 RISC架構的興起
RISC架構的興起

編者按
John Hennessy和David Patterson是體系結構領域的權威,兩人在其2017年圖靈獎獲獎演講時說,未來十年是體系機構的黃金年代,在CPU性能達到瓶頸的情況下,需要針對特定的領域定制專用處理器,這也就是當前大家熟悉的DSA(Domain Specific Architecture,特定領域架構)。隨后,還專門寫了專業的論文詳細論證此事(見參考文獻)。 那么,反向的思考,是否存在足夠“通用”的處理器,能夠按照摩爾定律,在性能快速提升的同時,依然能夠“包治百病”,盡可能滿足眾多客戶的當前和未來一定時期的需求?
1從歷史中汲取靈感
1.1 RISC架構的興起
在上世紀七十年代到八十年代初,因為流水線等技術的應用,CPU速度提升非常之快,而內存的容量和速度相對落后。通過不定長的指令格式能夠提供更高的代碼密度,同樣大小內存空間能裝載更多指令,從而間接的提高運行速度。并且,這時候的編譯器能力比較有限,編譯器很難做到CPU寄存器的合理利用,也無法針對微架構的具體特征進行深層次的性能優化,這就使得CPU的設計師們偏愛直接內存-內存以及寄存器-內存風格的指令執行模式。這些都是典型的復雜指令集(CISC)的特征。 這一時期,幾乎所有的處理器設計都在按照CISC的路線發展,并且走向一個極端:不斷加入新的指令,試圖在指令集架構層面對高層編程語言提供更直接有效的支持,等等。這種發展路線使得硬件復雜度快速飛升,研發成本不斷提高,研發周期變長,而編譯器也難以利用這越來越復雜的指令集。 隨后,RISC架構興起。來自IBM的John Cocke認為,更加精簡清爽的指令集設計將有助于減少硬件開發難度和成本,同時也有利于編譯器進行代碼優化工作。當時在在伯克利任教的David Patterson,與其學生們的成果在1983年國際固態電子電路大會(ISSCC)進行展示。盡管制造工藝老舊,主頻比DEC、摩托羅拉、Intel等競爭對手同期制造的處理器慢上幾乎一半,晶體管數量也只有幾分之一,但是更加清爽的新式設計在編譯器等其他工具的輔助下竟然將來自工業界的競爭對手們盡數擊敗。 RISC架構處理器提倡簡化指令集設計、固定指令長度、統一指令編碼格式、加速常用指令。