 3D視覺技術內容理解領域的研究進展
3D視覺技術內容理解領域的研究進展

Facebook 的博客詳細介紹了其在 3D 內容理解領域的研究進展。

要想解釋現實世界,AI 系統必須理解三維視覺場景。而這需要機器人學、導航,甚至增強現實應用等等。2D 圖像和視頻所描述的場景和對象本身仍是三維的,而真正智能的內容理解系統必須能夠從杯子的視頻中識別出手柄的幾何情況,或者識別出照片前景和背景中的對象。
不久之前,Facebook 發布博客介紹了多個新研究項目的詳情,這些項目以不同卻互補的方式推進 3D 圖像理解領域的當前最優水平。相關研究已被 ICCV 2019 接收,它利用不同類型和數量的訓練數據和輸入,解決了大量用例和環境中的 3D 內容理解問題。
Mesh R-CNN 是一種新型的當前最優方法,可基于大量 2D 現實世界圖像預測出最準確的 3D 形狀。該方法利用目標實例分割任務的通用 Mask R-CNN 框架,能夠檢測出復雜的對象,如椅子腿或者重疊的家具。 利用 Mesh R-CNN 的替代和補充性方法 C3DPO,Facebook 通過解釋三維幾何,首次在三個基準數據集(涉及超過 14 種對象類別)上實現了大規模非剛性三維形狀重建。而該成果的實現僅使用了 2D 關鍵點,未使用 3D 標注。 Facebook 提出了一種新方法來學習圖像和 3D 形狀之間的關聯,同時大幅減少對標注訓練樣本的需求。這向著為更多對象類別創建 3D 表征的自監督系統邁出了一步。 Facebook 開發了一種新技術 VoteNet,可對激光雷達等傳感器輸出的 3D 圖像執行目標檢測。大部分傳統的目標檢測系統依賴 2D 圖像信號,而 VoteNet 僅基于 3D 點云,且取得了高于之前研究的精度。
這些研究基于使用深度學習預測和定位圖像中對象的近期進展,以及執行 3D 形狀理解(如體素、點云和網格)的新工具和架構。計算機視覺領域覆蓋大量任務,而 3D 理解將對推進 AI 系統更準確地理解、解釋現實世界并在其中運行起到核心作用。
在預測無約束受遮擋對象的 3D 形狀任務中達到當前最優
感知系統(如 Mask R-CNN)是理解圖像的強大通用工具。但是,這些系統只能對 2D 圖像執行預測,忽略了世界的 3D 結構。Facebook 利用 2D 感知領域的進展,設計了一個 3D 目標重建模型,該模型可以基于無約束現實世界圖像預測 3D 對象形狀,而這些圖像包含大量視覺難題,如對象被遮擋、雜亂,以及多樣化的拓撲結構。向對此類復雜性具備穩健性的目標檢測系統添加第三個維度,需要更強大的工程能力,而目前的工程框架阻礙了該領域的進步。

Mesh R-CNN 預測輸入圖像中的對象實例,并推斷其 3D 形狀。為了捕捉幾何和拓撲的多樣性,Mesh R-CNN 首先預測粗糙的體素,然后細化以執行準確的網格預測。
為了解決這些挑戰,Facebook 為 Mask R-CNN 的 2D 目標分割系統添加了網格預測部分,從而構建了 Torch3d。這是一個 PyTorch 庫,具備高度優化的 3D 算子以實現該系統。Mesh R-CNN 使用 Mask R-CNN 來檢測和分類圖像中的不同對象,然后利用新的網格預測器推斷對象的 3D 形狀,該預測器由體素預測和網格細化兩個步驟構成,這個兩階段流程可以實現優于之前細粒度 3D 結構預測研究的結果。Torch3d 保證 chamfer distance、可微網格采樣和可微渲染器等復雜操作的高效、靈活和模塊化實現,從而使得上述流程得以順利進行。
Facebook 利用 Detectron2 實現 Mesh R-CNN,它使用 RGB 圖像作為輸入,既能檢測對象,也能預測 3D 形狀。與 Mask R-CNN 利用監督學習獲得強大的 2D 感知能力類似,新方法 Mesh R-CNN 利用完全監督學習(即圖像和網格對)學習 3D 預測。在訓練階段中,Facebook 研究人員使用 Pix3D 數據集(包含一萬個圖像和網格對),該數據集的規模遠遠小于通常包含數十萬圖像和對象標注的 2D 基準數據集。
Facebook 在兩個數據集上評估 Mesh R-CNN 的性能,均獲得了優秀的結果。在 Pix3D 數據集上,Mesh R-CNN 是首個能夠同時檢測出所有對象類別,并基于多樣、雜亂、被遮擋的家具場景估計其完整 3D 形狀的系統。之前的研究主要關注在完美剪裁、未受遮擋的圖像分割部分上訓練得到的模型。在 ShapeNet 數據集上,將體素預測和網格細化結合起來的 Mesh R-CNN 方法的性能比之前的研究高出 7%。

