 借助深度學習算法實現5秒內克隆你的聲音
借助深度學習算法實現5秒內克隆你的聲音

大家應該都知道聲音克隆技術,通俗的來說就是借助深度學習算法,可以完全模擬某個人的聲音,而且由機器合成的語音連情緒都能夠完美表達出來,基本可以以假亂真,只要不見面,你根本就察覺不出來向你發出聲音的知識一個機器。
語音克隆最大的創新之一是減少創建語音所需的原始數據量。過去,該系統需要數十甚至數百小時的音頻。但是,今天猿妹要和大家分享的這個工具5秒鐘就可以克隆成功,這個工具名叫——MockingBird。
MockingBird已經登上Github熱榜,收獲3.5K的Star,累計分支 303(Github地址:https://github.com/babysor/MockingBird)
MockingBird具有如下特性:
支持普通話并使用多種中文數據集進行測試
適用于 pytorch,已在 1.9.0 版本(最新于 2021 年 8 月)中測試,GPU Tesla T4 和 GTX 2060
支持 Windows + Linux
僅使用新訓練的合成器(synthesizer)就有良好效果,復用預訓練的編碼器/聲碼器
MockingBird如何使用
MockingBird的安裝要求如下:
首先,MockingBird需要Python 3.7 或更高版本
安裝 PyTorch
安裝 ffmpeg。
運行pip install -r requirements.txt 來安裝剩余的必要包。
安裝 webrtcvad 用 pip install webrtcvad-wheels。
接著,你需要使用數據集訓練合成器:
下載 數據集并解壓:確保您可以訪問 train 文件夾中的所有音頻文件(如.wav)
使用音頻和梅爾頻譜圖進行預處理:python synthesizer_preprocess_audio.py 《datasets_root》 可以傳入參數 --dataset {dataset} 支持 adatatang_200zh, magicdata, aishell3
預處理嵌入:python synthesizer_preprocess_embeds.py 《datasets_root》/SV2TTS/synthesizer
訓練合成器:python synthesizer_train.py mandarin 《datasets_root》/SV2TTS/synthesizer
當你在訓練文件夾 synthesizer/saved_models/ 中看到注意線顯示和損失滿足您的需要時,請轉到下一步。
使用預先訓練好的合成器,如果沒有設備或者不想慢慢調試,可以使用網友貢獻的模型。
訓練聲碼器
預處理數據: python vocoder_preprocess.py 《datasets_root》
訓練聲碼器: python vocoder_train.py mandarin 《datasets_root》
啟動工具箱
然后你可以嘗試使用工具箱:python demo_toolbox.py -d 《datasets_root》
責任編輯:haq
-
開源
+關注
關注
3文章
4204瀏覽量
46130 -
克隆
+關注
關注
0文章
22瀏覽量
8036 -
深度學習
+關注
關注
73文章
5598瀏覽量
124396
原文標題:5秒內克隆你的聲音,并生成任何內容,這個工具細思極恐...還特么的開源~
文章出處:【微信號:AndroidPush,微信公眾號:Android編程精選】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
歡迎使用中國香河英茂科工豆包智能體
穿孔機頂頭檢測儀 機器視覺深度學習
【團購】獨家全套珍藏!龍哥LabVIEW視覺深度學習實戰課(11大系列課程,共5000+分鐘)
【團購】獨家全套珍藏!龍哥LabVIEW視覺深度學習實戰課程(11大系列課程,共5000+分鐘)
如何深度學習機器視覺的應用場景
利用 Banana Pi BPI-CM5 Pro(ARMSoM CM5 SoM) 加速保護科學
重大更新,LVGL有UI編輯器用了,2秒內加載,快到飛起!
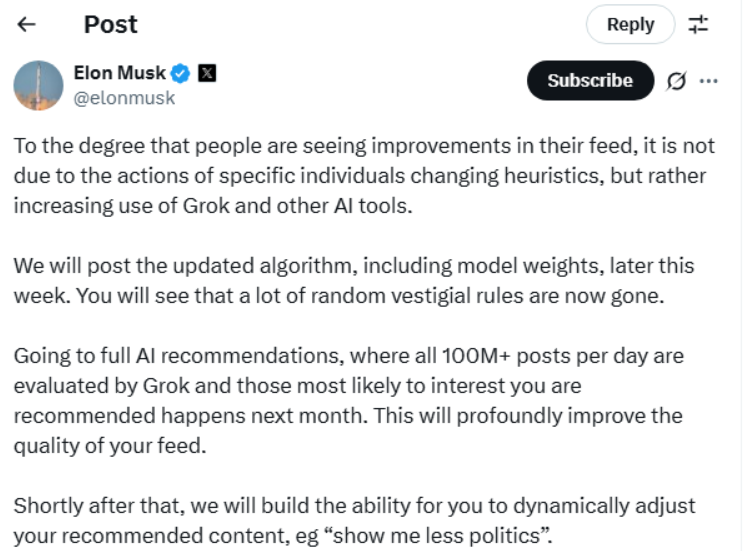
信息流全面轉向AI推薦!馬斯克稱X本周內將發布AI算法更新



 工商網監
工商網監
評論