") 基于深度學(xué)習(xí)的三種目標(biāo)檢測方法
基于深度學(xué)習(xí)的三種目標(biāo)檢測方法

目標(biāo)檢測是計(jì)算機(jī)視覺的一個(gè)非常重要的核心方向,它的主要任務(wù)目標(biāo)定位和目標(biāo)分類。
在深度學(xué)習(xí)介入該領(lǐng)域之前,傳統(tǒng)的目標(biāo)檢測思路包括區(qū)域選擇、手動(dòng)特征提取、分類器分類。由于手動(dòng)提取特征的方法往往很難滿足目標(biāo)的多樣化特征,傳統(tǒng)方法始終沒能很好的解決目標(biāo)檢測問題。
深度學(xué)習(xí)興起之后,神經(jīng)網(wǎng)絡(luò)可以從大量數(shù)據(jù)中自動(dòng)學(xué)出強(qiáng)大的特征提取和擬合能力,因而涌現(xiàn)出很多性能優(yōu)良的目標(biāo)檢測算法。
基于深度學(xué)習(xí)的目標(biāo)檢測方法大致可分為三類——雙階段目標(biāo)檢測、單階段目標(biāo)檢測、基于transformer的目標(biāo)檢測,本文將分別介紹這三類方法。
常用數(shù)據(jù)集
VOC數(shù)據(jù)集
VOC數(shù)據(jù)集[1]是目標(biāo)檢測領(lǐng)域的常用數(shù)據(jù)集,共有約10,000張帶有邊界框的圖片用于訓(xùn)練和驗(yàn)證,每張圖片有像素級別的分割標(biāo)注、邊界框標(biāo)注以及目標(biāo)類別標(biāo)注,其中包含車輛、家具、動(dòng)物、人4個(gè)大類,20個(gè)小類。
該數(shù)據(jù)集被廣泛用作目標(biāo)檢測、語義分割、分類任務(wù)的基準(zhǔn)數(shù)據(jù)集。
COCO數(shù)據(jù)集
COCO[2]的全稱是Microsoft Common Objects in Context,它是微軟于2014年出資標(biāo)注的數(shù)據(jù)集,與ImageNet競賽一樣,COCO目標(biāo)檢測競賽也被視為是計(jì)算機(jī)視覺領(lǐng)域最受關(guān)注和最權(quán)威的比賽之一。
相比于規(guī)模較小的VOC數(shù)據(jù)集,COCO是一個(gè)大型、豐富的物體檢測、分割數(shù)據(jù)集。這個(gè)數(shù)據(jù)集以scene understanding為目標(biāo),主要從復(fù)雜的日常場景中截取,并通過精確的segmentation進(jìn)行目標(biāo)位置的標(biāo)定。
圖像包括91類目標(biāo),328,000影像和2,500,000個(gè)label。提供的類別有80 類,有超過33 萬張圖片,其中20 萬張有標(biāo)注,整個(gè)數(shù)據(jù)集中個(gè)體的數(shù)目超過150 萬個(gè)。
雙階段目標(biāo)檢測算法
相較于單階段目標(biāo)檢測算法,雙階段目標(biāo)檢測算法先根據(jù)圖像提取候選框,然后基于候選區(qū)域做二次修正得到檢測點(diǎn)結(jié)果,檢測精度較高,但檢測速度較慢。
