") 如何檢查相互競爭的模型并通過GPU獲得成功
如何檢查相互競爭的模型并通過GPU獲得成功

數(shù)據(jù)科學(xué)家和機(jī)器學(xué)習(xí)工程師經(jīng)常面臨“與 深度學(xué)習(xí) 相比使用 機(jī)器學(xué)習(xí) 分類器解決其業(yè)務(wù)問題”的困境。根據(jù)數(shù)據(jù)集的性質(zhì),一些數(shù)據(jù)科學(xué)家更喜歡經(jīng)典的機(jī)器學(xué)習(xí)方法。其他人采用最新的深度學(xué)習(xí)模式,而還有人追求“集成”模式,希望在可解釋性和性能這兩個方面都達(dá)到最佳。
機(jī)器學(xué)習(xí),特別是決策樹,導(dǎo)致了更先進(jìn)的 XGBoost 模型,比深度學(xué)習(xí)成熟得更早,并且有一些成熟的方法。深度學(xué)習(xí)在非表格計算機(jī)視覺、語言和語音識別領(lǐng)域表現(xiàn)出色。無論您選擇哪一種, GPU 都在加速數(shù)據(jù)科學(xué)用例,使其達(dá)到這樣的程度:對大型數(shù)據(jù)集的任何數(shù)據(jù)分析都只需要它們來滿足每天的便利性、快速迭代和結(jié)果。
RAPIDS 通過類似于 scikit-learn 和 pandas 等收藏夾的界面,使數(shù)據(jù)科學(xué)家更容易利用 GPU 。這里,我們使用的是一個表格數(shù)據(jù)集。經(jīng)典的提取 – 轉(zhuǎn)換 – 加載過程( ETL )是任何數(shù)據(jù)科學(xué)項目的核心起點。
對于GPU加速用例,NVIDIA NVTabular 應(yīng)用框架 推薦系統(tǒng) 使用 NVTabular -加速特征工程、預(yù)處理和數(shù)據(jù)加載庫,也可用于其他領(lǐng)域,如金融服務(wù)。
在本文中,我們將演示如何檢查相互競爭的模型(稱為 challenger models ),并使用 GPU 加速,通過簡單、經(jīng)濟(jì)高效且可理解的模型可解釋性應(yīng)用程序獲得成功。當(dāng) GPU 加速在模型開發(fā)過程中被多次使用時,建模者的時間將通過在數(shù)十次模型迭代中攤銷培訓(xùn)時間和降低成本而得到更有效的利用。
我們是在使用 公共房利美抵押貸款數(shù)據(jù)集 預(yù)測抵押貸款拖欠的情況下這樣做的。我們還展示了用于模型訓(xùn)練的 NVTabular 數(shù)據(jù)加載器獲得的簡單加速比。同樣的例子也可以擴(kuò)展到信用承銷、信用卡拖欠或其他一系列重要的分類問題。
所有金融信用風(fēng)險建模中的一個共同主題是對預(yù)期損失的關(guān)注。無論交易是一方欠另一方一定金額的兩個交易對手之間的交易協(xié)議,還是借款人欠貸款人每月還款金額的貸款協(xié)議,我們都可以通過以下方式查看預(yù)期損失 EL :
EL = PD x LGD x EAD
哪里:
PD :違約概率,考慮到人口中的所有貸款
LGD :違約造成的損失;介于 0 和 1 之間的值,用于測量未付貸款的百分比
EAD :違約風(fēng)險敞口,即剩余未償余額
PD 和 EL 附加到一個時間段,該時間段通常可以設(shè)置為每年或每月,具體取決于發(fā)放貸款的公司的選擇。
在我們的案例中,我們的目標(biāo)是根據(jù)個人貸款的特征預(yù)測最有可能拖欠的具體個人貸款。因此,我們主要關(guān)注影響 PD 利率的貸款,也就是說,將有預(yù)期損失的貸款與無預(yù)期損失的貸款分開。
機(jī)器學(xué)習(xí)與深度學(xué)習(xí)方法
