 由JVM的鎖機制導致的CPU占用率高問題
由JVM的鎖機制導致的CPU占用率高問題

編者按:筆者在 AArch64 中遇到一個 G1 GC 掛起,CPU 利用率高達 300%的案例。經過分析發現問題是由 JVM 的鎖機制導致,該問題根因是并發編程中沒有正確理解內存序導致。本文著重介紹 JVM 中 Monitor 的基本原理,同時演示了在什么情況下會觸發該問題。希望通過本文的分析,讀者能夠了解到內存序對性能、正確性的影響,在并發編程時更加仔細。
現象
本案例是一個典型的弱內存模型案例,大致的現象就是 AArch64 平臺上,業務掛死,而進程占用 CPU 持續維持在 300%。配合 top 和 gdb,可以看到是 3 個 GC 線程在 offer_termination 處陷入了死循環:

多個并行 GC 線程在 Minor GC 結束時調用 offer_termination,在 offer_termination 中自旋等待其他并行 GC 線程到達該位置,才說明 GC 任務完成,可以終止。(關于并行任務的中止協議問題,可以參考相關論文,這里不做著重介紹。
簡單地說,在并行任務執行時,多個任務之間可能存在任務不均衡,所以 JVM 內部設計了任務均衡機制,同時必須設計任務終止的機制來保證多個任務都能完成,這里的 offer_termination 就是嘗試終止任務)。
在該案例中,部分 GC 線程完成自己的任務,等待其他的 GC 線程。此時出現掛起,很有可能是因為發生了死鎖。所以問題很可能是由于那些尚未完成任務的 GC 線程上錯誤地使用鎖。所以使用 gdb 觀察了一下其他 GC 線程,發現其他 GC 線程全都阻塞在一把 JVM 的鎖上:
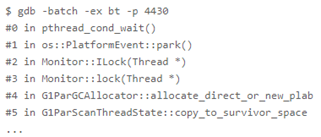
而這把 Monitor 中的情況如下:
cxq 上積累了大量 GC 線程
OnDeck 記錄的 GC 線程已經消失
_owner 記錄的鎖持有者為 NULL
分析
在進一步分析前,首先普及一下 JVM 鎖組件 Monitor 的基本原理,Monitor 類主要包含 4 個核心字段:
“Thread * volatile _owner” 字段指向這把鎖的持有線程
“SplitWord_LockWord” 字段被設計為 1 個機器字長,目的是為了確保操作時天然的原子性,它的最低位被設計為上鎖標記位,而高位區域用來存放 256 字節對齊的競爭隊列(cxq)地址
“ParkEvent * volatile_EntryList” 字段指向一個等待隊列,跟 cxq 差別不大,個人理解只是為了緩解 cxq 的競爭壓力而設計
“ParkEvent * volatile_OnDeck” 字段指向這把鎖的法定繼承人,同時最低位還充當了內部鎖的角色
接下來通過一組流程圖來介紹加解鎖的具體流程:
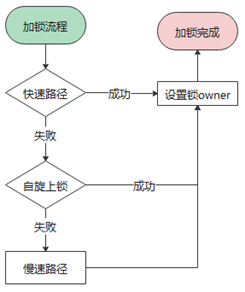
上圖是加鎖的一個整體流程,大致分為 3 步:
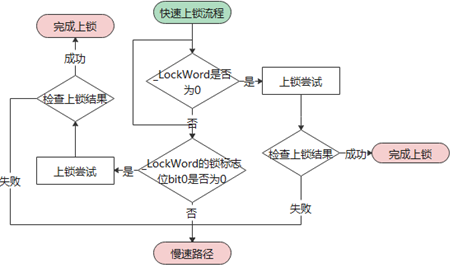
首先走快速上鎖流程,主要對應鎖本身無人持有的最理想情況
接著是自旋上鎖流程,這是預期將在短時間內獲取鎖的情況
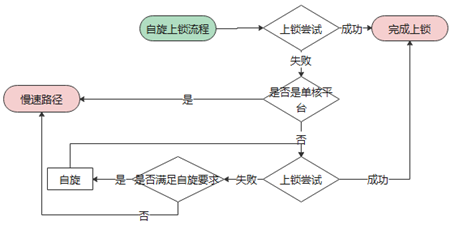
最后是慢速上鎖流程,申請者將會加入等待隊列(cxq),然后進入睡眠,直到被喚醒后發現自己變成了法定繼承者,于是進入自旋,直到完成上鎖。
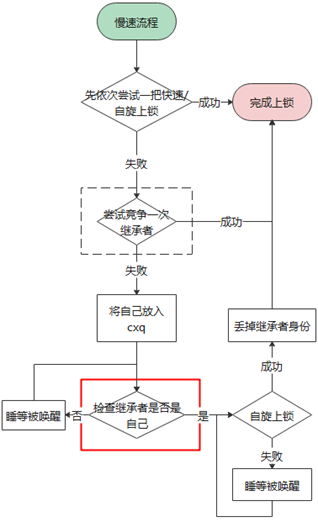
而且,基于性能考慮,整個上鎖流程中的每一步幾乎都做了“插隊”的嘗試:
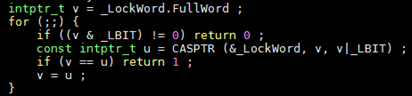
如上圖代碼中所示,“插隊”的意思就是不經過排隊(cxq),直接嘗試置上鎖標志位。
上圖就是整個解鎖流程了,顯然真正的解鎖操作在第二步中就已經完成了(意味著接下來時刻有“插隊”現象發生),剩下的主要就是選出繼承者的過程,大致分為以下幾步:
解鎖線程首先需要將內部鎖(_OnDeck)標記上鎖
從競爭隊列(cxq)抽取所有等待者放入等待隊列(_EntryList)
_ EntryList 取出頭一個元素,寫入_OnDeck 的同時解除內部鎖標記,這代表選出了繼承者
喚醒繼承者
當然伴隨著整個解鎖流程每一步的,還有對“插隊”行為的處理。
至此,JVM 鎖組件 Monitor 的原理就介紹到這里,再回歸到問題本身,一個疑問就是_OnDeck 上記錄的繼承者為何消失?作為繼承者,既然已經消失在競爭隊列和等待隊列里,顯然意味著它大概率已經持有鎖、然后解鎖走人了,所以問題很可能跟繼承者選取過程有關。基于這種猜測,我們對相關代碼著重進行了梳理,就發現了下圖兩處紅框標記位置存在疑點,那就是在選繼承者過程第 3 步中:
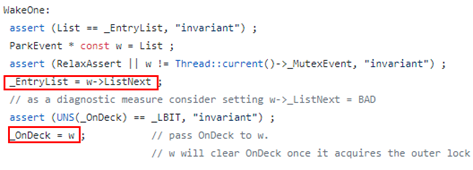
寫EntryList 和寫_OnDeck 之間沒有 barrier 來保證執行順序,這可能出現_OnDeck 先于EntryList 寫入的情況,一旦繼承人提前持有鎖,后果就可能非常糟糕…
這里貼了一張可能的問題場景:
線程 A 處于解鎖流程中,由于亂序,先寫入了繼承者同時解除內部鎖
線程 B 處于上鎖流程,發現自己就是法定繼承者后,立刻完成上鎖
線程 B 又迅速進入解鎖流程,并從_EntryList 中取出頭元素(也就是線程 B!)作為繼承者寫入_OnDeck,完成解鎖走人
線程 A 此時才更新_EntryList,然后喚醒繼承者(也就是線程 B!),完成解鎖走人
_OnDeck 上的繼承者線程 B,實際已經完成加解鎖離開,后續等待線程再也無法被喚醒。
正巧在社區的高版本上找到了一個相關的修復記錄(JDK- 8166197),這里貼出 2 個關鍵的代碼片段:

