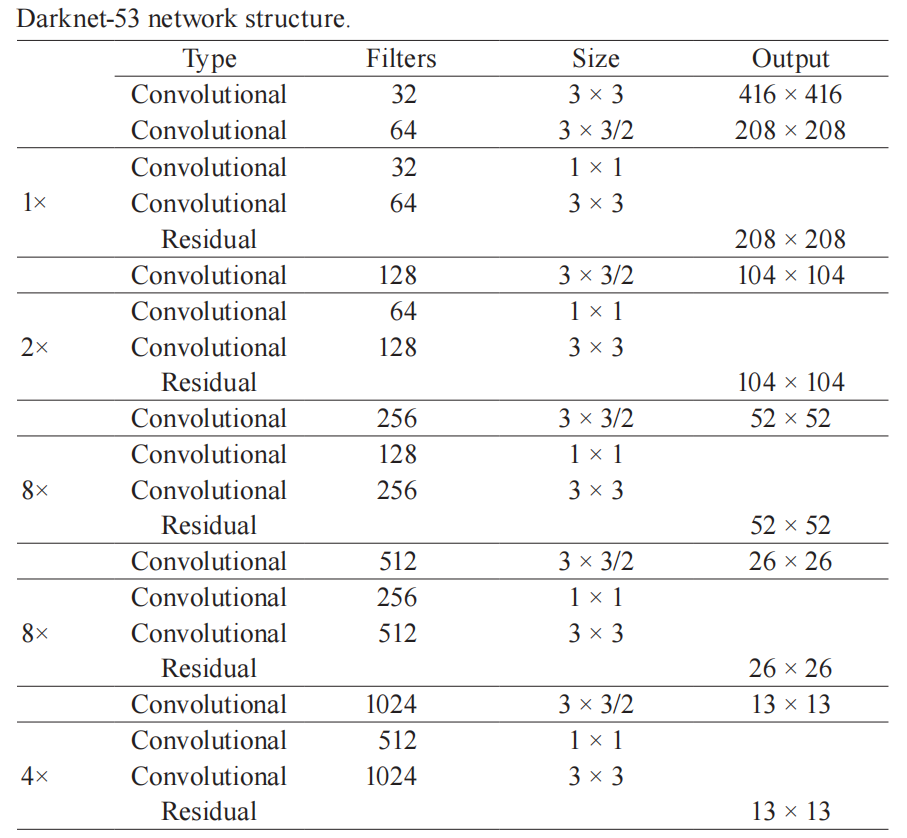
輸入圖像通過 Darknet 得到三個尺度的特征圖,從上往下為(52×52×256), (26×26×512), (13×13×1024),也就是在三種尺度上進行以便檢測到不同大小的目標。也可以結合下面這個更加精煉圖來理解。
4關鍵步驟
目標檢測也可以看作是對圖像中的背景和前景作某種理解分析,即從圖像背景中分離出感興趣的目標,得到對于目標的描述<位置,類別>。
由于可能有多個目標存在,模型輸出是一個列表,包含目標的位置以及目標的類別。目標位置一般用矩形檢測框(包圍盒)的中心和寬高來表示。
?模型輸出值