這在當時來看,與占據主流的CISC設計風格背道而馳。但RISC陣營的David Patterson有了流片成功的芯片與硬件測試結果在手,加之1983年的ISSCC大會上聚集了幾位與David Patterson觀點相同的支持者,RISC流派開始逐步占據上風。 CISC ISA呈現出符合“二八定律”的特征:80%的指令很少被使用,只有20%的指令經常用到。RISC針對這20%的指令集,進行重組、優化和加速,另外80%指令通過這20%簡單指令的組合來完成,性能反而高于CISC。 我們無意于介紹CISC和RISC的歷史恩怨,之后的情況是:兩種理念的ISA也是相互借鑒相互融合,逐步形成了現在的x86、ARM和RISC-v三強競爭的局面。
1.2 從微服務到云計算服務分層
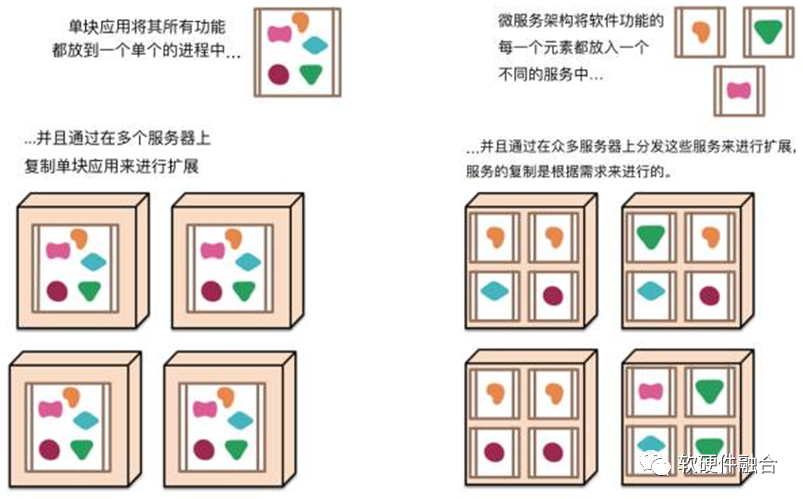
最開始,所有的應用都是單塊“巨”應用系統。企業應用系統經常包含三個主要部分:客戶端用戶界面、數據庫和服務端應用系統。漸漸地,特別是隨著越來越多的應用系統正被部署到云端,軟件變更受到了很大的限制:應用系統中一個很小部分的一處變更,也需要將整個單塊應用系統進行重新構建和部署;單塊應用逐漸難以保持一個良好的模塊化結構,當對系統進行擴展時,不得不擴展整個應用系統,而不能僅擴展該系統中需要更多資源的那些部分。 這些問題催生出了微服務架構風格:以構建一組小型服務的方式來構建應用系統。除了這些服務能被獨立地部署和擴展之外,每一個服務還能提供一個穩固的模塊邊界,甚至能允許使用不同的編程語言來編寫不同的服務。并且,這些服務也能被不同的團隊來管理。 微服務的方式,很好地把一個完整的應用系統拆分成用戶關心的應用核心本身,以及其他一些輔助的服務,如:
基礎設施服務,比如VM、容器、網絡、存儲、安全等;
中間件層服務,如負載均衡、數據庫、文件系統、訪問控制、消息隊列、物聯網接入平臺等。
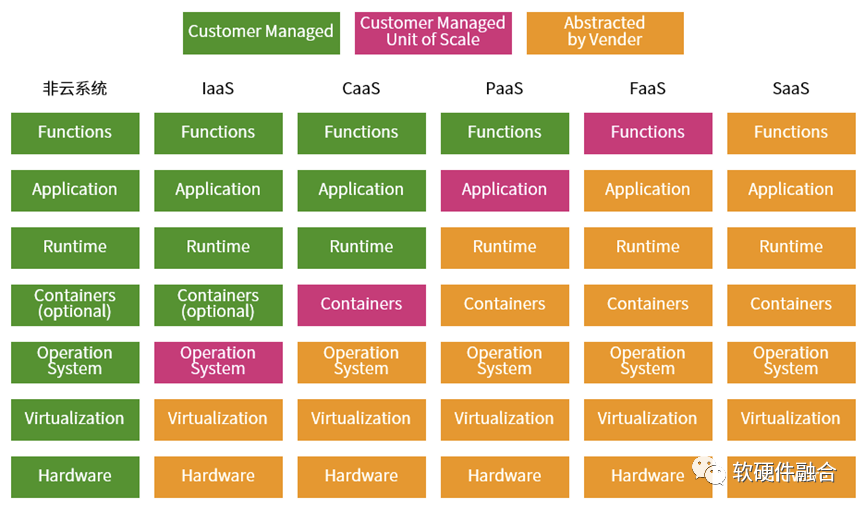