機(jī)器學(xué)習(xí)( ML )和深度學(xué)習(xí)( DL )已經(jīng)發(fā)展成為分析預(yù)測的合作和競爭方法。考慮兩種方法并權(quán)衡每個模型的結(jié)果,或者使用集成多個方法來獲得給定應(yīng)用的兩個世界,這是最好的實踐。這兩種方法都可以從數(shù)據(jù)中提取深刻、復(fù)雜的見解,幫助決策。
在許多情況下,與傳統(tǒng)回歸模型相比,使用更高級的 ML 模型可以提供真正的業(yè)務(wù)價值。然而,使用更先進(jìn)的模型解釋特定決策的驅(qū)動因素可能很困難、耗時,而且使用傳統(tǒng)的基礎(chǔ)設(shè)施成本高昂。模型運行時間與解釋預(yù)測的解釋步驟的運行時間同樣重要。
為了對結(jié)果充滿信心,我們希望解決對可解釋性的新需求。現(xiàn)有技術(shù)速度慢,計算成本高,是 GPU 加速的理想選擇。通過轉(zhuǎn)向 GPU 加速建模和解釋,團(tuán)隊可以改進(jìn)處理、準(zhǔn)確性和解釋性,并在業(yè)務(wù)需要時提供結(jié)果。
抵押貸款風(fēng)險預(yù)測
從消費者角度來看,違約風(fēng)險可能會影響我們個人,也可能會影響發(fā)行方。今天,在許多國家,為基礎(chǔ)設(shè)施改善項目發(fā)放了大量貸款。例如,一條大型公路 橋 可能需要超過 10 億美元的債務(wù)融資。顯然,為數(shù)十億美元的巨額項目融資會帶來違約風(fēng)險。
衡量違約概率很重要,因為管理機(jī)構(gòu)的公民當(dāng)然不希望看到該債券違約。英格蘭銀行的一篇題為 金融學(xué)中的機(jī)器學(xué)習(xí)可解釋性:在違約風(fēng)險分析中的應(yīng)用 的論文為當(dāng)前的工作提供了靈感,該工作的重點是住房抵押貸款。
在英格蘭銀行的文件中很容易看到這種解釋透明的好處。作者稱他們的方法為定量輸入影響( QII ), QII 用于線性邏輯和梯度增強(qiáng)樹機(jī)器學(xué)習(xí)預(yù)測模型。問題是:哪些因素對違約的影響最大?
作者解釋了這些解釋的直覺力量。他們還進(jìn)行觀察,這是金融建模從業(yè)者應(yīng)該注意的。本文通過精確召回曲線結(jié)果,展示了為默認(rèn)預(yù)測設(shè)計足夠的精確性、精確性和召回率的能力。
模型可解釋性可能是與思想領(lǐng)袖、管理層、外部審計師和監(jiān)管者討論的重要組成部分。[VZX38 ]使用[VZX39 ]計算,其中數(shù)據(jù)集由英國的六百萬個貸款組成,具有大約2.5%的違約率。
正如 NVIDIA 作者在最近的文章中所描述的,違約風(fēng)險是資本市場、銀行業(yè)和保險業(yè)中非常常見的債務(wù)用例。例如,信用衍生工具是一種對違約可能性進(jìn)行投機(jī)的方式,通過分期付款和離家較近的方式進(jìn)行投機(jī)。抵押貸款貸款者對他們是否能及時得到償還深感興趣。
歸根結(jié)底,保險合同是從客戶的角度覆蓋洪水、盜竊或死亡相關(guān)風(fēng)險的方式。從貸款人或保險承保的角度來看,預(yù)測這些事件對其業(yè)務(wù)的盈利能力至關(guān)重要。借助著名的美國房利美公共抵押貸款數(shù)據(jù)集,我們能夠使用 GPU ML 和 DL 模型的加速訓(xùn)練,檢查風(fēng)險方法和樣本外精確度、召回率。
本文的重點是 ML 和 DL 模型的細(xì)微差別以及可解釋性的方法。如果發(fā)生逾期 90 天的貸款事件,貸款公司就會產(chǎn)生擔(dān)憂。由于重置成本,違約概率令人擔(dān)憂。本文的一個關(guān)鍵結(jié)果是,當(dāng) GPU 加速應(yīng)用于本 GPUTreeShap paper 中所述的算法時,計算 Shap 值的速度提高了 29 倍。
