 使用Thanos+Prometheus+Grafana構建監控系統
使用Thanos+Prometheus+Grafana構建監控系統

對于彈性伸縮和高可用的系統來說,一般有大量的指標數據需要收集和存儲,如何為這樣的系統打造一個監控方案呢?本文介紹了如何使用 Thanos+Prometheus+Grafana 構建監控系統。
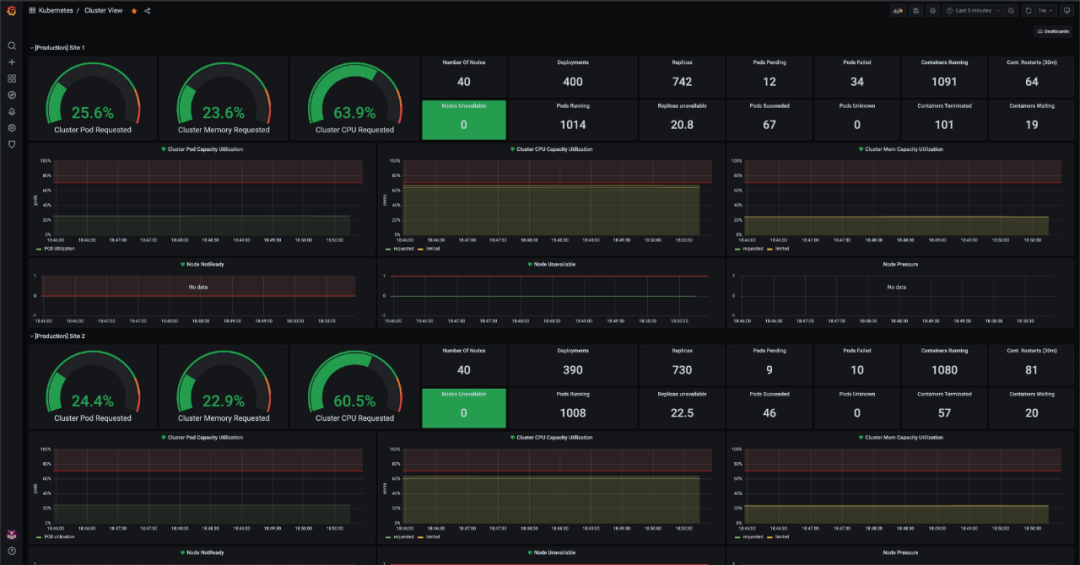
集群容量概覽
直到今年 1 月,我一直在使用一款企業級監控解決方案來監控 Kubernetes 集群,這款監控方案還用于 APM。它用起來很自然,與 Kubernetes 的集成非常容易,只需要進行一些細微的調整,并且可以集成 APM 和基礎設施指標。
盡管這款監控方案可以很容易地收集和存儲數據,但使用指標創建警報卻有很大的查詢限制。經常我們收到的告警和儀表盤上顯示的內容會不一樣。更不用說我們有 6 個集群,收集和存儲的指標數量非常多,這在很大程度上增加了我們的經濟成本。
經過一番考慮,我們認識到繼續使用這款監控方案弊大于利。是時候替換我們的監控方案了!但是,該使用什么產品或者工具呢?Grafana 是可視化工具的最佳選項,但我們的“后端”需要具備彈性伸縮和高可用能力,該使用什么工具呢?
純粹使用 OpenTSDB 的話,安裝需要太多的工作和精力;單機 Prometheus 不提供復制能力,還需要為其配備多個數據庫;TimeScaleDB 看起來不錯,但我不太會使用 PostgreSQL。
在對以上這些方案進行了一些實驗后,我查看了 CNCF 網站,最后找到了 Thanos!它滿足我們所有的需求:可長期保留數據、可復制、高可用、適合微服務、對使用相同數據庫的所有集群有一個 global view!