Mesh R-CNN 系統概覽。研究人員用 3D 形狀推斷增強了 Mask R-CNN。
在現實世界中準確預測和重建無約束場景的形狀是提升新體驗的重要一步,如虛擬現實以及其他形式的遠程呈現。不過,收集標注 3D 圖像數據要比 2D 圖像更加復雜、耗時,這也是 3D 形狀預測數據集落后于 2D 數據集的原因。因而,Facebook 探索了不同的方法,嘗試利用監督和自監督學習重建 3D 對象。
Mesh R-CNN 相關論文,參見:https://arxiv.org/abs/1906.02739
利用 2D 關鍵點重建 3D 對象類別
當訓練過程中無法獲得網格及其對應圖像時,對靜態對象或場景執行完整重建則無必要,而 Facebook 開發出一種替代方法——C3DPO 系統(Canonical 3D Pose Networks)。該系統構建 3D 關鍵點模型重建,重建結果堪比使用充足 2D 關鍵點監督信號獲得的當前最優結果。C3DPO 幫助我們用弱監督的方式理解 3D 幾何,該系統適合大規模部署。

對于廣泛的對象類別,C3DPO 能夠基于檢測出的 2D 關鍵點生成 3D 關鍵點,并準確區分視角變化和形狀變化。
2D 關鍵點追蹤對象類別的特定部分(如人體關節或鳥類翅膀),為對象幾何及其變形或視角變化提供完整的線索。得到的 3D 關鍵點很有用,比如可用于建模 3D 人臉和全身網格,以輸出更逼真的 VR 頭像圖。與 Mesh R-CNN 類似,C3DPO 使用具備遮擋和缺失值的無約束圖像重建 3D 對象。
C3DPO 是首個利用數千個 2D 關鍵點,重建包含數十萬圖像的數據集的方法。該模型在三個數據集(超過 14 種不同非剛性對象類別)上獲得了當前最優的重建準確率。
代碼地址:https://github.com/facebookresearch/c3dpo_nrsfm
該模型有兩個重要創新。首先,給定一組單目 2D 關鍵點,C3DPO 可以預測對應攝像機視角的參數,以及 3D 關鍵點的標準位置。其次,Facebook 提出了一種新型正則化技術 canonicalization,它包含一個輔助深度網絡,可以與 3D 重建網絡一道學習。該技術解決了對 3D 視角和形狀執行因式分解導致的模糊性。這兩個創新促使更優秀數據統計模型的誕生。
以前,這樣的 3D 重建是不可實現的,原因在于之前基于矩陣分解的方法會帶來內存限制。與深度網絡不同,之前方法無法以「minibatch」機制運行。之前方法在建模變形時利用了多個同步圖像,并構建圖像與即時 3D 重建結果之間的對應關系,這對硬件有很高要求,此類硬件通常出現在特殊實驗室中。而 C3DPO 使得在無法部署 3D 捕捉硬件時也能實現 3D 重建。
C3DPO 相關論文,參見:https://research.fb.com/publications/c3dpo-canonical-3d-pose-networks-for-non-rigid-structure-from-motion/
從圖像集中學習像素-表面映射(pixel-to-surface mapping)