“一切皆服務”,當從微服務的視角,云計算是由不同的服務組成的分層服務體系:每一層就是一個服務族,然后不同層次的服務族組成整個云計算服務體系,這就是我們所熟悉的云計算三層服務IaaS、PaaS和SaaS。更詳細的軟件堆棧如上圖所示,從非云系統所有的“服務”堆棧都需要用戶自己擁有并維護,經過IaaS、CaaS、PaaS、FaaS,再到最后的SaaS,一切都由供應商運營維護。從左到右的過程,就是“服務”堆棧的下層layer不斷的由云運營商接管的過程。 這也是一個鮮明的“二八定律”案例:80%的任務由云運營商負責,20%的任務由用戶負責;站在用戶的角度,20%自己負責的任務價值占到80%,而運營商負責的部分只占到到20%的價值。
1.3 結論:“二八定律”在發生作用
二八定律(也稱80/20法則、關鍵少數法則、帕累托法則),起源于意大利經濟學家維弗雷多·帕累托在洛桑大學注意到了80/20的聯系,于他的文章《政治經濟學》中說明了該現象,例如:意大利約有80%的土地由20%的人口所有、80%的豌豆產量來自20%的植株等等。該原則在現今企業管理中廣泛運用。 回到計算機領域,二八定律也是一個常見的規律:
CISC指令太過冗繁,只有20%的指令經常用到,而另外80%的指令則較少用到。所以,RISC就只保留常見的20%的簡單指令。
一個應用系統,完全不同的只是應用的核心部分(大約占20%),其他的如網絡訪問、存儲盤、文件系統,也包括數據庫、負載均衡、消息隊列等(大約占80%)其實都是用戶相對不關心,并且是眾多應用系統都會用到的組件。
云計算,是一個由眾多服務組成服務分層體系,隨著不斷的抽象封裝,云運營商不斷接管了80%的眾多服務分層,而用戶只需要關注20%的應用和函數即可。
等等。
2 分析一下各類處理引擎
2.1 從單位計算復雜度的視角
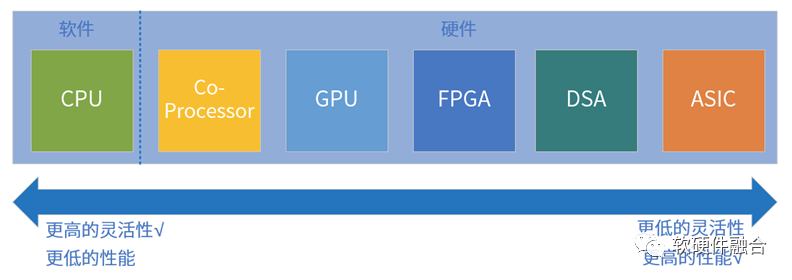
指令是軟件和硬件的媒介,指令的復雜度(單位計算密度)決定了系統的軟硬件解耦程度。按照指令的復雜度,典型的處理器引擎大致分為CPU、協處理器、GPU、FPGA、DSA、ASIC。任務在CPU運行,則定義為軟件運行;任務在協處理器、GPU、FPGA、DSA或ASIC運行,則定義為硬件加速運行。 魚和熊掌不可兼得,指令復雜度和編程靈活性是兩個互反的特征:指令越簡單,編程靈活性越高,因此我們才說軟件有更高的靈活性;指令越復雜,性能越高,因此而受到的限制越多,只能用于特定領域或場景的應用,其軟件靈活性越差。
2.2 從處理器引擎類型數量的視角
