") 結(jié)合句子間差異的無監(jiān)督句子嵌入對比學習方法-DiffCSE
結(jié)合句子間差異的無監(jiān)督句子嵌入對比學習方法-DiffCSE

寫在前面
今天分享給大家一篇NAACL2022論文,結(jié)合句子間差異的無監(jiān)督句子嵌入對比學習方法-DiffCSE,全名《DiffCSE: Difference-based Contrastive Learning for Sentence Embeddings》。該篇論文主要是在SimCSE上進行優(yōu)化,通過ELECTRA模型的生成偽造樣本和RTD(Replaced Token Detection)任務(wù),來學習原始句子與偽造句子之間的差異,以提高句向量表征模型的效果。
paper:https://arxiv.org/pdf/2204.10298.pdf
github:https://github.com/voidism/DiffCSE
介紹
句向量表征技術(shù)目前已經(jīng)通過對比學習獲取了很好的效果。而對比學習的宗旨就是拉近相似數(shù)據(jù),推開不相似數(shù)據(jù),有效地學習數(shù)據(jù)表征。SimCSE方法采用dropout技術(shù),對原始文本進行數(shù)據(jù)增強,構(gòu)造出正樣本,進行后續(xù)對比學習訓練,取得了較好的效果;并且在其實驗中表明”dropout masks機制來構(gòu)建正樣本,比基于同義詞或掩碼語言模型的刪除或替換等更復雜的增強效果要好得多。“。這一現(xiàn)象也說明,「直接增強(刪除或替換)往往改變句子本身語義」。
paper:https://aclanthology.org/2021.emnlp-main.552.pdf
github:https://github.com/princeton-nlp/SimCSE
