 探究SMT對計算密集型workload的效果
探究SMT對計算密集型workload的效果

宋老師的SMT測試很有意思,但是編譯內核涉及的因素太多了,包括訪問文件系統等耗時受到存儲器性能的影響,難以估算,因此很難評判SMT對性能的提升如何。
為了探究SMT對計算密集型workload的效果,我自己寫了一個簡單的測試程序。
使用pthread開多個線程,每個線程分別計算斐波那契數列第N號元素的值。每個線程計算斐波那契數列時除線程的元數據外只分配兩個unsigned long變量,由此避免過高的內存開銷。
workload的詳細代碼和測試腳本在[https://github.com/HongweiQin/smt_test]
毫無疑問,這是一個計算密集型負載,我在自己的筆記本上運行,配置如下(省略了一些不重要的項目):
lscpuArchitecture: x86_64: 12CPU(s) list: 0-11per core: 2per socket: 6: 1NUMA node(s): 1Vendor ID: GenuineIntelModel name: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHzL1d cache: 192 KiBL1i cache: 192 KiBL2 cache: 1.5 MiBL3 cache: 12 MiB
可以看到筆記本有一個Intel i7的處理器,6核12線程。經查,CPU0和CPU6共用一個Core,CPU1和CPU7共用一個Core,以此類推。
以下的測試(Test 1-5)中,每個線程分別計算斐波那契數列第40億號元素的數值。
Test1:采用默認配置,開12線程進行測試。測試結果為總耗時45.003s。
qhw@qhw-laptop:~/develop/smt_test$ time ./smt_test -f 4000000000threads_num=12, fibonacci_max=4000000000, should_set_affinity=0, should_inline=1, alloc_granularity=32real0m45.003suser7m12.953ssys0m0.485s
Test2:把smt關掉,同樣的測試方法(12線程)。總耗時為25.733s。
qhw@qhw-laptop:~/develop/smt_test$ cat turnoff_smt.shecho "turn off smt"sudo sh -c 'echo off > /sys/devices/system/cpu/smt/control'qhw@qhw-laptop:~/develop/smt_test$ ./turnoff_smt.shturn off smtqhw@qhw-laptop:~/develop/smt_test$ time ./smt_test -f 4000000000threads_num=12, fibonacci_max=4000000000, should_set_affinity=0, should_inline=1, alloc_granularity=32real0m25.733suser2m23.525ssys0m0.116s
對,你沒看錯。同樣的workload,如果關掉smt,總耗時還變少了。Intel誠不欺我!
Test3:再次允許smt,但是將程序限制在三個物理Core上運行,則總耗時為34.896s。
qhw@qhw-laptop:~/develop/smt_test$ ./turnon_smt.shturn on smtqhw@qhw-laptop:~/develop/smt_test$ time taskset -c 0-2,6-8 ./smt_test -f 4000000000threads_num=12, fibonacci_max=4000000000, should_set_affinity=0, should_inline=1, alloc_granularity=32real0m34.896suser3m17.033ssys0m0.028s
Test3相比于Test1用了更少的Core,反而更快了。
為什么在Test2和3會出現這樣違反直覺的結果?
猜想:Cache一致性在作怪!
圖1
測試程序的main函數會分配一個含有T(T=nr_threads)個元素的`struct thread_info`類型的數組,并分別將每個元素作為參數傳遞給每個計算線程使用。`struct thread_info`定義如下:
struct thread_info {pthread_t thread_id;int thread_num;unsigned long res[2];};
結構體中的res數組用于計算斐波那契數列,因此會被工作線程頻繁地寫。
注意到,sizeof(struct thread_info)為32,而我的CPU的cacheline大小為64B!這意味著什么?
如果Thread 0在Core 0上運行,則它會頻繁寫tinfo[0],Thread 1在Core 1上運行,則它會頻繁寫tinfo[1]。
這意味著,當Thread 0寫tinfo[0]時,它其實是寫入了Core 0上L1 Cache的Cacheline。同樣的,當Thread 1寫tinfo[1]時,它其實是寫入了Core 1上L1 Cache的Cacheline。此時,由于Core 1上的Cacheline并非最新,因此CPU需要首先將Core 0中的Cacheline寫入多核共享的L3 Cache甚至是內存中,然后再將其讀入Core 1的L1 Cache中,最后再將Thread 1的數據寫入。此時,由于Cache 0中的數據并非最新,Cacheline會被無效化。由此可見,如果程序一直這樣運行下去,這一組數據需要在Cache 0和1之間反復跳躍,占用較多時間。
