") 利用NVIDIA TensorRT實現(xiàn)推理的QAT偽量化
利用NVIDIA TensorRT實現(xiàn)推理的QAT偽量化

深度學(xué)習(xí)正在徹底改變行業(yè)提供產(chǎn)品和服務(wù)的方式。這些服務(wù)包括用于計算機(jī)視覺的對象檢測、分類和分割,以及用于基于語言的應(yīng)用程序的文本提取、分類和摘要。這些應(yīng)用程序必須實時運行。
大多數(shù)模型都采用浮點 32 位算法進(jìn)行訓(xùn)練,以利用更大的動態(tài)范圍。然而,在推理時,這些模型可能需要更長的時間來預(yù)測結(jié)果相比,精度降低推理,造成一些延遲的實時響應(yīng),并影響用戶體驗。
在許多情況下,最好使用精度降低的整數(shù)或 8 位整數(shù)。挑戰(zhàn)在于訓(xùn)練后簡單地四舍五入權(quán)重可能導(dǎo)致較低的模型精度,特別是當(dāng)權(quán)重具有較大的動態(tài)范圍時。本文簡單介紹了量化感知訓(xùn)練( QAT ),以及如何在訓(xùn)練過程中實現(xiàn)偽量化,并用 NVIDIA TensorRT 8 。 0 進(jìn)行推理。
概述
模型量化是一種流行的深度學(xué)習(xí)優(yōu)化方法,其中模型數(shù)據(jù)(包括網(wǎng)絡(luò)參數(shù)和激活)從浮點表示轉(zhuǎn)換為較低精度表示,通常使用 8 位整數(shù)。這有幾個好處:
在處理 8 位整數(shù)數(shù)據(jù)時, NVIDIA GPU 使用更快更便宜的 8 位 張量核 來計算卷積和矩陣乘法運算。這會產(chǎn)生更多的計算吞吐量,這在計算受限的層上尤其有效。
將數(shù)據(jù)從內(nèi)存移動到計算元素(在 NVIDIA GPU s 中的流式多處理器)需要時間和精力,而且還會產(chǎn)生熱量。將激活和參數(shù)數(shù)據(jù)的精度從 32 位浮點值降低到 8 位整數(shù)可導(dǎo)致 4 倍的數(shù)據(jù)縮減,從而 省電 并減少產(chǎn)生的熱量。
有些層有帶寬限制(內(nèi)存有限)。這意味著它們的實現(xiàn)將大部分時間用于讀寫數(shù)據(jù),因此減少它們的計算時間并不會減少它們的總體運行時間。帶寬限制層從減少的帶寬需求中獲益最大。
減少內(nèi)存占用意味著模型需要更少的存儲空間,參數(shù)更新更小,緩存利用率更高,等等。
量子化方法
量化有很多好處,但是參數(shù)和數(shù)據(jù)精度的降低很容易影響模型的任務(wù)精度。考慮到 32 位浮點可以在區(qū)間[-3 。 4e38 , 3 。 40e38]中表示大約 40 億個數(shù)字。這個可表示數(shù)的區(qū)間也被稱為 dynamic-range 。兩個相鄰的可表示數(shù)字之間的距離是表示的 精確 。
浮點數(shù)在動態(tài)范圍內(nèi)分布不均勻,大約一半的可表示浮點數(shù)在區(qū)間[-1 , 1]內(nèi)。換言之,[-1 , 1]區(qū)間中的可表示數(shù)字將比[1 , 2]中的數(shù)字具有更高的精度。[-1 , 1]中可表示的 32 位浮點數(shù)的高密度有助于深度學(xué)習(xí)模型,其中參數(shù)和數(shù)據(jù)的大部分分布質(zhì)量都在零附近。
但是,使用 8 位整數(shù)表示法,只能表示 28不同的價值觀。這 256 個值可以均勻地或不均勻地分布,例如,為了在零附近獲得更高的精度。所有主流的深度學(xué)習(xí)硬件和軟件都選擇使用統(tǒng)一的表示,因為它能夠使用高吞吐量的并行或矢量化整數(shù)數(shù)學(xué)管道進(jìn)行計算。