論文解讀:https://zhuanlan.zhihu.com/p/452761704
Dangovski等人發(fā)現(xiàn),在圖像上,采用不變對比學習和可變對比學習相互結(jié)合的方法可以提高圖像表征的效果。而采用不敏感的圖像轉(zhuǎn)換(如,灰度變換)進行數(shù)據(jù)增強再對比損失來改善視覺表征學習,稱為「不變對比學習」。而「可變對比學習」,則是采用敏感的圖像轉(zhuǎn)換(如,旋轉(zhuǎn)變換)進行數(shù)據(jù)增強的對比學習。如下圖所示,做左側(cè)為不變對比學習,右側(cè)為可變對比學習。對于NLP來說,「dropout方法」進行數(shù)據(jù)增強為不敏感變化,采用「詞語刪除或替換等」方法進行數(shù)據(jù)增強為敏感變化。
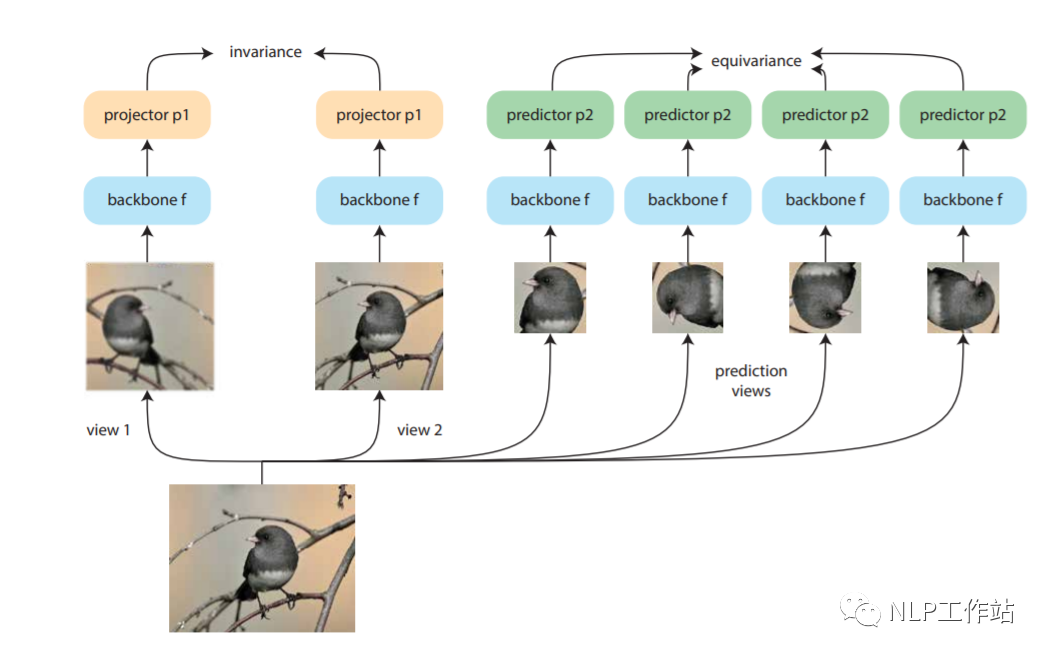
paper:https://arxiv.org/pdf/2111.00899.pdf
作者借鑒Dangovski等人在圖像上的做法,提出來「DiffCSE方法」,通過使用基于dropout masks機制的增強作為不敏感轉(zhuǎn)換學習對比學習損失和基于MLM語言模型進行詞語替換的方法作為敏感轉(zhuǎn)換學習「原始句子與編輯句子」之間的差異,共同優(yōu)化句向量表征。
模型
模型如下圖所示,
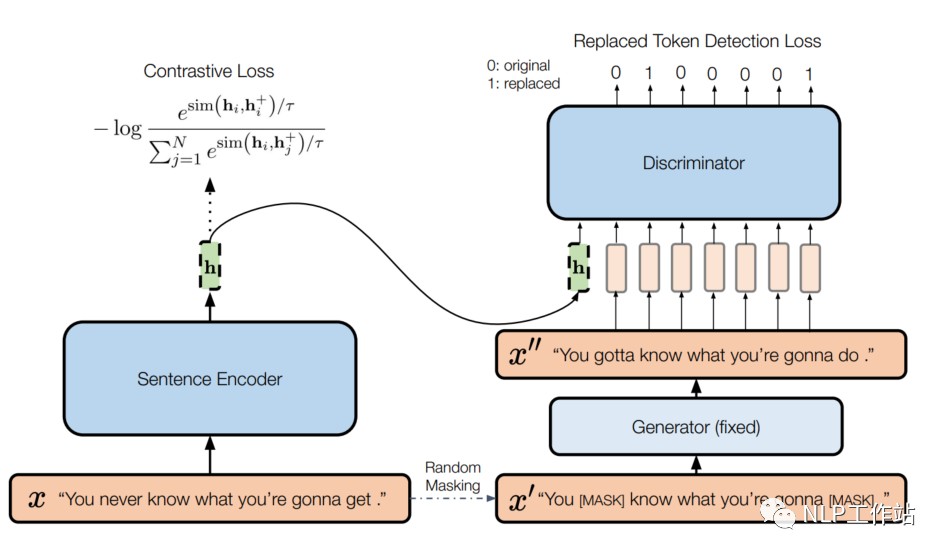
左側(cè)為一個標準的SimCSE模型,右側(cè)為一個帶條件的句子差異預測模型。給定一個句子,SimCSE模型通過dropout機制構(gòu)造一個正例,使用BERT編碼器f,獲取句向量,SimCSE模型的訓練目標為:
其中,為訓練輸入batch大小,為余弦相似度,為溫度參數(shù).
