") HBM3首發(fā)GPU,又要進(jìn)軍自動駕駛
HBM3首發(fā)GPU,又要進(jìn)軍自動駕駛

人工智能的蓬勃發(fā)展促使產(chǎn)業(yè)對AI基礎(chǔ)設(shè)施提出了更高的性能要求,先進(jìn)計(jì)算處理單元,尤其是ASIC或GPU,為了在機(jī)器學(xué)習(xí)、HPC提供穩(wěn)定的算力表現(xiàn),傳統(tǒng)的內(nèi)存系統(tǒng)已經(jīng)不太能滿足日益增加的帶寬了。與此同時,在我們報(bào)道的不少AI芯片、HPC系統(tǒng)中,HBM或類似的高帶寬內(nèi)存越來越普遍,為數(shù)據(jù)密集型應(yīng)用提供了支持。
提及HBM,不少人都會想到成本高、良率低等缺陷,然而這并沒有影響業(yè)內(nèi)對HBM的青睞,諸如AMD的RadeonPro5600M、英偉達(dá)的A100等消費(fèi)級/企業(yè)級GPU,或是思科的路由ASIC芯片SiliconOneQ100、英特爾與AMD-Xilinx的FPGA,都用到了HBM內(nèi)存。就在今年1月底,JEDEC終于正式發(fā)布了HBM的第四代HBM3的標(biāo)準(zhǔn)。
HBM3性能未來可期
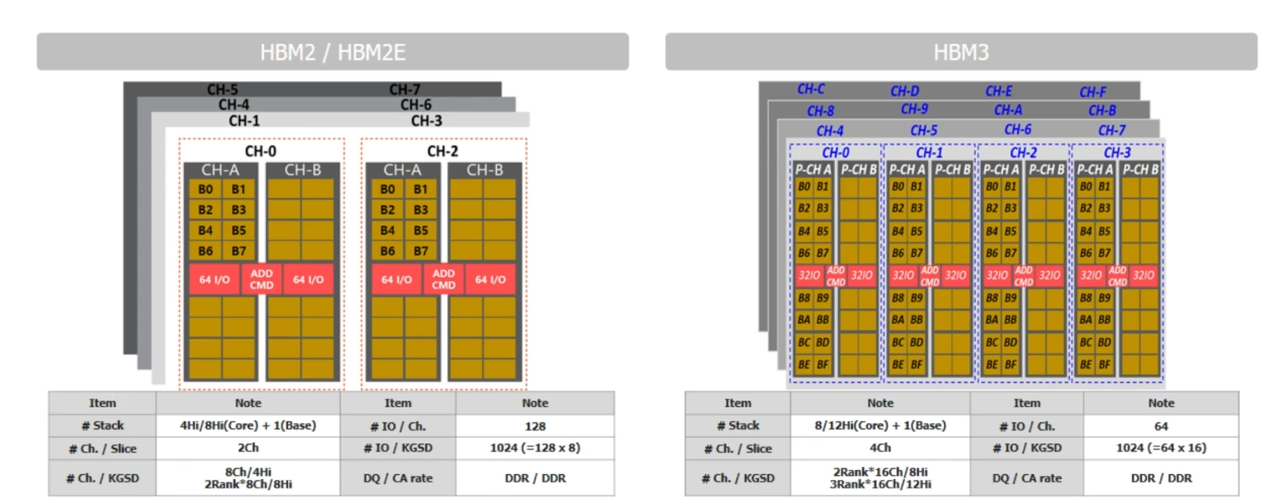
HBM2/2E與HBM3的架構(gòu)對比 / SK海力士
HBM3帶來的性能提升大家應(yīng)該都比較清楚了,傳輸速率是HBM2的兩倍,達(dá)到了6.4Gb/s,使得每個堆棧最高可達(dá)819GB/s的帶寬。可用的獨(dú)立通道也從HBM2的8個擴(kuò)充至16個,加上每個通道兩個偽通道的設(shè)計(jì),HBM3可以說支持到32通道了,提供更優(yōu)秀的時序來提升系統(tǒng)性能。
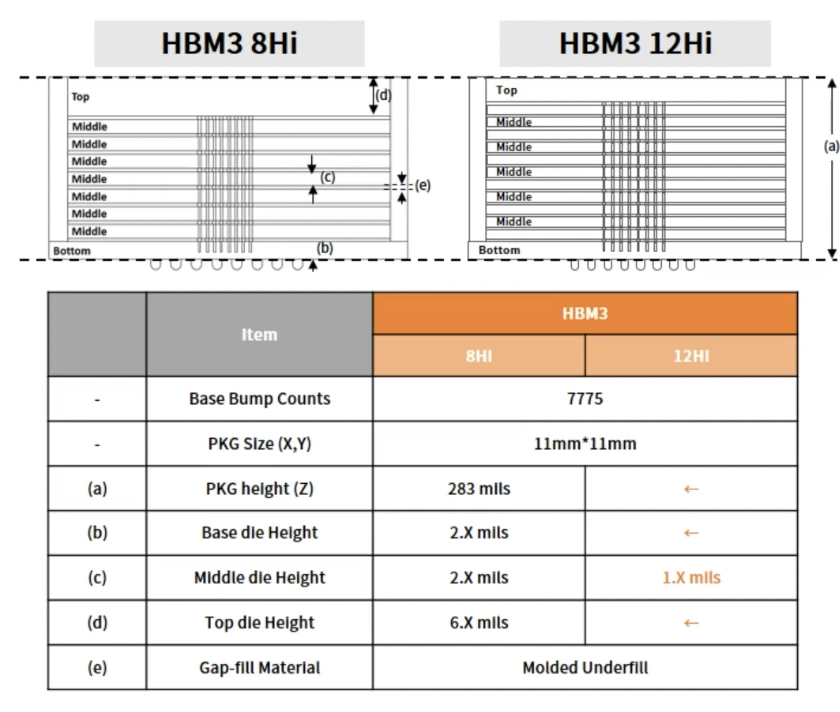
HBM3 8Hi和12Hi的機(jī)械結(jié)構(gòu)對比/ SK海力士
HBM3的TSV堆疊層數(shù)支持4-high、8-high和12-high,這倒是和HBM2e沒有什么差別。從SK海力士提供的機(jī)械結(jié)構(gòu)圖來看,無論是8Hi還是12Hi,其封裝大小和高度都是一樣的,只不過是減小了中間堆疊的裸片高度。這僅僅是第一代HBM3,未來HBM3會擴(kuò)展至16-high的TSV堆棧,單設(shè)備的內(nèi)存密度范圍也將達(dá)到4GB至64GB,不過第一代HBM3設(shè)備的話,目前用到的依然是16GB的內(nèi)存層。
此外,在散熱上,通過增加dummybump、增加HBM3裸片大小并降低間隙高度,HBM3成功將溫度降低了25%,實(shí)現(xiàn)了更好的散熱性能。在7位ADC的支持下,HBM3的溫度傳感器也能以1℃的分辨率輸出0到127℃的溫度信息。
首個用上HBM3的平臺
以在GTC22上亮相的H100 GPU為例,這是全球首個支持PCIe5.0并利用HBM3的GPU,其內(nèi)存容量達(dá)到了80GB。這個容量與上一代A100一致,但帶寬卻有了質(zhì)的飛躍,與采用HBM2的A100相比,H100的內(nèi)存帶寬提升了兩倍,達(dá)到了3TB/s。