架構
我們的集群上沒有可用的持久化存儲(所有服務都保持無狀態),所以默認的 Prometheus + Thanos sidecar 方法不可用,metric 存儲必須置于集群之外。此外,集群之間相互隔離,將 Thanos 組件綁定到一組特定的集群是不可能的,必須從“外部”監控集群。
綜上所述,考慮到高可用性以及 Thanos 在虛擬機上運行的可能性,我們最終的架構是這樣的:
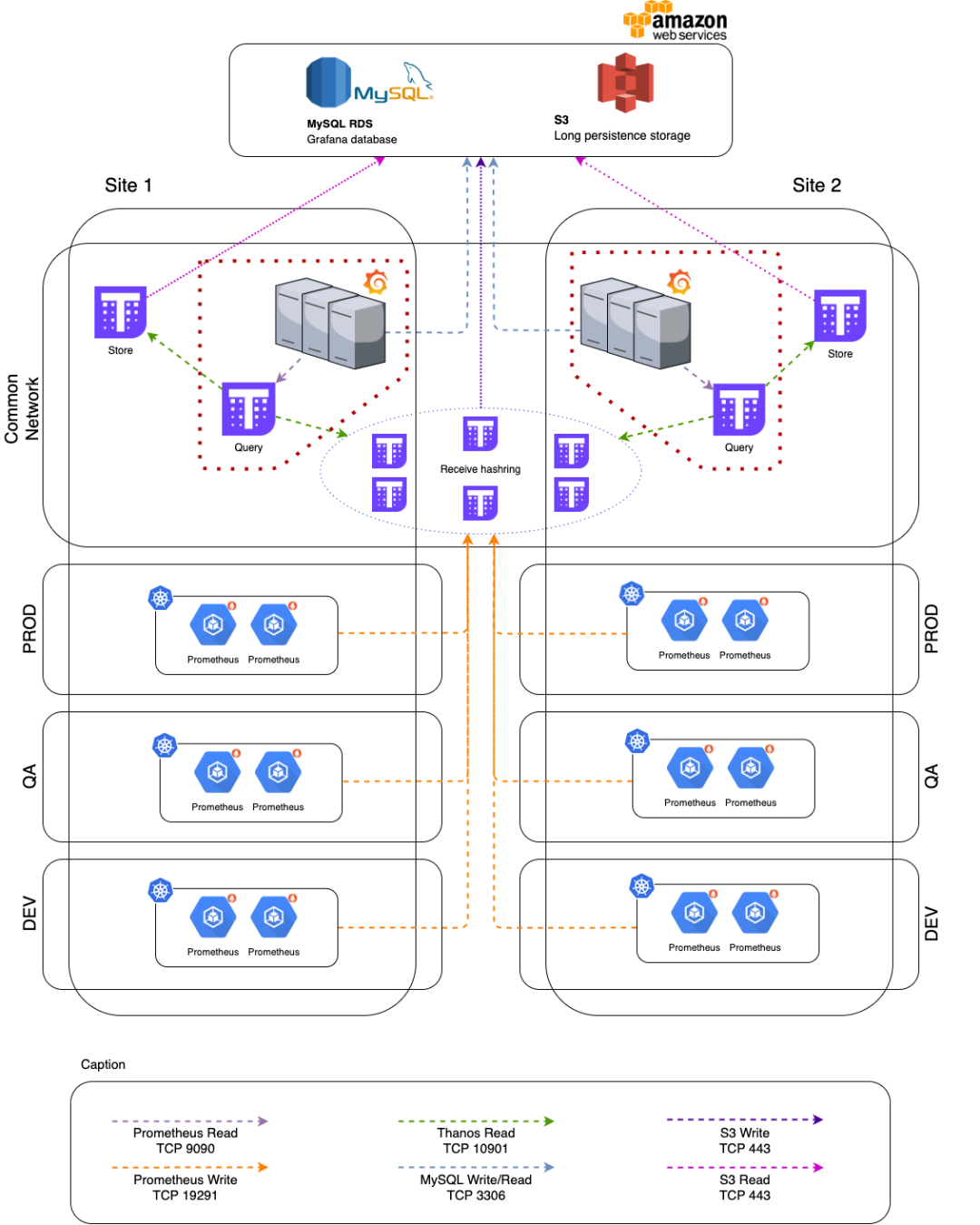
如圖所示,我們是多數據中心的架構。其中每個中心都有一組 Grafana + Query 服務器,一組存儲服務器和三個 Receive 服務器(集群數量的一半)。
Grafana 使用的數據庫還有一個 AWS RDS。這個數據庫不必很龐大(降低成本),我們團隊也不需要管理 MySQL。
在 Thanos 提供的所有組件中,我們實現了其中的 4 個:
Receive:負責 TSDB,還管理所有運行 receive 的服務器和 TSBD 塊上傳到 S3 之間的復制。
Query:負責查詢 receive 數據庫。
Store:讀取 S3 以獲取不再存儲在 receive 中的長期 metrics。
Compactor:管理存儲在 S3 中的 TSDB 塊的數據下采樣和壓縮。
Data Ingestion
所有集群的 data ingestion 都由集群內運行的專用 Prometheus Pod 管理。它從 control plate(API 服務器、控制器和調度程序)、etcd 集群以及集群內的 Pod 收集指標,這些集群內具有與基礎設施和 Kubernetes 本身相關的指標(Kube-proxy、Kubelet、Node Exporter、State Metrics 、Metrics Server 和其他具有 scraping annotation 的 Pod)。
Prometheus Pod 然后將信息發送到使用遠程存儲配置管理 TSDB 的 receive 服務器之一。
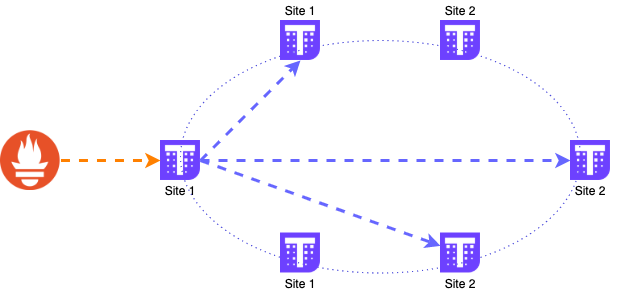
data ingestion
所有數據都發送到單個服務器,然后復制到其他服務器。Prometheus 使用的 DNS 地址是一個 DNS GSLB,它探測每個 receive 服務器并平衡健康的服務器之間的 DNS 解析,在所有服務器之間分擔負載,因為 DNS 解析只為每個 DNS 查詢提供一個 IP。