右側(cè)實際上是ELECTRA模型,包含生成器和判別器。給定一個長度為T的句子,,生成一個隨機掩碼序列,其中。使用MLM預訓練語言模型作為生成器G,通過掩碼序列來生成句子中被掩掉的token,獲取生成序列。然后使用判別器D進行替換token檢測,也就是預測哪些token是被替換的。其訓練目標為:
針對一個batch的訓練目標為。
最終將兩個loss通過動態(tài)權(quán)重將其結(jié)合,
為了使判別器D的損失可以傳播的編碼器f中,將句向量拼接到判別器D的輸入中,輔助進行RTD任務(wù),這樣做可以鼓勵編碼器f使信息量足夠大,從而使判別器D能夠區(qū)分和之間的微小差別。
當訓練DiffCSE模型時,固定生成器G參數(shù),只有句子編碼器f和鑒別器D得到優(yōu)化。訓練結(jié)束后,丟棄鑒別器D,只使用句子編碼器f提取句子嵌入對下游任務(wù)進行評價。
結(jié)果&分析
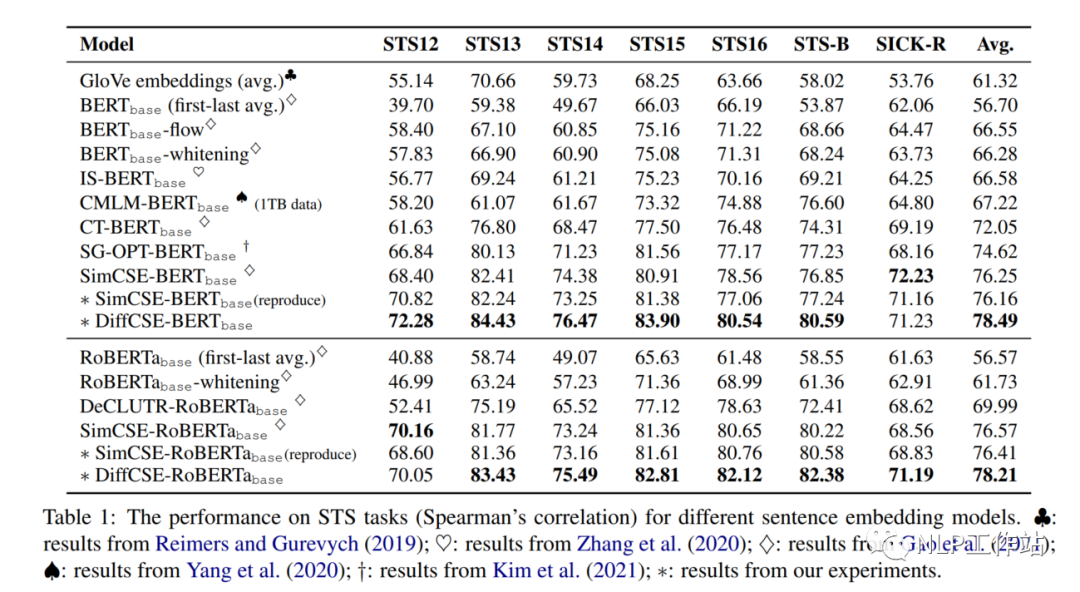
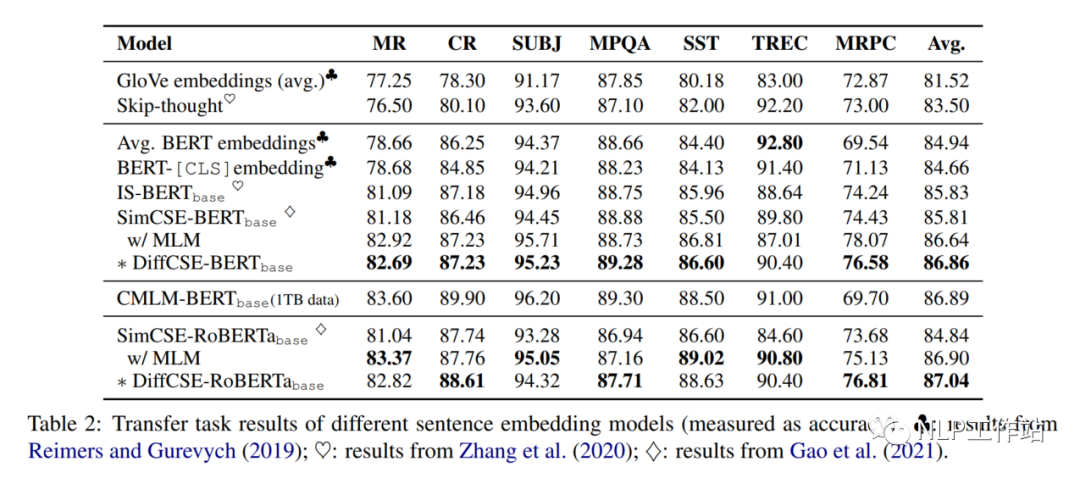
在句子相似度任務(wù)以及分類任務(wù)上的效果,如下表1和表2所示,相比與SimCSE模型均有提高,
為了驗證DiffCSE模型具體是哪個部分有效,進行以下消融實驗。
Removing Contrastive Loss
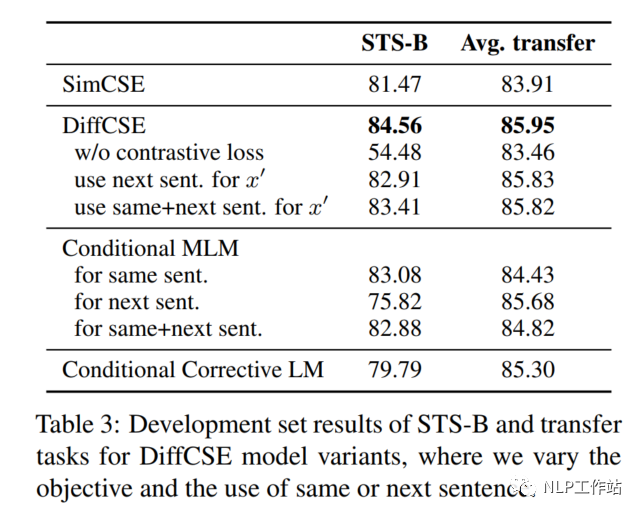
如表3所示,當去除對比學習損失,僅采用RTD損失時,在句子相似度任務(wù)上,下降30%,在分類任務(wù)上下降2%。
Next Sentence vs. Same Sentence
如表3所示,當將同句話預測任務(wù),變成預測下句話任務(wù)時,在句子相似度任務(wù)和分類任務(wù)上,具有不同程度的下降。
Other Conditional Pretraining Tasks
DiffCSE模型采用MLM模型和LM模型分別作為生成器時,效果如表3所示,在句子相似度任務(wù)和分類任務(wù)上,具有不同程度的下降。句子相似度任務(wù)上下降的較為明顯。
Augmentation Methods: Insert/Delete/Replace
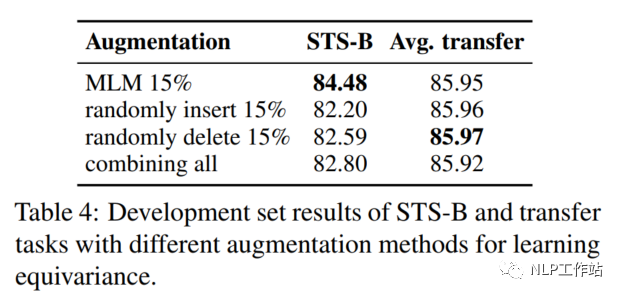