我們預(yù)測美國房利美抵押貸款數(shù)據(jù)集違約的 Python 程序?qū)⑹褂?GPU 加速框架 RAPIDS 。 RAPIDS 為數(shù)據(jù)幀操作提供類似于 Python pandas 的應(yīng)用程序接口( API )。本手冊提供的抵押貸款數(shù)據(jù)集非常方便 RAPIDS 抵押數(shù)據(jù)鏈路 擁有近二十年的貸款業(yè)績數(shù)據(jù),記錄了實際利率、借款人特征和貸款人名稱。我們的抵押貸款表格數(shù)據(jù)集存在一個經(jīng)典的 imbalanced class 預(yù)測問題,因為只有大約 4% 的貸款拖欠。
分類列的因式分解
因子是編程語言中的一個重要概念。熟悉 R 語言進(jìn)行統(tǒng)計計算的讀者了解使用 factor() 函數(shù)創(chuàng)建的因子,作為將列分類為離散值集的一種方法。 R 、 事實上,默認(rèn)情況下是對列進(jìn)行因式分解,可以根據(jù)輸入進(jìn)行因式分解,因此用戶通常應(yīng)該覆蓋read.csv()帶有 wordy 參數(shù)的選項stringsAsFactors=FALSEPython pandas 和 RAPIDS 軟件包包含非常相似的factorize()本 article 中提到的方法。對于我們的抵押貸款數(shù)據(jù)集,郵政編碼是一個需要分解的經(jīng)典列。
df[‘Zip’], Zip = df[‘Zip’].factorize()
一系列轉(zhuǎn)換語句是一個熱編碼列的替代方案,減少了轉(zhuǎn)換數(shù)據(jù)所需的稀疏性和內(nèi)存。與使用單一熱編碼相比,因子分解的優(yōu)勢在于,數(shù)據(jù)幀不需要隨著列值數(shù)量的增加而變寬,但我們?nèi)匀痪哂蟹诸惲凶兞康膬?yōu)勢。
XGBoost 分類器調(diào)整
當(dāng)使用決策樹時,可以獲得特征重要性的好處。特性重要性報告有助于解釋決策中最常用的特性。如圖 1 所示的特征重要性報告是推動決策樹成為流行分類方法的工件之一。決策樹節(jié)點對應(yīng)于一組訓(xùn)練數(shù)據(jù)集行。最初,我們從一個節(jié)點開始表示所有訓(xùn)練行。節(jié)點純度指的是數(shù)據(jù)集行相似。當(dāng)我們開始決策樹訓(xùn)練過程時,節(jié)點雜質(zhì)更為常見,當(dāng)我們在掃描數(shù)據(jù)集時擴(kuò)展樹時,純度變得更為常見。特征重要性列在 減少節(jié)點雜質(zhì) 中,根據(jù)到達(dá)該節(jié)點的機(jī)會進(jìn)行加權(quán)。最有效的節(jié)點是那些導(dǎo)致雜質(zhì)最佳減少的節(jié)點,同時也代表數(shù)據(jù)總體中樣本數(shù)量最多的節(jié)點。
對于決策樹(如 XGBoost 分類器),當(dāng)決策樹通過從初始單個節(jié)點到數(shù)百個節(jié)點的拆分進(jìn)行擴(kuò)展時,當(dāng)發(fā)生拆分以獲得準(zhǔn)確性時,不需要節(jié)點雜質(zhì)。我們將很快討論更多關(guān)于可解釋性的問題。
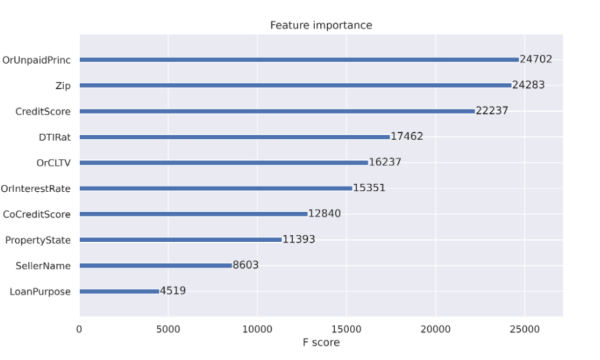
圖 1 : XGBoost 分類器報告的特征重要性。要素的列名列在打印之前。