轉(zhuǎn)換浮點張量的表示 (Xf) 到 8 位表示 (Xq) ,使用 scale-factor 將浮點張量的動態(tài)范圍映射到[-128 , 127]:
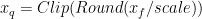
這是對稱量子化,因為動態(tài)范圍是關(guān)于原點對稱的。
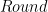
是一個應(yīng)用某些舍入策略將有理數(shù)舍入為整數(shù)的函數(shù);和
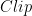
是一個函數(shù),用于剪裁超出[-128127]區(qū)間的異常值。 TensorRT 使用對稱量化來表示激活數(shù)據(jù)和模型權(quán)重。
圖 1 的頂部是一個任意浮點張量的圖Xf,表示為元素分布的直方圖。我們選擇了一個對稱的系數(shù)范圍來表示量化張量:[-amax,amax]。 在這里amax是要表示的絕對值最大的元素。要計算量化比例,請將浮點動態(tài)范圍劃分為 256 個相等部分:


這里顯示的計算比例的方法使用 全量程 ,可以用有符號 8 位整數(shù)表示:[-128 , 127]。 TensorRT 顯式精度( Q / DQ )網(wǎng)絡(luò)在量化權(quán)重和激活時使用此范圍。
使用 8 位整數(shù)表示的動態(tài)范圍與舍入操作引入的誤差之間存在緊張關(guān)系。較大的動態(tài)范圍意味著原始浮點張量中的更多值用量化張量表示,但也意味著使用較低的精度和引入較大的舍入誤差。
選擇較小的動態(tài)范圍可以減小舍入誤差,但會引入剪裁誤差。超出動態(tài)范圍的浮點值將被剪裁為動態(tài)范圍的最小/最大值。
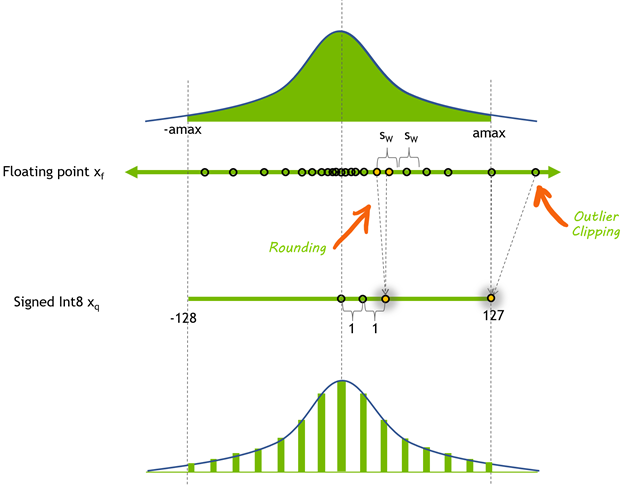
圖 1 。浮點張量的 8 位有符號整數(shù)量化Xf對稱動態(tài)范圍Xf[-amax,amax]通過量化映射到 [-128 , 127]。
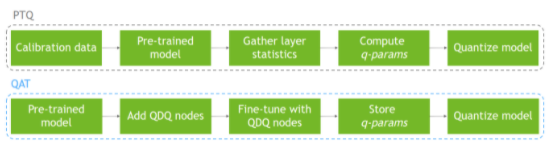
為了解決精度損失對任務(wù)精度的影響,人們發(fā)展了各種量化技術(shù)。這些技術(shù)可以分為兩類:訓(xùn)練后量化( PTQ )或量化感知訓(xùn)練( QAT )。
顧名思義, PTQ 是在高精度模型經(jīng)過訓(xùn)練后進(jìn)行的。使用 PTQ ,量化權(quán)重很容易。您可以訪問權(quán)重張量并可以測量它們的分布。量化激活更具挑戰(zhàn)性,因為激活分布必須使用實際輸入數(shù)據(jù)進(jìn)行測量。
為此,使用代表任務(wù)實際輸入數(shù)據(jù)的小數(shù)據(jù)集評估訓(xùn)練的浮點模型,并收集有關(guān)層間激活分布的統(tǒng)計信息。作為最后一步,使用幾個優(yōu)化目標(biāo)之一確定模型激活張量的量化尺度。這個過程是 校準(zhǔn) ,使用的代表數(shù)據(jù)集是 calibration-dataset 。
有時 PTQ 不能達(dá)到可接受的任務(wù)準(zhǔn)確性。這是當(dāng)你 MIG HT 考慮使用 QAT 的時候。 QAT 背后的思想很簡單:如果在訓(xùn)練階段包含量化誤差,就可以提高量化模型的精度。它使網(wǎng)絡(luò)能夠適應(yīng)量化的權(quán)值和激活。