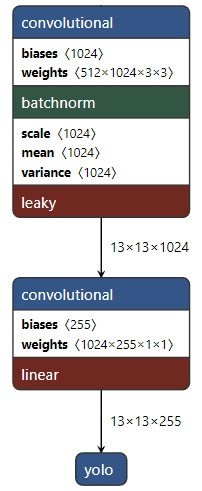
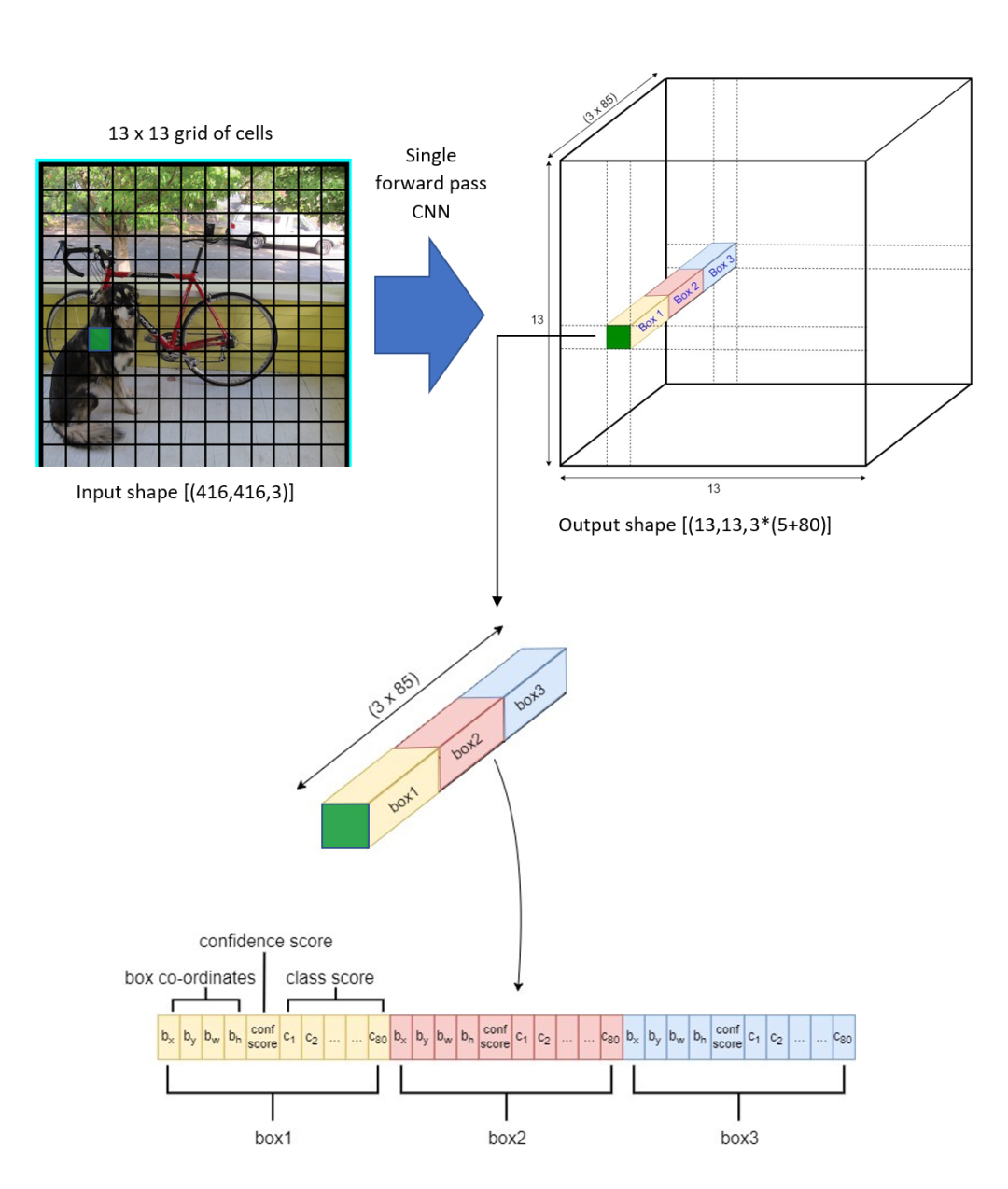
分辨率最低的輸出分支對應的結果是,下圖展示了在特征圖上的檢測結果,特征圖上的一個像素對應一個網格,每個網格會有 3 個預測框,每個預測框具有(5 + C)個值,其中前 5 個數對應包圍盒的位置以及屬于目標的可能性,C 表示類別數。

具體來看,最后輸出的結果為:每個網格單元對應一個維向量,表示一個網格可以預測包圍盒的數目,上面已經說了,個數值中的前個對應包圍盒的中心位子和寬高值和個目標置信度。
這個結果的含義大致清楚了,但是還有個小問題,就是這個輸出是根據什么信息計算而來呢?
