 如何編寫有利于編譯器優化的代碼
如何編寫有利于編譯器優化的代碼

在嵌入式開發中,代碼的體積和運行效率非常重要,代碼體積往往和芯片的FLASH、RAM容量對應,程序的運行效率也要求在相應能力的處理器上運行。在大多數情況下,成熟的開發人員都希望降低代碼體積、提高代碼運行效率,然而具體該怎么做呢?本篇文章將以國際知名編譯器廠商IAR Systems的編譯器為例,來解答開發人員在實際工作中常常遇到的問題,工程師朋友們可以在IAR編譯器上進行實踐驗證。
對于嵌入式系統,最終代碼的體積和效率取決于由編譯器生成的可執行代碼,而非開發人員編寫的源代碼;但是源代碼的優化,可以幫助編譯器生成更加優質的可執行代碼。因此,開發人員不僅要從整體效率等因素上去構思源代碼體系,也要高度關注編譯器的性能和編譯優化的便捷性。
有優化功能的編譯器可生成既小又快的可執行代碼,編譯器是通過對源代碼的重復轉換來實現優化。通常,編譯器優化會遵循完善的數學或邏輯理論基礎。但是某些編譯優化則是通過啟發式的方法,經驗表明,一些代碼轉換往往會產生更好的代碼,或者開拓出進一步編譯優化的空間。
編譯優化只有少數情況依賴于編譯器的黑科技,大多數時候編寫源代碼的方式決定了程序是否可以被編譯器優化。在某些情況下,即使對源代碼做微小改動也會對編譯器生成的代碼效率產生重大影響。
本文將講述在編寫代碼時需要注意的事項,但我們首先應明確一點,我們沒有必要盡量減少代碼量,因為即使在一個表達式中使用 ?:- 表達式、后增量和逗號表達式來消除副作用,也不會使編譯器產生更有效的代碼。這只會使你的源代碼變得晦澀難懂,難以維護。例如在一個復雜的表達式中間加入一個后增量或賦值,則在讀代碼的時候很容易被忽略。請盡量用一種易于閱讀的風格來編寫代碼。
循環
下面看似簡單的循環會報錯嗎?
for (i = 0; i != n; ++i)
{
a[i] = b[i];
}
雖然不會報錯,但其中有幾點會影響到編譯器生成的代碼效率。
例如,索引變量的類型應與指針相匹配。
像 a[i] 這樣的數組表達式實際上是 *(&a[0]+i*sizeof(a[0]),或者通俗地說:將第 i個元素的偏移量加到 a 的第一個元素的指針上。對于指針運算, 索引表達式的類型最好與指針所指向的類型一致(__far 指針除外,因為其指針所指向的類型和索引表達式的類型不同)。如果索引表達式的類型與指針所指向的類型不匹配,那么在把它與指針相加之前,必須將它強制轉換為正確的類型。
如果在應用中,堆棧空間資源(堆棧一般放在RAM中)比代碼尺寸資源(代碼一般放在ROM或者Flash中)更寶貴,則可以為索引變量選擇一個更小的類型來減少堆棧空間的使用,但這往往會犧牲代碼尺寸和執行時間(代碼尺寸變大,執行時間變慢)。不僅如此,這種轉換也會妨礙循環代碼的優化。
除上述問題外,我們也要關注循環條件,因為只有在進入循環之前可以計算出迭代次數的情況下,才可以進行循環優化。然而,這項計算工作非常復雜,并非用最終值減去初始值并除以增量那么簡單。例如,如果 i 是一個無符號字符,n 是一個整數,而 n 的值是 1000,那么會發生什么情況?答案是變量 i 在達到 1000 之前就會溢出。
雖然程序員肯定不想要一個無限循環,重復地將 256 個元素從 b 復制到 a,但是編譯器無法了解程序員的意圖。它必須假設最壞的情況,并且不能應用需要在進入循環之前提供行程數的優化。此外,如果最終值是一個變量,您還應該避免在循環條件中使用關系運算符 <= 和 >=。如果循環條件是 i <= n,那么 n 有可能是該類型中可表示的最高值,因此編譯器必須假定這是一個潛在的無限循環。
別名
通常,我們不建議使用全局變量。這是因為您可在程序的任何地方修改全局變量,并且程序會因全局變量的值而變化。這就會形成復雜的依賴關系,使人很難理解程序,也很難確定改變全局變量的值會對程序產生怎樣的影響。從優化器的角度來看,這種情況更糟糕,因為通過指針的存儲就可以改變任意全局變量的值。如果能通過多種方式訪問一個變量,這種情況就會被稱為別名,而別名使代碼更難優化。
char *buf
void clear_buf()
{
int i;
for (i = 0; i < 128; ++i)
{
buf[i] = 0;
}
}
盡管程序員知道向 buf 所指向的緩存區進行寫操作不會改變這個buf變量本身,但編譯器還是不得不做最壞的打算,在循環的每一次迭代中從內存中重新加載 buf。
如果將緩存區的地址作為參數傳遞,而不是使用全局變量,則可以消除別名:
void clear_buf(char *buf)
{
int i;
for (i = 0; i < 128; ++i)
{
buf[i] = 0;
}
}
使用這個解決方案后,指針 buf 就不會被通過指針的存儲影響。如此一來,指針 buf 在循環中就可以保持不變,其值只需在循環前加載一次即可,而不是在每次迭代時都要重新加載。
然而,如果需要在不共享調用者/被調用者關系的代碼段之間傳遞信息,則直接使用全局變量即可。但是,對于計算密集型任務,尤其是涉及指針操作時,最好使用自動變量。