有各種各樣的方法來執(zhí)行 QAT ,從一個未經(jīng)訓(xùn)練的模型開始到一個預(yù)先訓(xùn)練的模型開始。通過在訓(xùn)練圖中插入假量化操作來模擬數(shù)據(jù)和參數(shù)的量化,所有的方法都改變了訓(xùn)練方案,將量化誤差包含在訓(xùn)練損失中。這些運算被稱為“假”運算,因為它們對數(shù)據(jù)進(jìn)行量化,然后立即對數(shù)據(jù)進(jìn)行去量化,這樣運算的計算就保持浮點精度。這個技巧在深度學(xué)習(xí)框架中增加了量化噪聲而沒有太大變化。
在前向過程中,對浮點權(quán)重和激活進(jìn)行偽量化,并使用這些偽量化的權(quán)重和激活來執(zhí)行層的操作。在向后過程中,使用權(quán)重的漸變來更新浮點權(quán)重。為了處理量化梯度,除了未定義的點之外,幾乎所有地方都是零,您可以使用( 直通估計器 ( STE ),它通過偽量化操作符傳遞梯度。當(dāng) QAT 過程完成時,偽量化層持有量化尺度,您可以使用這些尺度來量化模型用于推理的權(quán)重和激活。
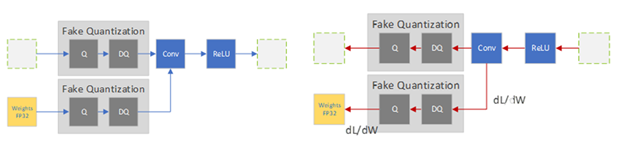
圖 2 。訓(xùn)練前傳球中的 QAT 偽量化算子 (左) 后傳球 (右)
PTQ 是這兩種方法中比較流行的方法,因為它簡單,不涉及訓(xùn)練管道,這也使得它成為一種更快的方法。然而, QAT 幾乎總是產(chǎn)生更好的精度,有時這是唯一可以接受的方法。
TensorRT 中的量子化
TensorRT 8 。 0 支持使用兩種不同處理模式的 INT8 模型。第一種處理模式使用 TensorRT 張量動態(tài)范圍 API ,并利用 INT8 精度( 8 位有符號整數(shù))計算和數(shù)據(jù)機(jī)會優(yōu)化推理延遲。
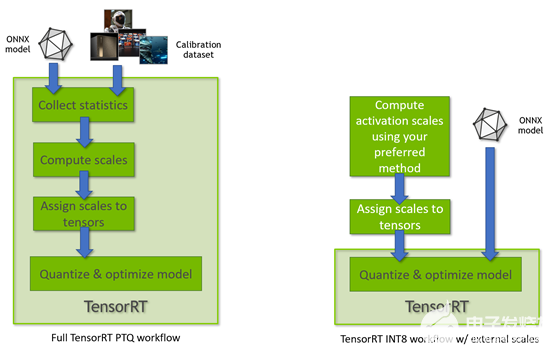
圖 3 。 TensorRT PTQ 工作流程 (左) vs 。 TensorRT INT8 量子化,使用從配置張量動態(tài)范圍導(dǎo)出的量子化尺度 (右)
當(dāng) TensorRT 執(zhí)行完整的 PTQ 校準(zhǔn)配方時,以及當(dāng) TensorRT 使用預(yù)配置的張量動態(tài)范圍時,使用此模式(圖 3 )。另一種 TensorRT INT8 處理模式用于處理具有 QuantizeLayer/DequantizeLayer 層的浮點 ONNX 網(wǎng)絡(luò),并遵循 顯式量化規(guī)則 。有關(guān)差異的更多信息,請參閱 TensorRT 開發(fā)人員指南中的 顯式量化與 PTQ 處理 。
TensorRT 量化工具箱
TensorRT ZCK4 的量化工具箱 通過提供一個方便的 PyTorch 庫來補(bǔ)充 TensorRT ,該庫有助于生成可優(yōu)化的 QAT 模型。該工具包提供了一個 API 來自動或手動為 QAT 或 PTQ 準(zhǔn)備模型。
API 的核心是 TensorQuantizer 模塊,它可以量化、偽量化或收集張量的統(tǒng)計信息。它與 QuantDescriptor 一起使用,后者描述了如何量化張量。在 TensorQuantizer 之上分層的是量化模塊,這些模塊被設(shè)計為 PyTorch 全精度模塊的替代品。這些是使用 TensorQuantizer 對模塊的權(quán)重和輸入進(jìn)行偽量化或收集統(tǒng)計信息的方便模塊。