需要強調一下,數據必須發送到單個 receive 實例并讓它管理復制,發送相同的 metric 會導致復制失敗和行為異常。
在這個層面上,metrics 也會上傳到 S3 存儲桶進行長期留存。Receive 每 2 小時(當每個 TSDB 塊關閉時)上傳一次 block,這些 metric 可用于使用 Store 組件進行查詢。
還可以設置本地數據的保留時間。在這種情況下,所有本地數據都會保留 30 天以供日常使用和故障排除,這樣可以加快查詢速度。
超過 30 天的數據僅在 S3 上可用,最長可保留 1 年,用于長期評估和比較。
數據查詢
數據被收集并存儲在 receiver 中以供查詢。這部分也設置為多數據中心可用。
每臺服務器都運行 Grafana 和 Query,如果其中一臺(或兩臺)出現故障,我們可以更輕松地從負載均衡器中識別并刪除。在 Grafana 中,數據源配置為 localhost,因此它始終使用本地 Query 來獲取數據。
對于查詢配置,它必須知道所有存儲了 metrics 的服務器(Receiver 和 Store)。query 組件知道哪個服務器在線并且能夠從它們收集 metrics。
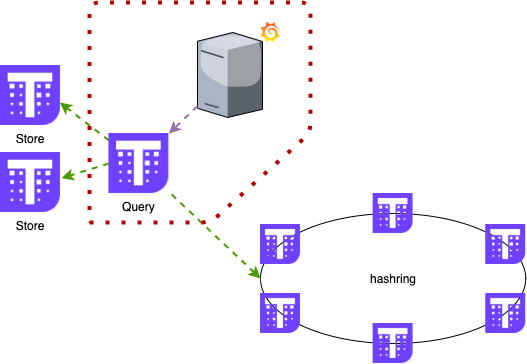
數據查詢
它還管理重復數據刪除,因為它查詢所有服務器并配置了 replication,所有 metrics 都有多個副本。可以使用分配給 metrics 的標簽和查詢參數 (--query.replica-label=QUERY.REPLICA-LABEL) 來完成。通過這些配置,query 組件知道從 Receiver 和 Store 收集的 metrics 是否重復并僅使用一個數據點。
長期數據
如前所述,數據在本地最多保留 30 天,其他所有內容都存儲在 S3 上。這樣可以減少 Receiver 上所需的空間量并降低成本,因為塊存儲比對象存儲更貴。更何況查詢超過 30 天的數據不是很常見,主要用于資源使用歷史和預測。
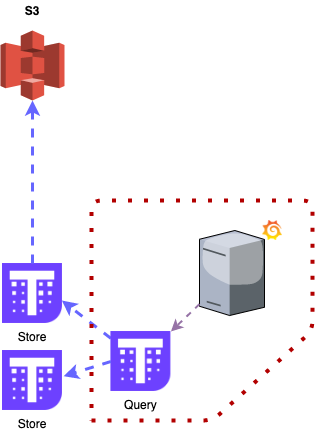
遠程數據查詢
該 Store 還保留存儲在 S3 存儲桶上的每個 TSDB 塊的索引的本地副本,因此如果需要查詢超過 30 天的數據,它知道要下載和使用哪些塊來提供數據。
數據情況
考慮到所有集群,該監控方案:
監控了 6 個 Kubernetes 集群;
收集了 670 個服務的 metrics;
使用 Node Exporter 監控了 246 個服務器;
每分鐘收集約 27w 個指標;