這類算法的開山之作是RCNN[3],隨后Fast RCNN[4]、Faster RCNN[5]依次對其進(jìn)行了改進(jìn)。
由于優(yōu)秀的性能,F(xiàn)aster RCNN至今仍然是目標(biāo)檢測領(lǐng)域很有競爭力的算法。隨后,F(xiàn)PN[6]、Mask RCNN[7]等算法又針對Faster RCNN的不足提出了改進(jìn),這進(jìn)一步豐富了Faster RCNN的組件,提升了它的性能。
RCNN
RCNN是首個(gè)將深度學(xué)習(xí)應(yīng)用到目標(biāo)檢測領(lǐng)域的工作,它的算法的思想較為簡單:對于每張圖片,RCNN首先采用選擇性搜索算法[1]生成大約2000個(gè)候選區(qū)域。隨后將每個(gè)候選區(qū)域的尺寸轉(zhuǎn)換為固定大小,并用CNN提取候選區(qū)域的特征。隨后使用SVM分類器判斷候選區(qū)域的類別,使用線性回歸模型,為每個(gè)物體生成更精確的邊界框。
盡管RCNN取得了很大進(jìn)展,它仍然有很多缺點(diǎn):首先,整個(gè)目標(biāo)檢測階段涉及到三個(gè)模型,用于特征提取的CNN、用于分辨目標(biāo)物體類別的SVM分類器、用于調(diào)整邊界框的線性回歸模型。RCNN無法做到端到端訓(xùn)練,只能分別訓(xùn)練這三個(gè)模型,這增大了訓(xùn)練難度與訓(xùn)練時(shí)間。
其次,每張圖片要提取2000個(gè)訓(xùn)練區(qū)域,隨后又要用CNN分別提取每個(gè)區(qū)域的特征,特征的數(shù)量將非常大,這降低了模型的推理速度。通常每張圖片需要45秒進(jìn)行預(yù)測,基本無法處理大型數(shù)據(jù)集。
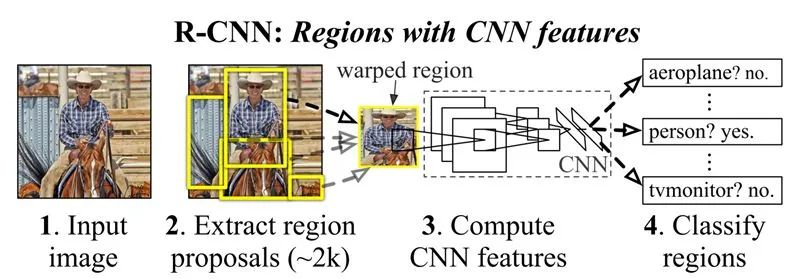
圖1:RCNN算法流程
Fast RCNN
在RCNN中,每個(gè)候選區(qū)域都需要用CNN單獨(dú)提取特征。為了減少算法的計(jì)算時(shí)間,F(xiàn)ast-RCNN希望在每張圖片上只使用一次CNN,就能提取到所有關(guān)注區(qū)域的特征。為此,RCNN設(shè)計(jì)了如下步驟的目標(biāo)檢測算法:
首先對圖片使用啟發(fā)式算法,得到大量候選區(qū)域。隨后將圖片輸入到卷積神經(jīng)網(wǎng)絡(luò)中,得到圖片的特征,與候選區(qū)域的相對位置結(jié)合,就可以得到候選區(qū)域的特征。隨后使用ROI池化層將候選區(qū)域調(diào)整至相同尺寸,并將調(diào)整后的結(jié)構(gòu)輸入到全連接神經(jīng)網(wǎng)絡(luò)中。最后在全連接神經(jīng)網(wǎng)絡(luò)后面添加softmax層,預(yù)測目標(biāo)的列別;并以相同的方式添加線性回歸層。