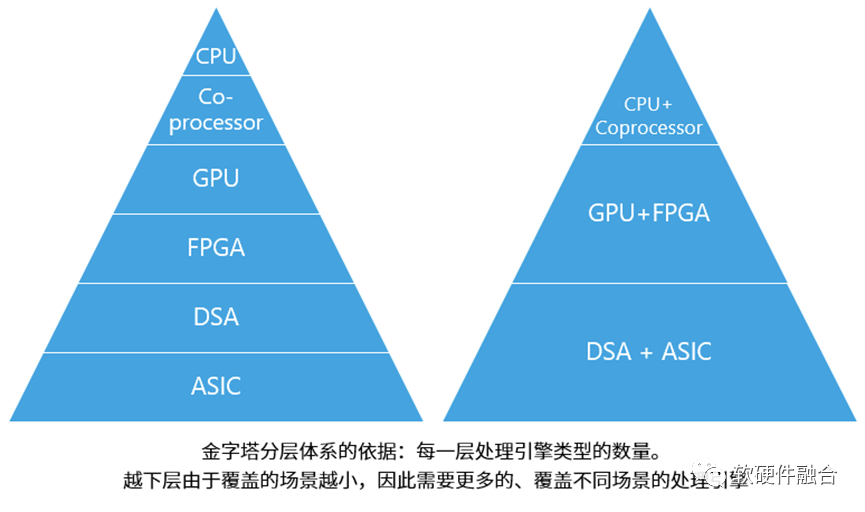
常見有六個主要的處理器引擎類型,依據不同類型處理引擎的數量不同,形成了金字塔形的處理器層次結構(Hierarchy):
CPU,是最通用的處理器引擎,CPU指令是最基礎的,因此具有最好的靈活性。這一層級的只有CPU一個形態的處理器。
Coprocessor,是基于CPU的擴展指令集的運行引擎,如ARM的NEON、Intel的AVX、AMX擴展指令集和相應的協處理器。
GPU,本質上是很多小CPU核的并行,因此NP、Graphcore的IPU等都和GPU處于同一層次的處理器類型。
FPGA,從架構上來說,可以用來實現定制的ASIC引擎,但因為硬件可編程的能力,可以切換到其他ASIC引擎,具有一定的彈性可編程能力。
DSA,是接近于ASIC的設計,但具有一定程度上的可編程。覆蓋的領域和場景比ASIC要大,但依然存在太多的領域需要特定的DSA去覆蓋。
ASIC,是完全不可編程的定制處理引擎,理論上最復雜的“指令”以及最高的性能效率。因為覆蓋的場景非常小,因此需要數量眾多的ASIC處理引擎,才能覆蓋各類場景。

為了更加簡潔的理解六類常見的處理引擎的定位和作用,我們兩兩合并,定義三大類處理引擎類型:
基礎設施層任務。基礎設施層的任務都相對確定,適合DSA和ASIC處理引擎處理。
應用層可加速部分任務。基礎設施層是Vendor負責提供,而應用層則是給到用戶應用。用戶的應用多種多樣,因此應用層的加速也需要一定程度的彈性。這樣,GPU和FPGA就相對比較合適。
應用層的不可加速部分。主要是一些通用的處理,如控制以及一些細粒度的計算。協處理器在具體實現上,是CPU的一部分。因此,CPU(包含協處理器)可以兼顧常規的控制處理以及一些計算任務。
2.3 從處理器覆蓋場景的視角

“尺有所長,寸有所短”,每個類型的處理器都有自己的優勢,也都有自己的劣勢:
CPU及協處理器,最好的靈活可編程性,可以用在任何領域和場景。但性能卻是最低。
GPU及FPGA,較好的軟件或硬件編程能力,覆蓋領域和場景較多,但性能居中無法極致。
DSA及ASIC,性能最好。但DSA的可編程性較少,可以覆蓋特定領域;ASIC完全不可編程,只能覆蓋特定領域里的某個具體場景。