這個猜想同樣可以解釋為什么使用較少的CPU可以加速程序運行。原因是當使用較少的CPU時,多線程不得不分時共用CPU,如果Thread 0和Thread 1分時共用了同一個CPU,則不需要頻繁將Cache無效化,程序運行時間也就縮短了。
驗證猜想:增加內存分配粒度!
對程序進行修改后,可以使用`-g alloc_granularity`參數設定tinfo結構體的分配粒度。使用4KB為粒度進行分配,再次進行測試:
Test4:12線程,開啟SMT,分配粒度為4096。總耗時為13.193s,性能相比于Test1的45.003s有了質的提升!
qhw@qhw-laptop:~/develop/smt_test$ time ./smt_test -f 4000000000 -g 4096threads_num=12, fibonacci_max=4000000000, should_set_affinity=0, should_inline=1, alloc_granularity=4096real0m13.193suser2m31.091ssys0m0.217s
Test5:在Test4的基礎上限制只能使用3個物理Core。總耗時為24.841s,基本上是Test4的兩倍。這說明在這個測試下,多核性能還是線性可擴展的。
qhw@qhw-laptop:~/develop/smt_test$ time taskset -c 0-2,6-8 ./smt_test -f 4000000000 -g 4096threads_num=12, fibonacci_max=4000000000, should_set_affinity=0, should_inline=1, alloc_granularity=4096real0m24.841suser2m26.253ssys0m0.032s
超線程SMT究竟可以快多少?
表格和結論:
| 測試名 | 硬件配置 | 運行時間(s) |
| Test6 | “真”6核 | 38.562 |
| Test7 | “假”6核 | 58.843 |
| Test8 | “真”3核 | 73.175 |
測試使用的是6個工作線程。為了減少誤差,增加一點運行時間,每個線程計算斐波那契數列第200億項的值。
對比Test6和7,可以看到SMT的提升大概在52.6%左右。
測試記錄:
Test6:別名“真”6核,使用6個關閉了SMT的物理核進行計算。總耗時為38.562s。
Test7:別名“假”6核,使用3個開啟了SMT的物理核進行計算。總耗時為58.843s。
Test8:別名“真”3核,使用3個關閉了SMT的物理核進行計算。總耗時為1m13.175s。
qhw@qhw-laptop:~/develop/smt_test$ cat test.shfibonacci=20000000000sudo printf ""./turnoff_smt.shtime ./smt_test -f $fibonacci -g 4096 -t 6./turnon_smt.shtime taskset -c 0-2,6-8 ./smt_test -f $fibonacci -g 4096 -t 6./turnoff_smt.shtime taskset -c 0-2,6-8 ./smt_test -f $fibonacci -g 4096 -t 6./turnon_smt.shqhw@qhw-laptop:~/develop/smt_test$ ./test.shturn off smtthreads_num=6, fibonacci_max=20000000000, should_set_affinity=0, should_inline=1, alloc_granularity=4096real0m38.562suser3m50.786ssys0m0.000sturn on smtthreads_num=6, fibonacci_max=20000000000, should_set_affinity=0, should_inline=1, alloc_granularity=4096real0m58.843suser5m53.018ssys0m0.005sturn off smtthreads_num=6, fibonacci_max=20000000000, should_set_affinity=0, should_inline=1, alloc_granularity=4096real1m13.175suser3m39.486ssys0m0.008sturn on smt
責任編輯:haq
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
smt
+關注
關注
45文章
3188瀏覽量
76289 -
多線程
+關注
關注
0文章
279瀏覽量
21027
原文標題:超線程SMT究竟可以快多少?(斐波那契版)
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
熱點推薦
意法半導體與亞馬遜云計算服務深化戰略合作
的先進半導體技術與產品戰略供應商,助力AWS為客戶提供新一代高性能計算實例、降低運營成本,并更高效地擴展計算密集型工作負載。
物聯網和邊緣計算助力實現智慧農業可持續發展
傳統農業依賴代代相傳的經驗,而現代農業正在經歷一場深刻的變革——“靠數據種地”,將農業從“勞動密集型”升級為“智能決策型”。通過實時感知土壤水分、作物營養狀況和病蟲害跡象,在最恰當的時機進行精準干預,不僅關乎產量提升,更可實現可持續發展——用最少的水、肥、農藥,獲得最優質
Altera全新推出MAX 10 FPGA封裝新選擇
Altera 全新推出 MAX 10 FPGA 封裝新選擇,采用可變間距球柵陣列 (VPBGA) 技術并已開始批量出貨,可為空間受限及 I/O 密集型應用的設計人員帶來關鍵技術優勢。