該系統學得一個參數化卷積神經網絡(CNN),該網絡以圖像作為輸入,并預測像素級標準表面圖(per-pixel canonical surface map,表示像素在模板形狀上的對應位置點)。2D 圖像和 3D 形狀之間的標準表面圖中的類似顏色表示對應關系。
Facebook 進一步減少了開發通用對象類別 3D 理解系統所需的監督信號。研究人員提出一種利用無標注圖像集的方法,這些圖像僅具備恰當的自動實例分割。他們沒有顯式地預測圖像的底層 3D 結構,轉而處理一個補充性任務:將圖像中的像素映射至類別級 3D 形狀模板的表面。
該映射不僅可以幫助我們在類別級 3D 形狀背景下理解圖像,還提供泛化同類對象之間對應關系的能力。例如,人們在看到下圖左側突出顯示的鳥喙時,可以很輕松地在右圖中找出對應點的位置。

這是因為我們直觀上理解這些實例之間的共享 3D 結構。Facebook 提出的將圖像像素映射至標準 3D 表面的新方法幫助學得系統也具備這種能力。對該方法在不同實例上遷移對應關系的效果進行評估后,研究人員發現其準確率是之前未利用圖像底層 3D 結構的自監督方法的 2 倍。
使得模型在監督信號大量減少的情況下還能學習的關鍵要素是:從像素到 3D 表面的映射,輔以從 3D 表面到像素的逆運算,可形成一個完整循環。Facebook 提出的新方法使這一關鍵要素得以運行,且學習過程中僅需使用免費無標注、具備恰當實例分割結果的公共圖像集。得到的系統還可即拿即用,與其他自上而下的 3D 預測方法一道應用,提供像素級 3D 理解。
代碼地址:https://github.com/nileshkulkarni/csm/
上述視頻中移動車輛的顏色是一致的,這表面該系統對正在移動和旋轉的對象生成不變的像素級嵌入。這種一致性可擴展到特定實例,也可用于需要理解不同對象共性的場景中。
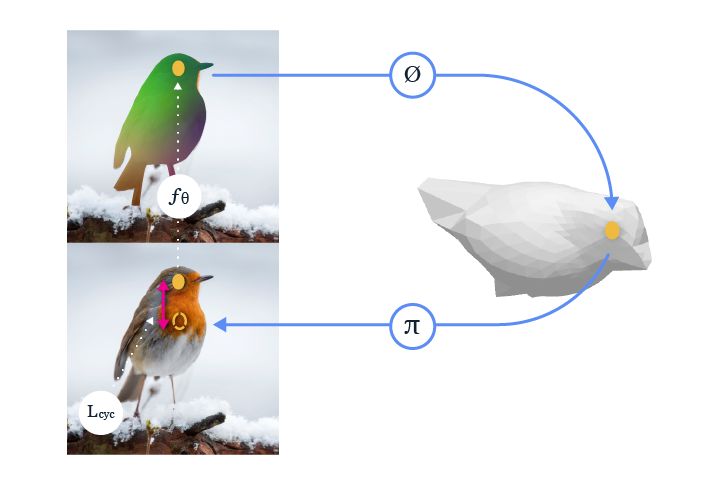
Facebook 提出的方法沒有直接學習兩張圖像之間的 2D 對應關系,而是學習 2D 到 3D 的對應,并確保 3D 到 2D 重新投影的一致性,這種一致性循環可作為學習 2D 到 3D 對應關系的監督信號。