API 支持將 PyTorch 模塊自動轉(zhuǎn)換為其量化版本。轉(zhuǎn)換也可以使用 API 手動完成,這允許在不想量化所有模塊的情況下進(jìn)行部分量化。例如,一些層可能對量化更敏感,并且使其未量化可提高任務(wù)精度。

圖 4 。 TensorRT 量化工具箱組件
在 NVIDIA 量子化 白皮書中詳細(xì)描述了 QAT 的 TensorRT 特定配方,其中包括對量化方法的更嚴(yán)格的討論,以及在各種學(xué)習(xí)任務(wù)上比較 QAT 和 PTQ 的實驗結(jié)果。
代碼示例演練
本節(jié)描述了工具箱中包含的分類任務(wù)量化 例子 。
QAT 的推薦工具箱配方要求從預(yù)訓(xùn)練模型開始,因為 展示 已經(jīng)指出,從預(yù)訓(xùn)練模型開始并進(jìn)行微調(diào)可以獲得更好的精度,并且需要的迭代次數(shù)要少得多。在本例中,加載一個 預(yù)訓(xùn)練 ResNet50 模型 。從 bash shell 運行示例的命令行參數(shù):

--data-dir 參數(shù)指向 ImageNet ( ILSVRC2012 )數(shù)據(jù)集,您必須分別使用 download 數(shù)據(jù)集。 --calibrator=histogram 參數(shù)指定在微調(diào)模型之前,應(yīng)該使用直方圖校準(zhǔn)器對模型進(jìn)行校準(zhǔn)。其余的參數(shù)以及更多的參數(shù)都記錄在示例中。
ResNet50 模型最初來自 Facebook 的 Torchvision 包,但是因為它包含一些重要的更改(跳過連接的量化),所以網(wǎng)絡(luò)定義包含在工具箱中( resnet50_res )。有關(guān)詳細(xì)信息,請參閱 Q / DQ 層布置建議 。
下面是代碼的簡要概述。
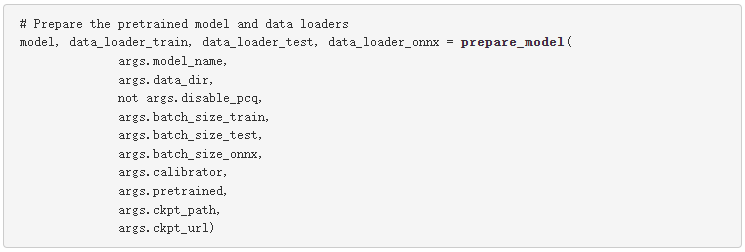
函數(shù) prepare_model 像往常一樣實例化數(shù)據(jù)加載器和模型,但它也配置量化描述符。舉個例子:

QuantDescriptor 的實例描述了如何通過配置校準(zhǔn)方法和量化軸來校準(zhǔn)和量化張量。對于每個量化操作(例如 quant_nn.QuantConv2d ),您可以在 QuantDescriptor 中分別配置激活和權(quán)重,因為它們使用不同的偽量化節(jié)點。
然后在訓(xùn)練圖中添加假量化節(jié)點。下面的代碼( quant_modules.initialize )在幕后動態(tài)地修補(bǔ) PyTorch 代碼,以便將 torch.nn.module 的一些子類替換為它們的量化對應(yīng)項,實例化模型的模塊,然后還原動態(tài)修補(bǔ)程序( quant_modules.deactivate )。例如,將 torch.nn.conv2d 替換為 pytorch_quantization.nn.QuantConv2d ,其在執(zhí)行 2D 卷積之前執(zhí)行偽量化。應(yīng)該在模型實例化之前調(diào)用方法 quant_modules.initialize 。

接下來,收集校準(zhǔn)數(shù)據(jù)的統(tǒng)計信息( collect_stats ):將校準(zhǔn)數(shù)據(jù)饋送到模型,并以直方圖的形式收集每個層的激活分布統(tǒng)計信息以進(jìn)行量化。收集直方圖數(shù)據(jù)后,使用一個或多個校準(zhǔn)算法( compute_amax )校準(zhǔn)刻度( calibrate_model )。