將MLM模型生成偽造句換成隨機插入、隨機刪除或隨機替換的效果,如表示所4,MLM模型的效果綜合來說較為優(yōu)秀。
Pooler Choice
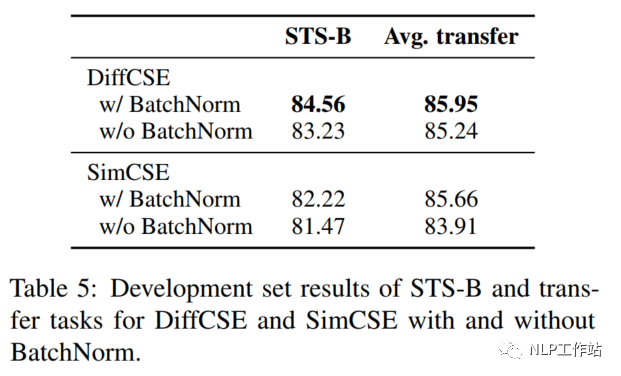
在SimCSE模型中,采用pooler層(一個帶有tanh激活函數(shù)的全連接層)作為句子向量輸出。該論文實驗發(fā)現(xiàn),采用帶有BN的兩層pooler效果更為突出,如表5所示;并發(fā)現(xiàn),BN在SimCSE模型上依然有效。
代碼如下:
classProjectionMLP(nn.Module):
def__init__(self,config):
super().__init__()
in_dim=config.hidden_size
hidden_dim=config.hidden_size*2
out_dim=config.hidden_size
affine=False
list_layers=[nn.Linear(in_dim,hidden_dim,bias=False),
nn.BatchNorm1d(hidden_dim),
nn.ReLU(inplace=True)]
list_layers+=[nn.Linear(hidden_dim,out_dim,bias=False),
nn.BatchNorm1d(out_dim,affine=affine)]
self.net=nn.Sequential(*list_layers)
defforward(self,x):
returnself.net(x)
Size of the Generator
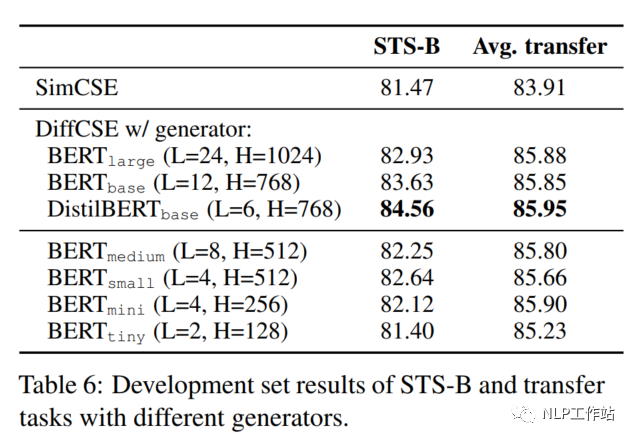
在DiffCSE模型中,嘗試了不同大小的生成器G,如下表所示,DistilBERTbase模型效果最優(yōu)。并且發(fā)現(xiàn)與原始ELECTRA模型的結(jié)論不太一致。原始ELECTRA認為生成器的大小在判別器的1/4到1/2之間效果是最好的,過強的生成器會增大判別器的難度。而DiffCSE模型由于融入了句向量,導致判別器更容易判別出token是否被替換,所以生成器的生成能力需要適當提高。
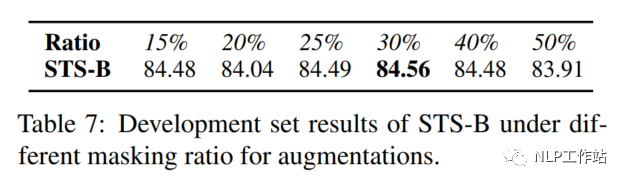
Masking Ratio