例如,如果我們訓練一個系統去學習坐在椅子上的正確位置或者握杯子的合適位置,則學到的表征應在系統理解坐在另外一把椅子的合適位置或如何握住另一只杯子的時候依然有用。此類任務不僅能夠深化對傳統 2D 圖像和視頻內容的理解,還可以通過遷移對象表征提升 AR/VR 體驗。關于標準表面映射的更多信息,參見:https://research.fb.com/publications/canonical-surface-mapping-via-geometric-cycle-consistency/
在目前的 3D 系統中,改進目標檢測的基礎要素
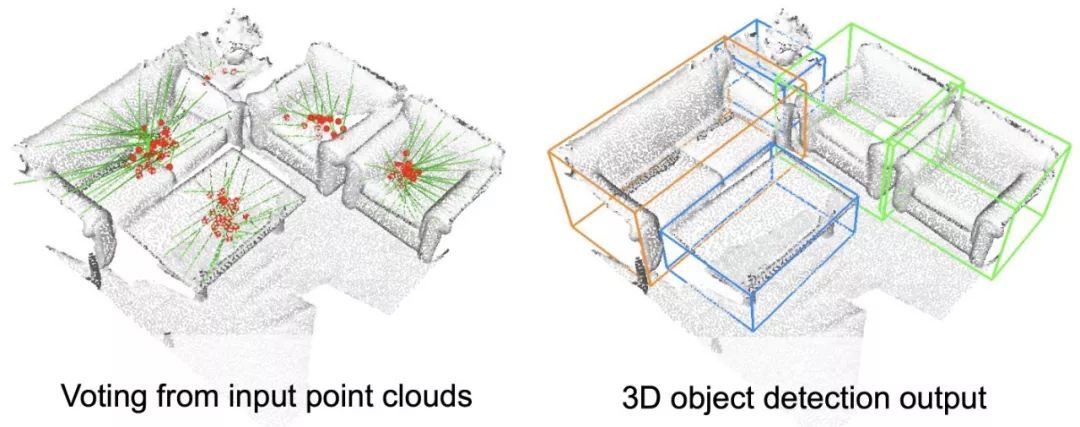
隨著前沿技術(如掃描 3D 空間的自動智能體和系統)的發展,我們需要推進針對 3D 數據的目標檢測機制。在這些案例中,3D 場景理解系統需要了解場景中有哪些對象以及它們的位置,以支持導航等高級任務。Facebook 對已有系統進行了改進,提出了高度準確的端到端 3D 目標檢測網絡 VoteNet,該網絡專為點云設計,相關論文《Deep Hough Voting for 3D Object Detection in Point Clouds》獲得了 ICCV 2019 最佳論文提名。與依賴 2D 圖像信號的傳統系統不同,VoteNet 是首批僅依賴 3D 點云數據的系統。該方法比之前研究更加高效,識別準確率也更高。
VoteNet 開源地址:https://github.com/facebookresearch/votenet
VoteNet 在 3D 目標檢測任務上的性能超過了之前所有方法,獲得了當前最優 3D 檢測結果,在 SUN RGB-D 和 ScanNet 數據集上的性能較之之前方法至少提升了 3.7 和 18.4 mAP。VoteNet 優于之前方法的原因是:僅使用幾何信息,不依賴標準彩色圖像。
VoteNet 設計簡單,模型緊湊,效率高,對全景圖像的處理速度約為 100 毫秒,內存占用也比之前方法小。該方法以深度相機獲得的 3D 點云作為輸入,返回對象的 3D 邊界框,且標明對象的語義類別。
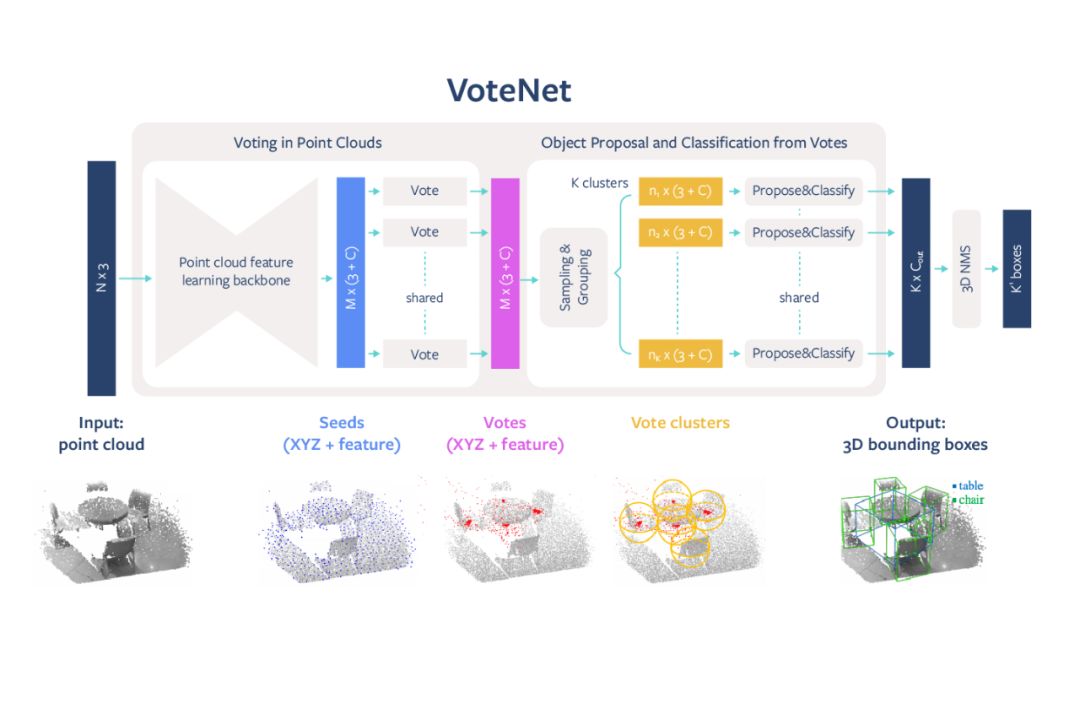
VoteNet 架構圖示。