每天 ingest 約 7.3 GB 的數據,或每月 ingest 約 226.3 GB 的數據;
為 Kubernetes 組件創建了 40 個專用儀表盤;
在 Grafana 上創建了 116 個警報。
對于每月費用,由于大部分組件在本地運行,成本降低了 90.61%,從每月 38,421.25 美元降至 3,608.99 美元,其中包括 AWS 服務成本。
總結
配置和設置上述架構大約需要一個月左右的時間,包括測試其他一些解決方案、驗證架構、實現、在集群上開啟收集以及創建所有儀表盤。
在第一周,好處是顯而易見的。監控集群變得更加容易,儀表盤可以快速構建和定制,收集 metrics 幾乎是即插即用的,大多數應用程序以 Prometheus 格式導出 metrics,并根據 annotations 自動收集。
此外,通過集成 Grafana 的 LDAP 可以達到更精細的團隊權限控制。開發人員和 SRE 可以訪問大量儀表盤,其中包含有關其命名空間、ingress 等的相關 metrics。
原文標題:使用 Thanos 和 Prometheus 打造一個高可用的 Kubernetes 監控系統
文章出處:【微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
審核編輯:湯梓紅
-
監控系統
+關注
關注
21文章
4184瀏覽量
185049 -
kubernetes
+關注
關注
0文章
268瀏覽量
9516 -
Prometheus
+關注
關注
0文章
36瀏覽量
2062
原文標題:使用 Thanos 和 Prometheus 打造一個高可用的 Kubernetes 監控系統
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
Prometheus的架構原理從“監控”談起
阿里云容器Kubernetes監控(二) - 使用Grafana展現Pod監控數據
prometheus做監控服務的整個流程介紹
簡述linux-arm64 UOS安裝開源Grafana的步驟

SpringBoot+Prometheus+Grafana實現自定義監控
Grafana 9泰酷了吧
基于kube-prometheus的大數據平臺監控系統設計
從零入門Prometheus:構建企業級監控與報警系統的最佳實踐指南
使用Prometheus與Grafana實現MindIE服務可視化監控功能



 工商網監
工商網監
評論