對于掩碼概率,經(jīng)實驗發(fā)現(xiàn),在掩碼概率為30%時,模型效果最優(yōu)。
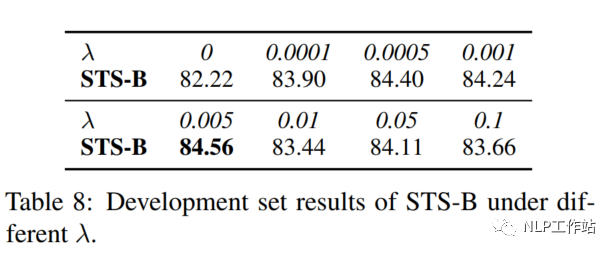
Coefficient λ
針對兩個損失之間的權(quán)重值,經(jīng)實驗發(fā)現(xiàn),對比學習損失為RTD損失200倍時,模型效果最優(yōu)。
總結(jié)
個人覺得這篇論文的主要思路還是通過加入其他任務(wù),來增強句向量表征任務(wù),整體來說挺好的。但是該方法如何使用到監(jiān)督學習數(shù)據(jù)上,值得思考,歡迎留言討論。
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7335瀏覽量
94754 -
生成器
+關(guān)注
關(guān)注
7文章
322瀏覽量
22706 -
向量
+關(guān)注
關(guān)注
0文章
55瀏覽量
12036
原文標題:DiffCSE:結(jié)合句子間差異的無監(jiān)督句子嵌入對比學習方法
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
無鉛焊接下,低TG與高TG板材表現(xiàn)差異全解析
【EMC標準分析】GB_T 18655最新2025版與2018版的標準差異對比

有鉛VS無鉛:PCBA加工工藝的6大核心差異,工程師必看
MSCMG無刷直流電機改進的I_f無位置起動方法
MSCMG無刷直流電機改進的I_f無位置起動方法
ARM入門學習方法分享
英語單詞學習頁面+單詞朗讀實現(xiàn) -- 【1】頁面實現(xiàn) ##HarmonyOS SDK AI##
機器學習異常檢測實戰(zhàn):用Isolation Forest快速構(gòu)建無標簽異常檢測系統(tǒng)

第一章 W55MH32 高性能以太網(wǎng)單片機的學習方法概述

無源晶振vs有源晶振:參數(shù)差異如何影響系統(tǒng)設(shè)計
使用MATLAB進行無監(jiān)督學習

嵌入式適合自學嗎?
18個常用的強化學習算法整理:從基礎(chǔ)方法到高級模型的理論技術(shù)與代碼實現(xiàn)



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論