受經典 Hough voting 算法啟發,Facebook 提出了一種投票機制。利用該機制可生成緊鄰對象中心的新點,將這些點分組并聚合以生成邊界框候選。使用通過深度神經網絡學得的投票基本思路,一組 3D 種子點投票競爭對象中心,以恢復對象的位置和類別。
隨著 3D 掃描儀在現實中的使用,尤其是在自動駕駛汽車、生物醫學等領域的普遍應用,通過定位和分類 3D 場景中的對象來實現對 3D 內容的語義理解變得尤為重要。向 2D 攝像頭補充一些更先進的深度相機傳感器以方便 3D 識別,這可以幫助我們捕捉到任意給定場景的更穩健視圖。使用 VoteNet,系統可以更好地識別出場景中的主要對象,并支持放置虛擬對象、導航和 LiveMap 構建等任務。
開發對現實世界具備更多了解的系統
3D 計算機視覺領域存在很多開放性研究問題,Facebook 正在試驗多個問題陳述、技術和監督方法,正如過去探索推動 2D 理解的最佳方式一樣。隨著數字世界更多地使用 3D 圖像和浸入式 AR/VR 體驗等產品,我們需要持續推進更準確理解視覺場景并與其中對象互動的復雜系統的開發。 當 AI 系統與其他感官結合起來時,如觸覺和自然語言理解,這些系統(如虛擬助手)可以更加無縫地發揮作用。這一前沿研究幫助我們向著構建和人類一樣更直觀理解三維世界的 AI 系統更進了一步。
本文介紹的研究論文已被 ICCV 2019 接收,還有一些新的計算機視覺工作,包括:
SlowFast:使用不同幀率的輸入從視頻中提取信息的方法。
TensorMask:使用密集的滑動窗口技術執行目標分割的方法。
審核編輯 :李倩
-
Facebook
+關注
關注
3文章
1432瀏覽量
59277 -
計算機視覺
+關注
關注
9文章
1715瀏覽量
47698 -
3D視覺
+關注
關注
4文章
488瀏覽量
29296
原文標題:一文看盡 Facebook 3D視覺技術研究進展
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
人形機器人 3D 視覺路線之爭:激光雷達、雙目和 3D - ToF 誰更勝一籌?
友思特技術 | 智能iToF技術:開啟高性價比3D視覺新紀元