與RCNN相比,F(xiàn)ast RCNN計(jì)算一張圖片只需要2秒,速度有大幅提升,每張圖片的計(jì)算時(shí)間只有但仍不夠理想。因?yàn)樗廊挥玫搅诉x擇性搜索方法得到感興趣區(qū)域,而這一過程通常很慢。
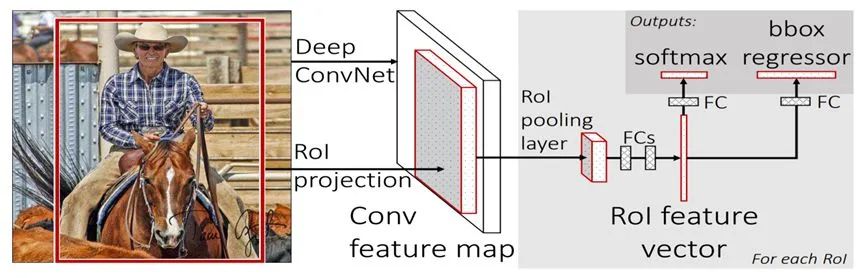
圖2:Fast RCNN網(wǎng)絡(luò)結(jié)構(gòu)
Faster RCNN
Faster RCNN針對感興趣區(qū)域的生成方式,對RCNN進(jìn)行了優(yōu)化,進(jìn)一步提高了計(jì)算速度和準(zhǔn)確率。具體來說,F(xiàn)aster RCNN使用Reigion Proposal Network(RPN)生成感興趣區(qū)域:
首先,將圖片輸入到CNN中得到高層特征映射,隨后將其傳遞到RPN中。
RPN會在特征映射上使用一個(gè)滑動(dòng)窗口,并在每個(gè)窗口設(shè)置K個(gè)不同大小、不同長寬比的先驗(yàn)框。
對于每個(gè)先驗(yàn)框,RPN會分別預(yù)測該框包含目標(biāo)物體的概率,以及對該框的調(diào)整回歸量。最終得到不同形狀、尺寸的邊界框,調(diào)增尺寸后將其傳遞到完全連接層,得到目標(biāo)類別以及最終的先驗(yàn)框。
Faster RCNN進(jìn)一步提高了計(jì)算速度,并獲得了較高的準(zhǔn)確率。時(shí)至今日,依然是目標(biāo)檢測領(lǐng)域的主流算法之一。
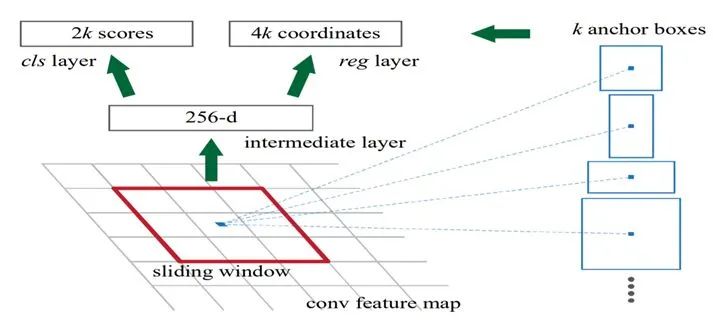
圖3:RPN的網(wǎng)絡(luò)結(jié)構(gòu)
FPN
Faster R-CNN是利用單個(gè)高層特征圖(下采樣四倍的卷積層——Conv4)進(jìn)行物體的分類和bounding box的回歸。這樣做對小物體的檢測不利,因?yàn)樾∥矬w本身具有的像素信息較少,在下采樣的過程中,這些信息很容易丟失,從而降低了算法的性能。
為了處理這種物體大小差異十分明顯的檢測問題,F(xiàn)PN提出了特征金字塔網(wǎng)絡(luò)結(jié)構(gòu),它引入了多尺度特征,在只增加少量計(jì)算量的情況下,提升小物體的檢測性能。
具體來說,F(xiàn)aster RCNN將最后一層特征輸入到了RPN中,最后一層的特征經(jīng)過3x3卷積,得到256個(gè)channel的卷積層,再分別經(jīng)過兩個(gè)1x1卷積得到類別得分和邊框回歸結(jié)果。
而FPN將P2、P3、P4、P5、P6這五個(gè)特征層的特征都輸入到了RPN中。每個(gè)特征層的下采樣倍數(shù)不同,這意味著它們具有不同的尺度信息分離,因此作者將322、642、1282、2562、5122這五種尺度的anchor,分別對應(yīng)到P2、P3、P4、P5、P6這五個(gè)特征層上,這樣一來,每個(gè)特征層只需要專門處理單一的尺度信息即可。
此外,作者通過實(shí)驗(yàn)發(fā)現(xiàn),如果將這5個(gè)特征層后面的RPN參數(shù)共享,所得到的結(jié)果與不共享幾乎沒有差別。這說明不同下采樣倍數(shù)之間的特征有相似語義信息。