“專業的人做專業的事”,通過CPU + Coprocessor + GPU + FPGA + DSA + ASIC等各種類型處理引擎的混合架構,能夠兼顧性能和靈活性:
從宏觀的看,絕大部分計算是通過加速完成的,性能有顯著的提升;
而從用戶應用的角度,應用依然是運行在CPU上,跟之前沒有變化,依然是自己“掌控一切”。
3 設計一個理想的宏處理器
因為二八定律的存在,在整個系統堆棧里,用戶關心的那20%的相對不確定的任務,仍然需要用戶通過軟件編程實現;而用戶不關心的、每個用戶應用系統都會存在的、占80%的這些相對確定的任務,則適合通過硬件加速的方式來實現。
3.1 當前的處理器芯片基本都是“單兵作戰”
處理器芯片是由各類處理器引擎組成的,在云計算數據中心,主要有三類同構處理器芯片。分析如下表所示。
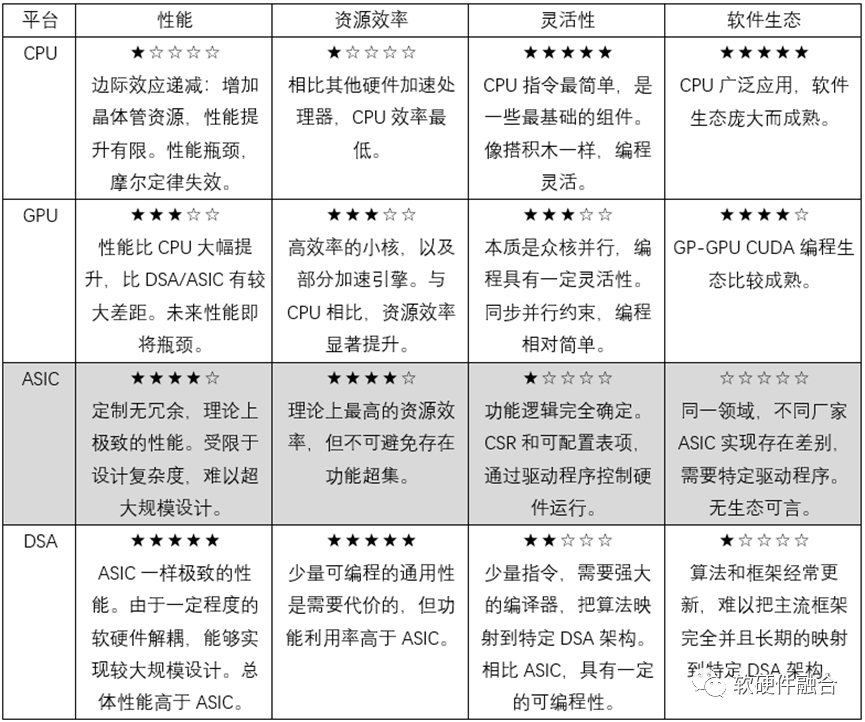
這里我們對三類引擎組成的同構處理器進行分析:
CPU是數據中心最常見的處理器,但受限于性能瓶頸的原因,目前大家都在“八仙過海,各顯神通”,通過各種各樣的優化手段,來努力提升整個服務器和數據中心的算力。
GPU在HPC、圖形圖形等領域,有非常大的優勢。近些年,隨著AI的興起,與此同時AI算法更新很快,這就使得GPU成為AI最合適的處理器,GPU因此大放光彩。
DSA目前最主要的領域也是在AI,第一款經典的DSA處理器是谷歌TPU。目前,受限于AI算法的快速迭代,仍然沒有DSA處理器的大范圍落地的案例。即使強大如谷歌能從芯片、框架到服務統統協同優化,但嚴格來說,TPU也仍然沒有大范圍落地。
3.2 CPU+xPU的異構處理仍然不夠
另外,對單個處理器引擎來說,性能和靈活性是一對矛盾,如果只考慮同構計算,則很難達到方方面面兼顧。可以通過板級集成或者芯片內集成異構的方式,實現CPU+GPU/FPGA/DSA的架構,但也是存在一些問題。
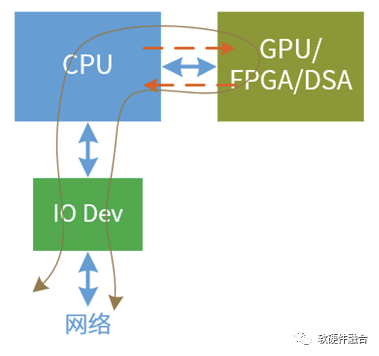
傳統異構計算的架構,是以CPU為中心,這種架構本身就存在一些問題:
IO路徑。CPU+xPU架構IO路徑太長,IO成為整個算力的瓶頸。
輸入輸出損耗。CPU+xPU加速增加了額外的CPU和xPU之間的數據輸入輸出損耗。