XGBoost 分類器作為 Python Jupyter 筆記本的一部分進(jìn)行了調(diào)整,以檢查貸款拖欠的可預(yù)測性。這項工作的靈感來自于 逐條降級 。我們在前一篇文章中重點介紹了 XGBoost 分類器,并且能夠報告通過因子分解在精確度和召回率方面的改進(jìn)。給定一個包含刺激變量和默認(rèn)輸出變量的數(shù)據(jù)集,數(shù)據(jù)行的可預(yù)測性受到限制。我們在圖 2 中的結(jié)果來自 2007 年至 2012 年期間 1120 萬份個人抵押貸款,測試集中有 110 萬份貸款。與使用標(biāo)準(zhǔn)值 0.5 相比,對發(fā)出的違約概率使用自定義閾值有助于平衡精確度和召回率。我們將在下面用最佳參數(shù)顯示代碼序列。
samples/tree/main/credit_default_risk上找到,以及有關(guān)如何下載抵押貸款數(shù)據(jù)集的說明。
params = { 'num_rounds': 100, 'max_depth': 12, 'max_leaves': 0, 'alpha': 3, 'lambda': 1, 'eta': 0.17, 'subsample': 1, 'sampling_method': 'gradient_based', 'scale_pos_weight': scaling, # num_negative_samples/num_positive_samples 'max_delta_step': 1, 'max_bin': 2048, 'tree_method': 'gpu_hist', 'grow_policy': 'lossguide', 'n_gpus': 1, 'objective': 'binary:logistic', 'eval_metric': 'aucpr', 'predictor': 'gpu_predictor', 'num_parallel_tree': 1, "min_child_weight": 2, 'verbose': True } if use_cpu: print('training XGBoost model on cpu') params['tree_method'] = 'hist' params['sampling_method'] = 'uniform' params['predictor'] = 'cpu_predictor' dtrain = xgb.DMatrix(X_train, label=y_train) dtest = xgb.DMatrix(X_test, label=y_test) evals = [(dtest, 'test'), (dtrain, 'train')] model = xgb.train(params, dtrain, params['num_rounds'], evals=evals, early_stopping_rounds=10)
我們可以在前面看到, XGBoost 培訓(xùn)步驟的目標(biāo)是binary:logistic評估指標(biāo)是精確性和召回率曲線下的面積,稱為aucpr. 訓(xùn)練模型后,在訓(xùn)練集上計算對應(yīng)于最大 F1 分?jǐn)?shù)的閾值。該閾值應(yīng)用于測試集上的預(yù)測,結(jié)果如圖 2 所示,并在圖 3 的精度召回曲線中顯示為紅點。
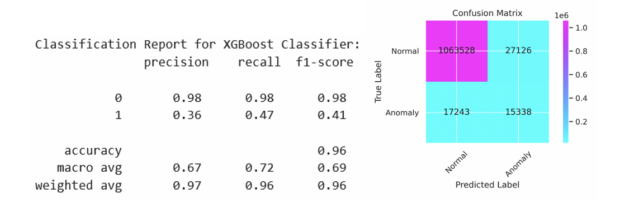
圖 2 :針對 1120 萬套抵押貸款記錄培訓(xùn)和測試集,報告精度和召回測試集。測試集中包括 110 萬筆貸款。
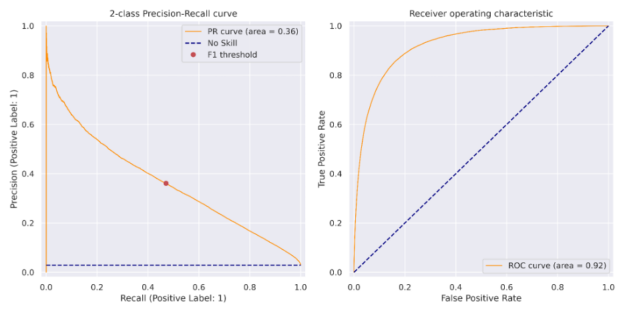
圖 3:XGBoost 機(jī)器學(xué)習(xí)精度召回曲線(左)和接收器工作特性曲線(右)反映了數(shù)據(jù)集的不平衡性質(zhì)。精密度召回曲線的面積為 0.36 ,與英格蘭銀行 816 紙張精密度召回曲線相比,該曲線更具優(yōu)勢。 紅點表示用于獲得該車型 F1 最高分?jǐn)?shù)的閾值。