在FPN問世之后,立刻成為了Faster RCNN的必要組成部件。
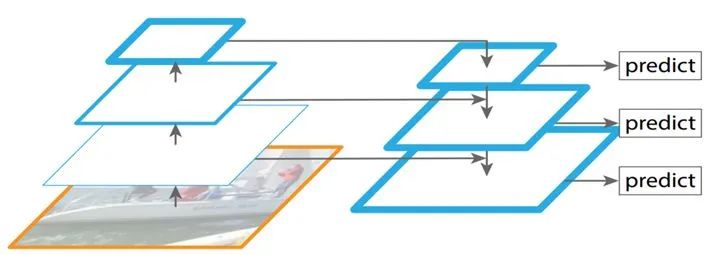
圖4:FPN的網(wǎng)絡(luò)結(jié)構(gòu)
Mask RCNN
相較于Faster RCNN,Mask RCNN采用了全新的、性能更強(qiáng)的ResNeXt-101+FPN的組合作為backbone提取輸入圖片的特征。并在網(wǎng)絡(luò)最后額外添加了一個(gè)分支,進(jìn)行mask預(yù)測任務(wù),這將有助于提升特征提取網(wǎng)絡(luò)和RPN的性能。
此外,Mask RCNN還提出了一個(gè)改進(jìn),將原先的ROI池化層改進(jìn)成ROIAlign層。在Faster RCNN中,有兩次整數(shù)化的操作:(1)RPN輸出的邊界框回歸值通常是小數(shù),為了方便操作,會直接通過四舍五入把其整數(shù)化。(2)在ROI池化層中,整數(shù)化后的邊界區(qū)域被平均分割成了K×K個(gè)單元,因此需要對這些單元的邊界進(jìn)一步整數(shù)化。
Mask RCNN的作者指出,經(jīng)過這兩次整數(shù)化后的候選框,已經(jīng)和最開始RPN輸出的候選框有了一定的位置偏差,這將影響模型的準(zhǔn)確度。為此,作者提出了ROI Align方法,它沒有采用整數(shù)化操作,而是使用雙線性插值方法,獲得浮點(diǎn)數(shù)坐標(biāo)的像素值。
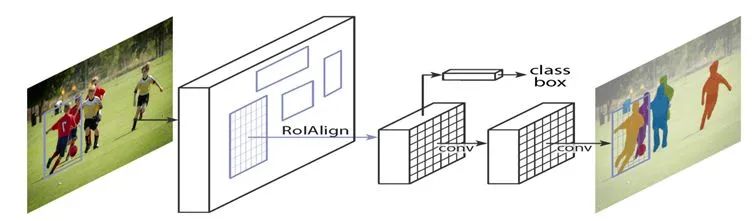
圖5:Mask RCNN的網(wǎng)絡(luò)結(jié)構(gòu)
單階段目標(biāo)檢測算法
相較于雙階段目標(biāo)檢測算法,單階段目標(biāo)驗(yàn)測算法直接對圖像進(jìn)行計(jì)算生成檢測結(jié)果,檢測低速度快,但檢測精度低。
這類算法的開山之作是YOLO[8],隨后SSD [9]、Retinanet[10]依次對其進(jìn)行了改進(jìn),提出YOLO的團(tuán)隊(duì)將這些有助于提升性能的 trick融入到Y(jié)OLO算法中,后續(xù)又提出了4個(gè)改進(jìn)版本YOLOv2~YOLOv5。
盡管預(yù)測準(zhǔn)確率不如雙階段目標(biāo)檢測算法,由于較快的運(yùn)行速度,YOLO成為了工業(yè)界的主流。
YOLO
雙階段目標(biāo)檢測需要預(yù)先設(shè)置大量先驗(yàn)框,并且需要專門的神經(jīng)網(wǎng)絡(luò)RPN對先驗(yàn)框進(jìn)行位置修正。這種設(shè)定使得雙階段目標(biāo)檢測算法復(fù)雜且計(jì)算慢。
YOLO是單階段目標(biāo)檢測的開山之作,它只需要用神經(jīng)網(wǎng)絡(luò)處理一次圖片,就可以同時(shí)預(yù)測得到位置和類別,從而將目標(biāo)檢測任務(wù)定義為端到端的回歸問題,提升了計(jì)算速度。YOLO的工作流程如下:
對于一張輸入圖片,首先將圖片縮放成統(tǒng)一的尺寸,并在圖片上劃分出若干表格。隨后使用卷積神經(jīng)網(wǎng)絡(luò)提取圖片特征,并使用全連接層在每個(gè)網(wǎng)格上進(jìn)行回歸預(yù)測,每個(gè)網(wǎng)格預(yù)測K個(gè)box,每個(gè)box預(yù)測五個(gè)回歸值。其中的四個(gè)回歸值代表box的位置,第五個(gè)回歸值代表box中含有物體的概率和位置的準(zhǔn)確程度。
隨后對于含有物體的box,使用全連接層,回歸預(yù)測物體的在各個(gè)類別的條件概率。因而,卷積網(wǎng)絡(luò)共輸出的預(yù)測值個(gè)數(shù)為N×(K×5+C),其中N為網(wǎng)格數(shù),K為每個(gè)網(wǎng)格生成box個(gè)數(shù),C為類別數(shù)。
盡管單階段模型顯著提高了計(jì)算速度,YOLO劃分網(wǎng)格的方式較為粗糙,在小目標(biāo)檢測任務(wù)上表現(xiàn)不佳,總體性能弱于Faster RCNN。
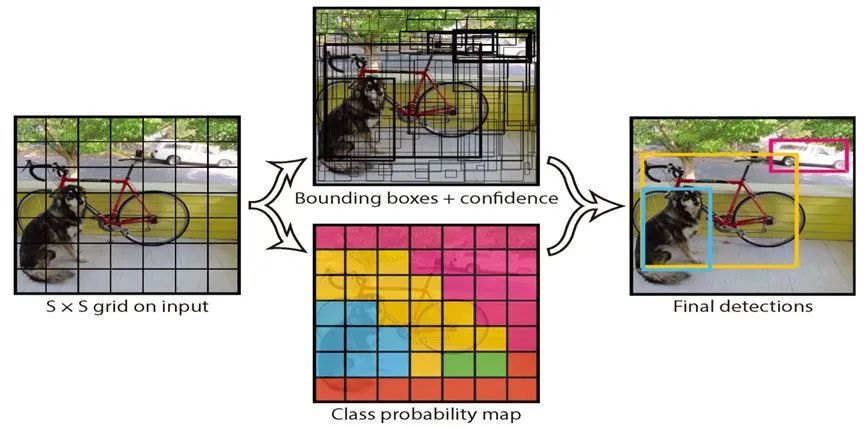
圖6:YOLO的檢測流程
SSD
針對YOLO的不足,SSD借鑒了雙階段目標(biāo)檢測算法的一些trick,在YOLO的基礎(chǔ)上進(jìn)行了一系列改進(jìn):
YOLO利用單個(gè)高層特征進(jìn)行目標(biāo)檢測,SSD則是將特征提取網(wǎng)絡(luò)中不同層的多個(gè)特征輸入到目標(biāo)檢測模塊,以希望提升小物體檢測的精度。
YOLO在每個(gè)網(wǎng)格上預(yù)測多個(gè)邊界框,但這些預(yù)測都相對這個(gè)正方形網(wǎng)格本身,與真實(shí)目標(biāo)多變的形狀差異較大,這使得YOLO需要在訓(xùn)練過程中自適應(yīng)目標(biāo)的形狀。SSD借鑒了Faster R-CNN中先驗(yàn)框理念,為每個(gè)網(wǎng)格設(shè)置不同尺度、長寬比的先驗(yàn)框,這在一定程度上減少訓(xùn)練難度。
SSD還使用卷積層絡(luò)替代全連接層,針對不同特征圖進(jìn)行回歸預(yù)測,這樣一來,對于形狀為mxnxp的特征圖,只需要采用3x3xp這樣比較小的卷積核得到檢測值,進(jìn)一步減少了模型的參數(shù)量,提高了計(jì)算速度。
SSD的改進(jìn),使得單階段目標(biāo)檢測算法的性能基本與當(dāng)時(shí)的Faster-RCNN持平,不過后續(xù)又被Faster-RCNN類算法超越。
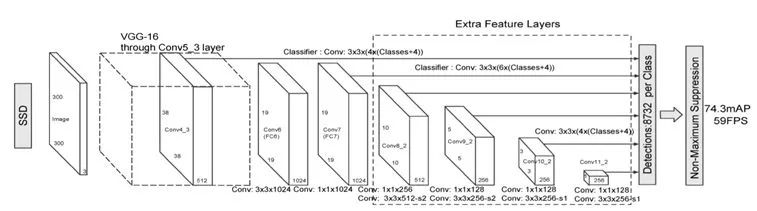
圖7:SSD的網(wǎng)絡(luò)結(jié)構(gòu)
Retinanet
相較于SSD,RetinaNet并沒有模型層面的創(chuàng)新,模型的性能提升主要源自于Focal Loss,它進(jìn)一步解決了目標(biāo)檢測中的類別不平衡問題。
