") GPGPU市場增長強勁 創(chuàng)新性架構(gòu)大幅提升AI計算效率!
GPGPU市場增長強勁 創(chuàng)新性架構(gòu)大幅提升AI計算效率!

電子發(fā)燒友網(wǎng)報道(文/李彎彎)GPU中文叫圖形處理單元,是一種并行處理的硬件,早起只用來渲染復(fù)雜的計算機圖形環(huán)境。隨著技術(shù)進步,GPU不再局限于圖形領(lǐng)域,擴展應(yīng)用到其他計算密集的領(lǐng)域,被稱為GPGPU,成為AI 芯片領(lǐng)域的代表。
GPU具有很好的通用性,同時傳統(tǒng)的架構(gòu)也存在一定局限,比如計算密度低、效率低,如何在保證通用性的情況下,又提高它的計算效率成為業(yè)界關(guān)注的重點。
創(chuàng)新架構(gòu)提高AI計算效率
那么應(yīng)該如何做呢?為了提高GPU的計算效率,GPU知名企業(yè)英偉達(dá)也進行的相應(yīng)的嘗試,即對原來的GPU架構(gòu)進行修改,比如增加專門的張量計算單元、增加片上內(nèi)存器等,這一定程度可以提高AI的計算效率,不過受限于GPU整體架構(gòu),問題并沒有得到很好的解決。

圖:傳統(tǒng)GPU對AI加速的局限體現(xiàn)在哪些方面(圖片來自登臨科技分享)
成立于2017年的登臨科技,從2018年自主研發(fā)創(chuàng)新性的GPU+架構(gòu),一款由軟件定義的、片內(nèi)異構(gòu)的支持并行化計算的架構(gòu)。GPU+架構(gòu)針對AI應(yīng)用,具備和GPU一樣的可編程能力和通用性。同時通過架構(gòu)創(chuàng)新,提供更高的計算密度,更快的計算速度,同時大幅降低對外部帶寬的需求。而這些是傳統(tǒng)GPU芯片無法兼顧的。