在標(biāo)定過程中,盡量確定每一層的量化尺度,以達(dá)到優(yōu)化模型精度等目標(biāo)。目前有兩種校準(zhǔn)器等級:
pytorch_quantization.calib.histogram – 使用熵最小化( KLD )、均方誤差最小化( MSE )或百分位度量方法(選擇動態(tài)范圍,以表示指定的分布百分比)。
pytorch_quantization.calib.max – 使用最大激活值進(jìn)行校準(zhǔn)(表示浮點數(shù)據(jù)的整個動態(tài)范圍)。
要在以后確定校準(zhǔn)方法的質(zhì)量,請在數(shù)據(jù)集上評估模型精度。該工具包可以很容易地比較四種不同校準(zhǔn)方法的結(jié)果,以發(fā)現(xiàn)適用于特定模型的最佳方法。該工具包可以擴(kuò)展專有的校準(zhǔn)算法。有關(guān)更多信息,請參閱 ResNet50 示例筆記本 。
如果模型的精度令人滿意,你不必繼續(xù)進(jìn)行 QAT 。您可以導(dǎo)出到 ONNX 并完成。這就是 PTQ 配方。 TensorRT 給出了具有量化尺度的 Q / DQ 算子的 ONNX 模型,并優(yōu)化了模型進(jìn)行推理。所以,這是一個 PTQ 工作流,它產(chǎn)生了一個 Q / dqonnx 模型。
要繼續(xù)到 QAT 階段,請選擇最佳校準(zhǔn)、量化模型。使用 QAT 對原始訓(xùn)練計劃的 10% 左右進(jìn)行微調(diào),并使用退火學(xué)習(xí)率計劃,最后導(dǎo)出到 ONNX 。有關(guān)更多信息,請參閱 深度學(xué)習(xí)推理的整數(shù)量化:原理與實證評價 白皮書。
導(dǎo)出到 ONNX 時,需要記住以下幾點:
ONNX opset 13 中引入了每通道量化( PCQ ),因此如果您按照建議使用 PCQ ,請注意您使用的 opset 版本。
參數(shù) do_constant_folding 應(yīng)設(shè)置為 True ,以生成可讀性更好的較小模型。

當(dāng)模型最終導(dǎo)出到 ONNX 時,偽量化節(jié)點作為兩個獨立的 ONNX 操作符導(dǎo)出到 ONNX : QuantizeLinear 和 DequantizeLinear (如圖 5 中的 Q 和 DQ 所示)。
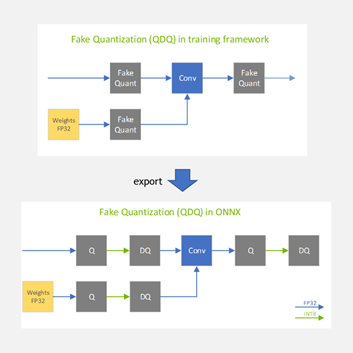
圖 5 。偽量化運算符被轉(zhuǎn)換為 Q/DQ PyTorch 模型導(dǎo)出到 ONNX 時的 ONNX 運算符
QAT 推斷階段
在高層次上, TensorRT 使用 Q / DQ 運算符處理 ONNX 模型,類似于 TensorRT 處理任何其他 ONNX 模型的方式:
TensorRT 導(dǎo)入包含 Q / DQ 操作的 ONNX 模型。
它執(zhí)行一組專門用于 Q / DQ 處理的優(yōu)化。
它繼續(xù)執(zhí)行常規(guī)優(yōu)化過程。
它為推理執(zhí)行構(gòu)建了一個特定于平臺的執(zhí)行計劃文件。此計劃文件包含量化操作和權(quán)重。
除了啟用 INT8 外,在 TensorRT 中構(gòu)建 Q / DQ 網(wǎng)絡(luò)不需要任何特殊的生成器配置,因為在網(wǎng)絡(luò)中檢測到 Q / DQ 層時,它會自動啟用。使用 TensorRT 示例應(yīng)用程序 trtexec 構(gòu)建 Q / DQ 網(wǎng)絡(luò)的最小命令如下:

TensorRT 使用稱為 顯式量子化 的特殊模式優(yōu)化 Q / DQ 網(wǎng)絡(luò),這是出于對網(wǎng)絡(luò)處理可預(yù)測性的要求和對用于網(wǎng)絡(luò)操作的算術(shù)精度的控制。處理可預(yù)測性是保持原始模型計算精度的保證。其思想是, Q / DQ 層指定必須發(fā)生精度轉(zhuǎn)換的位置,并且所有優(yōu)化必須保留原始 ONNX 模型的算術(shù)語義。
對比 TensorRT Q / DQ 處理和普通 TensorRT INT8 處理有助于更好地解釋這一點。在 plain TensorRT 中,使用 動態(tài)范圍 API 或通過 校準(zhǔn)過程 為 INT8 網(wǎng)絡(luò)張量分配量化尺度。 TensorRT 在應(yīng)用后端優(yōu)化時將模型視為浮點模型,并使用 INT8 作為另一個工具來優(yōu)化層執(zhí)行時間。如果一個層在 INT8 中運行得更快,那么它被配置為使用 INT8 。否則,使用 FP32 或 FP16 ,以較快者為準(zhǔn)。在這種模式下, TensorRT 只針對延遲進(jìn)行優(yōu)化,您幾乎無法控制量化哪些操作。
相反,在顯式量化中, Q / DQ 層指定必須發(fā)生精度轉(zhuǎn)換的位置。優(yōu)化器不允許執(zhí)行非由網(wǎng)絡(luò)指定的精度轉(zhuǎn)換。即使這樣的轉(zhuǎn)換提高了層精度(例如,選擇 FP16 實現(xiàn)而不是 INT8 實現(xiàn)),并且即使這樣的轉(zhuǎn)換會導(dǎo)致執(zhí)行速度更快的計劃文件(例如,在 V100 上, INT8 不被張量核加速時,首選 INT8 而不是 FP16 ),這也是正確的。
在顯式量化中,您可以完全控制精度轉(zhuǎn)換,并且量化是可預(yù)測的。 TensorRT 仍然優(yōu)化性能,但要保持原始模型的算術(shù)精度。不支持在 Q / DQ 網(wǎng)絡(luò)上使用動態(tài)范圍 API 。
顯式量化優(yōu)化過程分為三個階段:
首先,優(yōu)化器嘗試最大化模型的 INT8 數(shù)據(jù),并使用 Q / DQ 層傳播進(jìn)行計算。 Q / DQ 傳播是一組規(guī)則,指定 Q / DQ 層如何在網(wǎng)絡(luò)中 MIG 速率。例如, QuantizeLayer 可以 MIG 通過與 ReLU 激活層交換位置來對網(wǎng)絡(luò)的開始部分進(jìn)行速率調(diào)整。通過這樣做, ReLU 層的輸入和輸出激活減少到 INT8 精度,帶寬需求減少 4 倍。
然后,優(yōu)化器融合層來創(chuàng)建對 INT8 輸入操作的量化操作,并使用 INT8 數(shù)學(xué)管道。例如, QuantizeLayer 可以與 ConvolutionLayer 融合。
最后, TensorRT 自動調(diào)諧器優(yōu)化器搜索每一層的最快實現(xiàn),同時也尊重該層指定的輸入和輸出精度。
有關(guān) TensorRT 執(zhí)行的主要顯式量化優(yōu)化的更多信息,請參閱 TensorRT 開發(fā)者指南 。
通過構(gòu)建 TensorRT Q / DQ 網(wǎng)絡(luò)創(chuàng)建的計劃文件包含量化的權(quán)重和操作,可以部署。 EfficientNet 是需要 QAT 來保持準(zhǔn)確性的網(wǎng)絡(luò)之一。下表比較了 PTQ 和 QAT 。
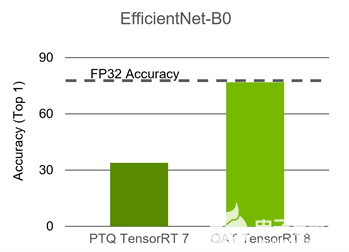