單階段目標(biāo)檢測模型常常會面臨嚴(yán)重的正負(fù)樣本不平衡問題,由于算法會在圖片的每個(gè)位置密集抽樣,而圖片中的樣本數(shù)量有限,因此候選區(qū)域中的物體數(shù)量會顯著小于背景數(shù)量。
對于兩階段目標(biāo)檢測模型,正負(fù)樣本不平衡問題得到了一定的緩解。因?yàn)榈谝浑A段的RPN可以避免生成很大一部分負(fù)樣本,最終第二階段的檢測模塊只需要處理少量候選框。
針對正負(fù)樣本不均衡問題,SSD算法采用了hard mining,從大量的負(fù)樣本中選出loss最大的topk個(gè)負(fù)樣本以保證正負(fù)樣本比例為1:3。
相較于SSD的抽樣方法,F(xiàn)ocal Loss從損失函數(shù)的視角來解決樣本不平衡問題,它根據(jù)置信度動(dòng)態(tài)調(diào)整交叉熵?fù)p失函數(shù),當(dāng)預(yù)測正確的置信度增加時(shí),loss的權(quán)重系數(shù)會逐漸衰減至0,這使得模型訓(xùn)練的loss更關(guān)注難例,而大量容易的例子loss貢獻(xiàn)很低。
YOLO的后續(xù)版本
YOLO的團(tuán)隊(duì)借鑒了其它有助于提升性能的 trick融入到Y(jié)OLO算法中,后續(xù)又提出了4個(gè)改進(jìn)版本YOLOv2~YOLOv5。
YOLOv2使用了很多trick,包括:Batch Normalization、高分辨率圖像分類器、使用先驗(yàn)框、聚類提取先驗(yàn)框的尺度信息、約束預(yù)測邊框的位置、在passthrough層檢測細(xì)粒度特征、分層分類等。
YOLOv3借鑒了SSD的思想,使用了多尺度特征進(jìn)行目標(biāo)檢測,與SSD不同的是,YOLOv3采用上采樣+特征融合的方式,對多尺度特征進(jìn)行了一定的融合。
后續(xù)版本采用了Retinanet提出的Facol loss,緩解了正負(fù)樣本不均衡問題,進(jìn)一步提升了模型表現(xiàn)。
基于transformer
的方法
對于目標(biāo)檢測任務(wù)而言,理論上講,各個(gè)目標(biāo)之間的關(guān)系是有助于提升目標(biāo)檢測效果的。盡管傳統(tǒng)目標(biāo)檢測方法使用到了目標(biāo)之間的關(guān)系,直到Transformer[11]模型面世,無論是單階段還是雙階段目標(biāo)檢測,都沒有很好地利用到注意力機(jī)制。
一個(gè)可能的原因是目標(biāo)與目標(biāo)之間的關(guān)系難以建模,因?yàn)槟繕?biāo)的位置、尺度、類別、數(shù)量都會因圖像的不同而不同。而現(xiàn)代基于CNN的方法大多只有一個(gè)簡單、規(guī)則的網(wǎng)絡(luò)結(jié)構(gòu),對于上述復(fù)雜現(xiàn)象有些無能為力。