如下圖所示,在前一層得到的特征圖上再接一個核大小為的卷積層得到最終的輸出,即由每個網點的特征向量(1024 維)轉化為我們需要的輸出,即包圍盒、目標置信度以及類別信息。
上面說了,在這個尺度上會檢測 3 個預測框,把它們拼接在一起,得到完整的結果示意圖如下。
另外兩個尺度上類似,它們對應的分支輸出如下兩個圖所示。
網絡會在 3 個尺度上分別檢測,每個尺度上每個網格點都預設 3 個包圍盒,所以整個網絡共檢測到13×13×3 + 26×26×3 + 52×52×3 = 10647個包圍盒。
那么這里的 3 個預設包圍盒又是怎么回事呢?
其實每個網格單元可以對目標的包圍盒進行一定數量的猜測,比如下圖中的示例,黃色網格單元進行兩次包圍盒(藍色框)預測以定位人的位置。
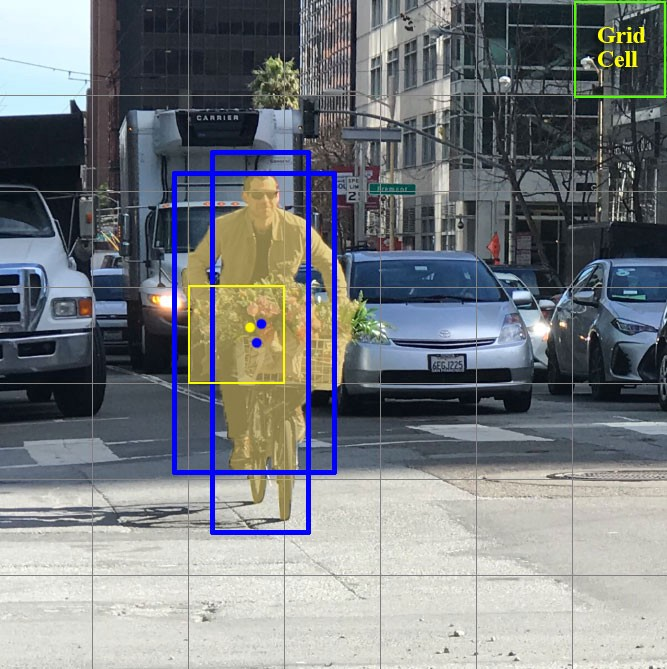
而 YOLO v3 中采用3 個預設包圍盒,但值得注意的是這里限定只能檢測同一個目標。
?先驗包圍盒
還有一個問題,每個網格對應的包圍盒怎么取呢?理論上,包圍盒可以各種各樣,但是這樣的話就需要大量計算。
為了節省計算,不妨預先了解一下在圖像中出現的目標一般具有怎么樣的包圍盒。可以通過在數據集 VOC 和 COCO 上使用聚類法尋找一般目標的包圍盒尺寸。
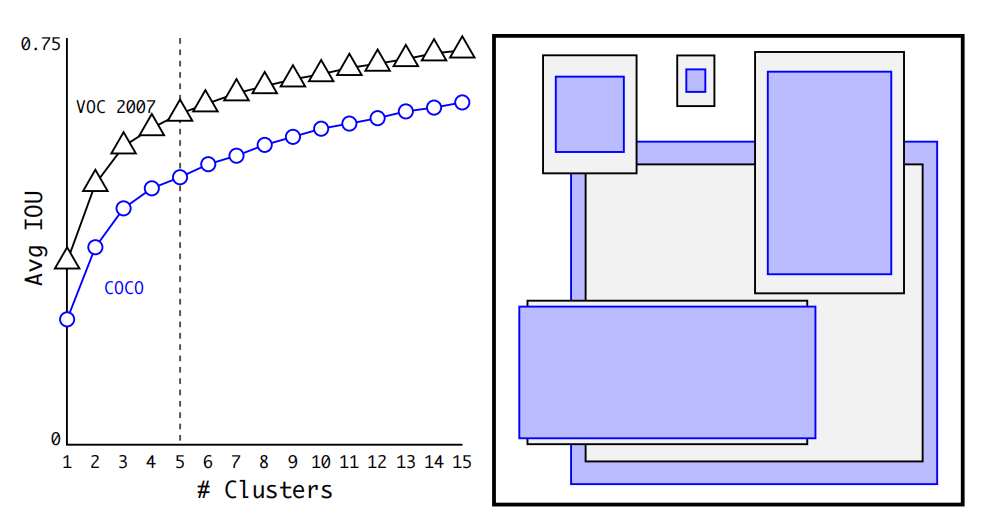