盡量不用后增量和后減量
在下文中,關于后增量的所有內容也適用于后減量。C 語言中關于后增量語義的標準文本指出:“后綴 ++ 運算符的結果是操作數的值。在得到結果后,操作數的值會遞增”。雖然微控制器普遍擁有可在加載或存儲操作后增加指針的尋址模式,但其中只有很少能以同樣的效率處理其他類型的后增量。為符合標準,編譯器必須在執行增量之前將操作數復制到一個臨時變量。對于直線代碼來說,可以從表達式中取出增量,然后放在表達式之后。比如以下表達式:
foo = a[i++];
可以改為
foo = a[i];
i = i + 1;
但如果后增量屬于 while 循環中的條件,又會發生什么?由于在條件后面沒有可以插入增量的地方,因此必須在測試前添加增量。對于這些常見但是又與生成可執行代碼效率密切相關的設計,諸如IAR Systems的Embedded Workbench這樣的工具都在總結了大量實踐后提供了優化方案。
比如以下循環
i = 0;
while (a[i++] != 0)
{
...
}
應改為
loop:
temp = i; /* 保存操作數的值 */
i = temp + 1; /* 遞增操作數 */
if (a[temp] == 0) /* 使用保存的值 */
goto no_loop;
...
goto loop;
no_loop:
或
loop:
temp = a[i]; /* 使用操作數的值 */
i = i + 1; /* 遞增操作數 */
if (temp == 0)
goto no_loop;
...
goto loop;
no_loop:
如果循環后的 i 的值不相關,最好將增量放在循環內。比如以下幾乎相同的循環
i = 0;
while (a[i] != 0)
{
++i;
...
}
可以在沒有臨時變量的情況下執行:
loop:
if (a[i] == 0)
goto no_loop;
i = i + 1;
...
goto loop;
no_loop:
優化編譯器的開發者們很清楚后增量會使代碼編寫變得更復雜,盡管我們已盡力去識別這些模式,并盡量消除臨時變量,但總有一些情況使我們無法產生有效代碼,尤其是遇到比上述更復雜的循環條件時。通常,我們會將一個復雜的表達式分割成若干個更簡單的表達式,就像上面的循環條件被分割成一個測試和一個增量那樣。
在 C++ 環境中,選擇前增量還是后增量的重要性更高。這是因為 operator++ 和 operator-- 都可以以前綴和后綴的形式重載。將運算符作為類對象重載時,雖然沒必要模仿基本類型運算符的行為,但也應盡量接近。因此,對于那些可以直觀地對對象進行遞增和遞減的類,例如迭代器,通常會有前綴(operator++() 和 operator--())和后綴形式(operator++(int) 和 operator--(int))。
為了模擬基本類型的前綴 ++ 的行為,operator++() 可以修改對象并返回對修改后對象的引用。那么模擬基本類型的后綴 ++ 的行為會怎樣?您還記得嗎?“后綴 ++ 運算符的結果是操作數的值。在得到結果后,操作數的值會遞增”。就像上面的非直線代碼一樣,operator++(int) 的實現者必須復制原始對象,修改原始對象,并按值返回副本。由于存在復制操作,因此 operator++(int) 的開銷要高于 operator++()。
對于基本類型,如果忽略 i++ 的結果,優化器通常可以消除不必要的復制,但優化器不能將對一個重載運算符的調用變為另一個。如果您出于習慣編寫 i++ 而不是 ++i,您就會調用開銷更大的增量運算符。
雖然我們一直在反對使用后增量,但不得不承認,后增量在有些情況下還是有用的。如果確實要給一個變量進行后置增量操作,那就繼續吧。如果后增量操作和您期望的操作一致,可以使用后增量操作。但請注意,切勿為避免多寫一行代碼來遞增變量,而使用后增量操作。
每當您在循環條件、if 條件、switch 表達式、?:- 表達式或函數調用參數中添加不必要的后增量時,都會使編譯器不得不生成更大、更慢的代碼。這個清單是不是太長了,記不住?今天就開始培養好的習慣吧!在使用后增量操作前,先問問自己能不能把增量操作作為下一條語句。
結語
當然,軟件開發工作并不是只要求開發人員去“將就”編譯器,他們與編譯器之間的相互協同是快速而高效地完成編程工作的基礎之一。此外,從編譯器的發展過程來看,它們不僅要跟隨技術和語言的演進而迭代和創新,而且還要廣泛參考更多的開發習慣,那些歷史更悠久、使用更廣泛的編譯器可以為開發人員帶來更高的效率。
因此,在了解了如何編寫利于一款優秀編譯器優化的代碼之后,用戶們的工作效率就可以事半功倍。本文中提到的這些原理和tips,也是IAR Systems這樣的公司長時間總結的最優實踐,而且都可以在該公司的Embedded Workbench中進行驗證和探索,在其工具界面中可以查看代碼的執行時間和代碼尺寸,從而找到最佳解決方案。
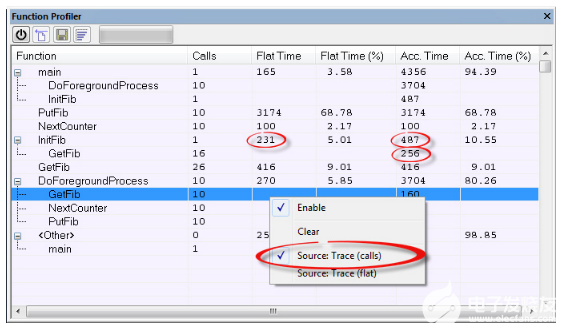