針對這種情況,Relation Net[12]和DETR[13]利用Transformer將注意力機(jī)制引入到目標(biāo)檢測領(lǐng)域。Relation Net利用Transformer對不同目標(biāo)之間的關(guān)系建模,在特征之中融入了關(guān)系信息,實(shí)現(xiàn)了特征增強(qiáng)。DETR則是基于Transformer提出了全新的目標(biāo)檢測架構(gòu),開啟了目標(biāo)檢測的新時(shí)代。
Relation Net
盡管用到了Transformer,Relation Net仍然是基于Faster RCNN的改進(jìn)工作。Faster RCNN會通過RPN網(wǎng)絡(luò)生成一系列感興趣區(qū)域,隨后將感興趣區(qū)域輸入到神經(jīng)網(wǎng)絡(luò)中預(yù)測目標(biāo)的位置和類別。
Relation Net并沒有直接將感興趣區(qū)域輸入到最終的預(yù)測網(wǎng)絡(luò)中,而是先將這些感興趣區(qū)域輸入到transformer中,利用注意力機(jī)制,融合不同感興趣區(qū)域的關(guān)系信息,進(jìn)而實(shí)現(xiàn)特征增強(qiáng)。隨后,再將transformer的輸出送入到最終的預(yù)測網(wǎng)絡(luò)中,預(yù)測目標(biāo)的位置和類別。
此外,作者還用transformer模塊取代了非極大值抑制模塊(NMS),真正實(shí)現(xiàn)了端到端訓(xùn)練。
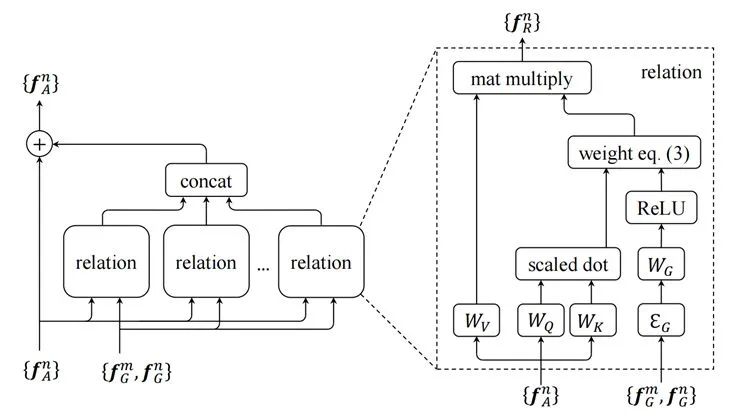
圖8:Relation module的結(jié)構(gòu)
DETR
DETR是首個(gè)用transformer完成目標(biāo)檢測任務(wù)的代表性工作。
首先,DETR使用CNN提取圖片的特征,再加上NLP領(lǐng)域常用的位置編碼,最終生成了一批序列化數(shù)據(jù)。
在encoder階段,將序列化數(shù)據(jù)其送入encoder中,利用注意力機(jī)制提取數(shù)據(jù)中的特征。在decoder階段,輸入N個(gè)隨機(jī)初始化向量,每個(gè)object query關(guān)注圖片的不同位置。經(jīng)過decoder的解碼,最終會生成N個(gè)向量,每個(gè)向量對應(yīng)一個(gè)檢測到的目標(biāo)。最后將這N個(gè)向量輸入到神經(jīng)網(wǎng)絡(luò)中,得到每個(gè)目標(biāo)的類別和位置。
相較于其它目標(biāo)檢測算法,DETR生成的檢測框數(shù)量大幅減少,與真實(shí)的檢測框數(shù)量基本一致。DETR使用匈牙利算法,將預(yù)測框與真實(shí)框進(jìn)行了匹配,隨后就可以計(jì)算出loss,完成對模型的訓(xùn)練。
DETR取得了好于Faster RCNN的檢測效果,并且它不需要預(yù)先指定候選區(qū)域,不需要使用NMS去除重復(fù)的目標(biāo)框,算法流程十分簡潔。
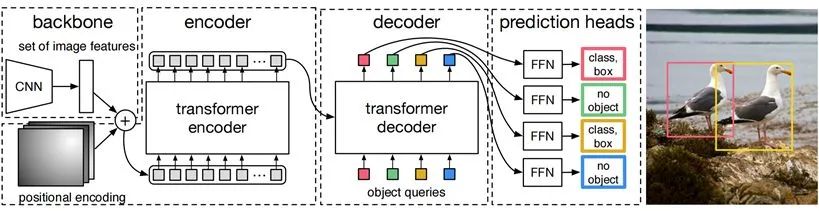
圖9:DETR的算法流程
總結(jié)
憑借著強(qiáng)大的特征提取能力,深度學(xué)習(xí)幫助目標(biāo)檢測算法取得了長足的發(fā)展。