使用 NVTABLAR 加速 PyTorch 深度學(xué)習(xí)培訓(xùn)
這個 NVIDIA NVTabular Python 軟件包 是一個用于表格數(shù)據(jù)的功能工程和預(yù)處理庫,旨在快速輕松地操作 TB 級數(shù)據(jù)集,并培訓(xùn)基于深度學(xué)習(xí)( DL )的推薦系統(tǒng)。它可以使用 Anaconda 或 Docker 安裝,也可以使用帶有 NVTabular 關(guān)鍵字的 pip 安裝。在我們的例子中,我們只是在訓(xùn)練期間使用它將數(shù)據(jù)輸入 PyTorch 分類器。我們還比較了使用普通 PyTorch 數(shù)據(jù)加載器與 NVTABLAR 的異步 PyTorch 數(shù)據(jù)加載器的運行時。我們發(fā)現(xiàn),對于抵押貸款數(shù)據(jù)集, NVTabular 比不使用它有 6 倍的優(yōu)勢,因為兩次運行都是在同一個 GPU 上完成的。有關(guān)更多詳細(xì)信息,請參見圖 4 和 文章 。
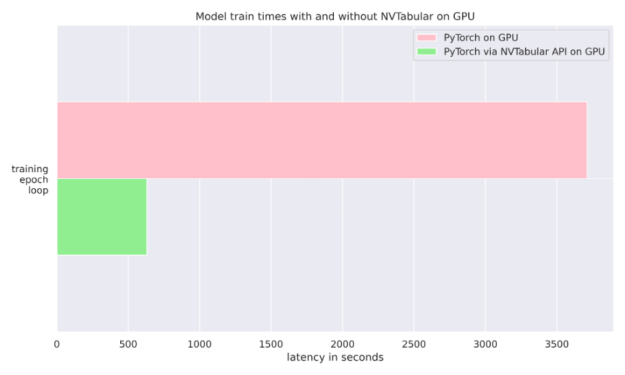
圖 4 : NVTabular 6 X 加速度。兩個 PyTorch 訓(xùn)練循環(huán)都在 GPU 上運行。
為了簡單起見,我們選擇了一個 5 層多層感知( MLP )神經(jīng)網(wǎng)絡(luò),其中包含 512 個神經(jīng)元,包括線性層、預(yù)處理、批量歸一化和退出。簡單的 MLP 能夠在測試集上匹配 XGBoost 模型的性能。更復(fù)雜的模型可能會超過此性能。在將該閾值應(yīng)用于測試集之前,采用相同的方法來確定在列車組上產(chǎn)生最大 F1 分?jǐn)?shù)的閾值。分類報告和混淆矩陣如下所述,類似的 PR 曲線和 ROC 曲線如圖 5 所示。
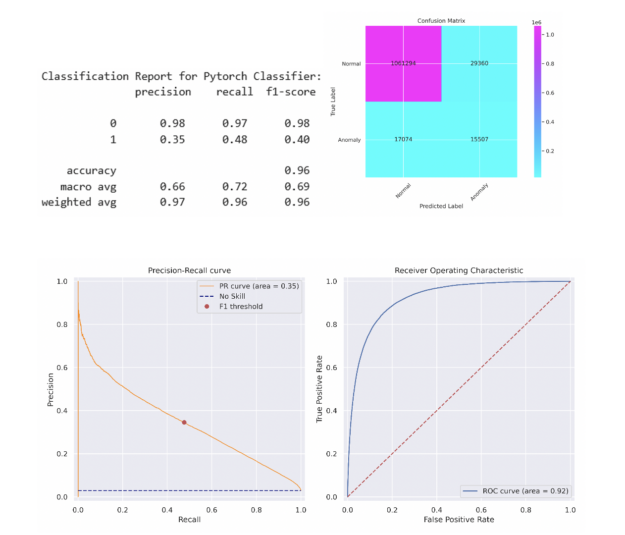
圖 5 :PyTorch 深度學(xué)習(xí)精度召回曲線(左)和接收器操作特征曲線(右)反映了數(shù)據(jù)集的不平衡性質(zhì)。精確查全率曲線的面積為 0.35 ,與英格蘭銀行 816 紙張精確查全率曲線相比,具有優(yōu)勢。
機(jī)器學(xué)習(xí)和深度學(xué)習(xí)的可解釋性
既然我們對我們的預(yù)測模型有信心,那么就必須更多地了解它是如何工作的以及為什么工作的。對于 ML 和 DL 模型,可以使用 SHAP 和 Captum 計算 Shapley 值。對于 SHAP 包,可以很容易地檢索 Shapley 值,以便按照下面的代碼片段解釋我們的 XGBoost ML 模型:
expl = shap.TreeExplainer(model) shap_values = expl.shap_values(X_test) shap.summary_plot(shap_values, X_test.to_pandas(), sort=False, show=False) plt.tight_layout()
使用CaptumGradientShap 方法計算 PyTorch DL Shapley 值,并使用以下代碼繪制,將 Shapley 值傳遞到 SHAP summary _ plot ()方法中。我們分離出積極和消極的分類變量和連續(xù)變量,以便只可視化一個不同的類或兩個類,如圖 6 所示。