由于GPU良好的通用性,在服務(wù)器及云端等使用場景中,會大規(guī)模應(yīng)用 GPU。運行各類神經(jīng)網(wǎng)絡(luò)。大量開源生態(tài)的應(yīng)用、大量客戶定制化的軟件,都是在主流的GPU軟件生態(tài)上完成。如何保持客戶已有的投入,即如何減少客戶的使用成本,也是AI技術(shù)產(chǎn)業(yè)化的重要課題。
怎么做呢?登臨科技在接受電子發(fā)燒友采訪的時候表示,登臨自主創(chuàng)新的GPU+架構(gòu),通過對高效的Tensor引擎和可編程的GPGPU引擎的有機配合,硬件直接兼容CUDA/OpenCL,可無縫接入現(xiàn)有軟件生態(tài),大大降低了客戶的遷移成本。
通過片內(nèi)異構(gòu),GPU+解決了傳統(tǒng)的系統(tǒng)級異構(gòu)計算調(diào)度,數(shù)據(jù)交換的開銷大,以及數(shù)據(jù)的連貫相干性的難題。在整個系統(tǒng)的計算密度極高的基礎(chǔ)上,通過軟件定義,使針對不同神經(jīng)網(wǎng)絡(luò)的應(yīng)用場景,都能達(dá)到硬件性能和能效最大化。
登臨科技表示,通過大規(guī)模客戶實測,在同等功耗下,GPU+的性能可以達(dá)到國際主流產(chǎn)品3倍以上的能效。
打造真正符合市場需求的產(chǎn)品
登臨科技成立以后,一直思考如何制定真正符合市場需求的技術(shù)路線,即上文所談的如何保持客戶已有的投入,減少客戶的使用成本,這是登臨科技制定產(chǎn)品的價值導(dǎo)向。
2018年登臨確定了產(chǎn)品的方向:基于GPGPU的高能效計算,并自主研發(fā)創(chuàng)新的GPU+架構(gòu)。經(jīng)過團隊一年多的工作,于2019年6月,公司完成了首款基于GPU+架構(gòu)的Goldwasser設(shè)計,并mpw流片成功。
2020年6月Goldwasser成功回片通過測試,開始客戶送樣,Goldwasser目前已在成熟的12nm/14nm工藝上實現(xiàn)量產(chǎn)。登臨Goldwasser已于2021年在智慧城市、互聯(lián)網(wǎng)等領(lǐng)域順利實現(xiàn)了商業(yè)化落地,并同時與數(shù)十家客戶在邊緣至云端的不同應(yīng)用場景中進行產(chǎn)品開發(fā)、測試。
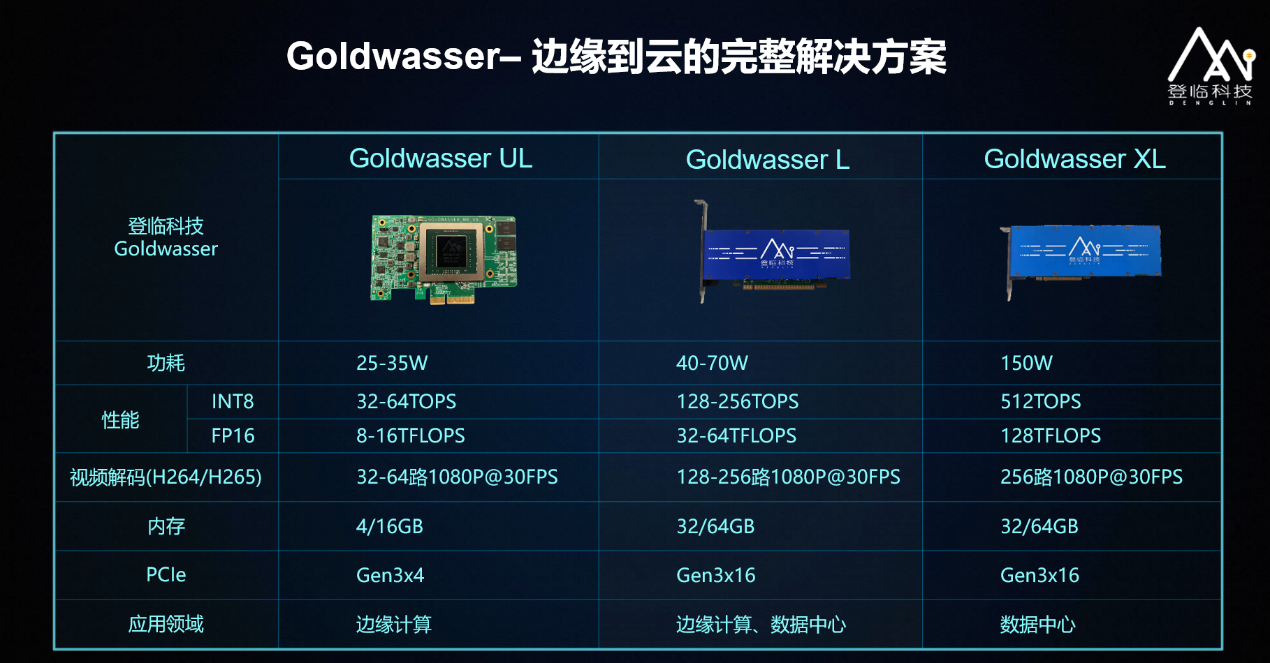
登臨科技的Goldwasser 系列產(chǎn)品包括:邊緣計算產(chǎn)品 Goldwasser UL,功率 25-35W,INT8 算力 32-64TOPS;半高半長的服務(wù)器計算卡 Goldwasser L,功耗 40-70W,提供 128-256TOPS 算力;另有一種全高全長的 Goldwasser XL,輸出 512TOPS 算力。多種規(guī)格的產(chǎn)品,使得客戶可以根據(jù)自身需求分別部署在邊緣側(cè)、云端的各種計算設(shè)備中。
登臨科技方案架構(gòu)總監(jiān)鄭韜此前在某論壇上也介紹過,Goldwasser覆蓋主流系統(tǒng)生態(tài),登臨Hamming軟件開發(fā)包支持主流GPU編程語言,包括CUDA、OpenCL等;適配國內(nèi)外主流服務(wù)器廠家;支持主流國內(nèi)外AI計算框架,包括PyTorch、百度飛漿、TensorFlow等;適配國內(nèi)外主流CPU廠家,包括飛騰、龍芯、英特爾、AMD等。
在不同的應(yīng)用場景下,Goldwasser可以支持多種不同的算法實現(xiàn)和落地,如智慧城市、智能交通、語音識別、虛擬客服、智慧工地、智慧車站、機器翻譯、工業(yè)視覺等,場景覆蓋CV、NLP、知識圖譜、信號處理和計算等多個領(lǐng)域。Goldwasser可以同時支持訓(xùn)練和推理。
登臨科技表示,目前Goldwasser正與30多家不同行業(yè)的頭部企業(yè)進行量產(chǎn)導(dǎo)入。同時,登臨科技打通供應(yīng)鏈上下游相關(guān)企業(yè)和合作伙伴,確保產(chǎn)品正常交付。
小結(jié)
當(dāng)前AI技術(shù)正快速發(fā)展,GPGPU呈現(xiàn)出強勁的增長勢頭,根據(jù)有關(guān)數(shù)據(jù)預(yù)測,到2025年,我國GPGPU芯片板卡的市場規(guī)模將達(dá)458億元,年復(fù)合增長率高達(dá)32%,未來市場可觀。
目前國際巨頭占據(jù)大部分市場,與之相比國內(nèi)廠商還存在差距,不過近幾年不少國內(nèi)GPU廠商通過自主創(chuàng)新,在技術(shù)上逐漸取得進展,產(chǎn)品也逐步走向落地商用,比如登臨科技。
另外,對于政府目前重點關(guān)注的降碳增效,登臨科技表示,對計算芯片而言關(guān)鍵指標(biāo)是能效比,而這也是公司產(chǎn)品的最重要的優(yōu)勢之一,登臨將繼續(xù)通過對傳統(tǒng)GPU的架構(gòu)創(chuàng)新,不斷提升異構(gòu)硬件的算力,達(dá)到非常顯著的能效比優(yōu)勢,為降碳和增效做貢獻。
發(fā)布評論請先 登錄
Altair CFD 以技術(shù)賦能工程創(chuàng)新?
Imagination:邊緣AI是半導(dǎo)體市場重要增長引擎,E-Series 架構(gòu)恰逢其時




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論