英偉達(dá)各個系列GPU加速卡的內(nèi)存帶寬 / 英偉達(dá)
你可能會感到疑惑,既然HBM3可以提供每個堆棧16GB以上的內(nèi)存,從H100的芯片圖上看來有6個HBM3,為何只有80GB呢?是不是英偉達(dá)為了成本有所閹割?

H100 GPU / 英偉達(dá)
其實(shí)原因很簡單,6個HBM3的其中一個為DummyDie,所以真正可用的HBM3內(nèi)存只有5x16也就是80GB,所以英偉達(dá)在H100的白皮書也明確提到了這80GB是由5Stacks的HBM3內(nèi)存組成。如此做的原因很可能是出于良率的考量,畢竟我們已經(jīng)提到了HBM良率低的包袱,而且上一代80GB HBM2e的A100也是如此設(shè)計(jì)的。
HBM找到了新的市場
根據(jù)SK海力士給出的市場預(yù)期,HBM市場正在以40%的年復(fù)合增長率席卷HPC、AI和CPU等應(yīng)用,如今這其中還多出來一個特殊的應(yīng)用,那就是ADAS和自動駕駛。如今的自動駕駛芯片上幾乎看不到HBM的存在,即便是英偉達(dá)的JetsonAGX Orin,用的也只是256位的LPDDR5內(nèi)存,帶寬最高只有204.8GB/s。