from captum.attr import GradientShap Gradshap = GradientShap(model) attr_gs, delta = gradshap.attribute((torch.cat([pos_cats, neg_cats], dim=0), torch.cat([pos_conts, neg_conts], dim=0)), baselines=(torch.zeros_like(neg_cats, device=device), torch.zeros_like(neg_conts, device=device)), n_samples=200, return_convergence_delta=True) df = DataFrame(cp.asarray(torch.cat([torch.cat([pos_cats, pos_conts], dim=1), torch.cat([neg_cats, neg_conts], dim=1)], dim=0))) df.columns = CATEGORICAL_COLUMNS + CONTINUOUS_COLUMNS svals = cp.asnumpy(torch.cat(attr_gs, dim=1)) shap.summary_plot(svals, df[CATEGORICAL_COLUMNS+CONTINUOUS_COLUMNS].to_pandas(), sort=False, show=False) plt.tight_layout()
一般來說,我們想解釋一個單一的預(yù)測,并解釋這些特征是如何導(dǎo)致該預(yù)測的。 Shapley 功能解釋總結(jié)為一行的預(yù)測,我們可以跨行聚合以批量解釋模型預(yù)測。出于監(jiān)管目的,這意味著模型可以為任何輸出(有利或不利)提供人類可解釋的解釋。任何持有抵押貸款或在債務(wù)工具領(lǐng)域工作的人都可以認(rèn)識到這些熟悉的因素。
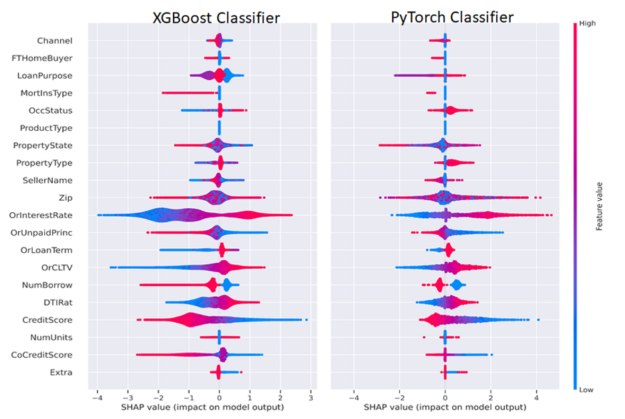
圖 6 :使用 Shapley 算法測量特征的影響和方向。紅色表示特征值較高,藍(lán)色表示特征值較低。更為正值的 SHAP 值表示對正值類別(貸款拖欠)的貢獻(xiàn)更大,反之亦然。要素名稱通常顯示在左側(cè)。
圖 6 并排描述了 ML 和 DL Shapley 值。我們可以以 CreditScore 和利率( OrInterestRate )特性為例,按照以下方式解釋圖 6 。 CreditScore 功能的紅色部分表示較高的信用分?jǐn)?shù),如圖右側(cè)圖例所示,較高的功能值為紅色,較低的功能值為藍(lán)色。對于聚集在負(fù) x 軸上的 CreditScore 點,對應(yīng)于負(fù) SHAP 值,這有助于形成負(fù)或非拖欠類別,表明信用分?jǐn)?shù)高的人不太可能拖欠。對稱地, CreditScore 的藍(lán)色(低)值位于正 x 軸或正 Shapley 值上,表示對正或拖欠類別的貢獻(xiàn)。
OrInterestRate 功能也可以采用類似但相反的解釋:低(藍(lán)色)利率產(chǎn)生負(fù) Shapley 值,并與較低的拖欠率相關(guān),這是直觀的,因為較低的利率意味著較低的抵押付款。有些特性可能不太清晰,為數(shù)據(jù)科學(xué)家或機(jī)器學(xué)習(xí)工程師提供了改進(jìn)模型的機(jī)會。例如,在我們的簡單 MLP 模型中,我們在傳遞到 MLP 之前將因式分類特征與連續(xù)特征連接起來。該模型的一個改進(jìn)可能是使用分類嵌入,這既可以提高模型性能,也可以增強(qiáng)可解釋性。通過這種方式,數(shù)據(jù)科學(xué)家或機(jī)器學(xué)習(xí)工程師可以嘗試優(yōu)化模型的可解釋性和性能。
GPU-Acceleration results
