 用NVIDIA H100 CNX構建人工智能系統
用NVIDIA H100 CNX構建人工智能系統

人們對能夠以更快的速度將數據從網絡傳輸到 GPU 的服務器的需求不斷增加。隨著人工智能模型不斷變大,訓練所需的數據量需要多節點訓練等技術才能在合理的時間范圍內取得成果。 5G 的信號處理比前幾代更復雜, GPU 可以幫助提高這種情況發生的速度。機器人或傳感器等設備也開始使用 5G 與邊緣服務器通信,以實現基于人工智能的決策和行動。
專門構建的人工智能系統,比如最近發布的 NVIDIA DGX H100 ,是專門為支持數據中心用例的這些需求而設計的。現在,另一種新產品可以幫助企業獲得更快的數據傳輸和更高的邊緣設備性能,但不需要高端或定制系統。
NVIDIA 首席執行官 Jensen Huang 上周在 NVIDIA 公司 GTC 宣布, NVIDIA H100 CNX 是一個高性能的企業包。它結合了 NVIDIA H100 的能力與 NVIDIA ConnectX-7 SmartNIC 先進的網絡能力。這種先進的體系結構在 PCIe 板上提供,為主流數據中心和邊緣系統的 GPU 供電和 I / O 密集型工作負載提供了前所未有的性能。
H100 CNX 的設計優勢
在標準 PCIe 設備中,控制平面和數據平面共享相同的物理連接。然而,在 H100 CNX 中, GPU 和網絡適配器通過直接 PCIe Gen5 通道連接。這為 GPU 和使用 GPUDirect RDMA 的網絡之間的數據傳輸提供了專用的高速路徑,并消除了通過主機的數據瓶頸。
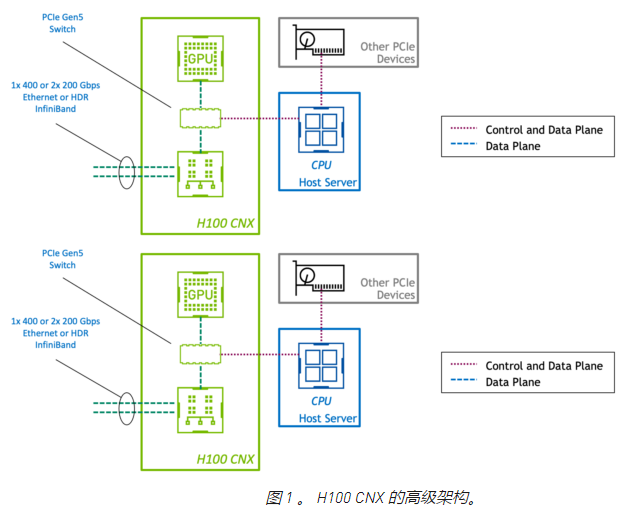
通過將 GPU 和 SmartNIC 組合在一塊板上,客戶可以利用 PCIe Gen4 甚至 Gen3 上的服務器。通過高端或專門構建的系統實現一次性能水平可以節省硬件成本。將這些組件放在一塊物理板上也可以提高空間和能源效率。
將 GPU 和 SmartNIC 集成到單個設備中,通過設計創建了一個平衡的體系結構。在具有多個 GPU 和 NIC 的系統中,聚合加速卡強制 GPU 與 NIC 的比例為 1:1 。這避免了服務器 PCIe 總線上的爭用,因此性能會隨著附加設備線性擴展。
NVIDIA 的核心加速軟件庫(如 NCCL 和 UCX )自動利用性能最佳的路徑將數據傳輸到 GPU 。現有的加速多節點應用程序可以在不做任何修改的情況下利用 H100 CNX ,因此客戶可以立即從高性能和可擴展性中受益。
H100 CNX 用例
H100 CNX 提供 GPU 加速,同時具有低延遲和高速網絡。這是在較低的功耗下完成的,與兩個分立的卡相比,占用空間更小,性能更高。許多用例可以從這種組合中受益,但以下幾點尤其值得注意。
5G 信號處理
使用 GPU 進行 5G 信號處理需要盡快將數據從網絡移動到 GPU ,并且具有可預測的延遲也是至關重要的。 NVIDIA 聚合加速器與 NVIDIA Aerial SDK 相結合,為運行 5G 應用程序提供了性能最高的平臺。由于數據不經過主機 PCIe 系統,因此處理延遲大大減少。在使用速度較慢的 PCIe 系統的商品服務器時,甚至可以看到這種性能的提高。
加速 5G 以上的邊緣人工智能
NVIDIA AI on 5G 由 NVIDIA EGX 企業平臺、 NVIDIA 公司的 SDK 軟件定義的 5G 虛擬無線局域網和企業 AI 框架組成。這包括像 NVIDIA ISAAC 和 NVIDIA Metropolis 這樣的 SDK 。攝像機、工業傳感器和機器人等邊緣設備可以使用人工智能,并通過 5G 與服務器通信。