系統復雜度。異構計算是顯式的,CPU側軟件知道在做加速,CPU側需要處理與加速器側的數據和消息交互。
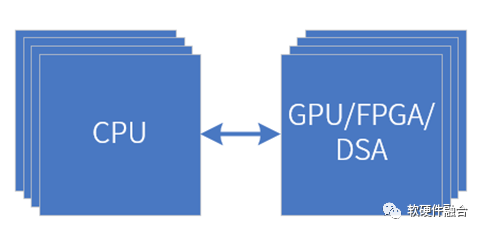
仍然受限于硬件加速處理器的特點,異構計算仍無法兼顧性能和靈活性:
GPU異構加速架構。雖然GPU具有非常好的彈性加速能力,覆蓋非常多的領域,但受限于GPU的性能效率,無法做到極致性能的加速。
FPGA異構加速架構。FPGA可以做到硬件可編程,可以通過FaaS(此處FaaS為FPGA as a Service)機制實現彈性加速。FPGA的問題在于成本和功耗過高,以及設計規模的約束,只能做非常少量并且規模較小的加速引擎。
DSA異構加速架構。DSA可以做到極致的性能加速能力,但受限于其只針對某個特定領域,所以使用范圍受限。
3.3 團隊協作成就通用的超異構處理器
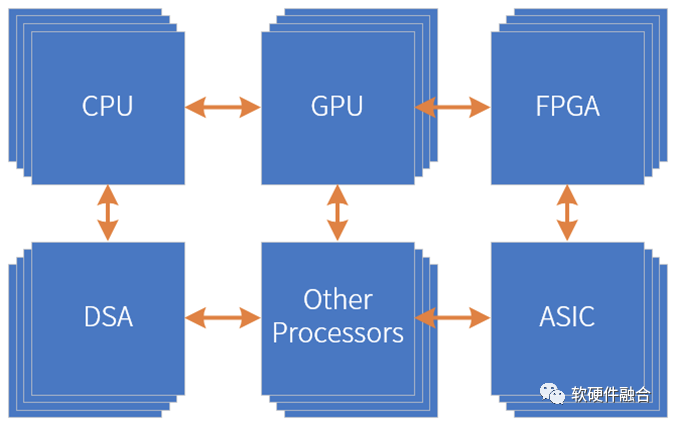
隨著CPU、GPU等常見處理引擎的成熟,也隨著工藝和Chiplet技術的進步,我們可以在單個芯片集成更多的處理器引擎,使得在單芯片超越2個形態處理引擎成為了可能,超異構處理器(Hyper-heterogeneous Processing Unit,HPU)開始逐步成為現實。
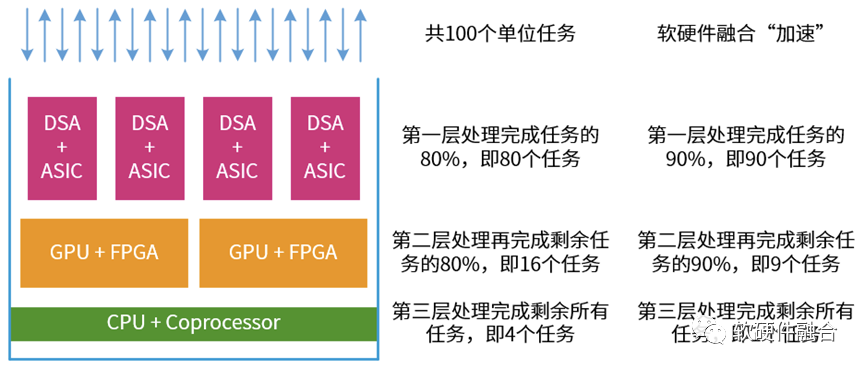
如上圖所示,有點像塔防游戲,我們設置了三層“防御”,然后待處理的任務就像是“需要消滅的敵人”:
我們假設,待處理的有100個單位任務;
第一層“防御”,DSA+ASIC能夠覆蓋80%的任務(即80個任務)的性能加速,可以很快“消滅”。但受限于覆蓋的領域和場景,會有20%(即20個任務)的“漏網之魚”;
第二層“防御”,GPU+FPGA能夠覆蓋接下來任務的80%,性能依然強勁,可以搞定剩下任務的80%(即16個任務)。但仍然有一些不是那么適合硬件加速的“頑固敵人”(剩余的4個任務)。
第三層“防御”,CPU和協處理器作為“定海神針”,能夠覆蓋所有場景。由它們負責“消滅”最后的“頑固敵人”(即處理最后4個任務)。
