 如何解決像亂序執行又像內存屏障的BUG
如何解決像亂序執行又像內存屏障的BUG

后發先至:另外一位讀者則給出了一個更奇怪的現象,兩個變量中后執行的代碼看起來卻先被調用了。
加個if問題竟然解了:最后一個反饋留言最令人崩潰,在代碼中隨便加上個判斷語句,不但解決了y=0的問題,性能還非常好。
1難道這就是傳說中的亂序執行?
先來看以下讀者回復的代碼:
package main import (“fmt”“sync/atomic”“time”) func main() {var x int32var y int32 go func() {for { x = atomic.AddInt32(&x, 1) y = atomic.AddInt32(&y, 1) } }() time.Sleep(time.Second) fmt.Println(“x=”, x) fmt.Println(“y=”, y)}
在這部分內容中,兩個變量x和y都是由原子操作Automic.Add來保證并發安全的,但是結果輸出出來我們可以發現y竟然比x還大?而且每次運行的情況基本都是y更大,只是大多少有所區別。
x= 49418397y= 49425282成功: 進程退出代碼 0.
看到這個輸出結果,我第一反應感覺這是亂序執行的衍生現象,因為x和y的加1操作彼此是獨立的,雖然編譯器不會優化執行順序,但是在CPU的執行層面有可能會對于前后無依賴的操作打亂順序執行。這樣一來就的確有可能出現后面的操作先執行的情況。
但是仔細一想這樣的說法應該并不合理,如果是亂序執行的原因,那么上面這段代碼的執行結果肯定不會每次結果都是y更大一些,每次執行都是y比x更大只能說明代碼是按照一定順序執行的,而且目前的CPU指令流水線的預測功能肯定還沒有牛到能夠完全知曉x與y的值不按照順序提交是沒有作何影響的地步。
2仔細一看還是多并發競爭問題
再來看以下代碼,
package main import (“fmt”“sync/atomic”“time”) func main() {var x int32var y int32 go func() {for { x = atomic.AddInt32(&x, 1) y = atomic.AddInt32(&y, 1) } }() time.Sleep(time.Second) x1 := x y1 := y fmt.Println(“x=”, x1) fmt.Println(“y=”, y1)}
只要把fmt.println之前先把x和y的值拷貝出來到x1與y1,再打印x1與y1的值就基本沒有這個誤差了。
x= 51061072y= 51061071成功: 進程退出代碼 0.
這也就是說,fmt.println在執行中間,go func中的子gorouine又被調度了。所以y比x的值大,本質又是一個多并發的競爭問題。而不是亂序執行的原因,只是這個問題在Go的開發模式下也是非常隱蔽。
3崩潰了,單核怎么也是0
再說第二個令人崩潰的讀者反饋,他在單核的云ECS嘗試運行以下代碼,
package main import (“fmt”//“sync/atomic”“time”) func main() {var x int32var y int32 go func() {for { x++ y++ } }() time.Sleep(time.Second) fmt.Println(“x=”, x) fmt.Println(“y=”, y)}
結果也是0。剛開始我覺得這個讀者反饋有誤,因此我也立刻在阿里云的X86集群與華為云的鯤鵬集群分別申請了一臺單核ECS,不過結果令人崩潰,無論是ARM還是X86單核平臺運行上述代表的結果也還是0,不過這還沒完。
4更崩潰了,隨隨便便加個if竟然殺瘋了…。
接下來是最令人崩潰的時刻,我們來看以下代碼:
package main import (“fmt”//“sync/atomic”“time”) func main() {var x int32var y int32 z := 0 go func() {for { x++//一些無需關注并發安全的計算問題 y++if z 》 0 { fmt.Println(“z is”, z)//這一行代碼不會執行到 } } }() time.Sleep(time.Second)//定時執行,超過1秒鐘就停止了,無需關注并發安全 fmt.Println(“x=”, x) fmt.Println(“y=”, y)}
這段代碼在沒有作何鎖或者互斥體的基礎上竟然解決了y=0的問題,而且令人崩潰的是,這段代碼的執行效率竟然還非常驚人,比之前Automic的方式至少快一個數量級,
如果是這樣的話那么這種代碼方案就非常適合于不需要并發控制,并且定時需要結束的計算場景,假如我一個計算任務只能給1秒鐘,能算得出來就算,算不出來就解下一題了,那么if的方案就非常適合了。
x= 407698730y= 407745938成功: 進程退出代碼 0.