圖 7 和圖 8 重點測試了讀取輸入數(shù)據(jù)集、合并兩個數(shù)據(jù)集所需的時間,以及與 Ice Lake 24 核雙 CPU 相比, NVIDIA Ampere A100 GPU 上的 DL 推斷步驟。如表 1 所示,每個步驟都有穩(wěn)定的加速。
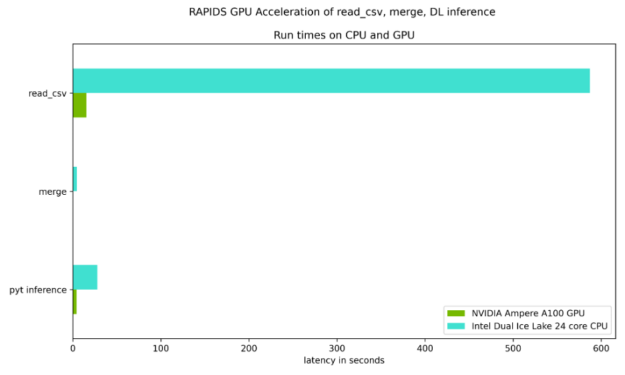
圖 7 :鍵 RAPIDS Python 步驟的相對運行時延遲,對于耗時超過 1 秒的計算密集型步驟,其顯示的加速比為 6 到 38 倍。

圖 8 :關(guān)鍵 Python 步驟的相對運行時延遲,計算密集型步驟的加速比為 2 到 29 倍
表 1 量化了圖 7 和圖 8 所示的加速,并強(qiáng)調(diào)了 GPU 加速的好處。
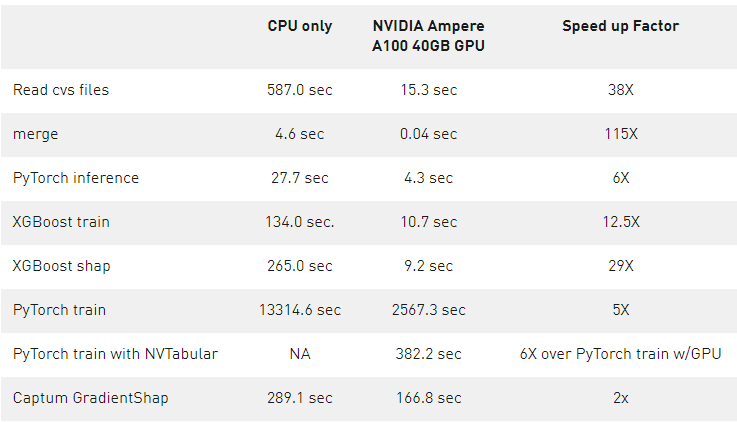
表 1 : 數(shù)據(jù)轉(zhuǎn)換或 ETL 過程的各個步驟的相對計算延遲,以及 1120 萬貸款數(shù)據(jù)集的培訓(xùn)和推理步驟。
在這篇文章中,我們擴(kuò)展了先前的一篇相關(guān)文章,通過深入學(xué)習(xí)討論了信用違約風(fēng)險預(yù)測,并討論了:
如何使用 RAPIDS 來 GPU 加速完整的默認(rèn)分析工作流
如何使用 GPU 在 RAPIDS 內(nèi)部應(yīng)用 XGBoost 實現(xiàn)
如何將深度學(xué)習(xí)lib庫應(yīng)用于 GPU 表格數(shù)據(jù)
如何使用 查看 NVTabular 包 對于 GPU 上的 PyTorch DL ,只需更改數(shù)據(jù)加載器即可獲得 6 倍的運行時性能。
如何使用 Shap 和 Captum 包以及 GPU 訪問可解釋的預(yù)測,并使用這些可解釋的結(jié)果進(jìn)一步改進(jìn)模型。
關(guān)于作者
Emanuel Scoullos 是 NVIDIA 金融服務(wù)和技術(shù)團(tuán)隊的數(shù)據(jù)科學(xué)家,他專注于 FSI 內(nèi)的 GPU 應(yīng)用。此前,他在反洗錢領(lǐng)域的一家初創(chuàng)公司擔(dān)任數(shù)據(jù)科學(xué)家,應(yīng)用數(shù)據(jù)科學(xué)、分析和工程技術(shù)構(gòu)建機(jī)器學(xué)習(xí)管道。他獲得了博士學(xué)位。普林斯頓大學(xué)化學(xué)工程碩士和羅格斯大學(xué)化學(xué)工程學(xué)士學(xué)位。
Mark J. Bennett 是 NVIDIA 的高級數(shù)據(jù)科學(xué)家,他專注于金融機(jī)器學(xué)習(xí)的加速。他擁有南加州大學(xué)計算機(jī)科學(xué)碩士學(xué)位和博士學(xué)位。來自加州大學(xué)洛杉磯分校的計算機(jī)科學(xué),并為愛荷華大學(xué)和芝加哥大學(xué)教授研究生業(yè)務(wù)分析。他曾在阿貢國家實驗室、諾基亞貝爾實驗室、諾斯羅普·格魯曼公司、 XR 交易證券公司和美國銀行證券公司擔(dān)任工程和管理職務(wù)。馬克與 R 合著了《金融分析》一書,由劍橋大學(xué)出版社出版。
John Ashley 目前領(lǐng)導(dǎo) NVIDIA 的全球金融服務(wù)和技術(shù)團(tuán)隊。在此之前,他啟動并領(lǐng)導(dǎo)了 NVIDIA 的專業(yè)服務(wù)深度學(xué)習(xí)實踐和 NVIDIA 深度學(xué)習(xí)專業(yè)服務(wù)合作伙伴計劃,致力于幫助客戶和合作伙伴采用并提供深度學(xué)習(xí)解決方案。此前在 NVIDIA 任職期間,他還負(fù)責(zé)管理與IBM軟件和認(rèn)知團(tuán)隊的關(guān)系,是一名高級解決方案架構(gòu)師,負(fù)責(zé)紐約和倫敦的金融服務(wù),并支持 NVIDIA 與平方公里陣列射電天文學(xué)項目的合作。他擁有計算科學(xué)和信息學(xué)博士學(xué)位,以及電子工程學(xué)士和碩士學(xué)位。