H100 CNX 可以在單個企業服務器中提供此功能,而無需部署昂貴的專用系統。與NVIDIA 多實例 GPU 技術相比,應用于 5G 信號處理的相同加速器可用于邊緣 AI 。這使得共享 GPU 用于多種不同目的成為可能。
多節點人工智能訓練
多節點培訓涉及不同主機上 GPU 之間的數據傳輸。在一個典型的數據中心網絡中,服務器通常會在性能、規模和密度方面受到各種限制。大多數企業服務器不包括 PCIe 交換機,因此 CPU 成為這種流量的瓶頸。數據傳輸受主機 PCIe 背板的速度限制。雖然 GPU:NIC 的比例為 1:1 是理想的,但服務器中 PCIe 通道和插槽的數量可能會限制設備的總數。
H100 CNX 的設計緩解了這些問題。從網絡到 GPU 有一條專用路徑,供 GPUDirect RDMA 以接近線路速度運行。無論主機 PCIe 背板如何,數據傳輸也會以 PCIe Gen5 的速度進行。主機內 GPU 功率的放大可以以平衡的方式進行,因為 GPU:NIC 的比例是 1:1 。服務器還可以配備更多的加速能力,因為與離散卡相比,聚合加速器所需的 PCIe 通道和設備插槽更少。
NVIDIA H100 CNX 預計可在今年下半年購買。如果你有一個用例可以從這個獨特而創新的產品中受益,請聯系你最喜歡的系統供應商,詢問他們計劃何時將其與服務器一起提供。
關于作者:About Charu Chaubal
Charu Chaubal 在NVIDIA 企業計算平臺集團從事產品營銷工作。他在市場營銷、客戶教育以及技術產品和服務的售前工作方面擁有 20 多年的經驗。 Charu 曾在云計算、超融合基礎設施和 IT 安全等多個領域工作。作為 VMware 的技術營銷領導者,他幫助推出了許多產品,這些產品共同發展成為數十億美元的業務。此前,他曾在 Sun Microsystems 工作,在那里他設計了分布式資源管理和 HPC 基礎設施軟件解決方案。查魯擁有化學工程博士學位,并擁有多項專利。
-
人工智能
+關注
關注
1817文章
50098瀏覽量
265393 -
5G
+關注
關注
1367文章
49155瀏覽量
616608 -
H100
+關注
關注
0文章
33瀏覽量
588
發布評論請先 登錄

中軟國際教育科技集團攜手蘭州大學構建人工智能通識創新實驗室
Magna AI加入NVIDIA Inception計劃,推動生產級人工智能規模化發展
使用OpenUSD與NVIDIA Halos構建安全物理AI系統
英偉達 H100 GPU 掉卡?做好這五點,讓算力穩如泰山!

利用超微型 Neuton ML 模型解鎖 SoC 邊緣人工智能
Lambda采用Supermicro NVIDIA Blackwell GPU服務器集群構建人工智能工廠
挖到寶了!人工智能綜合實驗箱,高校新工科的寶藏神器
挖到寶了!比鄰星人工智能綜合實驗箱,高校新工科的寶藏神器!
最新人工智能硬件培訓AI 基礎入門學習課程參考2025版(大模型篇)
如何構建邊緣人工智能基礎設施
是德科技如何破解人工智能的基礎設施困局
GPU 維修干貨 | 英偉達 GPU H100 常見故障有哪些?
開售RK3576 高性能人工智能主板
Cognizant將與NVIDIA合作部署神經人工智能平臺,加速企業人工智能應用




 工商網監
工商網監
評論