在包圍盒的維度上運行 k-means 聚類,以獲得良好先驗。左圖顯示了我們在選擇時得到的平均 IOU。在 YOLO v2 中,作者選擇,此時在模型的召回率與復雜性之間具有較好的平衡。右圖顯示了 VOC 和 COCO 的相對質心。兩組先驗都傾向于更薄、更高的盒子,而 COCO 的尺寸變化比 VOC 更大。
而在 YOLO v3 中,通過聚類選出了個先驗包圍盒:(10×13),(16×30),(33×23),(30×61),(62×45),(59×119),(116×90),(156×198),(373×326)。
?包圍盒預測
有了預設的先驗包圍盒,怎么來計算實際包圍盒呢?總不能直接套到每個網格單元處就完事了吧。
YOLO v3 引入一個機制,可以適當調整預設包圍盒來生成實際的包圍盒。下圖中的公式將網絡輸出值轉換得到實際的包圍盒信息。
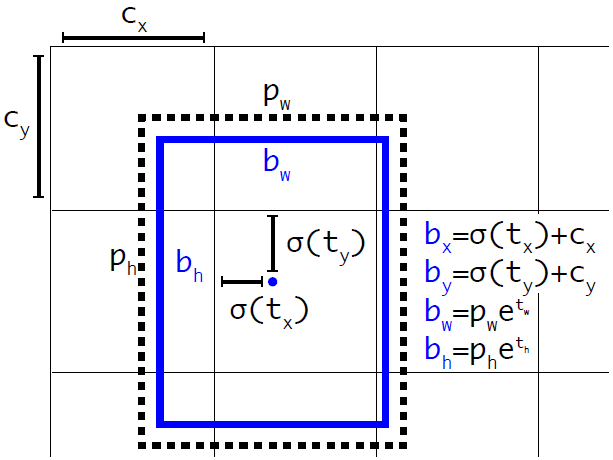
或者參考下圖,
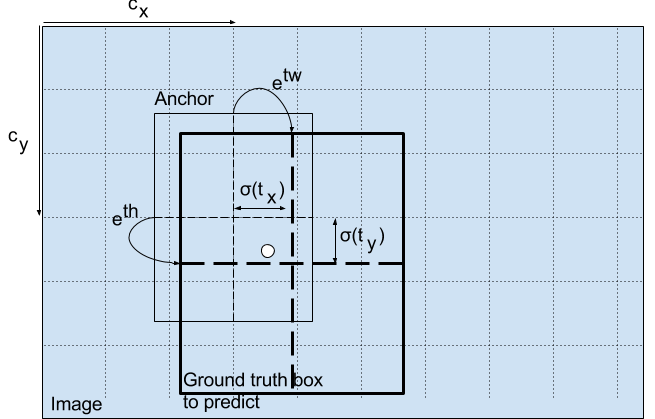
預測出包圍盒中心點相對于網格單元左上角的相對坐標。通過和可以將包圍盒中心點限制于網格單元內。另外,為了得到訓練數據的值,只需要反算即可。
?包圍盒后處理
YOLO v3 模型的輸出并沒有直接給出包含目標的包圍盒,而是包含所有網格單元對應結果的張量,因此需要一些后處理步驟來獲得結果。