在解釋if分支這個非主流的方案之前,我們再來看一下互斥體這種主流并發同步方案。
互斥體實現如下:
package main import (“fmt”“sync” //“sync/atomic”“time”) func main() {var x int32var y int32var mutex sync.Mutex go func() {for { mutex.Lock() x++ y++ mutex.Unlock() } }() time.Sleep(time.Second) x1 := x y1 := y fmt.Println(“x=”, x1) fmt.Println(“y=”, y1)}
運行結果如下:
x= 50889322y= 50889322成功: 進程退出代碼 0.
我們可以看到互斥、原子操作等方法最終運行結果基本都在一個數量級以內上下浮動,幅度不超過10%,對比之下if的方案實在是殺瘋了,直接比上述這種安全的寫法性能好出一個數量級!隨便加入個if分支,竟然也能解決y=0,而且還是高效解決這到底是為什么?
5關鍵時刻匯編令人心安,大神一語道破
在我的知識儲備實在無法解釋以上現象的時候,我只能將希望訴諸objdump,將gobuild生成的可執行文件來進行反編譯,通過查看匯編語言代碼來尋找問題解釋的蛛絲馬跡。不看不知道一看還真是有驚喜,加了if語句和加鎖等方式一樣全部會加上內存寫屏障writeBarrier。具體如下:
未加if的匯編結果
0000000000499400 《main.main.func1》:499400: eb 00 jmp 499402 《main.main.func1+0x2》499402: eb 00 jmp 499404 《main.main.func1+0x4》499404: eb 00 jmp 499406
《main.main.func1+0x6》499406: eb fa jmp 499402 《main.main.func1+0x2》499408: cc int3499409: cc int349940a: cc int3 49940b: cc int349940c: cc int349940d: cc int3.。。省略0000000000499420 《type..eq.[2]interface {}》:499420: 64 48 8b 0c 25 f8 ff mov %fs:0xfffffffffffffff8,%rcx499427: ff ff499429: 48 3b 61 10 cmp 0x10(%rcx),%rsp 49942d: 0f 86 cf 00 00 00 jbe 499502 《type..eq.[2]interface {}+0xe2》499433: 48 83 ec 50 sub $0x50,%rsp
加了if或者鎖的匯編結果
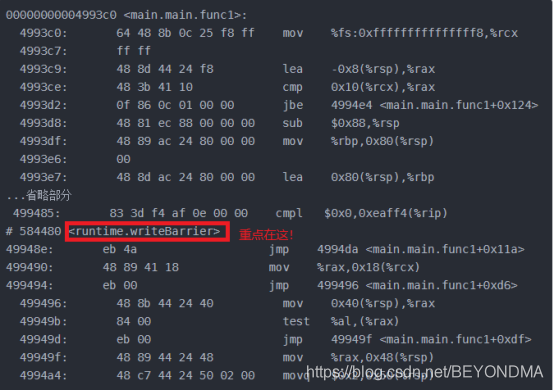
wirteBarrier有點類似于文件操作中flush的作用,會強制把數據由緩存同步到內存當中去,因此我前文中所說兩個變量其中一個加鎖,另一個結果也能不為0是因為他們在同一緩存行原因解釋也不對,x和y并不是因為在同一個緩存行所以才被一起同步回內存的,而是由于wirteBarrier這個屏障所引入的。我們來看下面的代碼。
package main import (“fmt”//“sync/atomic”“time”) func main() {var x int32var y int32 slice := make([]int, 10, 10) z := 0 go func() {for { x++ y++for index, value := range slice { slice[index] = value + 1 }if z 》 0 { fmt.Println(“z is”, z) } } }() time.Sleep(time.Second) fmt.Println(“x=”, x) fmt.Println(“y=”, y) fmt.Println(“slice=”, slice)}
他的運行結果是:
x= 86961625y= 86972610slice= [86978588 86979075 86979101 86979417 86979435 86979452 86979464 86979771 86979793 86979807]成功: 進程退出代碼 0.