圖 6 。 PTQ 和 QAT 上 EfficientNet-B0 的精確度比較
總結(jié)
在這篇文章中,我們簡要介紹了基本的量化概念和 TensorRT 的量化工具箱,然后回顧了 TensorRT 8 。 0 是如何處理 Q / DQ 網(wǎng)絡(luò)的。我們對量化工具箱提供的 resnet50qat 示例進(jìn)行了快速演練。
ResNet50 可以用 PTQ 量化,不需要 QAT 。然而, EfficientNet 需要 QAT 來保持準(zhǔn)確性。 EfficientNet B0 基線浮點 Top1 精度為 77 。 4 , PTQ Top1 精度為 33 。 9 , QAT Top1 精度為 76 。 8 。
關(guān)于作者
About Neta Zmora
Neta Zmora 是一位高級深度學(xué)習(xí)軟件架構(gòu)師,致力于 DL 加速。在 2020 年加入 NVIDIA 之前,內(nèi)塔是英特爾人工智能實驗室的研究工程師,負(fù)責(zé)開發(fā)深度神經(jīng)網(wǎng)絡(luò)壓縮方法。
About Hao Wu
Hao Wu 是 NVIDIA 的高級 GPU 計算架構(gòu)師。他在完成博士學(xué)位后于 2011 年加入 NVIDIA 計算架構(gòu)組。在中國科學(xué)院。近年來, Hao 的技術(shù)重點是將低精度應(yīng)用于深度神經(jīng)網(wǎng)絡(luò)訓(xùn)練和推理。
About Jay Rodge
Jay Rodge 是 NVIDIA 的產(chǎn)品營銷經(jīng)理,負(fù)責(zé)深入學(xué)習(xí)和推理產(chǎn)品,推動產(chǎn)品發(fā)布和產(chǎn)品營銷計劃。杰伊在芝加哥伊利諾伊理工學(xué)院獲得計算機(jī)科學(xué)碩士學(xué)位,主攻計算機(jī)視覺和自然語言處理。在 NVIDIA 之前,杰伊是寶馬集團(tuán)的人工智能研究實習(xí)生,為寶馬最大的制造廠使用計算機(jī)視覺解決問題。
審核編輯:郭婷
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5594瀏覽量
109731 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5599瀏覽量
124398
發(fā)布評論請先 登錄
如何在魔搭社區(qū)使用TensorRT-LLM加速優(yōu)化Qwen3系列模型推理部署
NVIDIA TensorRT 8.2將推理速度提高6倍
NVIDIA TensorRT助力打造AI計算機(jī)視覺算法推理平臺
使用NVIDIA QAT工具包實現(xiàn)TensorRT量化網(wǎng)絡(luò)的設(shè)計
NVIDIA T4 GPU和TensorRT提高微信搜索速度
NVIDIA TensorRT插件的全自動生成工具
螞蟻鏈AIoT團(tuán)隊與NVIDIA合作加速AI推理
FP32推理TensorRT演示
學(xué)習(xí)資源 | NVIDIA TensorRT 全新教程上線

現(xiàn)已公開發(fā)布!歡迎使用 NVIDIA TensorRT-LLM 優(yōu)化大語言模型推理

利用NVIDIA組件提升GPU推理的吞吐
魔搭社區(qū)借助NVIDIA TensorRT-LLM提升LLM推理效率
TensorRT-LLM低精度推理優(yōu)化




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論