好的工具除了通用的代碼編譯優化,還支持高度靈活的自定義優化設置,如IAR Embedded Workbench包含針對運行效率和代碼體積的不同優化等級,對于不同的應用需求,還可以設置從整個工程,到每個源代碼文件,甚至是每個函數的優化等級,幫助工程師為自己的應用適配出最佳的優化方案。希望此篇文章對于開發人員更深度地了解程序優化有所幫助。
-
嵌入式系統
+關注
關注
41文章
3747瀏覽量
133619 -
編譯器
+關注
關注
1文章
1672瀏覽量
51592
發布評論請先 登錄
c語言中的代碼優化
單片機大神的程序優化流程
單片機開發功能安全中編譯器
性能突破 | SpacemiT-X60 在 LLVM 編譯器上實現 16% 顯著提升
開源鴻蒙技術大會2025丨編譯器與編程語言分論壇:語言驅動系統創新,編譯賦能生態繁榮

GCC編譯器,怎么才能實現c文件中未被調用的函數,不會被編譯呢?
進迭時空同構融合RISC-V AI CPU的Triton算子編譯器實踐

邊緣設備AI部署:編譯器如何實現輕量化與高性能?
兆松科技ZCC編譯器全面支持芯來科技NA系列處理器
RISC-V架構下的編譯器自動向量化



 工商網監
工商網監
評論