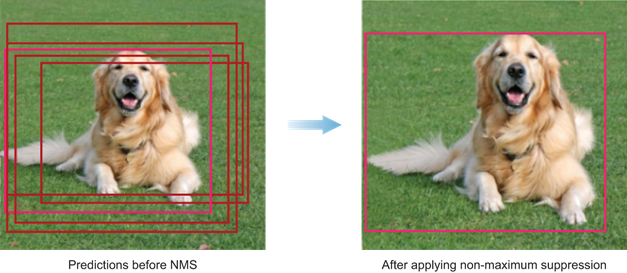
首先,需要根據閾值和模型輸出的目標置信度來淘汰一大批包圍盒。而剩下的包圍盒中很可能有好幾個圍繞著同一個目標,因此還需要繼續淘汰。這時候就要用到非極大值抑制(Non-Maximum Suppression,NMS),顧名思義就是抑制不是極大值的元素,可以認為求局部最優解。用在此處的基本思路就是選擇目標置信度最大的包圍盒,然后排除掉與之 IoU 大于某個閾值的附近包圍盒。
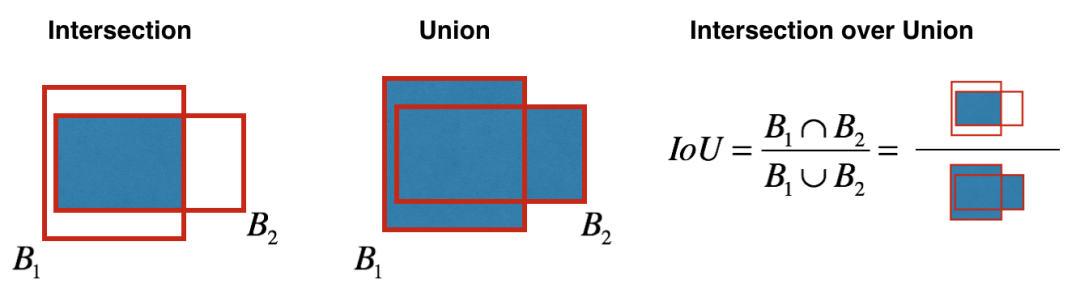
而兩個包圍盒的 IoU 計算如下,
?損失函數
由于網絡的輸出值比較多,因此損失函數也具有很多項,但總體還是清晰的,這里不作展開。
5實 驗
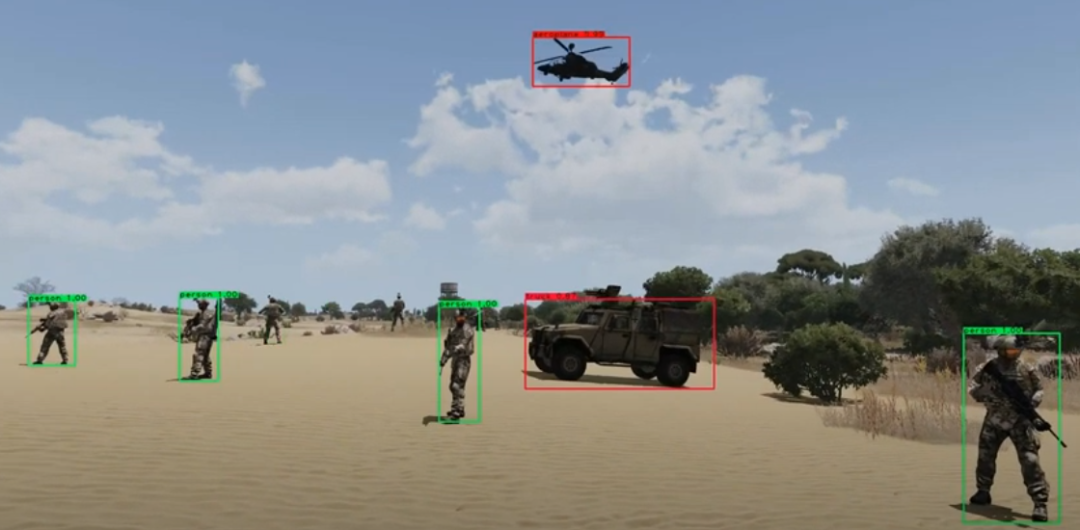
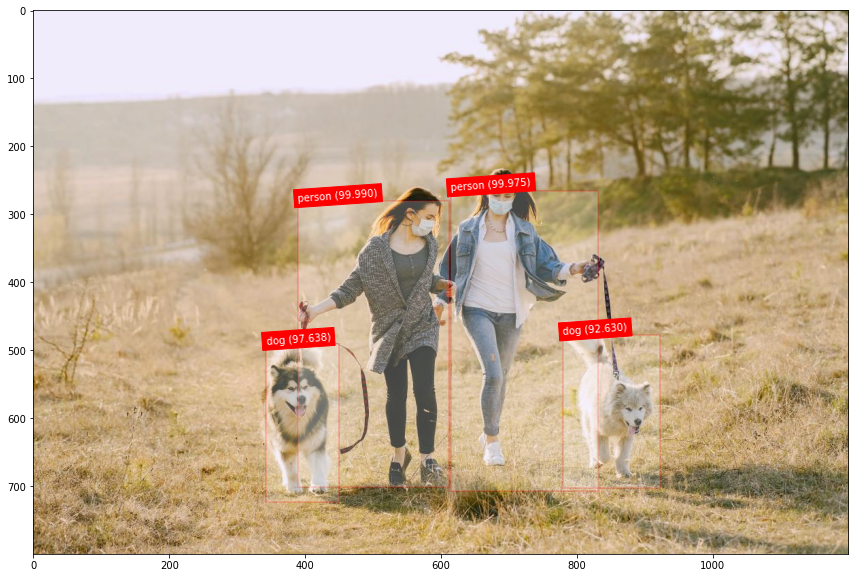
網上基于PyTorch[1]或者TF[2]等庫的 YOLO v3 實現版本很多,可以直接拿來把玩。下面是網上隨手下載的幾個圖像的測試結果,看著效果是不是還可以呢。



6小 結
先回顧下面這個圖,看看是否了解每個步驟的含義。
然后再用一個圖來總結一下流程,
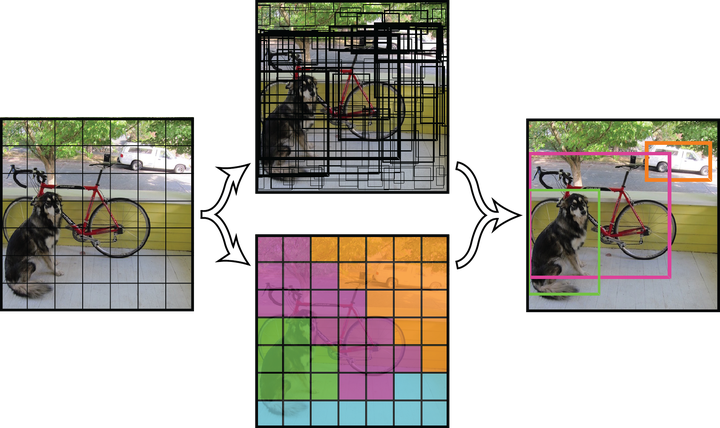
接下來根據輸出的目標置信度淘汰一大批包圍盒,在使用非極大值抑制繼續淘汰一批,最后剩下檢測到的目標,下圖是這些步驟的簡化版本演示圖。
參考代碼
[1]
PyTorch 實現:https://github.com/eriklindernoren/PyTorch-YOLOv3
[2]
TensorFlow 實現:https://machinelearningmastery.com/how-to-perform-object-detection-with-yolov3-in-keras/
審核編輯 :李倩
-
檢測算法
+關注
關注
0文章
122瀏覽量
25757 -
網絡架構
+關注
關注
1文章
101瀏覽量
13583
原文標題:圖解目標檢測算法之 YOLO
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
Melexis推出針對FIR陣列的免費版人員檢測算法
基于級聯分類器的人臉檢測基本原理

有哪些常見的AI算法可以用于裝置數據的異常檢測?

基于FPGA的SSD目標檢測算法設計
基于LockAI視覺識別模塊:C++目標檢測
基于RK3576開發板的車輛檢測算法
基于RK3576開發板的安全帽檢測算法
基于RV1126開發板的車輛檢測算法開發
基于RV1126開發板的安全帽檢測算法開發



 工商網監
工商網監
評論