上面這段代碼位于慢速上鎖流程,被喚醒后檢查繼承者是否是自己,修復后的代碼在讀_OnDeck 時加了 Load-Acquire 的 barrier。
上面這段代碼位于解鎖時選繼承者流程,從_ EntryList 取出頭一個元素,寫入_OnDeck 的同時解除內部鎖標記,修復后的代碼在寫_OnDeck 時加了 Store-Release 的 barrier。
顯然,圍繞_OnDeck 添加的這對 One-way barrier 可以確保:當繼承者線程被喚醒時,該線程可以“看”到_EntryList 已經被及時更新。
總結:
在 AArch64 這種弱內存模型的平臺上(關于內存序更多的知識在接下來的分享中會詳細介紹),一旦涉及多線程對公共內存的每一次訪問,必須反復確認是否需要通過 barrier 來嚴格保序,而且除非存在有效的依賴關系,否則 barrier 需要在讀寫端成對使用。
-
cpu
+關注
關注
68文章
11277瀏覽量
224954 -
JVM
+關注
關注
0文章
161瀏覽量
13036
原文標題:JVM 鎖 bug 導致 G1 GC 掛起問題分析和解決
文章出處:【微信號:openEulercommunity,微信公眾號:openEuler】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
面試必看!排隊自旋鎖32位變量的域劃分與核心作用

Linux性能分析實戰:用trace揪出卡頓、高CPU的“真兇”
基于米爾RK3576的環視實時性方案解析
RDMA設計2:開發必要性之性能簡介
NVMe高速傳輸之擺脫XDMA設計45:上板資源占用率分析
構建高可靠網絡:硬件BFD的關鍵作用

Arm Neoverse CPU上大代碼量Java應用的性能測試

RK3576機器人核心:三屏異顯+八路攝像頭,重塑機器人交互與感知
蜂鳥E203內核優化方法
rt-thread studio 如何進行多線程編譯?
深入剖析RabbitMQ高可用架構設計
當IM設備顯示“過載導致界面無法加載”時,該如何處理?
IM 系列設備過載保護機制下界面初始化中斷的底層邏輯與解決方案
HarmonyOS優化應用內存占用問題性能優化一
PCIe-8624千兆網卡:工業級多設備協同場景設計的PoE網卡




 工商網監
工商網監
評論