我造出來長度為10整形切片,緩存行一般只有64BYTE,那么這個切片上面的數據是不可能在同一緩存行上的,通過這段代碼的執行結果可以看到所有切換的值全部被更新了,因此我們可以了解writeBarrier這個內存寫屏障的功能是將之前所有的數據全部強制回寫到內存當中。
我對于單核ECS中運行的結果也是y=0的結果有了一定的認識,由于ECS虛擬機運行的主體也是物理機,而物理機肯定不是單核的,因此不執行writeBarrier這個寫屏障語句,數據也無法刷回內存,雖然程序運行在單核虛擬機上,而虛擬機并不會把匯編指令再做包裝,這也就造成實際的執行與多核環境沒有什么差別。
6if為什么會被如此安排
實在中If不但實際達到了內存同步的效果,而且還效率更高,看起來非常適合這種沒有強制同步需要的使用場景。不過我們不禁要問為什么編譯器要在出現if語句時顯式調用內存屏障。個人猜測原因有兩個,
if判斷使用真實值是隱含的前提:首先在進行判斷時,使用緩存中的數據可能會帶來顯而易見的問題:因為在做判斷時程序員一般是要求用目前變量的實際值而不是緩存值來進行的,這是一個隱含的前提,可能編譯器在優化時考慮到了這一點。
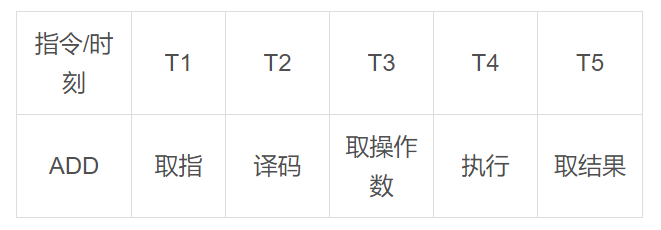
指令流水線的原因:我們知道CPU的每個動作都需要用晶體震蕩而觸發,以加法ADD指令為例,想完成這個執行指令需要取指、譯碼、取操作數、執行以及取操作結果等若干步驟,而每個步驟都需要一次晶體震蕩才能推進,因此在流水線技術出現之前執行一條指令至少需要5到6次晶體震蕩周期才能完成。如下圖:
為了縮短指令執行的晶體震蕩周期,芯片設計人員參考了工廠流水線機制的提出了指令流水線的想法,由于取指、譯碼這些模塊其實在芯片內部都是獨立的,完成可以在同一時刻并發執行,那么只要將多條指令的不同步驟放在同一時刻執行,比如指令1取指,指令2譯碼,指令3取操作數等等,就可以大幅提高CPU執行效率:
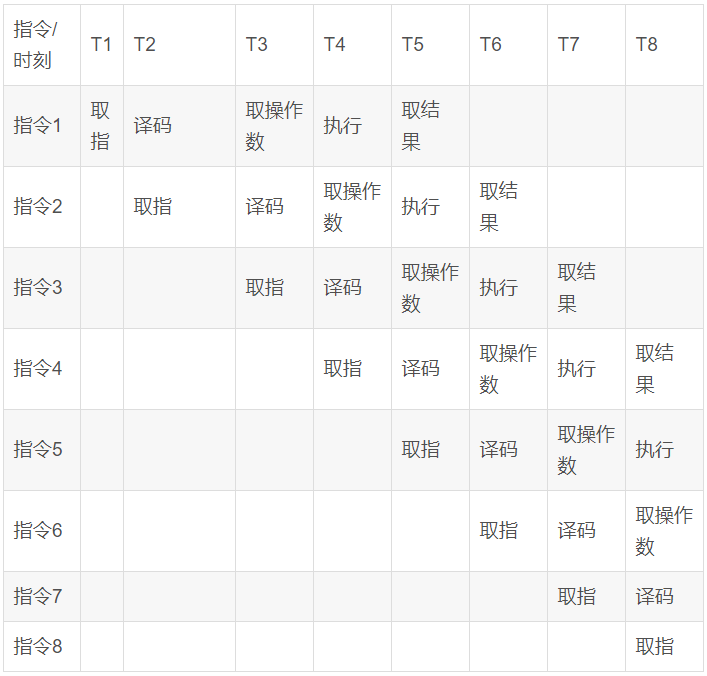
以上圖流水線為例 ,在T5時刻之前指令流水線以每周期一條的速度不斷建立,在T5時代以后每個震蕩周期,都可以有一條指令取結果,平均每條指令就只需要一個震蕩周期就可以完成。這種流水線設計也就大幅提升了CPU的運算速度。
但是if分支會造成流水線的停頓,也就是說指令流水線系統無法確定在指令1執行時確定指令7的具體情況。那么在if時加上writeBarrier這種耗時操作其實也就可以理解了,反正if也造拖慢執行速度,那編譯器也就不在乎在此時加上另外的耗時操作了。
7Rust為什么令人羨慕
不過在看了一段時間的Rust后,我感覺Rust的優勢是可以避免程序員犯很多錯誤,而這其中所謂的錯誤雖然看起來低級,但是如果他們被隱藏在千萬行代碼之中,那么排查起來真是相當費時費力,由于已經是所有權轉移了,因此變量的使用不太會出現像Go一樣的錯誤情況,這點我們在上一篇文章中已經有所論述了,而且我們來看以下代碼:
use std::thread;use std::mpsc;use std::Duration; fn main() {let (tx, rx) = mpsc::channel();let tx1 = mpsc::clone(&tx); //增加一個發送者tx1,需要clonelet tx2 =
mpsc::clone(&tx); //增加一個發送者tx2,需要clone thread::spawn(move || {let vals = vec![String::from(“I‘m”),String::from(“from”),String::from(“the”),String::from(“tx it self”), ]; for val in vals { tx.send(val).unwrap(); }}); thread::spawn(move || {let vals = vec!
[String::from(“I’m”),String::from(“from”),String::from(“the”),String::from(“tx1”), ]; for val in vals { tx1.send(val).unwrap(); }}); thread::spawn(move || {let vals = vec![String::from(“I‘m”),String::from(“from”),String::from(“the”),String::from(“tx2”), ]; for val in vals { tx2.send(val).unwrap(); }}); for received in rx { //一個通道一個接收者,接收若干個發送者的信息 println!(“Got: {}”, received);} }
可見Rust中連管道的多路并發的管理使用都要通過clone的方式來安全傳遞信息,個人根本想不到用Rust編程怎么能出現像上面例子中Go造成的Bug,因此Rust的學習曲線雖然陡峭,但是感覺Rust程序包往往只掌握原生的框架就可以做得很好了,而不像Python、Java除了原生語言知識以外,還需要學習熟練運用各種第三方的包。
馬超,CSDN博客專家,阿里云MVP、華為云MVP,華為2020年技術社區開發者之星。
編輯:jq
-
BUG
+關注
關注
0文章
156瀏覽量
16276
原文標題:遠看像亂序執行,近看是內存屏障的 BUG 是如何解決的?
文章出處:【微信號:coder_life,微信公眾號:程序人生】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄

Linux內核bug狩獵指南:從棧跟蹤到修復,官方文檔教你搞定系統核心故障


單片機程序的執行
從代碼執行看單片機內存的分配
【綜述】工作總有規范——測試執行和bug

提高RISC-V在Drystone測試中得分的方法
電路里的 “隱形屏障”:電容如何像濾網般隔絕電磁干擾?
如何像CanMV IDE預覽哪樣可以在Windows上讀到實時圖像?
隔離屏障的概念以及工作電壓和測試電壓之間的區別
allegro軟件走線命令下參數不顯示如何解決
紅外探測器像元尺寸詳解




 工商網監
工商網監
評論