基于3D視覺引導的移動式復合機器人設計:智能自動化革命的核心技術

2025 3D機器視覺的發展趨勢

3D 視覺系統供應商全景解析:技術迭代與國產力量的崛起
奧比中光3D視覺技術賦能IROS 2025研究成果
奧比中光領跑韓國機器人3D視覺市場
索尼與MIIIX幕象科技達成3D內容合作
季豐電子邀您相約2025國際3D視覺感知與應用大會
iTOF技術,多樣化的3D視覺應用
索尼與VAST達成3D業務合作
3D視覺傳感器如何變革工業領域
如何提高3D成像設備的部署和設計優勢
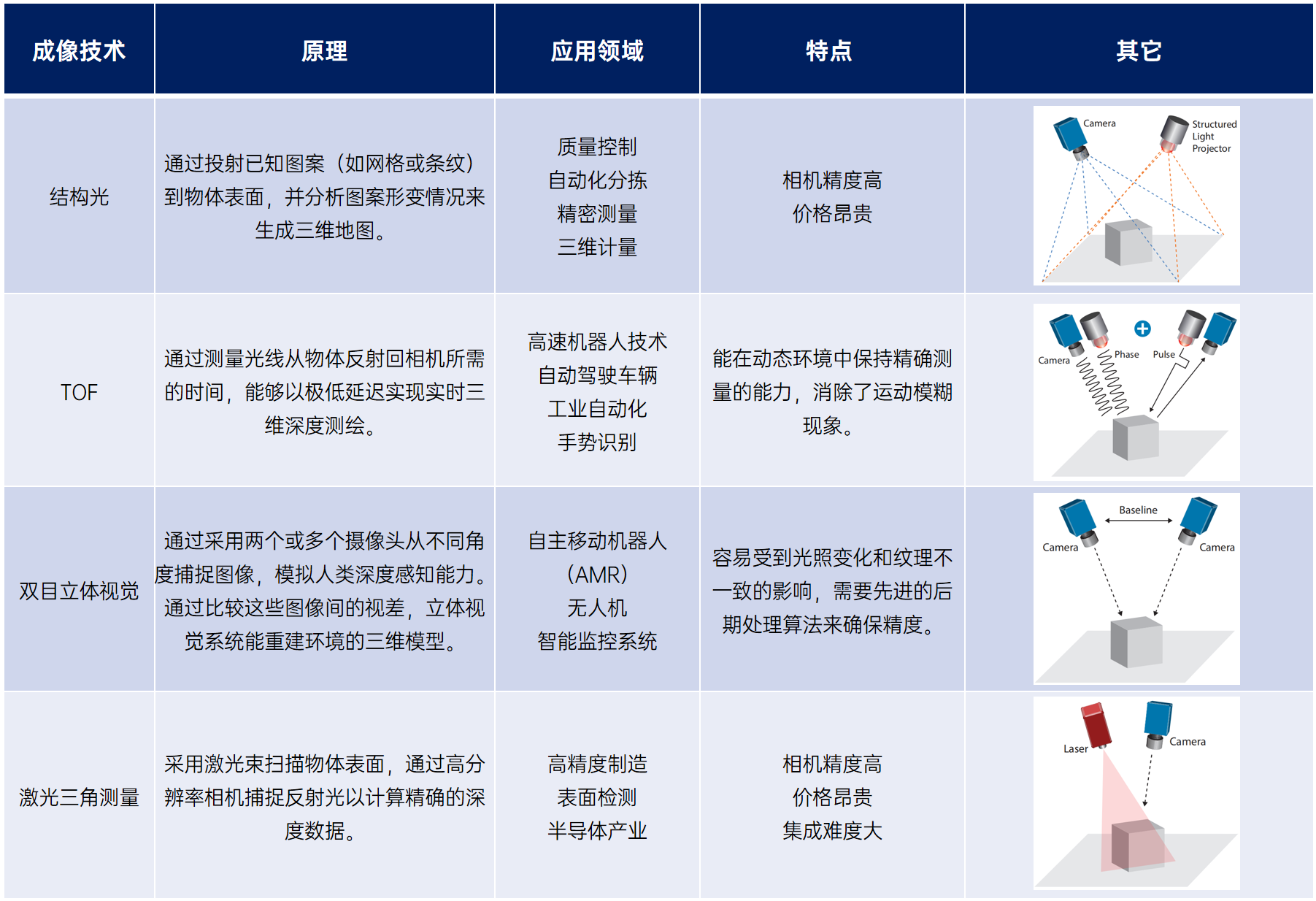
海伯森3D閃測傳感器,工業檢測領域的高精度利器




 工商網監
工商網監
評論