HBM3內(nèi)存 / SK海力士
這種情況再正常不過了,誰叫如今的ADAS或自動駕駛方案還用不到HBM的大帶寬。花錢去設(shè)計(jì)HBM,還不如在芯片的計(jì)算性能上多下功夫。然而到了L4或L5的自動駕駛中,又是另外一幅光景了。低延遲和準(zhǔn)確的數(shù)據(jù)處理對于激光雷達(dá)、攝像頭等傳感器來說,可謂至關(guān)重要,這兩大自動駕駛等級下的帶寬至少也要1TB/s。
據(jù)研究機(jī)構(gòu)的預(yù)測,到了2030年,L4以上的自動駕駛系統(tǒng)將占據(jù)20%的市場,到了2035年,這一比例將上升至45%。為了不在突破L3時遇到帶寬的瓶頸,引入HBM可以說是越早越好,甚至從L3就可以開始考慮了,畢竟現(xiàn)在不少自動駕駛芯片已經(jīng)標(biāo)榜著L3乃至L4以上的能力。
比如L3級別的自動駕駛,帶寬要求在600GB/s到1TB/s之間,單車可以使用兩個HBM2e或者一個HBM3;而L4到L5級別的自動駕駛,帶寬要求在1TB/s到1.5TB之間,單車可用3個HBM2e或兩個HBM3。
結(jié)語
雖然HBM3標(biāo)準(zhǔn)已經(jīng)發(fā)布,芯片設(shè)計(jì)公司(英偉達(dá)、AMD、英特爾)、IP公司(新思、Cadence、Rambus)、晶圓代工廠的封裝技術(shù)(臺積電Cowos-S、三星H-Cube、英特爾EMIB)以及存儲廠商(三星、SK海力士)都開始了相關(guān)的部署,但HBM3的普及仍然需要時間。
預(yù)計(jì)2023年到2024年,我們可以見到第一代HBM3內(nèi)存在HPC上的普及,2025年到2026年第二代才會開始放量,屆時我們也能看到下一代HBM4的性能前瞻。至于HBM上自動駕駛芯片倒是不必急求,汽車產(chǎn)品的上市周期一向很長,從HBM3的推進(jìn)速度來看,估計(jì)L4和L5才能充分利用HBM3乃至HBM4的全部優(yōu)勢。
-
gpu
+關(guān)注
關(guān)注
28文章
5194瀏覽量
135503 -
AI
+關(guān)注
關(guān)注
91文章
39806瀏覽量
301479 -
HBM
+關(guān)注
關(guān)注
2文章
431瀏覽量
15836 -
HBM3
+關(guān)注
關(guān)注
0文章
75瀏覽量
485
發(fā)布評論請先 登錄
如何構(gòu)建適合自動駕駛的世界模型?

自動駕駛汽車如何實(shí)現(xiàn)自動駕駛
L3級自動駕駛在技術(shù)上有什么不一樣的要求?

汽車行業(yè)迎L3自動駕駛上路潮,華為、小鵬、理想搶跑#晶揚(yáng)電子 #自動駕駛 #L3級自動駕駛 #智能駕駛
自動駕駛汽車如何確定自己的位置和所在車道?
如何確保自動駕駛汽車感知的準(zhǔn)確性?

自動駕駛達(dá)到什么技術(shù)標(biāo)準(zhǔn)才能稱為L3級?

低速自動駕駛與乘用車自動駕駛在技術(shù)要求上有何不同?

自動駕駛汽車是如何準(zhǔn)確定位的?
卡車、礦車的自動駕駛和乘用車的自動駕駛在技術(shù)要求上有何不同?
Vicor高效電源模塊優(yōu)化自動駕駛系統(tǒng)

劉強(qiáng)東,進(jìn)軍汽車領(lǐng)域# 京東# 自動駕駛# 自動駕駛出租車# 京東自動駕駛快遞車
AI將如何改變自動駕駛?
自動駕駛經(jīng)歷了哪些技術(shù)拐點(diǎn)?




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論