從RCNN開始,相關(guān)科研人員不斷引入新的機(jī)制、新的trick,以提高這類算法的精度。最終,以Faster RCNN為代表的雙階段目標(biāo)檢測算法取得了很高的預(yù)測準(zhǔn)確率。
相較于Faster RCNN,以YOLO為代表的單階段目標(biāo)檢測算法在保證較高預(yù)測精度的同時(shí)取得了很高的計(jì)算速度,憑借其優(yōu)秀的實(shí)時(shí)性,在工業(yè)界取得了廣泛應(yīng)用。
去年提出的以DETR為代表的視覺Transformer算法將注意力機(jī)制引入到目標(biāo)檢測領(lǐng)域。DETR憑借其簡潔優(yōu)雅的結(jié)構(gòu)、超過Faster RCNN的準(zhǔn)確率,吸引了越來越多的目標(biāo)檢測從業(yè)者開展視覺transformer的研究。從目前的發(fā)展態(tài)勢來看,視覺transformer必將進(jìn)一步推動(dòng)目標(biāo)檢測的快速進(jìn)展。
原文標(biāo)題:目標(biāo)檢測 - 主流算法介紹 - 從RCNN到DETR
文章出處:【微信公眾號:機(jī)器視覺智能檢測】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
審核編輯:湯梓紅
-
計(jì)算機(jī)
+關(guān)注
關(guān)注
19文章
7807瀏覽量
93202 -
目標(biāo)檢測
+關(guān)注
關(guān)注
0文章
233瀏覽量
16494 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5599瀏覽量
124398
原文標(biāo)題:目標(biāo)檢測 - 主流算法介紹 - 從RCNN到DETR
文章出處:【微信號:vision263com,微信公眾號:新機(jī)器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
穿孔機(jī)頂頭檢測儀 機(jī)器視覺深度學(xué)習(xí)
電壓放大器在全導(dǎo)波場圖像目標(biāo)識別的損傷檢測實(shí)驗(yàn)的應(yīng)用

如何深度學(xué)習(xí)機(jī)器視覺的應(yīng)用場景
如何在機(jī)器視覺中部署深度學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)

MEMS中的三種測溫方式

介紹三種常見的MySQL高可用方案
提高IT運(yùn)維效率,深度解讀京東云AIOps落地實(shí)踐(異常檢測篇)
精選好文!噪聲系數(shù)測量的三種方法
雙極型三極管放大電路的三種基本組態(tài)的學(xué)習(xí)課件免費(fèi)下載
labview調(diào)用yolo目標(biāo)檢測、分割、分類、obb
redis三種集群方案詳解



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論