在沒有硬件加速的情況下,所有的100個任務都需要CPU來處理;而有了加速之后,CPU只需要處理4個任務。當整個設計足夠均衡(各類加速引擎不成為性能的瓶頸)的時候,反過來我們可以說,通過超異構處理器HPU可以實現25倍的性能提升。 受宏觀超大規模數據中心的影響,也受軟硬件深度融合的加持,可以繼續優化這里的“二八定律”,假設我們可以把不同層次處理引擎可處理的任務比例再增強10%。這樣:DSA+ASIC完成90個任務,GPU+FPGA完成9個任務,最終CPU只需要完成1個任務。或者反過來說,可以通過軟硬件融合,實現通用的超異構處理器GP-HPU,實現100倍的性能提升。
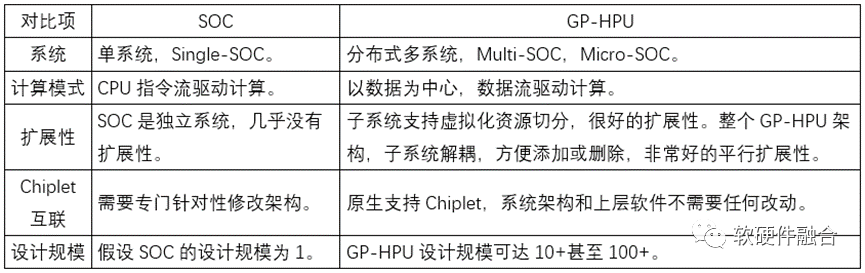
3.4 超越傳統SOC
通用超異構處理器GP-HPU,可以算是SOC,但又跟傳統的SOC有很大的不同。如果無法認識到這些不同,就無法理解到HPU的本質。下表是一些典型的區別對比。
審核編輯 :李倩
-
處理器
+關注
關注
68文章
20255瀏覽量
252310 -
RISC
+關注
關注
6文章
485瀏覽量
86607
原文標題:是否存在足夠“通用”的處理器,在性能快速提升的同時,還能夠“包治百病”?
文章出處:【微信號:bdtdsj,微信公眾號:中科院半導體所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
全球首創!RISC-V+AI架構高性能服務器CPU成功點亮
中科本原RISC-V架構 BY320RV0025 DSP正式亮相

RISC-V vs ARM:為什么工業與邊緣計算仍然選擇 ARM 架構?

新思科技STING助力破局RISC-V架構驗證復雜度
FreeRTOS 在 AS32系列RISC-V 架構MCU電機驅動中的應用實踐與優化
大咖論道:以架構創新、生態繁榮,加速RISC-V產業落地

知合計算:RISC-V架構創新,阿基米德系列劍指高性能計算

英偉達:CUDA 已經開始移植到 RISC-V 架構上
Tenstorrent 首席架構師:未來 RISC-V 會是計算機的主流
同一水平的 RISC-V 架構的 MCU,和 ARM 架構的 MCU 相比,運行速度如何?

RISC-V和ARM有何區別?


基于RISC-V雙核鎖步架構國產MCU芯片技術




 工商網監
工商網監
評論