英飛凌推出專為高功率與計算密集型應用而設計的400V和440V MOSFET
。新的CoolSiC? MOSFET具有更優的熱性能、系統效率和功率密度。其專為滿足高功率與計算密集型應用需求而設計,涵蓋了AI服務器電源、光伏逆變器、不
【產品介紹】Altair HPCWorks高性能計算管理平臺(HPC平臺)
AltairHPCWorksAltair高性能計算平臺最大限度地利用復雜的計算資源,并簡化計算密集型任務的工作流程管理,包括人工智能、建模和仿真,以及可視化應用。強大的

I/O密集型任務開發指導
使用異步并發可以解決單次I/O任務阻塞的問題,但是如果遇到I/O密集型任務,同樣會阻塞線程中其它任務的執行,這時需要使用多線程并發能力來進行解決。
I/O密集型任務的性能重點通常不在于CPU的處理
發表于 06-19 07:19
CPU密集型任務開發指導
CPU密集型任務是指需要占用系統資源處理大量計算能力的任務,需要長時間運行,這段時間會阻塞線程其它事件的處理,不適宜放在主線程進行。例如圖像處理、視頻編碼、數據分析等。
基于多線程并發機制處理CPU
發表于 06-19 06:05
半導體芯片制造Fab工廠布局和結構簡介-江蘇泊蘇系統集成有限公司
在半導體產業的核心地帶,芯片制造工廠以其高度自動化、超凈環境和復雜的工藝流程聞名。這些工廠不僅是技術密集型的象征,更是精密工程與空間設計的典范。
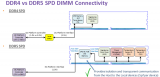
上海貝嶺推出全新DDR5 SPD芯片BL5118
隨著計算密集型任務的日益增長,DDR4內存的性能瓶頸已逐步顯現。DDR5的出現雖解燃眉之急,但真正推動內存發揮極致性能的背后“功臣”——正是 DDR5 SPD(Serial Presence Detect)芯片。
借助NVIDIA技術實現機器人裝配和接觸密集型操作
本期 NVIDIA 機器人研究與開發摘要 (R2D2) 將探討 NVIDIA 研究中心針對機器人裝配任務的多種接觸密集型操作工作流,以及它們如何解決傳統固定自動化在魯棒性、適應性和可擴展性等方面的關鍵挑戰。

InspireSemi借助Cadence解決方案為下一代AI鋪路
InspireSemi 致力于為 HPC、AI、圖形分析和其他計算密集型應用開發和提供卓越的加速計算解決方案。InspireSemi 致力于打造開放、多功能的架構,具有極快的速度、節能、開發人員友好的全 CPU 編程模型和改變游
表面貼裝技術(SMT):推動電子制造的變革
的廣泛應用,特別是在計算機和通信類電子產品中,已經成為行業標準。隨著技術的不斷進步,SMD器件的產量逐年上升,而傳統插裝元件的產量則逐年下降。這一趨勢表明,隨著時間的推移,SMT技術將越來越普及,成為
發表于 03-25 20:55
SMT技術的核心優勢與行業影響
在當今電子制造領域,表面貼裝技術(SMT)已成為實現電子產品小型化、高性能化和高可靠性的關鍵工藝。SMT技術通過將傳統電子元器件壓縮成體積更小的貼片元件,實現了電子產品組裝的高密度、小型化和輕量化
發表于 03-25 20:27
告別性能瓶頸:使用 Google Coral TPU 為樹莓派注入強大AI計算力!
使用機器學習的應用程序通常需要高計算能力。這些計算通常發生在顯卡的GPU上。RaspberryPi并不專門設計用于運行計算密集型應用程序。但GoogleCoralUSB加速器能在此提供

請問如何在Python中實現多線程與多進程的協作?
大家好!我最近在開發一個Python項目時,需要同時處理多個任務,且每個任務需要不同的計算資源。我想通過多線程和多進程的組合來實現并發,但遇到了一些問題。
具體來說,我有兩個任務,一個是I/O密集型
發表于 03-11 06:57



 工商網監
工商網監
評論