Prabhu Ramamoorthy 是 NVIDIA 的金融生態(tài)系統(tǒng)合作伙伴經(jīng)理,他專注于金融服務(wù)的 HPC / ML / AI 加速。他擁有來自威斯康星大學(xué)麥迪遜的工商管理碩士學(xué)位和來自印度頂尖工程學(xué)院之一的 BIT PrANIN 的本科學(xué)位。他是特許金融分析師 CFA 特許持有人、金融風(fēng)險經(jīng)理 FRM 和特許另類投資分析師 CAIA ,專門研究金融用例。他曾擔(dān)任保證金軟件公司 Dash Regtech (前身為 LDB ,被視為金本位)的技術(shù)負(fù)責(zé)人,主要面向投資銀行和經(jīng)紀(jì)自營商,并曾在四大公司畢馬威/安永擔(dān)任金融服務(wù)業(yè)務(wù)總監(jiān),在過去 10 年中,他幫助了 80 多家金融機(jī)構(gòu)。
Jochen Papenbrock 位于德國法蘭克福,在過去的15年中,Jochen一直在金融服務(wù)業(yè)人工智能領(lǐng)域擔(dān)任各種角色,擔(dān)任思想領(lǐng)袖、實施者、研究者和生態(tài)系統(tǒng)塑造者。
Miguel Martinez 是 NVIDIA 的高級深度學(xué)習(xí)數(shù)據(jù)科學(xué)家,他專注于 RAPIDS 和 Merlin 。此前,他曾指導(dǎo)過 Udacity 人工智能納米學(xué)位的學(xué)生。他有很強(qiáng)的金融服務(wù)背景,主要專注于支付和渠道。作為一個持續(xù)而堅定的學(xué)習(xí)者, Miguel 總是在迎接新的挑戰(zhàn)。
審核編輯:郭婷
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5592瀏覽量
109722 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8553瀏覽量
136934 -
python
+關(guān)注
關(guān)注
57文章
4876瀏覽量
90025
發(fā)布評論請先 登錄
高新興瑞聯(lián)成功通過國家高新技術(shù)企業(yè)認(rèn)定
沐曦股份曦云C系列GPU Day 0適配智譜GLM-4.6V多模態(tài)大模型

羅德與施瓦茨即將亮相2025年慕尼黑電子展
構(gòu)建CNN網(wǎng)絡(luò)模型并優(yōu)化的一般化建議
德賽電池成功獲得RBA白銀等級認(rèn)證
移遠(yuǎn)通信飛鳶AIoT大模型應(yīng)用算法成功通過備案
【VisionFive 2單板計算機(jī)試用體驗】在 VisionFive 2 上為目標(biāo)檢測準(zhǔn)備軟件環(huán)境并運行 MobileNet-SSD 模型
為什么無法在GPU上使用INT8 和 INT4量化模型獲得輸出?
商湯日日新SenseNova融合模態(tài)大模型 國內(nèi)首家獲得最高評級的大模型
國芯科技云安全芯片CCP917T測試成功
摩爾線程GPU成功適配Deepseek-V3-0324大模型

預(yù)測性維護(hù)實戰(zhàn):如何通過數(shù)據(jù)模型實現(xiàn)故障預(yù)警?




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論